
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przy budowie modele maszyn uczenia się, trzeba wybrać różne hiperparametrów , takie jak stopy odpadania w warstwie lub tempa uczenia się. Decyzje te wpływają na metryki modelu, takie jak dokładność. Dlatego ważnym krokiem w przepływie pracy uczenia maszynowego jest identyfikacja najlepszych hiperparametrów dla Twojego problemu, co często wiąże się z eksperymentowaniem. Proces ten jest znany jako „Optymalizacja hiperparametrów” lub „Dostrajanie hiperparametrów”.
Pulpit nawigacyjny HParams w TensorBoard zapewnia kilka narzędzi, które pomagają w tym procesie identyfikacji najlepszego eksperymentu lub najbardziej obiecujących zestawów hiperparametrów.
Ten samouczek skupi się na następujących krokach:
- Konfiguracja eksperymentu i podsumowanie HParams
- Dostosuj przebiegi TensorFlow do rejestrowania hiperparametrów i metryk
- Rozpocznij uruchamianie i loguj je wszystkie w jednym katalogu nadrzędnym
- Wizualizuj wyniki w panelu HParams TensorBoard
Zacznij od zainstalowania TF 2.0 i załadowania rozszerzenia notebooka TensorBoard:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
Importuj TensorFlow i wtyczkę TensorBoard HParams:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
Pobierz FashionMNIST zbiór danych i skalować go:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. Konfiguracja eksperymentu i podsumowanie eksperymentu HParams
Eksperymentuj z trzema hiperparametrami w modelu:
- Liczba jednostek w pierwszej gęstej warstwie
- Wskaźnik porzucania w warstwie porzucania
- Optymalizator
Wymień wartości do wypróbowania i zarejestruj konfigurację eksperymentu w TensorBoard. Ten krok jest opcjonalny: możesz podać informacje o domenie, aby umożliwić dokładniejsze filtrowanie hiperparametrów w interfejsie użytkownika, a także określić, które metryki mają być wyświetlane.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
Jeśli zdecydujesz się pominąć ten krok, można użyć ciągiem znaków gdziekolwiek byś inaczej używać HParam wartość: np hparams['dropout'] zamiast hparams[HP_DROPOUT] .
2. Dostosuj przebiegi TensorFlow do rejestrowania hiperparametrów i metryk
Model będzie dość prosty: dwie gęste warstwy z warstwą dropout pomiędzy nimi. Kod szkoleniowy będzie wyglądał znajomo, chociaż hiperparametry nie są już zakodowane na stałe. Zamiast tego hiperparametrów są dostarczane w hparams słownik i używane w funkcji szkoleniowej:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
Dla każdego przebiegu zanotuj podsumowanie hparams z hiperparametrami i końcową dokładnością:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
Podczas uczenia modeli Keras możesz użyć wywołań zwrotnych zamiast pisać je bezpośrednio:
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. Uruchom przebiegi i zapisz je wszystkie w jednym katalogu nadrzędnym
Możesz teraz wypróbować wiele eksperymentów, trenując każdy z nich z innym zestawem hiperparametrów.
Dla uproszczenia użyj przeszukiwania siatki: wypróbuj wszystkie kombinacje parametrów dyskretnych i tylko dolne i górne granice parametru o wartościach rzeczywistych. W przypadku bardziej złożonych scenariuszy bardziej efektywne może być losowe wybieranie każdej wartości hiperparametru (nazywa się to wyszukiwaniem losowym). Można zastosować bardziej zaawansowane metody.
Przeprowadź kilka eksperymentów, które potrwają kilka minut:
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. Wizualizuj wyniki we wtyczce HParams TensorBoard
Można teraz otworzyć pulpit nawigacyjny HParams. Uruchom TensorBoard i kliknij „HParams” u góry.
