
 在 GitHub 上查看源代码 在 GitHub 上查看源代码 |
|
构建机器学习模型时,您需要选择各种超参数,例如层中的随机失活率或学习率。这些决策会影响诸如准确率等模型指标。因此,为您的问题确定最佳超参数是机器学习工作流中的一个重要步骤,这通常需要进行实验。此过程被称为“超参数优化”或“超参数调节”。
TensorBoard 中的 HParams 信息中心为此过程提供了多种工具,可帮助确定最佳实验或最可行的超参数集。
本教程将重点关注以下步骤:
- 试验设置和 HParams 摘要
- 调整 TensorFlow 运行以记录超参数和指标
- 开始运行并将其全部记录在一个父目录下
- 在 TensorBoard 的 HParams 信息中心中可视化结果
注:HParams 摘要 API 和信息中心界面尚处于预览阶段,因此会随着时间而变化。
首先,安装 TF 2.0 并加载 TensorBoard 笔记本扩展程序:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
导入 TensorFlow 和 TensorBoard HParams 插件:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
下载 FashionMNIST 数据集并对其进行缩放:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. 试验设置和 HParams 实验摘要
在模型中试验三个超参数:
- 第一个密集层中的单元数
- 随机失活层中的随机失活率
- 优化器
列出要尝试的值,并将实验配置记录到 TensorBoard 中。此为可选步骤:您可以提供域信息以便在界面中更精确地筛选超参数,并且可以指定应显示哪些指标。
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
如果您选择跳过此步骤,可以在使用 HParam 值的地方使用字符串字面量(例如,使用 hparams['dropout'] 代替 hparams[HP_DROPOUT])。
2. 调整 TensorFlow 运行以记录超参数和指标
该模型将非常简单:两个密集层之间有一个随机失活层。尽管不再对超参数进行硬编码,但训练代码仍然相似。超参数将改为在 hparams 字典中提供,并用于整个训练函数:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
对于每次运行,记录包含超参数和最终准确率的 Hparams 摘要:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
训练 Keras 模型时,可以使用回调来代替直接编写:
