
Un ejemplo de un componente clave de TensorFlow Extended
 Ver fuente en GitHub
Ver fuente en GitHubEste cuaderno de colaboración de ejemplo ilustra cómo se puede usar TensorFlow Data Validation (TFDV) para investigar y visualizar su conjunto de datos. Eso incluye mirar estadísticas descriptivas, inferir un esquema, verificar y corregir anomalías y verificar la deriva y el sesgo en nuestro conjunto de datos. Es importante comprender las características de su conjunto de datos, incluido cómo podría cambiar con el tiempo en su canal de producción. También es importante buscar anomalías en los datos y comparar los conjuntos de datos de capacitación, evaluación y publicación para asegurarse de que sean coherentes.
Usaremos datos del conjunto de datos Taxi Trips publicado por la ciudad de Chicago.
Obtenga más información sobre el conjunto de datos en Google BigQuery . Explore el conjunto de datos completo en la interfaz de usuario de BigQuery .
Las columnas en el conjunto de datos son:
| pickup_community_area | tarifa | viaje_inicio_mes |
| hora_inicio_viaje | viaje_inicio_dia | marca_hora_inicio_viaje |
| recogida_latitud | longitud_de_recogida | dropoff_latitud |
| dropoff_longitude | viaje_millas | pickup_census_tract |
| dropoff_census_tract | tipo de pago | empresa |
| segundos_de_viaje | dropoff_community_area | consejos |
Instalar e importar paquetes
Instale los paquetes para TensorFlow Data Validation.
Actualizar Pip
Para evitar actualizar Pip en un sistema cuando se ejecuta localmente, verifique que se esté ejecutando en Colab. Por supuesto, los sistemas locales se pueden actualizar por separado.
try:
import colab
!pip install --upgrade pip
except:
pass
Instalar paquetes de validación de datos
Instale los paquetes y las dependencias de validación de datos de TensorFlow, lo que lleva unos minutos. Es posible que vea advertencias y errores relacionados con versiones de dependencia incompatibles, que resolverá en la siguiente sección.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
Importar TensorFlow y recargar paquetes actualizados
El paso anterior actualiza los paquetes predeterminados en el entorno de Gooogle Colab, por lo que debe volver a cargar los recursos del paquete para resolver las nuevas dependencias.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Verifique las versiones de TensorFlow y la Validación de datos antes de continuar.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