%tensorboard --logdir logs/hparam_tuning
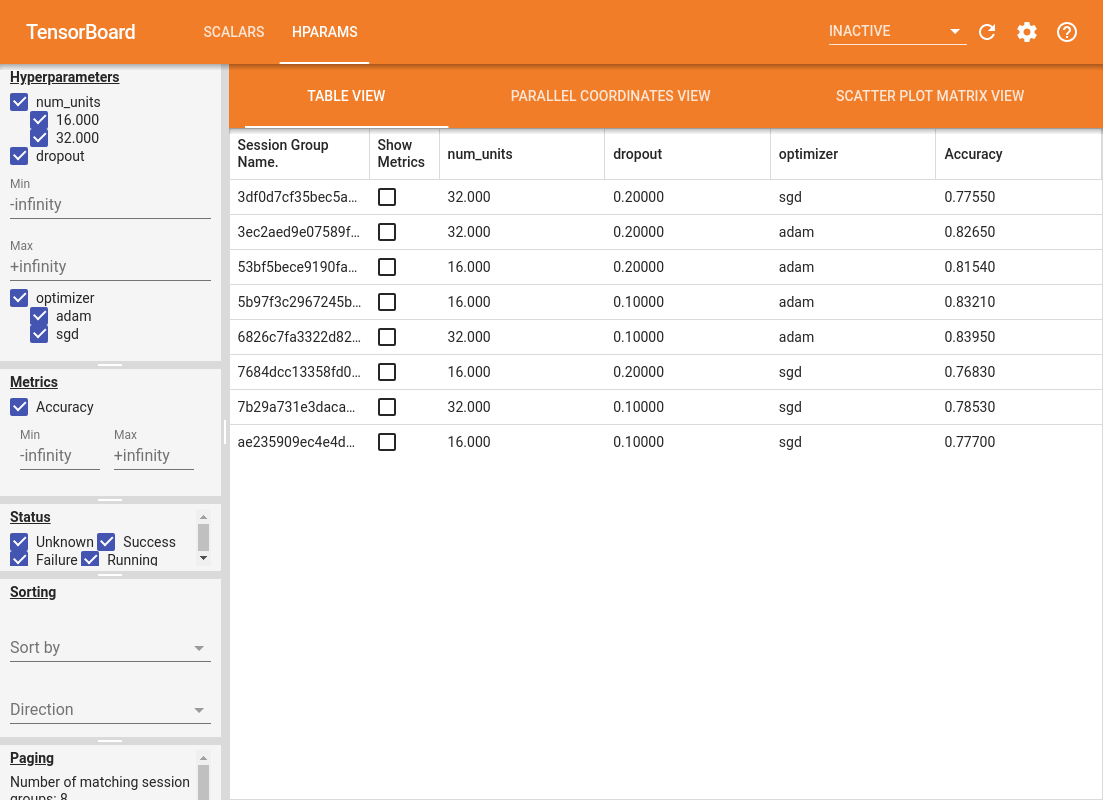
Lewe okienko pulpitu nawigacyjnego zapewnia funkcje filtrowania, które są aktywne we wszystkich widokach pulpitu nawigacyjnego HParams:
- Filtruj, które hiperparametry/metryki są wyświetlane na pulpicie nawigacyjnym
- Filtruj, które wartości hiperparametrów/metryk są wyświetlane na pulpicie nawigacyjnym
- Filtruj według stanu uruchomienia (działanie, sukces, ...)
- Sortuj według hiperparametru/metryki w widoku tabeli
- Liczba grup sesji do wyświetlenia (przydatne w przypadku wielu eksperymentów)
Pulpit nawigacyjny HParams ma trzy różne widoki z różnymi przydatnymi informacjami:
- Tabela Zobacz listę tras, ich hiperparametrów i ich metryki.
- Parallel Współrzędne View pokazuje każdy działał jako linii przechodzącej przez oś dla każdej hyperparemeter i metrykę. Kliknij i przeciągnij myszą na dowolnej osi, aby zaznaczyć region, który podświetli tylko biegi, które przez niego przechodzą. Może to być przydatne do określenia, które grupy hiperparametrów są najważniejsze. Same osie można zmienić, przeciągając je.
- Na wykres punktowy widok pokazuje wykresy porównujące każdą hyperparameter / metryczne ze sobą metrykę. Może to pomóc w identyfikacji korelacji. Kliknij i przeciągnij, aby wybrać region na określonym wykresie i podświetl te sesje na innych wykresach.
Wiersz tabeli, równoległą linię współrzędnych i rynek wykresu punktowego można kliknąć, aby wyświetlić wykres metryk jako funkcję kroków treningowych dla tej sesji (chociaż w tym samouczku dla każdego przebiegu jest używany tylko jeden krok).
