
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Panoramica
Gli algoritmi di apprendimento automatico sono in genere costosi dal punto di vista computazionale. È quindi fondamentale quantificare le prestazioni della tua applicazione di machine learning per assicurarti di eseguire la versione più ottimizzata del tuo modello. Usa il TensorFlow Profiler per profilare l'esecuzione del tuo codice TensorFlow.
Impostare
from datetime import datetime
from packaging import version
import os
Il tensorflow Profiler richiede le ultime versioni di tensorflow e TensorBoard ( >=2.2 ).
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
Conferma che TensorFlow può accedere alla GPU.
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
Addestrare un modello di classificazione delle immagini con i callback TensorBoard
In questo tutorial, di esplorare le capacità del tensorflow Profiler catturando il profilo delle prestazioni ottenuto attraverso la formazione di un modello da immagini Classificare nel set di dati MNIST .
Usa i set di dati TensorFlow per importare i dati di addestramento e suddividerli in set di addestramento e di test.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
Preelabora i dati di training e test normalizzando i valori dei pixel in modo che siano compresi tra 0 e 1.
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
Crea il modello di classificazione delle immagini utilizzando Keras.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
Crea un callback TensorBoard per acquisire i profili delle prestazioni e chiamarlo durante l'addestramento del modello.
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
Usa TensorFlow Profiler per profilare le prestazioni di addestramento del modello
Il TensorFlow Profiler è integrato in TensorBoard. Carica TensorBoard usando Colab magic e avvialo. Guarda i profili di prestazioni accedendo alla scheda Profilo.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
Il profilo delle prestazioni per questo modello è simile all'immagine qui sotto.
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
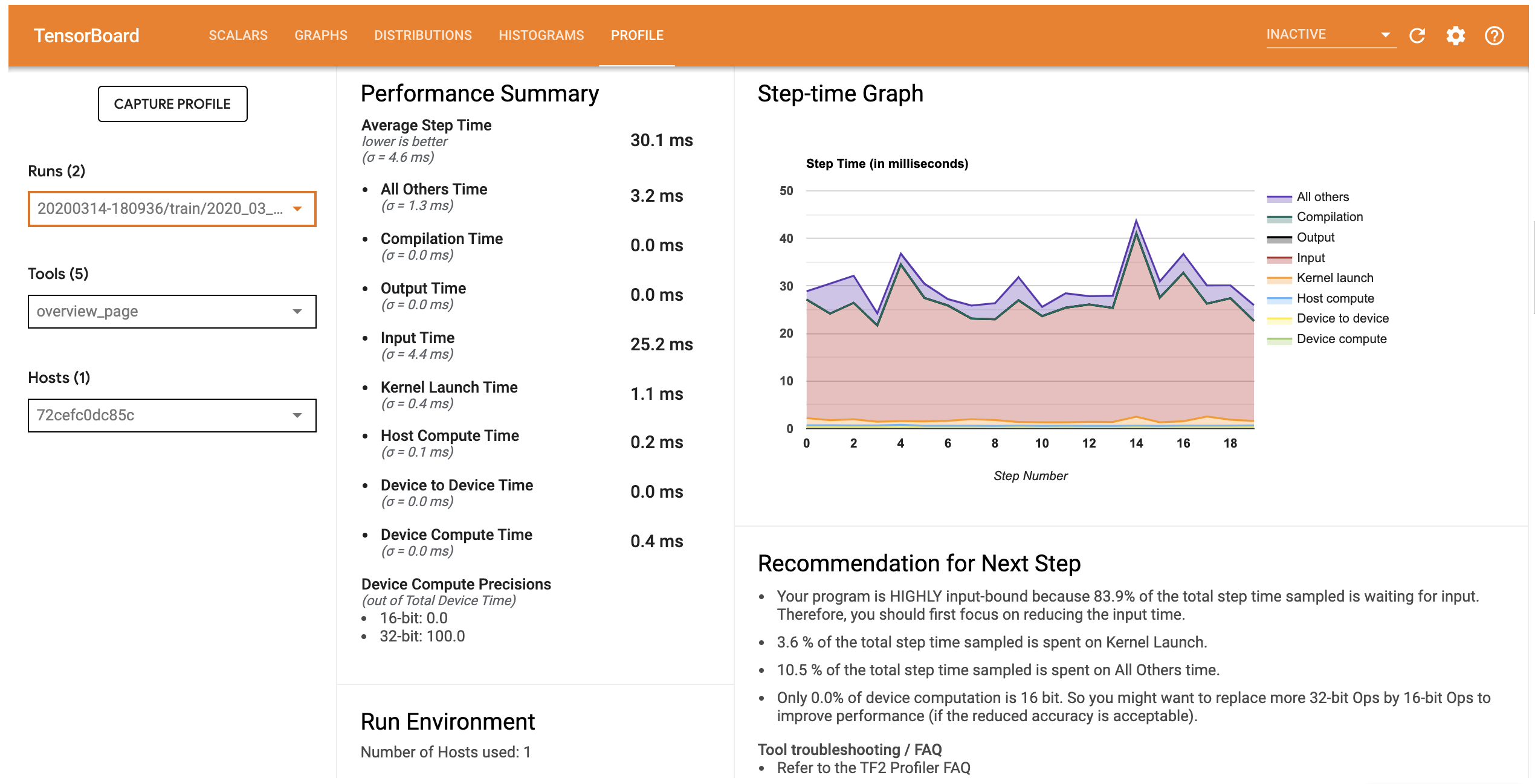
La scheda Profile apre la pagina Panoramica che mostra un riepilogo di alto livello delle vostre prestazioni del modello. Guardando il grafico Step-time sulla destra, puoi vedere che il modello è fortemente vincolato all'input (cioè, trascorre molto tempo nella linea di input dei dati). La pagina Panoramica fornisce anche consigli sui potenziali passaggi successivi che è possibile seguire per ottimizzare le prestazioni del modello.
