
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ภาพรวม
อัลกอริธึมการเรียนรู้ของเครื่องมักจะมีราคาแพงในการคำนวณ ดังนั้นจึงเป็นเรื่องสำคัญที่จะต้องวัดประสิทธิภาพของแอปพลิเคชันการเรียนรู้ของเครื่อง เพื่อให้แน่ใจว่าคุณกำลังใช้งานโมเดลที่ปรับให้เหมาะสมที่สุด ใช้ TensorFlow Profiler เพื่อกำหนดโปรไฟล์การเรียกใช้โค้ด TensorFlow ของคุณ
ติดตั้ง
from datetime import datetime
from packaging import version
import os
TensorFlow Profiler ต้องรุ่นล่าสุดของ TensorFlow และ TensorBoard ( >=2.2 )
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
ยืนยันว่า TensorFlow สามารถเข้าถึง GPU ได้
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
ฝึกโมเดลการจัดประเภทรูปภาพด้วย TensorBoard callbacks
ในการกวดวิชานี้คุณสำรวจความสามารถของ TensorFlow Profiler โดยการจับรายละเอียดผลการดำเนินงานที่ได้รับโดยการฝึกอบรมรูปแบบให้กับภาพประเภทใน ชุดข้อมูลที่ MNIST
ใช้ชุดข้อมูล TensorFlow เพื่อนำเข้าข้อมูลการฝึกและแบ่งออกเป็นชุดการฝึกและชุดทดสอบ