Cargue el conjunto de datos
Descargaremos nuestro conjunto de datos de Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
Calcular y visualizar estadísticas
Primero, usaremos tfdv.generate_statistics_from_csv para calcular las estadísticas de nuestros datos de entrenamiento. (ignora las advertencias rápidas)
TFDV puede calcular estadísticas descriptivas que brindan una descripción general rápida de los datos en términos de las características que están presentes y las formas de sus distribuciones de valor.
Internamente, TFDV utiliza el marco de procesamiento de datos en paralelo de Apache Beam para escalar el cálculo de estadísticas en grandes conjuntos de datos. Para las aplicaciones que desean integrarse más profundamente con TFDV (por ejemplo, adjuntar la generación de estadísticas al final de una canalización de generación de datos), la API también expone un Beam PTransform para la generación de estadísticas.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
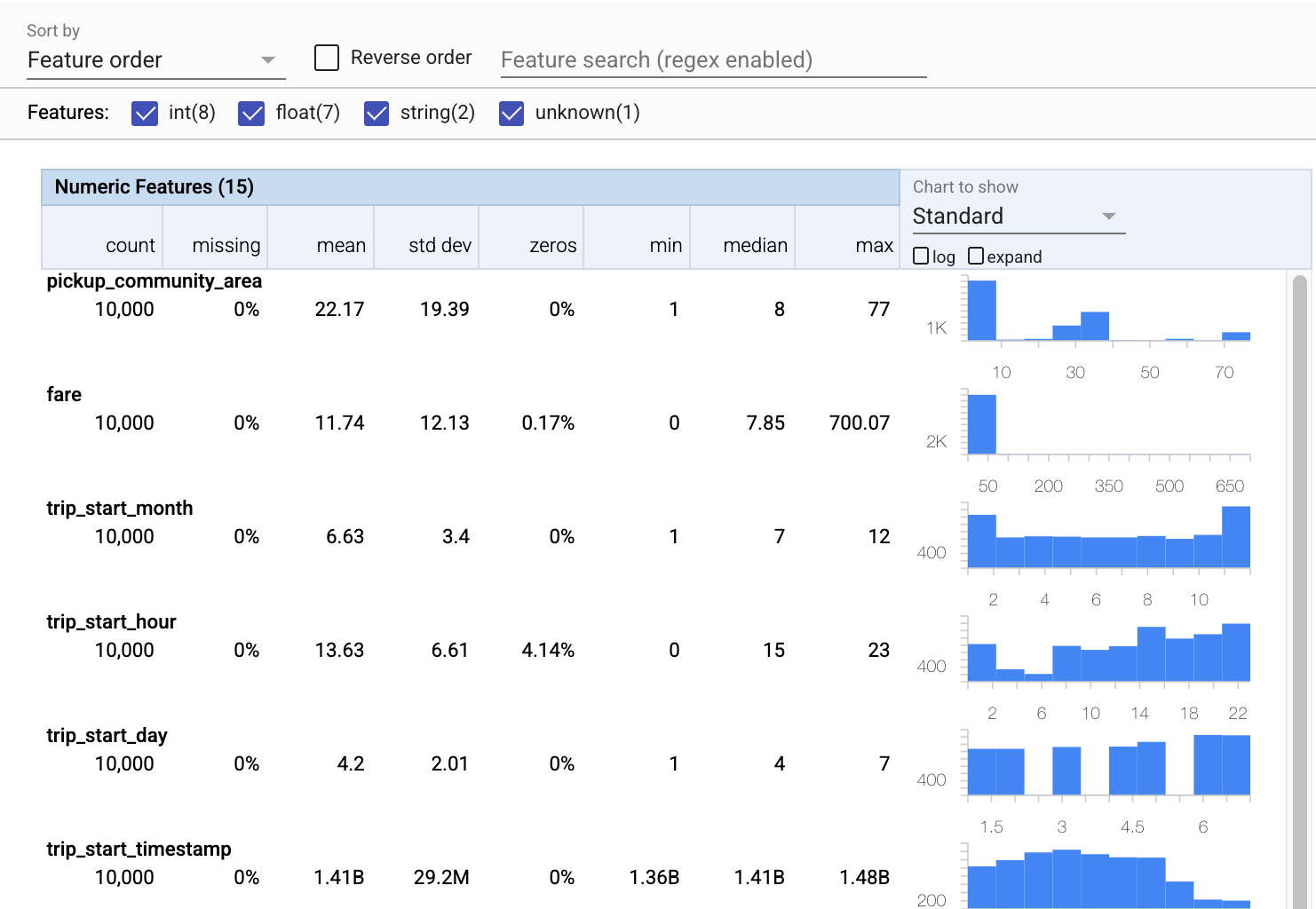
Ahora usemos tfdv.visualize_statistics , que usa facetas para crear una visualización sucinta de nuestros datos de entrenamiento:
- Observe que las características numéricas y las características categóricas se visualizan por separado, y que se muestran gráficos que muestran las distribuciones de cada característica.
- Tenga en cuenta que las funciones con valores faltantes o cero muestran un porcentaje en rojo como indicador visual de que puede haber problemas con los ejemplos en esas funciones. El porcentaje es el porcentaje de ejemplos que tienen valores faltantes o cero para esa característica.
- Tenga en cuenta que no hay ejemplos con valores para
pickup_census_tract. ¡Esta es una oportunidad para la reducción de la dimensionalidad! - Intente hacer clic en "expandir" encima de los gráficos para cambiar la visualización
- Intente pasar el cursor sobre las barras en los gráficos para mostrar los rangos y recuentos de cubos
- Intente cambiar entre las escalas logarítmica y lineal, y observe cómo la escala logarítmica revela muchos más detalles sobre la función categórica
payment_type - Intente seleccionar "cuantiles" en el menú "Gráfico para mostrar" y desplace el cursor sobre los marcadores para mostrar los porcentajes de cuantiles.
