
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Visão geral
Os algoritmos de aprendizado de máquina geralmente são computacionalmente caros. Portanto, é vital quantificar o desempenho do seu aplicativo de aprendizado de máquina para garantir que você esteja executando a versão mais otimizada do seu modelo. Use o TensorFlow Profiler para criar o perfil da execução do código do TensorFlow.
Configurar
from datetime import datetime
from packaging import version
import os
O TensorFlow Profiler exige as últimas versões de TensorFlow e TensorBoard ( >=2.2 ).
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
Confirme se o TensorFlow pode acessar a GPU.
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
Treinar um modelo de classificação de imagem com retornos de chamada do TensorBoard
Neste tutorial, você explorar as capacidades do TensorFlow Profiler ao capturar o perfil de desempenho obtidos através da formação de um modelo de imagens Classificar no conjunto de dados MNIST .
Use os conjuntos de dados do TensorFlow para importar os dados de treinamento e dividi-los em conjuntos de treinamento e teste.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
Pré-processe os dados de treinamento e teste normalizando os valores de pixel entre 0 e 1.
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
Crie o modelo de classificação de imagem usando Keras.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
Crie um retorno de chamada do TensorBoard para capturar perfis de desempenho e chamá-lo durante o treinamento do modelo.
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
Use o TensorFlow Profiler para traçar o perfil do desempenho do treinamento do modelo
O TensorFlow Profiler está integrado ao TensorBoard. Carregue o TensorBoard usando a magia Colab e inicie-o. Visualizar os perfis de desempenho, navegando até a guia Perfil.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
O perfil de desempenho para este modelo é semelhante à imagem abaixo.
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
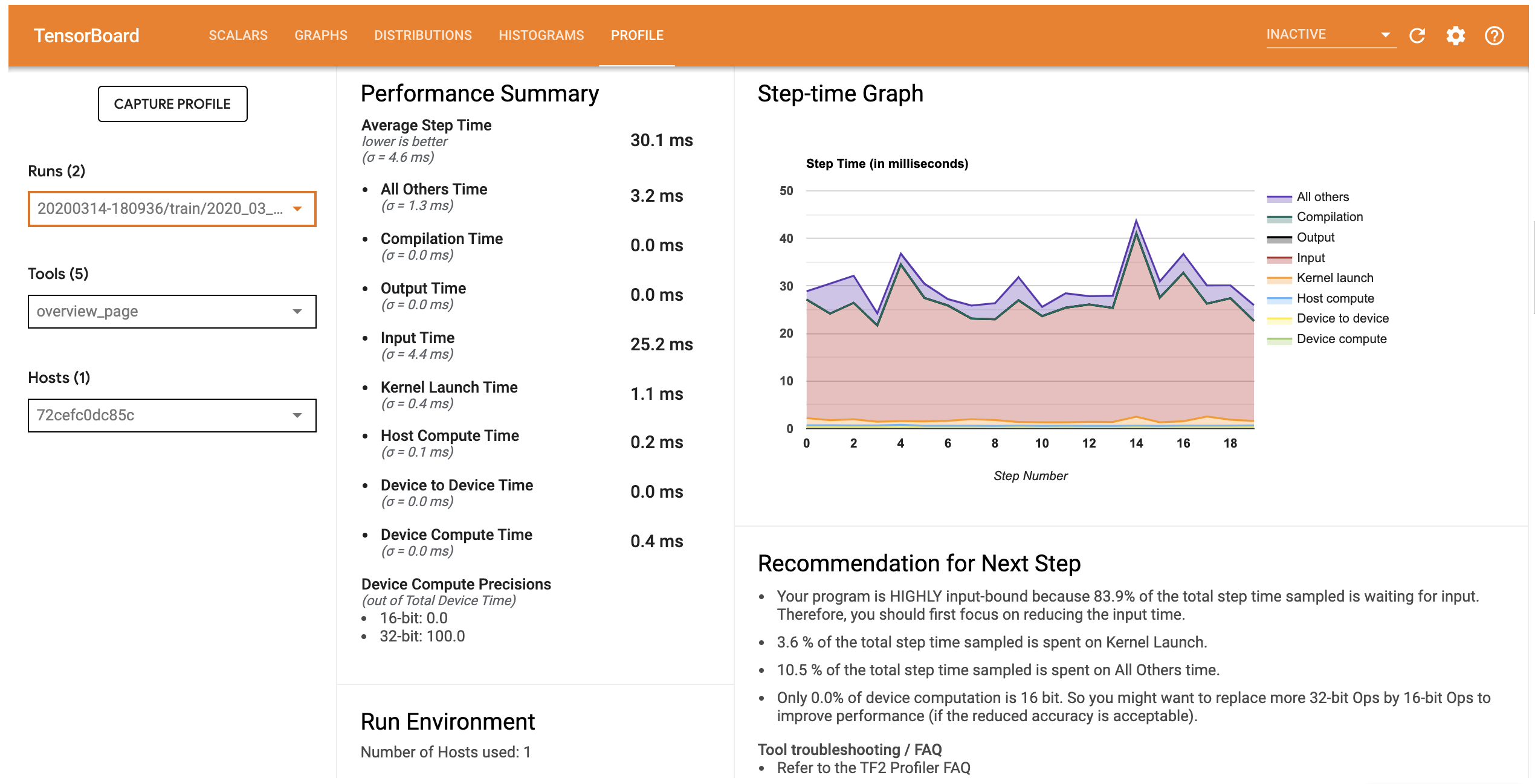
