
The performance of TensorFlow Serving is highly dependent on the application it runs, the environment in which it is deployed and other software with which it shares access to the underlying hardware resources. As such, tuning its performance is somewhat case-dependent and there are very few universal rules that are guaranteed to yield optimal performance in all settings. With that said, this document aims to capture some general principles and best practices for running TensorFlow Serving.
Please use the Profile Inference Requests with TensorBoard guide to understand the underlying behavior of your model's computation on inference requests, and use this guide to iteratively improve its performance.
Quick Tips
- Latency of first request is too high? Enable model warmup.
- Interested in higher resource utilization or throughput? Configure batching
Performance Tuning: Objectives and Parameters
When fine-tuning TensorFlow Serving's performance, there are usually 2 types of objectives you may have and 3 groups of parameters to tweak to improve upon those objectives.
Objectives
TensorFlow Serving is an online serving system for machine-learned models. As with many other online serving systems, its primary performance objective is to maximize throughput while keeping tail-latency below certain bounds. Depending on the details and maturity of your application, you may care more about average latency than tail-latency, but some notion of latency and throughput are usually the metrics against which you set performance objectives. Note that we do not discuss availability in this guide as that is more a function of the deployment environment.
Parameters
We can roughly think about 3 groups of parameters whose configuration determines observed performance: 1) the TensorFlow model 2) the inference requests and 3) the server (hardware & binary).
1) The TensorFlow Model
The model defines the computation that TensorFlow Serving will perform upon receiving each incoming request.
Underneath the hood, TensorFlow Serving uses the TensorFlow runtime to do the actual inference on your requests. This means the average latency of serving a request with TensorFlow Serving is usually at least that of doing inference directly with TensorFlow. This means if on a given machine, inference on a single example takes 2 seconds, and you have a sub-second latency target, you need to profile inference requests, understand what TensorFlow ops and sub-graphs of your model contribute most to that latency, and re-design your model with inference latency as a design constraint in mind.
Please note, while the average latency of performing inference with TensorFlow Serving is usually not lower than using TensorFlow directly, where TensorFlow Serving shines is keeping the tail latency down for many clients querying many different models, all while efficiently utilizing the underlying hardware to maximize throughput.
2) The Inference Requests
API Surfaces
TensorFlow Serving has two API surfaces (HTTP and gRPC), both of which implement
the
PredictionService API
(with the exception of the HTTP Server not exposing a MultiInference
endpoint). Both API surfaces are highly tuned and add minimal latency but in
practice, the gRPC surface is observed to be slightly more performant.
API Methods
In general, it is advised to use the Classify and Regress endpoints as they accept tf.Example, which is a higher-level abstraction; however, in rare cases of large (O(Mb)) structured requests, savvy users may find using PredictRequest and directly encoding their Protobuf messages into a TensorProto, and skipping the serialization into and deserialization from tf.Example a source of slight performance gain.
Batch Size
There are two primary ways batching can help your performance. You may configure your clients to send batched requests to TensorFlow Serving, or you may send individual requests and configure TensorFlow Serving to wait up to a predetermined period of time, and perform inference on all requests that arrive in that period in one batch. Configuring the latter kind of batching allows you to hit TensorFlow Serving at extremely high QPS, while allowing it to sub-linearly scale the compute resources needed to keep up. This is further discussed in the configuration guide and the batching README.
3) The Server (Hardware & Binary)
The TensorFlow Serving binary does fairly precise accounting of the hardware upon which it runs. As such, you should avoid running other compute- or memory-intensive applications on the same machine, especially ones with dynamic resource usage.
As with many other types of workloads, TensorFlow Serving is more efficient when
deployed on fewer, larger (more CPU and RAM) machines (i.e. a Deployment with
a lower replicas in Kubernetes terms). This is due to a better potential for
multi-tenant deployment to utilize the hardware and lower fixed costs (RPC
server, TensorFlow runtime, etc.).
Accelerators
If your host has access to an accelerator, ensure you have implemented your
model to place dense computations on the accelerator - this should be
automatically done if you have used high-level TensorFlow APIs, but if you have
built custom graphs, or want to pin specific parts of graphs on specific
accelerators, you may need to manually place certain subgraphs on accelerators
(i.e. using with tf.device('/device:GPU:0'): ...).