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
Inferir un esquema
Ahora usemos tfdv.infer_schema para crear un esquema para nuestros datos. Un esquema define restricciones para los datos que son relevantes para ML. Las restricciones de ejemplo incluyen el tipo de datos de cada característica, ya sea numérica o categórica, o la frecuencia de su presencia en los datos. Para características categóricas, el esquema también define el dominio: la lista de valores aceptables. Dado que escribir un esquema puede ser una tarea tediosa, especialmente para conjuntos de datos con muchas funciones, TFDV proporciona un método para generar una versión inicial del esquema basada en las estadísticas descriptivas.
Obtener el esquema correcto es importante porque el resto de nuestra canalización de producción dependerá del esquema que genere TFDV para que sea correcto. El esquema también proporciona documentación para los datos, por lo que es útil cuando diferentes desarrolladores trabajan en los mismos datos. tfdv.display_schema para mostrar el esquema inferido para que podamos revisarlo.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Comprobar los datos de evaluación en busca de errores
Hasta ahora solo hemos estado mirando los datos de entrenamiento. Es importante que nuestros datos de evaluación sean consistentes con nuestros datos de entrenamiento, incluso que usen el mismo esquema. También es importante que los datos de evaluación incluyan ejemplos de aproximadamente los mismos rangos de valores para nuestras características numéricas que nuestros datos de entrenamiento, de modo que nuestra cobertura de la superficie de pérdida durante la evaluación sea aproximadamente la misma que durante el entrenamiento. Lo mismo es cierto para las características categóricas. De lo contrario, podemos tener problemas de capacitación que no se identifican durante la evaluación, porque no evaluamos parte de nuestra superficie de pérdida.
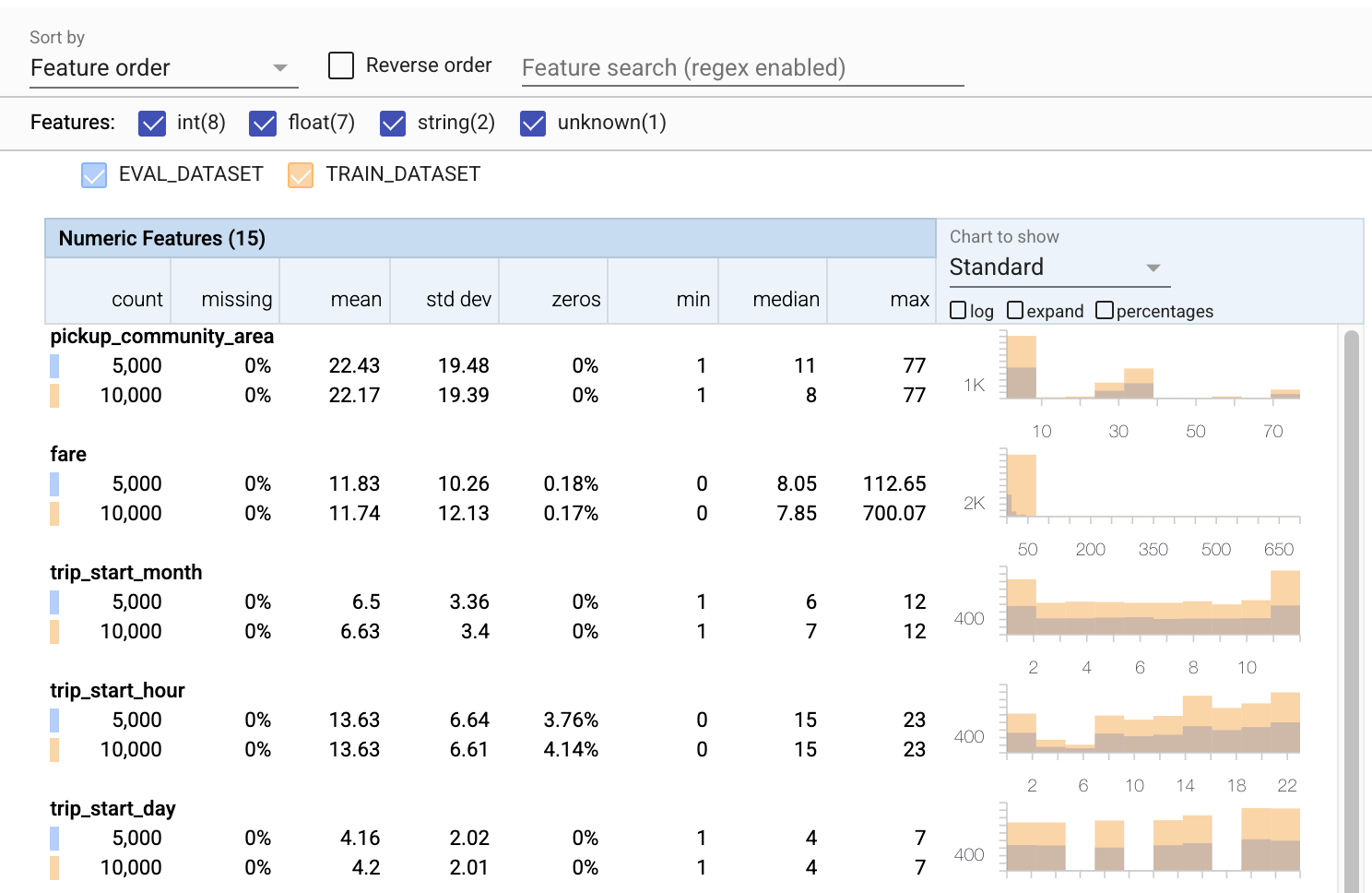
- Tenga en cuenta que cada función ahora incluye estadísticas para los conjuntos de datos de entrenamiento y evaluación.
- Observe que los gráficos ahora tienen superpuestos los conjuntos de datos de entrenamiento y evaluación, lo que facilita compararlos.