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
ประมวลผลข้อมูลการฝึกอบรมล่วงหน้าและทดสอบโดยการปรับค่าพิกเซลให้เป็นมาตรฐานให้อยู่ระหว่าง 0 ถึง 1
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
สร้างแบบจำลองการจัดประเภทรูปภาพโดยใช้ Keras
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
สร้างการเรียกกลับของ TensorBoard เพื่อบันทึกโปรไฟล์ประสิทธิภาพและเรียกใช้ขณะฝึกโมเดล
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
ใช้ TensorFlow Profiler เพื่อสร้างโปรไฟล์ประสิทธิภาพการฝึกโมเดล
TensorFlow Profiler ถูกฝังอยู่ภายใน TensorBoard โหลด TensorBoard โดยใช้เวทมนตร์ของ Colab แล้วเปิดใช้งาน ดูโปรไฟล์ของประสิทธิภาพการทำงานได้โดยไปที่แท็บโปรไฟล์
# Load the TensorBoard notebook extension.
%load_ext tensorboard
โปรไฟล์ประสิทธิภาพสำหรับรุ่นนี้คล้ายกับภาพด้านล่าง
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
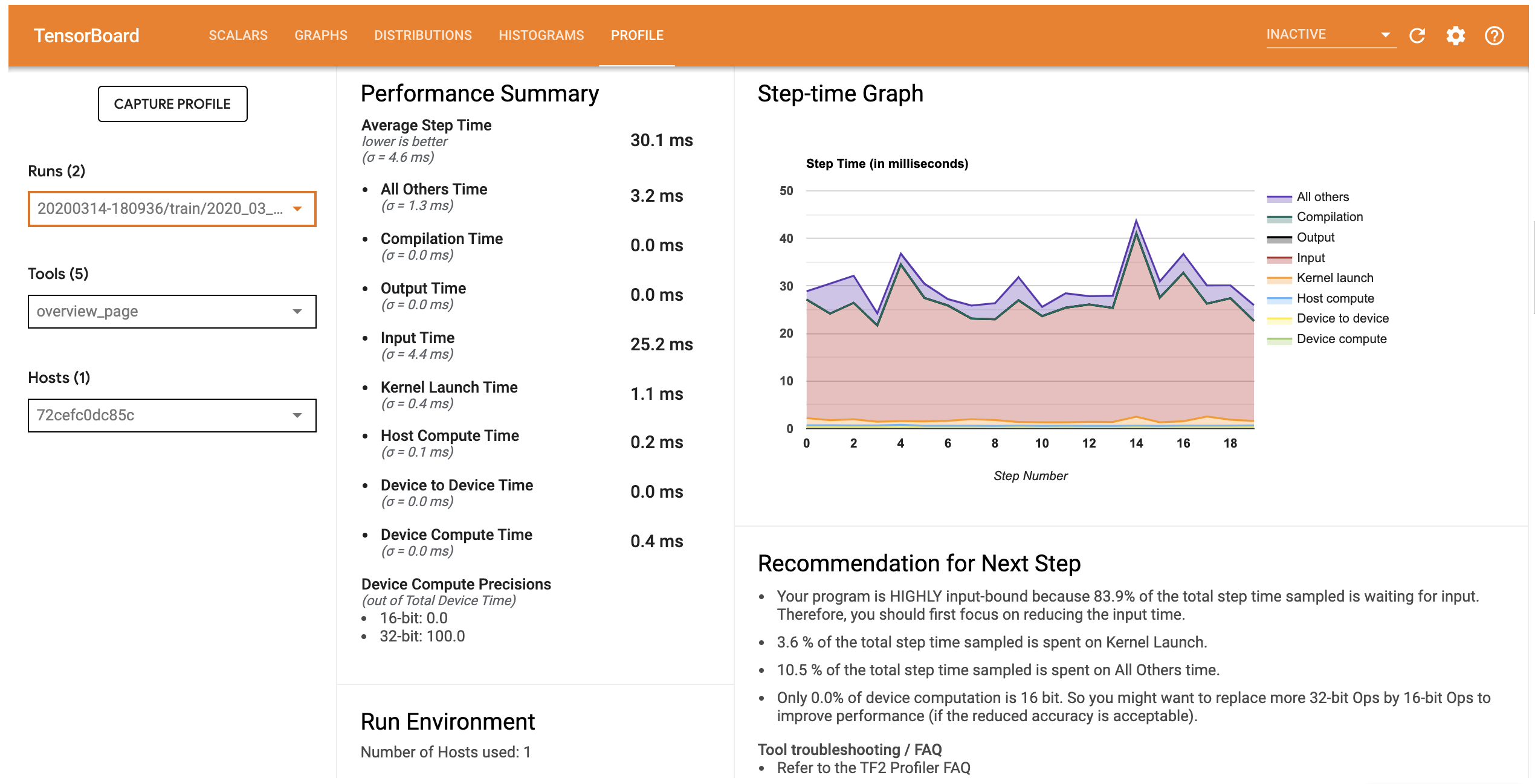