A guia Perfil abre a página de Visão Geral, que apresenta um resumo de alto nível do seu desempenho do modelo. Observando o Step-time Graph à direita, você pode ver que o modelo é altamente vinculado à entrada (ou seja, ele gasta muito tempo na linha de entrada de dados). A página Visão geral também fornece recomendações sobre possíveis próximas etapas que você pode seguir para otimizar o desempenho do seu modelo.
Para entender onde está o gargalo de desempenho ocorre no pipeline de entrada, selecione o visualizador de rastreamento das Ferramentas suspenso à esquerda. O Trace Viewer mostra uma linha do tempo dos diferentes eventos que ocorreram na CPU e na GPU durante o período de criação de perfil.
O Trace Viewer mostra vários grupos de eventos no eixo vertical. Cada grupo de eventos possui várias faixas horizontais, preenchidas com eventos de rastreamento. A faixa é uma linha do tempo de eventos para eventos executados em um thread ou fluxo de GPU. Eventos individuais são os blocos coloridos e retangulares nas faixas da linha do tempo. O tempo se move da esquerda para a direita. Navegar pelos eventos de rastreamento usando os atalhos de teclado W (zoom in), S (zoom out), A (rolagem esquerda) e D (deslocamento direita).
Um único retângulo representa um evento de rastreamento. Selecione o ícone do cursor do mouse na barra de ferramentas flutuante (ou use o atalho de teclado 1 ) e clique no evento de rastreamento para analisá-lo. Isso exibirá informações sobre o evento, como sua hora de início e duração.
Além de clicar, você pode arrastar o mouse para selecionar um grupo de eventos de rastreamento. Isso lhe dará uma lista de todos os eventos nessa área, juntamente com um resumo do evento. Use o M -chave para medir o tempo de duração dos eventos selecionados.
Os eventos de rastreamento são coletados de:
- CPU: eventos de CPU são exibidas em um grupo de eventos denominado
/host:CPU. Cada trilha representa uma thread na CPU. Os eventos de CPU incluem eventos de pipeline de entrada, eventos de agendamento de operação de GPU (op), eventos de execução de operação de CPU etc. - GPU: eventos GPU são exibidos em grupos de eventos prefixados por
/device:GPU:. Cada grupo de eventos representa um fluxo na GPU.
Depurar gargalos de desempenho
Use o Trace Viewer para localizar os gargalos de desempenho em seu pipeline de entrada. A imagem abaixo é um instantâneo do perfil de desempenho.