Per capire dove si verifica il collo di bottiglia delle prestazioni in cantiere di ingresso, selezionare il visualizzatore di analisi da Strumenti discesa a sinistra. Il Trace Viewer mostra una sequenza temporale dei diversi eventi che si sono verificati sulla CPU e sulla GPU durante il periodo di profilazione.
Il visualizzatore di tracce mostra più gruppi di eventi sull'asse verticale. Ogni gruppo di eventi ha più tracce orizzontali, piene di eventi di traccia. La traccia è una sequenza temporale degli eventi per gli eventi eseguiti su un thread o un flusso GPU. I singoli eventi sono i blocchi rettangolari colorati sulle tracce della timeline. Il tempo si sposta da sinistra a destra. Navigare gli eventi di traccia utilizzando i tasti di scelta rapida W (zoom), S (zoom out), A (scorrere verso sinistra), e D (scorrimento a destra).
Un singolo rettangolo rappresenta un evento di traccia. Selezionare l'icona cursore del mouse sulla barra degli strumenti galleggiante (o usare la scorciatoia da tastiera 1 ) e fare clic l'evento di traccia di analizzarlo. Verranno visualizzate le informazioni sull'evento, come l'ora di inizio e la durata.
Oltre a fare clic, è possibile trascinare il mouse per selezionare un gruppo di eventi di traccia. Questo ti darà un elenco di tutti gli eventi in quell'area insieme a un riepilogo dell'evento. Utilizzare il M chiave per misurare la durata degli eventi selezionati.
Gli eventi di traccia vengono raccolti da:
- CPU: gli eventi della CPU vengono visualizzati sotto un gruppo di eventi di nome
/host:CPU. Ogni traccia rappresenta un thread sulla CPU. Gli eventi della CPU includono eventi della pipeline di input, eventi di pianificazione delle operazioni (operazioni) della GPU, eventi di esecuzione delle operazioni della CPU, ecc. - GPU: eventi GPU vengono visualizzati in gruppi eventi preceduti da
/device:GPU:. Ogni gruppo di eventi rappresenta un flusso sulla GPU.
Debug delle prestazioni colli di bottiglia
Utilizzare il visualizzatore di traccia per individuare i colli di bottiglia delle prestazioni nella pipeline di input. L'immagine sotto è un'istantanea del profilo delle prestazioni.