รายละเอียดแท็บเปิดหน้าภาพรวมซึ่งแสดงให้เห็นว่าคุณจะสามารถสรุประดับสูงของประสิทธิภาพการทำงานรูปแบบของคุณ เมื่อดูกราฟขั้นตอนเวลาทางด้านขวา คุณจะเห็นว่าโมเดลมีการเชื่อมโยงอินพุตสูง (กล่าวคือ ใช้เวลามากในไปป์ไลน์การป้อนข้อมูล) หน้าภาพรวมยังให้คำแนะนำเกี่ยวกับขั้นตอนถัดไปที่เป็นไปได้ที่คุณสามารถปฏิบัติตามเพื่อปรับประสิทธิภาพของแบบจำลองของคุณให้เหมาะสมที่สุด
ที่จะเข้าใจว่าขวดประสิทธิภาพเกิดขึ้นในท่อป้อนข้อมูลให้เลือกติดตาม Viewer จากเครื่องมือแบบเลื่อนลงทางด้านซ้าย Trace Viewer จะแสดงไทม์ไลน์ของเหตุการณ์ต่างๆ ที่เกิดขึ้นบน CPU และ GPU ในช่วงระยะเวลาการทำโปรไฟล์
Trace Viewer แสดงกลุ่มเหตุการณ์หลายกลุ่มบนแกนตั้ง แต่ละกลุ่มเหตุการณ์มีแทร็กแนวนอนหลายแทร็ก เต็มไปด้วยเหตุการณ์การติดตาม แทร็กคือไทม์ไลน์ของเหตุการณ์สำหรับเหตุการณ์ที่ดำเนินการบนเธรดหรือสตรีม GPU เหตุการณ์แต่ละรายการคือบล็อกสี่เหลี่ยมสีบนแทร็กไทม์ไลน์ เวลาเคลื่อนจากซ้ายไปขวา นำทางเหตุการณ์ร่องรอยโดยใช้แป้นพิมพ์ลัด W (ซูมเข้า), S (ซูมออก) (เลื่อนไปทางซ้าย) และ A D (เลื่อนจากขวา)