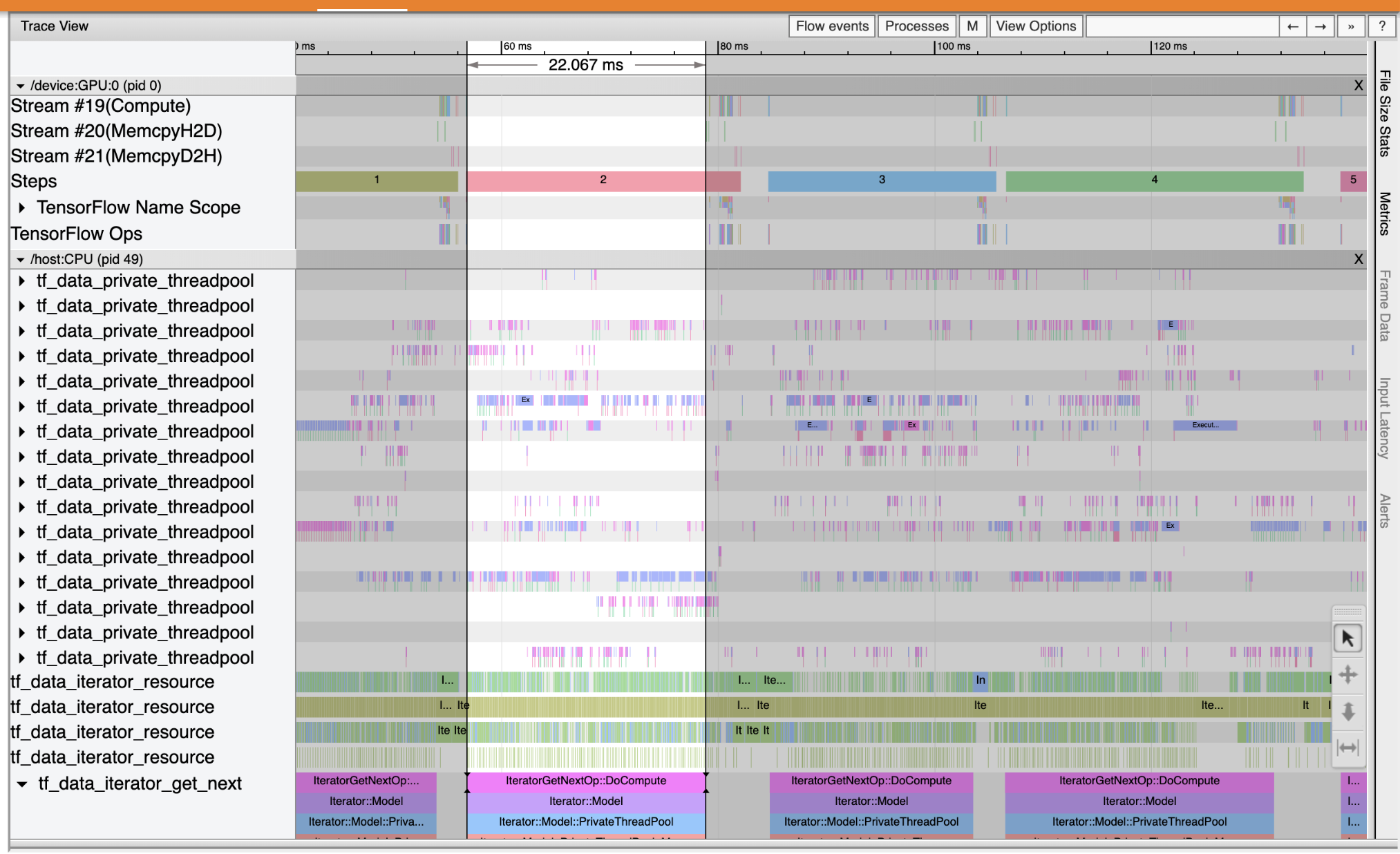
Olhando para os traços de eventos, você pode ver que a GPU está inativo enquanto o tf_data_iterator_get_next op está em execução na CPU. Este op é responsável por processar os dados de entrada e enviá-los para a GPU para treinamento. Como regra geral, é uma boa ideia manter sempre o dispositivo (GPU/TPU) ativo.
Use o tf.data API para otimizar a entrada do pipeline. Nesse caso, vamos armazenar em cache o conjunto de dados de treinamento e pré-buscar os dados para garantir que sempre haja dados disponíveis para a GPU processar. Veja aqui para mais detalhes sobre como usar tf.data para otimizar seus dutos de entrada.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
Treine o modelo novamente e capture o perfil de desempenho reutilizando o retorno de chamada de antes.
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
Re-lançamento TensorBoard e abra a guia Perfil para observar o perfil de desempenho para o gasoduto de entrada atualizada.
O perfil de desempenho do modelo com o pipeline de entrada otimizado é semelhante à imagem abaixo.
