
TensorFlow Serving のパフォーマンスは、実行されるアプリケーション、それがデプロイされる環境、および基盤となるハードウェア リソースへのアクセスを共有する他のソフトウェアに大きく依存します。そのため、パフォーマンスの調整は場合によって多少異なり、すべての設定で最適なパフォーマンスが得られることを保証する普遍的なルールはほとんどありません。そうは言っても、このドキュメントは、TensorFlow Serving を実行するためのいくつかの一般原則とベスト プラクティスを理解することを目的としています。
TensorBoard によるプロファイル推論リクエストガイドを使用して、推論リクエストにおけるモデルの計算の基本的な動作を理解し、このガイドを使用してパフォーマンスを反復的に改善してください。
簡単なヒント
- 最初のリクエストのレイテンシが高すぎますか?モデルのウォームアップを有効にします。
- より高いリソース使用率またはスループットに興味がありますか?バッチ処理の構成
パフォーマンスチューニング: 目標とパラメータ
TensorFlow Serving のパフォーマンスを微調整する場合、通常は 2 種類の目標があり、それらの目標を改善するために調整するパラメータの 3 つのグループがあります。
目的
TensorFlow Serving は、機械学習モデル用のオンライン サービング システムです。他の多くのオンライン サービス システムと同様に、その主なパフォーマンス目標は、テール レイテンシを一定の範囲以下に保ちながらスループットを最大化することです。アプリケーションの詳細と成熟度によっては、 tail-latencyよりも平均レイテンシを重視する場合がありますが、通常はレイテンシとスループットの概念がパフォーマンス目標を設定する基準となります。可用性については展開環境の機能によるものであるため、このガイドでは説明しません。
パラメーター
大まかに、観察されるパフォーマンスを決定する構成の 3 つのパラメータ グループについて考えることができます。1) TensorFlow モデル、2) 推論リクエスト、3) サーバー (ハードウェアおよびバイナリ)。
1) TensorFlow モデル
このモデルは、TensorFlow Serving が各受信リクエストを受信したときに実行する計算を定義します。
内部では、TensorFlow Serving は TensorFlow ランタイムを使用して、リクエストに対して実際の推論を実行します。これは、TensorFlow Serving でリクエストを処理する平均レイテンシは、通常、少なくとも TensorFlow で直接推論を行う場合のレイテンシ以上であることを意味します。これは、特定のマシン上で 1 つの例の推論に 2 秒かかり、レイテンシーを 1 秒未満の目標に設定している場合、推論リクエストをプロファイリングし、そのレイテンシーに最も寄与している TensorFlow 演算とモデルのサブグラフを理解する必要があることを意味します。を設計し、推論レイテンシーを設計上の制約として考慮してモデルを再設計します。
TensorFlow Serving を使用して推論を実行する場合の平均レイテンシーは、通常、TensorFlow を直接使用する場合よりも低くありませんが、TensorFlow Serving が優れている点は、基礎となるハードウェアを効率的に利用してスループットを最大化しながら、多くの異なるモデルをクエリする多くのクライアントのテール レイテンシーを低く抑えることです。 。
2) 推論リクエスト
API サーフェス
TensorFlow Serving には 2 つの API サーフェス (HTTP と gRPC) があり、どちらもPredictionService APIを実装します (HTTP サーバーがMultiInferenceエンドポイントを公開しない点を除く)。どちらの API サーフェスも高度に調整されており、遅延が最小限に抑えられていますが、実際には、gRPC サーフェスのパフォーマンスがわずかに優れていることが観察されています。
APIメソッド
一般に、Classify エンドポイントと Regress エンドポイントは高レベルの抽象化であるtf.Exampleを受け入れるため、これらのエンドポイントを使用することをお勧めします。ただし、大規模な (O(Mb)) 構造化リクエストのまれなケースでは、知識のあるユーザーは、PredictRequest を使用し、Protobuf メッセージを TensorProto に直接エンコードし、tf.Example へのシリアル化と tf.Example からの逆シリアル化をスキップすることが、わずかなパフォーマンス向上の原因であることに気づく場合があります。
バッチサイズ
バッチ処理がパフォーマンスを向上させる主な方法は 2 つあります。バッチ化されたリクエストを TensorFlow Serving に送信するようにクライアントを構成することも、個別のリクエストを送信して、あらかじめ決められた期間まで待機し、その期間内に到着するすべてのリクエストに対して 1 つのバッチで推論を実行するように TensorFlow Serving を構成することもできます。後者の種類のバッチ処理を構成すると、非常に高い QPS で TensorFlow Serving を達成できると同時に、維持するために必要なコンピューティング リソースを準線形にスケールすることができます。これについては、構成ガイドとバッチ処理の READMEで詳しく説明されています。
3) サーバー (ハードウェアとバイナリ)