สี่เหลี่ยมผืนผ้าเดียวแสดงถึงเหตุการณ์การติดตาม เลือกไอคอนเคอร์เซอร์ของเมาส์ในแถบเครื่องมือลอย (หรือใช้แป้นพิมพ์ลัด 1 ) และคลิกเหตุการณ์ร่องรอยในการวิเคราะห์มัน ซึ่งจะแสดงข้อมูลเกี่ยวกับกิจกรรม เช่น เวลาเริ่มต้นและระยะเวลา
นอกจากการคลิกแล้ว คุณยังสามารถลากเมาส์เพื่อเลือกกลุ่มของเหตุการณ์การติดตามได้ สิ่งนี้จะให้รายการกิจกรรมทั้งหมดในพื้นที่นั้นพร้อมกับสรุปกิจกรรม ใช้ M กุญแจสำคัญในการวัดระยะเวลาของเหตุการณ์ที่เลือก
เหตุการณ์การติดตามถูกรวบรวมจาก:
- CPU: CPU เหตุการณ์จะปรากฏอยู่ภายใต้กลุ่มเหตุการณ์ที่มีชื่อ
/host:CPUแต่ละแทร็กแสดงถึงเธรดบน CPU เหตุการณ์ CPU รวมถึงเหตุการณ์ไปป์ไลน์อินพุต เหตุการณ์การตั้งเวลาการทำงานของ GPU (op) เหตุการณ์การดำเนินการ CPU op เป็นต้น - GPU: เหตุการณ์ GPU จะปรากฏอยู่ภายใต้กลุ่มเหตุการณ์นำหน้าด้วย
/device:GPU:แต่ละกลุ่มเหตุการณ์แสดงถึงหนึ่งสตรีมบน GPU
แก้ปัญหาคอขวดด้านประสิทธิภาพ