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
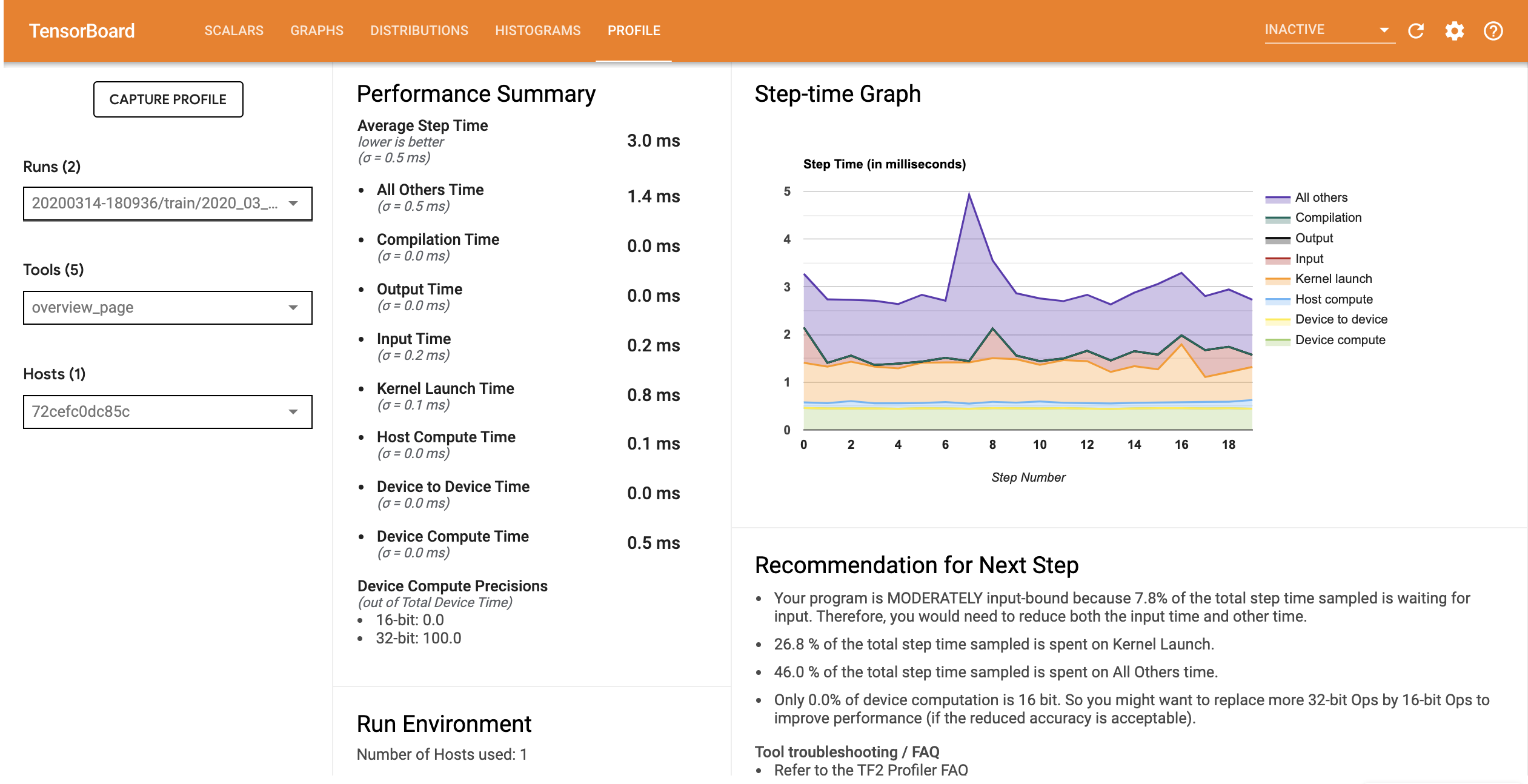
Na página Visão geral, você pode ver que o tempo médio da etapa foi reduzido, assim como o tempo da etapa de entrada. O Step-time Graph também indica que o modelo não é mais altamente vinculado à entrada. Abra o Trace Viewer para examinar os eventos de rastreamento com o pipeline de entrada otimizado.