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. 开始运行并将其全部记录在一个父目录下
现在,您可以尝试多个实验,使用不同的超参数集训练每个模型。
为简单起见,请使用网格搜索:尝试使用离散参数的所有组合,以及仅使用实值参数的上界和下界值。对于更复杂的场景,随机选择各个超参数值可能更加有效(这称为随机搜索)。也有更高级的方法可以使用。
运行一些实验,这将需要几分钟时间:
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. 在 TensorBoard 的 HParams 插件中可视化结果
现在可以打开 HParams 信息中心。启动 TensorBoard,然后点击顶部的“HParams”。
%tensorboard --logdir logs/hparam_tuning
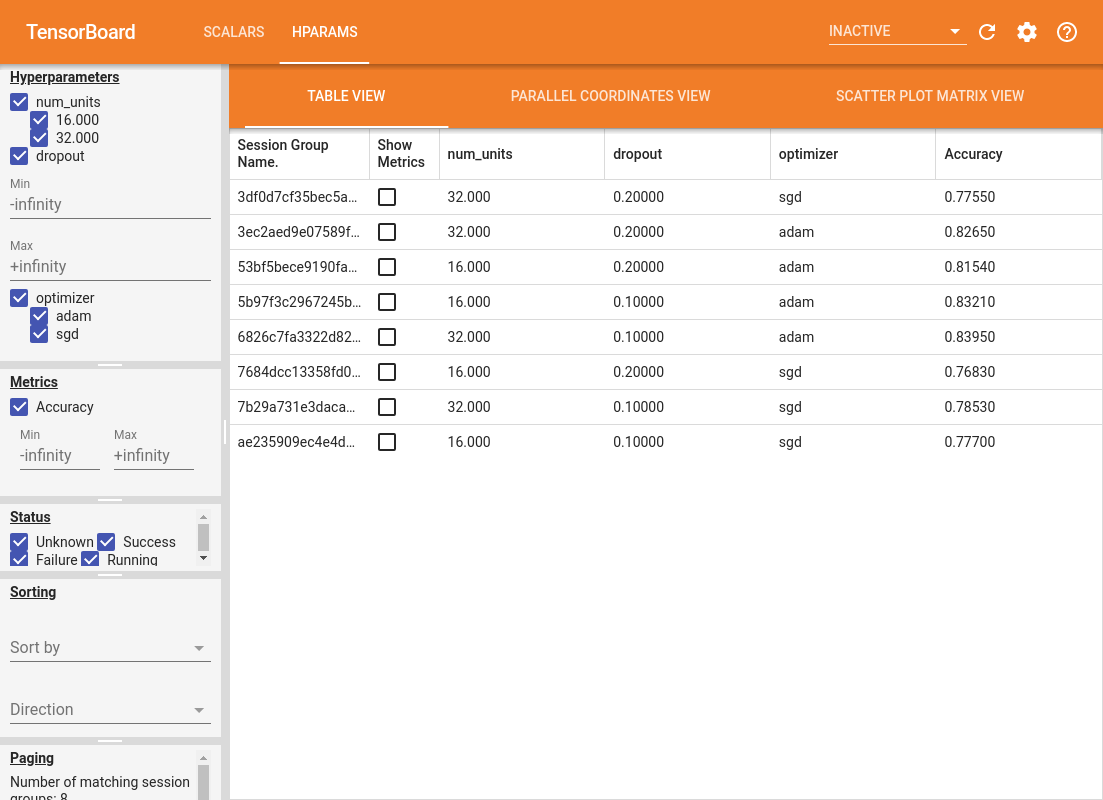
信息中心的左侧窗格提供了筛选功能,该功能在 HParams 信息中心的所有视图中均有效:
- 筛选在信息中心中显示哪些超参数/指标
- 筛选在信息中心中显示哪些超参数/指标值
- 筛选运行状态(正在运行、成功…)
- 在表格视图中按超参数/指标排序
- 设置要显示的会话组数(在包含大量实验时可有效提高性能)
HParams 信息中心具有三种不同的视图,包含了各种实用信息:
- 表格视图将列出运行、其超参数及其指标。
- 平行坐标视图将每次运行显示为一条穿过每个超参数和指标轴的线。点击并拖动任何轴可标记一个区域,这将仅突出显示通过该区域的运行。需要确定哪些超参数组最为重要时,这种模式非常实用。轴本身可以通过拖动来重新排序。
- 散点图视图将显示每个超参数/指标与每个指标相比较的图。这种视图可以帮助识别相关性。点击并拖动以选择特定图中的区域后,将在其他图中突出显示相应的会话。
可以点击表格行、平行坐标线和散点图市场,作为该会话训练步骤的函数查看指标图(在本教程中,每次运行仅使用一个步骤)。
要进一步了解 HParams 信息中心的功能,请下载一组包含更多实验的预生成日志:
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
在 TensorBoard 中查看这些日志:
%tensorboard --logdir logs/hparam_demo
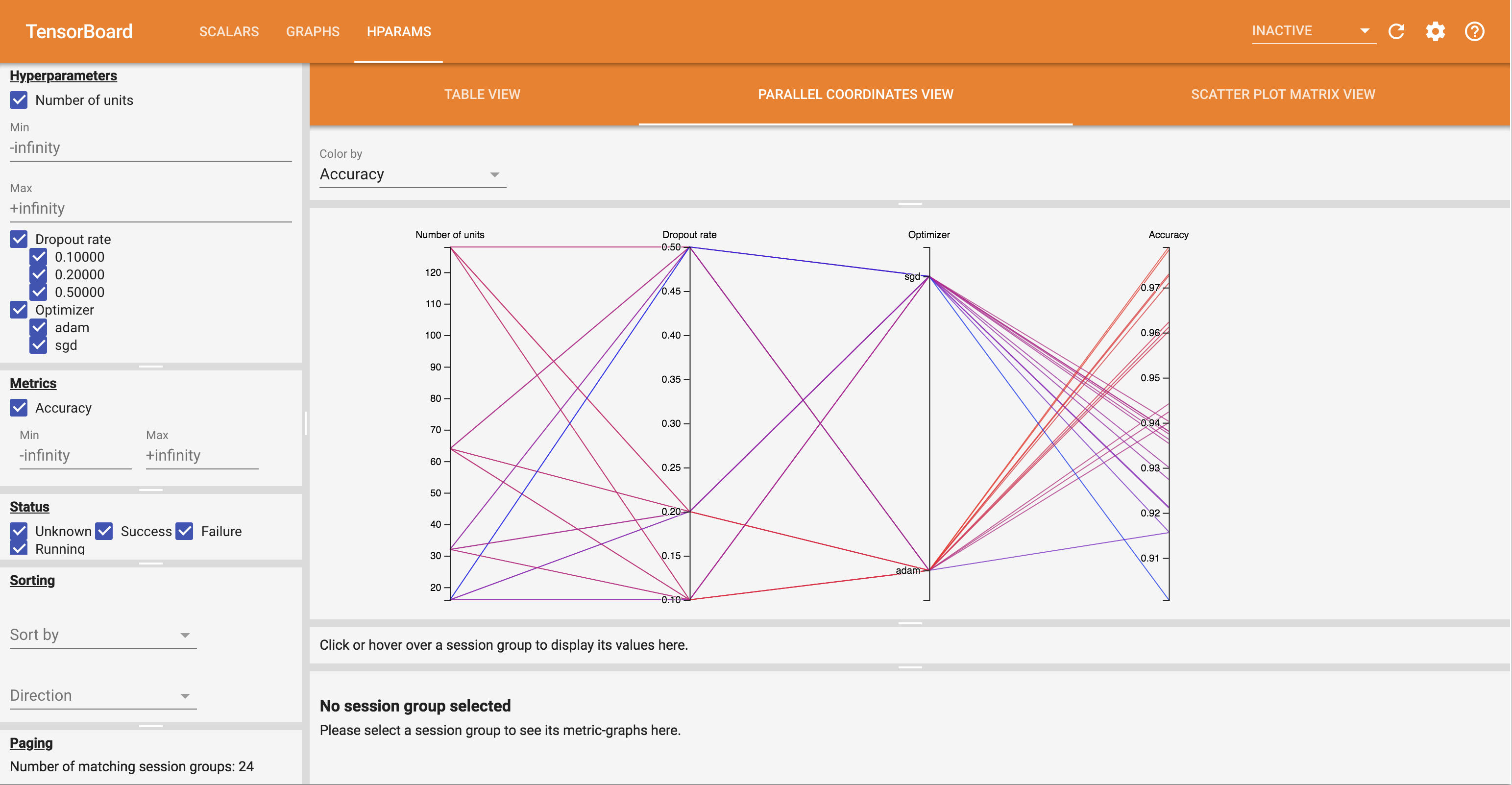
您可以尝试在 HParams 信息中心中使用不同的视图。
例如,切换到平行坐标视图,然后点击并拖动准确率轴,您可以选择准确率最高的运行。当这些运行通过优化器轴上的 'adam' 时,您可以得出结论,在这些实验中 'adam' 的性能优于 'sgd'。