TensorFlow Serving バイナリは、実行されるハードウェアをかなり正確に計算します。そのため、同じマシン上で他の計算やメモリを大量に消費するアプリケーション、特に動的リソースを使用するアプリケーションを実行しないようにする必要があります。
他の多くのタイプのワークロードと同様に、TensorFlow Serving は、より少数の、より大きな (より多くの CPU と RAM) マシン (つまり、Kubernetes 用語でより少ないreplicasを使用したDeployment ) にデプロイされると、より効率的になります。これは、ハードウェアを利用するマルチテナント展開の可能性が高まり、固定コスト (RPC サーバー、TensorFlow ランタイムなど) が削減されるためです。
アクセラレーター
ホストがアクセラレータにアクセスできる場合は、アクセラレータに高密度の計算を配置するようにモデルを実装していることを確認してください。これは、高レベルの TensorFlow API を使用しているが、カスタム グラフを構築している場合、または固定したい場合には自動的に行われます。グラフの特定の部分を特定のアクセラレータに配置するには、アクセラレータに特定のサブグラフを手動で配置する必要がある場合があります (つまりwith tf.device('/device:GPU:0'): ...使用します)。
最新の CPU
最新の CPU は、 SIMD (単一命令複数データ) や高密度計算に重要なその他の機能 (1 クロック サイクルでの乗算や加算など) のサポートを向上させるために、x86 命令セット アーキテクチャを継続的に拡張してきました。ただし、少し古いマシンで実行するために、TensorFlow と TensorFlow Serving は、これらの機能の最新のものはホスト CPU でサポートされていないという控えめな想定に基づいて構築されています。
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
TensorFlow Serving の起動時にこのログ エントリ (リストされている 2 つとは異なる拡張子である可能性があります) が表示された場合は、TensorFlow Serving を再構築して特定のホストのプラットフォームをターゲットにし、より良いパフォーマンスを享受できることを意味します。 TensorFlow Serving をソースから構築するのは Docker を使用することで比較的簡単であり、ここに文書化されています。
バイナリ構成
TensorFlow Serving は、実行時の動作を制御する多数の構成ノブを提供しており、そのほとんどはコマンドライン フラグを通じて設定されます。これらの一部 (特にtensorflow_intra_op_parallelismとtensorflow_inter_op_parallelism ) は、TensorFlow ランタイムの構成に渡され、自動構成されます。これらは、知識のあるユーザーが多くの実験を行って、特定のワークロードと環境に適した構成を見つけることでオーバーライドできます。
TensorFlow Serving 推論リクエストの寿命
TensorFlow Serving 推論リクエストのプロトタイプの例の動作を簡単に説明し、典型的なリクエストが通過する過程を見てみましょう。この例では、2.0.0 TensorFlow Serving gRPC API サーフェスによって受信される予測リクエストを詳しく見ていきます。
まずコンポーネントレベルのシーケンス図を見て、次にこの一連の対話を実装するコードに移りましょう。
シーケンス図
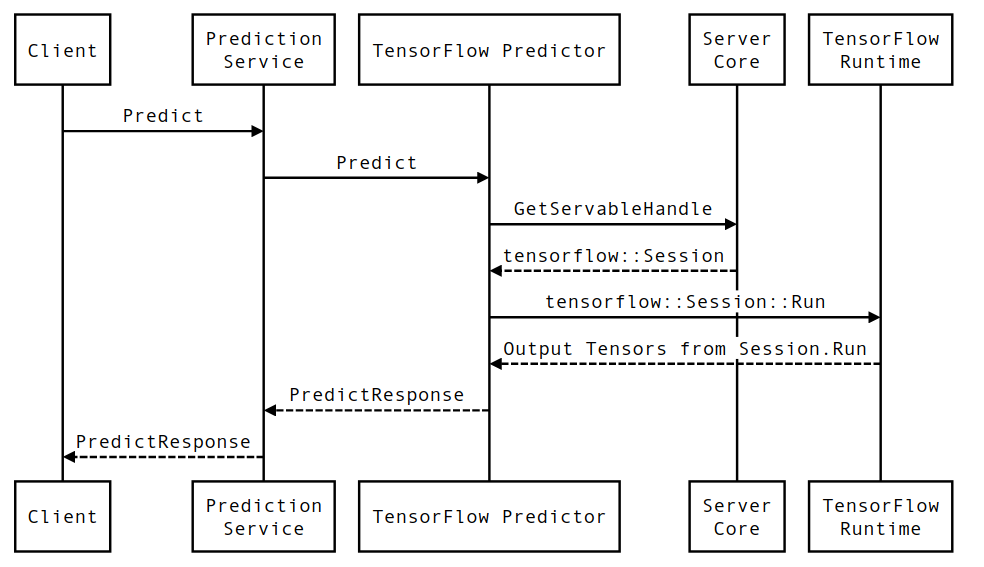
Client はユーザーが所有するコンポーネントであり、Prediction Service、Servables、および Server Core は TensorFlow Serving が所有し、TensorFlow Runtime はCore TensorFlowが所有することに注意してください。
シーケンスの詳細
PredictionServiceImpl::PredictPredictRequestを受け取りますTensorflowPredictor::Predictを呼び出して、gRPC リクエスト (設定されている場合) からリクエストの期限を伝播します。-
TensorflowPredictor::Predict内で、リクエストが推論を実行しようとしているServable (モデル) を検索し、そこから SavedModel に関する情報、そしてより重要なことに、モデル グラフが (おそらく部分的に) 含まれているSessionオブジェクトへのハンドルを取得します。ロードされています。この Servable オブジェクトは、モデルが TensorFlow Serving によってロードされたときにメモリ内に作成され、コミットされました。次に、 internal::RunPredictを呼び出して予測を実行します。 -
internal::RunPredictでは、リクエストを検証して前処理した後、Sessionオブジェクトを使用して、 Session::Runへのブロッキング呼び出しを使用して推論を実行します。その時点で、コア TensorFlow のコードベースに入ります。Session::Runが返され、outputsテンソルが設定された後、出力をPredictionResponseに変換し、結果をコール スタックに返します。