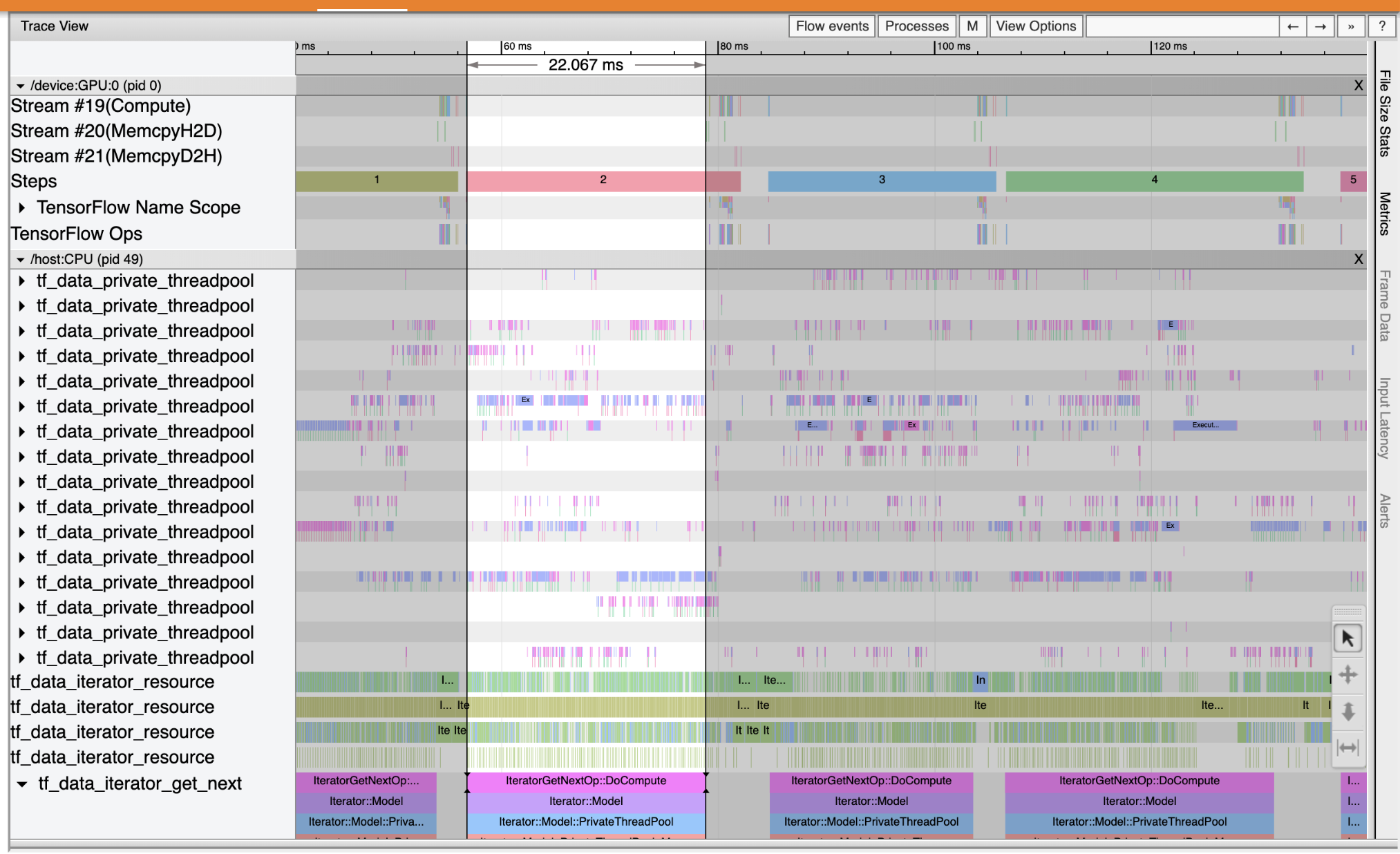
Guardando le tracce degli eventi, si può vedere che la GPU è inattivo, mentre il tf_data_iterator_get_next op è in esecuzione sulla CPU. Questa operazione è responsabile dell'elaborazione dei dati di input e dell'invio alla GPU per l'addestramento. Come regola generale, è una buona idea mantenere sempre attivo il dispositivo (GPU/TPU).
Utilizzare il tf.data API per ottimizzare la pipeline di ingresso. In questo caso, memorizziamo nella cache il set di dati di training e preleviamo i dati per assicurarci che siano sempre disponibili dati per l'elaborazione da parte della GPU. Vedi qui per maggiori dettagli sull'uso tf.data per ottimizzare le tubazioni di ingresso.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
Addestrare nuovamente il modello e acquisire il profilo delle prestazioni riutilizzando il callback precedente.
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
Rilancio TensorBoard e aprire la scheda Profilo di osservare il profilo delle prestazioni per il gasdotto di input aggiornato.