Modern CPUs
Modern CPUs have continuously extended the x86 instruction set architecture to improve support for SIMD (Single Instruction Multiple Data) and other features critical for dense computations (eg. a multiply and addition in one clock cycle). However, in order to run on slightly older machines, TensorFlow and TensorFlow Serving are built with the modest assumption that the newest of these features are not supported by the host CPU.
Your CPU supports instructions that this TensorFlow binary was not compiled to
use: AVX2 FMA
If you see this log entry (possibly different extensions than the 2 listed) at TensorFlow Serving start-up, it means you can rebuild TensorFlow Serving and target your particular host's platform and enjoy better performance. Building TensorFlow Serving from source is relatively easy using Docker and is documented here.
Binary Configuration
TensorFlow Serving offers a number of configuration knobs that govern its
runtime behavior, mostly set through
command-line flags.
Some of these (most notably tensorflow_intra_op_parallelism and
tensorflow_inter_op_parallelism) are passed down to configure the TensorFlow
runtime and are auto-configured, which savvy users may override by doing many
experiments and finding the right configuration for their specific workload and
environment.
Life of a TensorFlow Serving inference request
Let's briefly go through the life of a prototypical example of a TensorFlow Serving inference request to see the journey that a typical request goes through. For our example, we will dive into a Predict Request being received by the 2.0.0 TensorFlow Serving gRPC API surface.
Let's first look at a component-level sequence diagram, and then jump into the code that implements this series of interactions.
Sequence Diagram
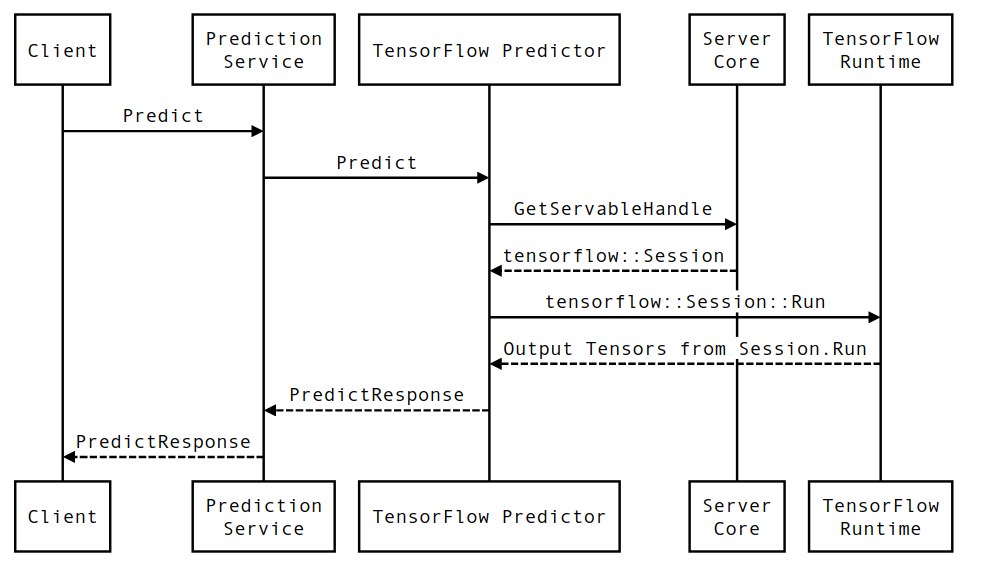
Note that Client is a component owned by the user, Prediction Service, Servables and Server Core are owned by TensorFlow Serving and TensorFlow Runtime is owned by Core TensorFlow.
Sequence Details
PredictionServiceImpl::Predictreceives thePredictRequest- We invoke the
TensorflowPredictor::Predict, propagating the request deadline from the gRPC request (if one was set). - Inside
TensorflowPredictor::Predict, we lookup the Servable (model) the request is looking to perform inference on, from which we retrieve information about the SavedModel and more importantly, a handle to theSessionobject in which the model graph is (possibly partially) loaded. This Servable object was created and committed in memory when the model was loaded by TensorFlow Serving. We then invoke internal::RunPredict to carry out the prediction. - In
internal::RunPredict, after validating and preprocessing the request, we use theSessionobject to perform the inference using a blocking call to Session::Run, at which point, we enter core TensorFlow's codebase. After theSession::Runreturns and ouroutputstensors have been populated, we convert the outputs to aPredictionResponseand return the result up the call stack.