ใช้ Trace Viewer เพื่อค้นหาคอขวดของประสิทธิภาพในไปป์ไลน์อินพุตของคุณ ภาพด้านล่างเป็นสแนปชอตของโปรไฟล์ประสิทธิภาพ
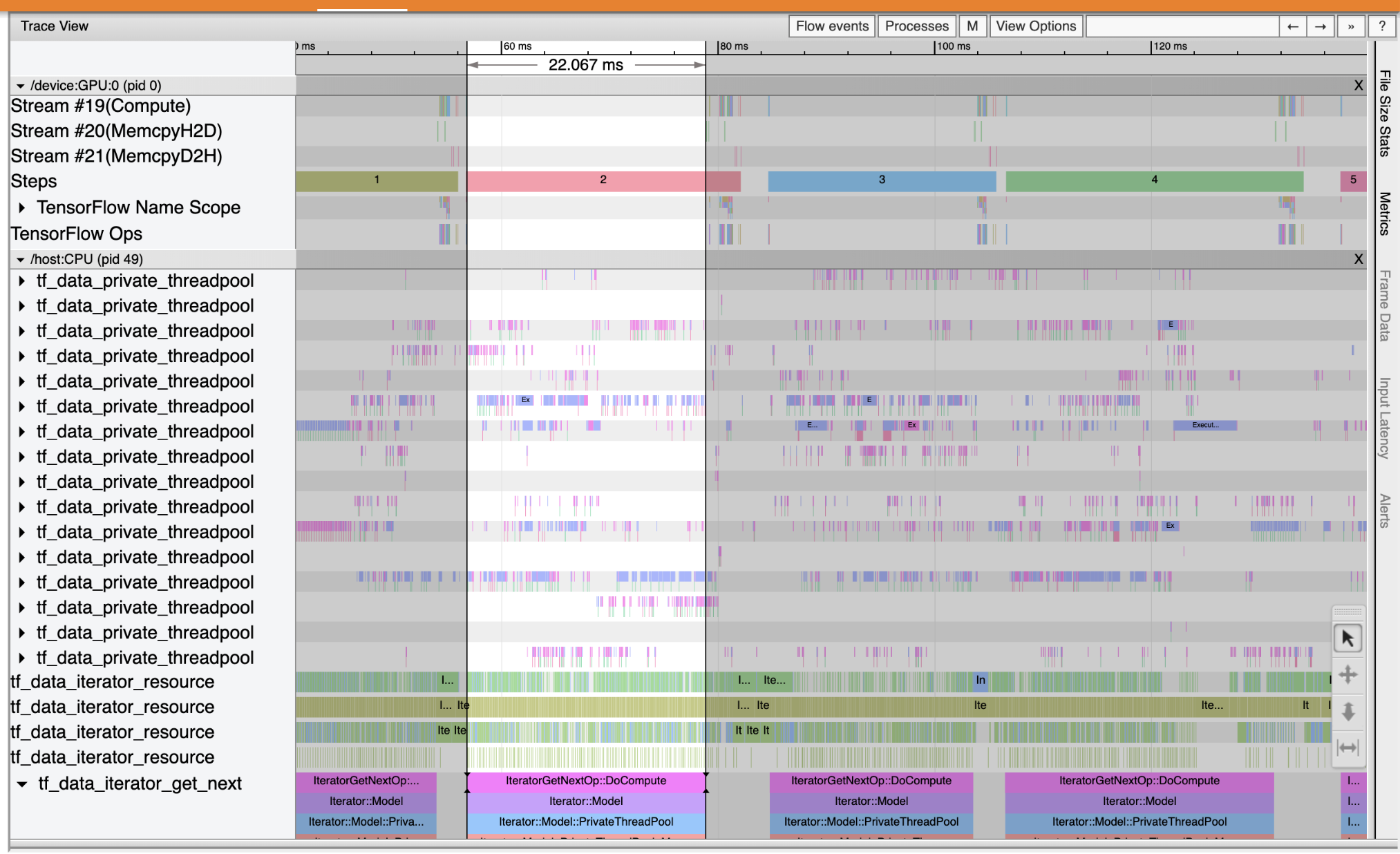
มองไปที่การติดตามเหตุการณ์ที่คุณสามารถเห็นได้ว่า GPU คือไม่ได้ใช้งานในขณะที่ tf_data_iterator_get_next op กำลังทำงานบน CPU op นี้มีหน้าที่ในการประมวลผลข้อมูลที่ป้อนเข้าและส่งไปยัง GPU เพื่อฝึกอบรม ตามหลักการทั่วไป ควรให้อุปกรณ์ (GPU/TPU) ทำงานอยู่เสมอ
ใช้ tf.data API เพื่อเพิ่มประสิทธิภาพท่อป้อนข้อมูล ในกรณีนี้ ให้แคชชุดข้อมูลการฝึกและดึงข้อมูลล่วงหน้าเพื่อให้แน่ใจว่ามีข้อมูลสำหรับ GPU ในการประมวลผลอยู่เสมอ ดู ที่นี่ สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับการใช้ tf.data เพื่อเพิ่มประสิทธิภาพท่อป้อนข้อมูลของคุณ
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
ฝึกโมเดลอีกครั้งและจับภาพโปรไฟล์ประสิทธิภาพโดยใช้การเรียกกลับจากเมื่อก่อน
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
เปิดตัวเว็บไซต์ใหม่ TensorBoard และเปิดรายละเอียดแท็บจะสังเกตเห็นรายละเอียดผลการดำเนินงานสำหรับท่อป้อนข้อมูลการปรับปรุง