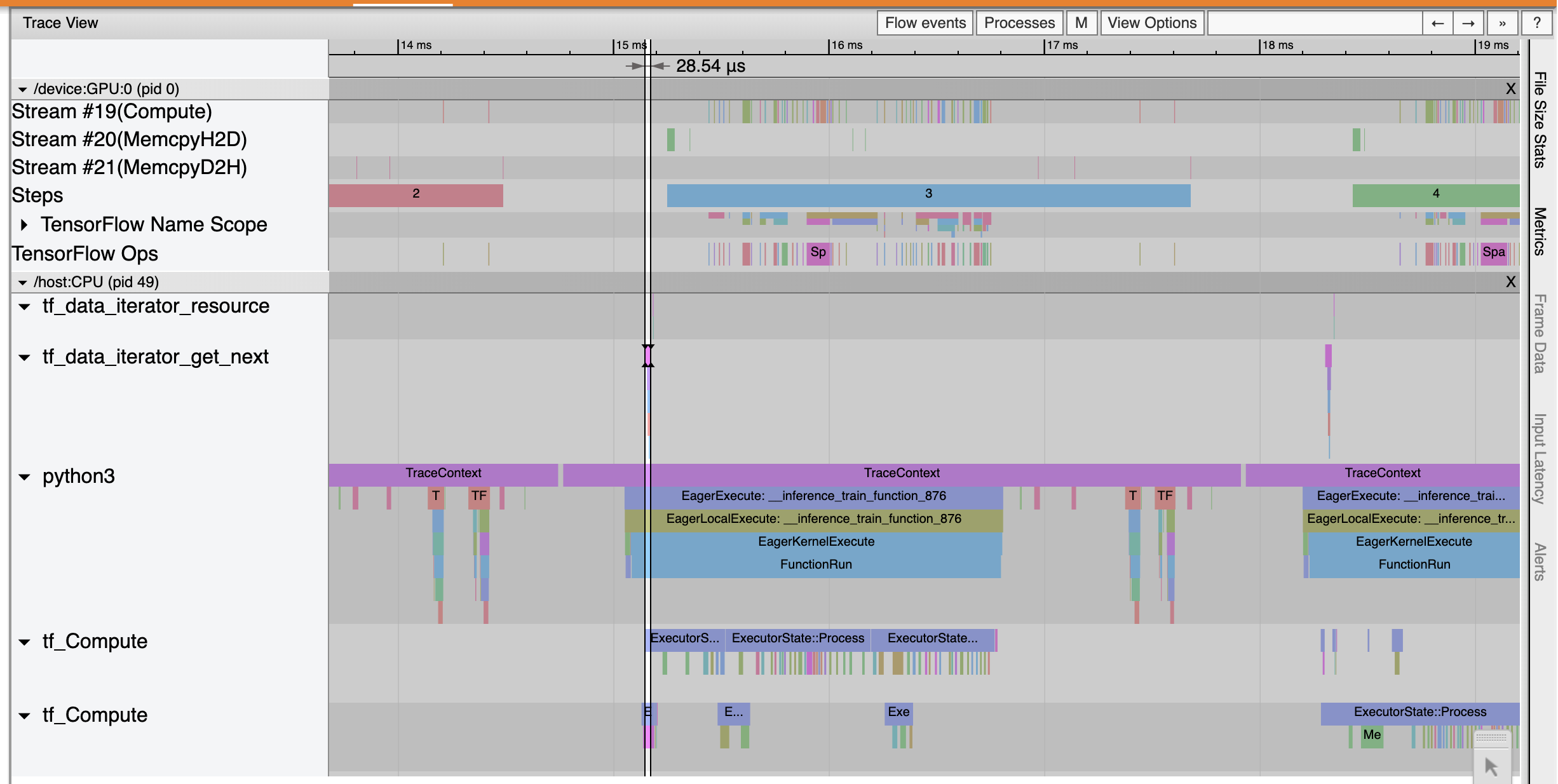
Os shows Trace Viewer que o tf_data_iterator_get_next op executa muito mais rápido. A GPU, portanto, obtém um fluxo constante de dados para realizar o treinamento e obtém uma utilização muito melhor por meio do treinamento do modelo.
Resumo
Use o TensorFlow Profiler para criar perfil e depurar o desempenho do treinamento do modelo. Leia o guia Profiler e ver o perfil de desempenho em TF 2 talk da Cúpula TensorFlow Dev 2020 para saber mais sobre o TensorFlow Profiler.