Aby dokładniej zbadać możliwości pulpitu HParams, pobierz zestaw wstępnie wygenerowanych dzienników z większą liczbą eksperymentów:
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
Zobacz te logi w TensorBoard:
%tensorboard --logdir logs/hparam_demo
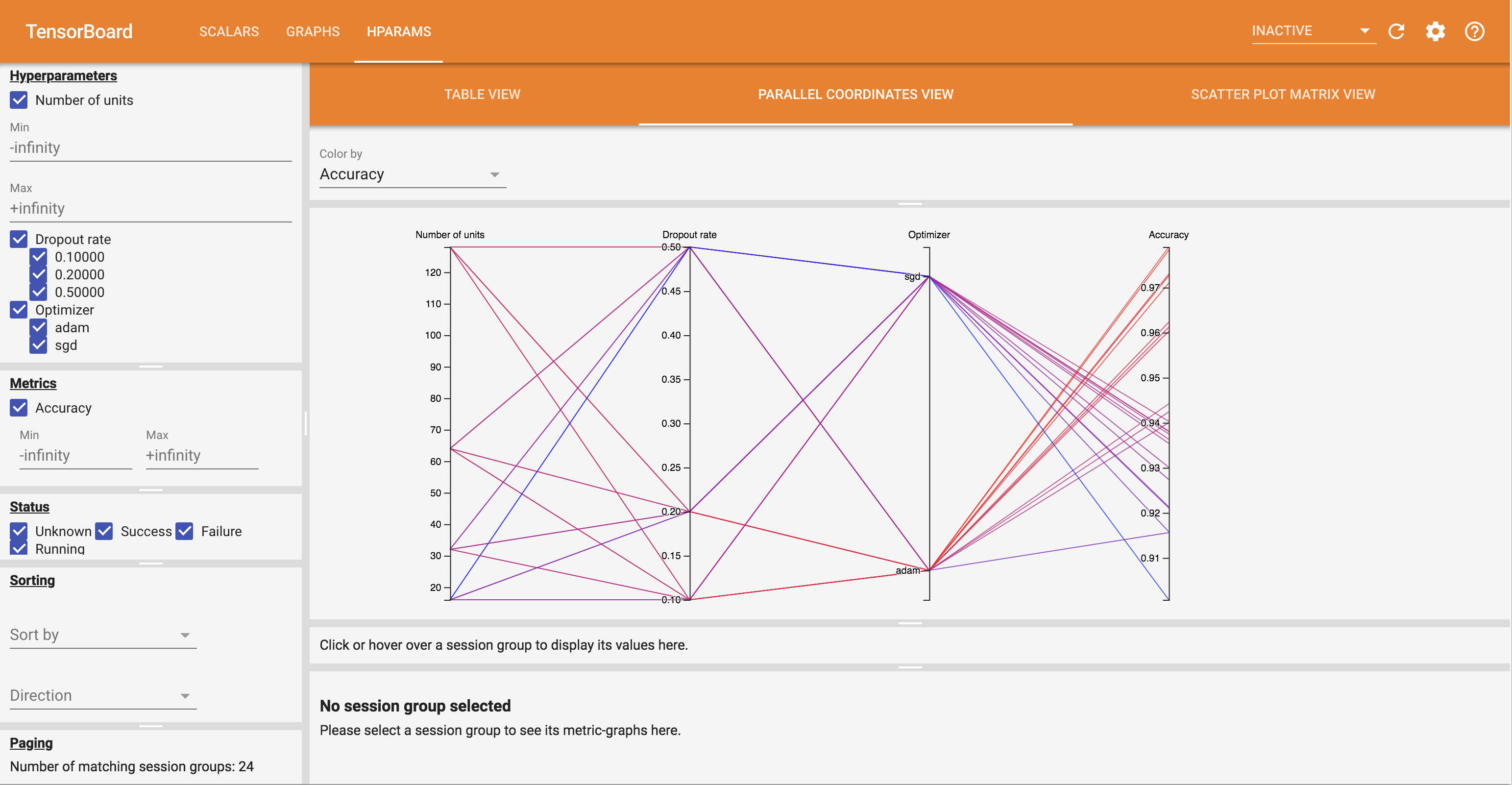
Możesz wypróbować różne widoki na pulpicie nawigacyjnym HParams.
Na przykład, przechodząc do widoku współrzędnych równoległych i klikając i przeciągając oś dokładności, można wybrać przebiegi o najwyższej dokładności. Ponieważ przebiegi te przechodzą przez „adam” na osi optymalizatora, można stwierdzić, że w tych eksperymentach wyniki „adam” były lepsze niż „sgd”.