Il profilo delle prestazioni per il modello con la pipeline di input ottimizzata è simile all'immagine seguente.
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
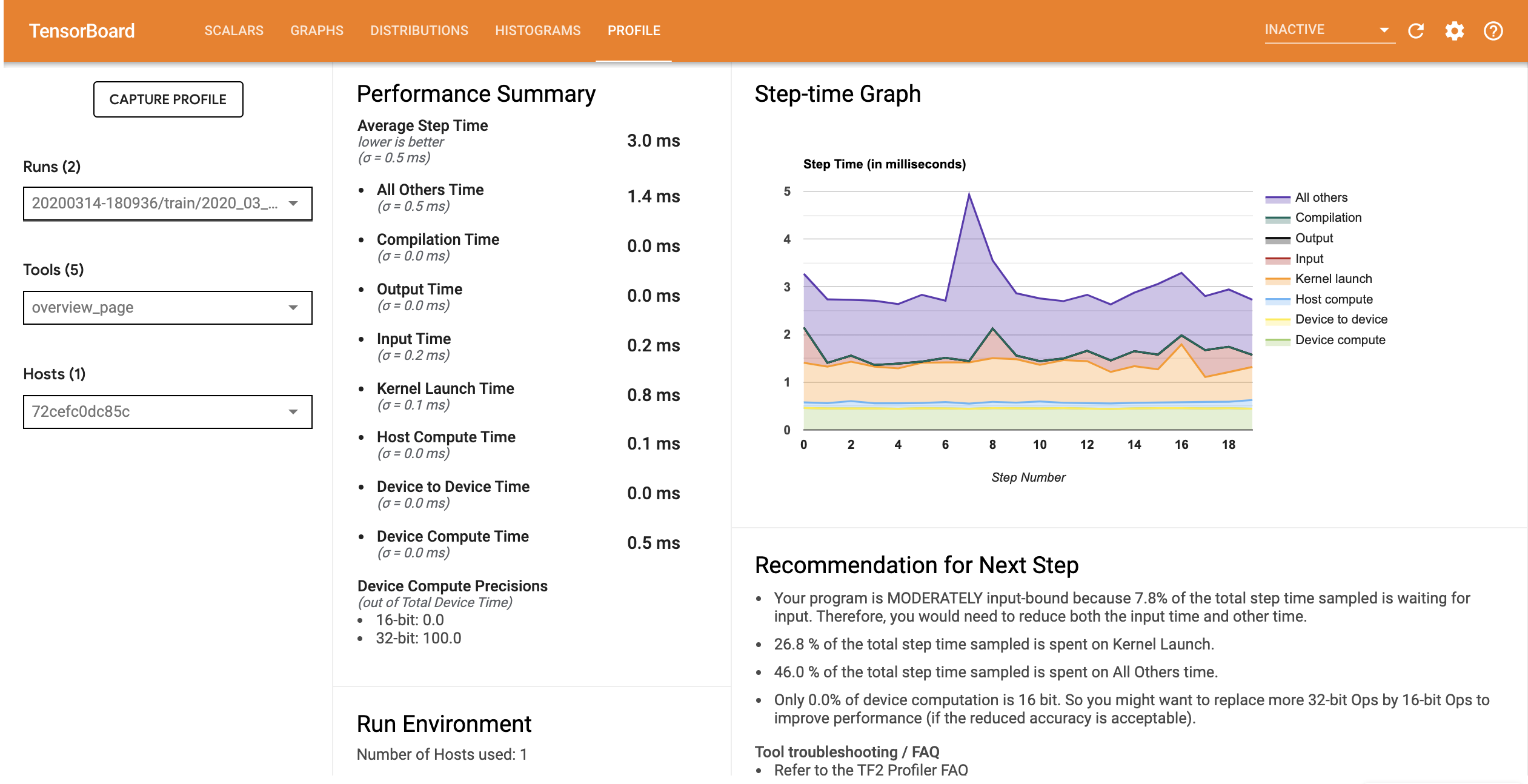
Dalla pagina Panoramica, puoi vedere che il tempo medio del passo si è ridotto così come il tempo del passo di input. Il grafico Step-time indica anche che il modello non è più fortemente vincolato all'input. Aprire il Visualizzatore di traccia per esaminare gli eventi di traccia con la pipeline di input ottimizzata.