โปรไฟล์ประสิทธิภาพสำหรับโมเดลที่มีไปป์ไลน์อินพุตที่ปรับให้เหมาะสมจะคล้ายกับภาพด้านล่าง
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
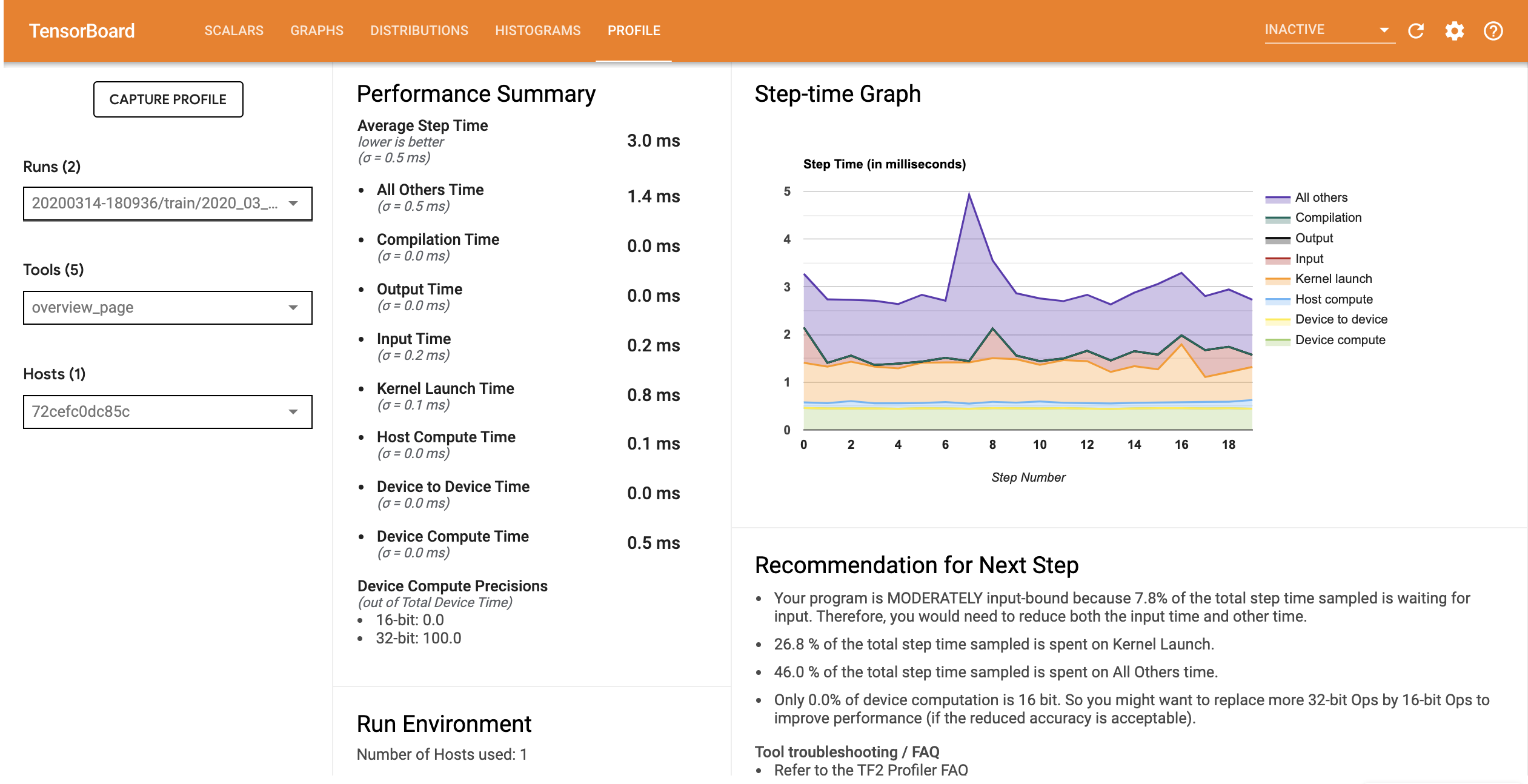
จากหน้าภาพรวม คุณจะเห็นว่าเวลาของขั้นตอนเฉลี่ยลดลงเช่นเดียวกับเวลาของขั้นตอนอินพุต กราฟขั้นตอนเวลายังระบุด้วยว่าโมเดลไม่มีการผูกกับอินพุตอย่างสูงอีกต่อไป เปิด Trace Viewer เพื่อตรวจสอบเหตุการณ์การติดตามด้วยไปป์ไลน์อินพุตที่ปรับให้เหมาะสม
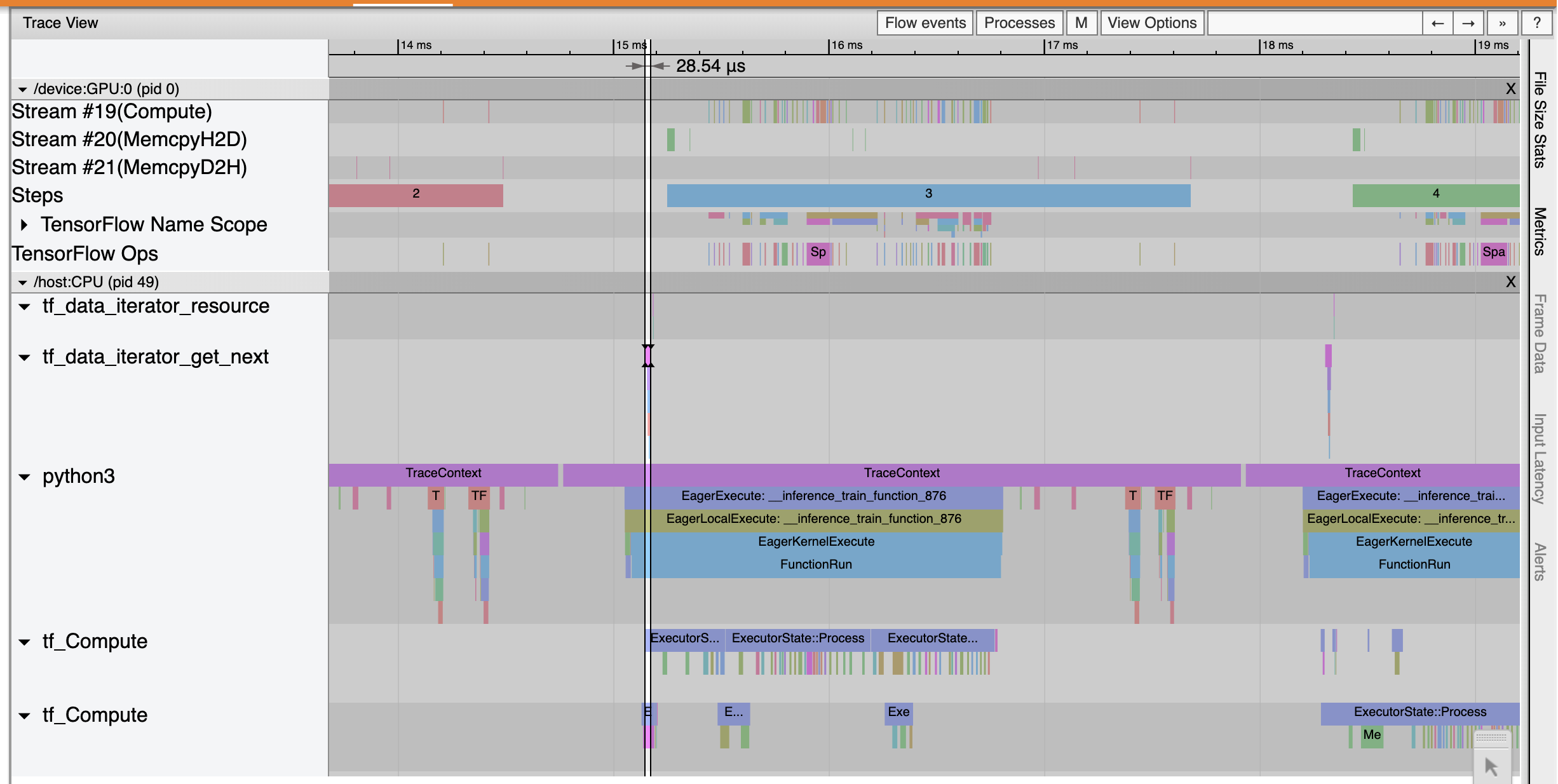
แสดงให้เห็นว่าการติดตามดูว่า tf_data_iterator_get_next สหกรณ์ดำเนินการได้เร็วขึ้นมาก ดังนั้น GPU จึงได้รับกระแสข้อมูลอย่างสม่ำเสมอเพื่อดำเนินการฝึกอบรมและใช้ประโยชน์ได้ดีขึ้นมากผ่านการฝึกโมเดล
สรุป
ใช้ TensorFlow Profiler เพื่อสร้างโปรไฟล์และดีบักประสิทธิภาพการฝึกโมเดล อ่าน คู่มือ Profiler และดู ผลงานของโปรไฟล์ใน TF 2 พูดคุยจาก TensorFlow Dev Summit 2020 ที่จะเรียนรู้เพิ่มเติมเกี่ยวกับ TensorFlow Profiler