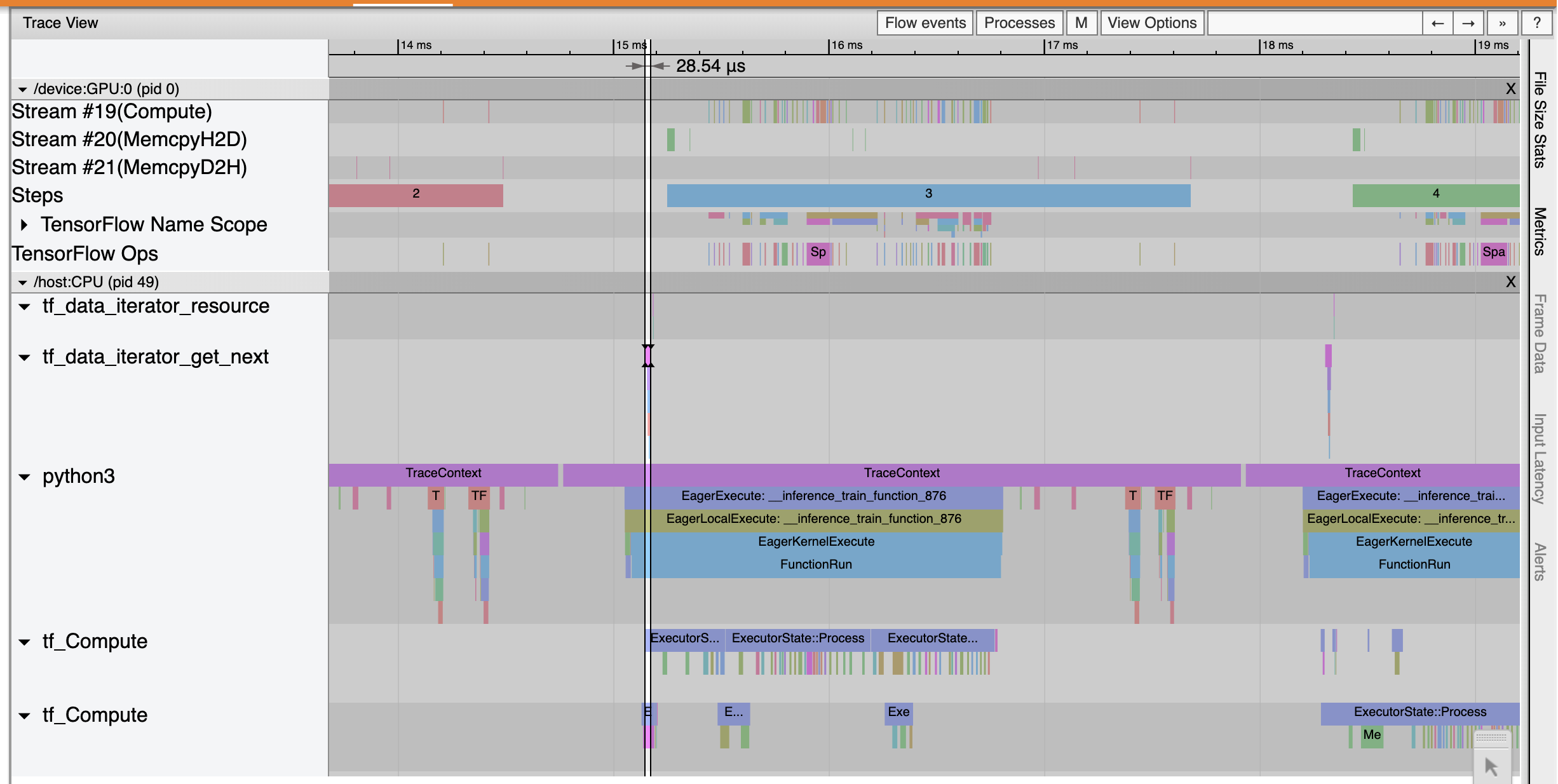
Gli spettacoli Trace Viewer che il tf_data_iterator_get_next op esegue molto più velocemente. La GPU quindi ottiene un flusso costante di dati per eseguire l'addestramento e ottiene un utilizzo molto migliore attraverso l'addestramento del modello.
Riepilogo
Usa TensorFlow Profiler per profilare ed eseguire il debug delle prestazioni di addestramento del modello. Leggi la guida Profiler e guardare il profiling delle prestazioni in TF 2 discorso dal vertice tensorflow Dev 2020 per saperne di più sulla tensorflow Profiler.