- Observe que los gráficos ahora incluyen una vista de porcentajes, que se puede combinar con el registro o las escalas lineales predeterminadas.
- Tenga en cuenta que la media y la mediana de
trip_milesson diferentes para los conjuntos de datos de entrenamiento y evaluación. ¿Eso causará problemas? - Guau, los
tipsmáximos son muy diferentes para los conjuntos de datos de entrenamiento y evaluación. ¿Eso causará problemas? - Haga clic en expandir en el gráfico Características numéricas y seleccione la escala logarítmica. Revise la función
trip_secondsy observe la diferencia en el máx. ¿La evaluación perderá partes de la superficie de pérdida?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
Comprobar anomalías de evaluación
¿Nuestro conjunto de datos de evaluación coincide con el esquema de nuestro conjunto de datos de entrenamiento? Esto es especialmente importante para las características categóricas, donde queremos identificar el rango de valores aceptables.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
Corregir anomalías de evaluación en el esquema.
¡UPS! Parece que tenemos algunos valores nuevos para company en nuestros datos de evaluación, que no teníamos en nuestros datos de entrenamiento. También tenemos un nuevo valor para payment_type . Estos deben considerarse anomalías, pero lo que decidamos hacer al respecto depende de nuestro conocimiento de dominio de los datos. Si una anomalía realmente indica un error de datos, entonces los datos subyacentes deben repararse. De lo contrario, simplemente podemos actualizar el esquema para incluir los valores en el conjunto de datos de evaluación.
A menos que cambiemos nuestro conjunto de datos de evaluación, no podemos arreglar todo, pero podemos arreglar cosas en el esquema que nos sintamos cómodos aceptando. Eso incluye relajar nuestra visión de lo que es y lo que no es una anomalía para características particulares, así como actualizar nuestro esquema para incluir valores faltantes para características categóricas. TFDV nos ha permitido descubrir lo que necesitamos corregir.
Hagamos esas correcciones ahora y luego revisemos una vez más.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
¡Oye, mira eso! ¡Verificamos que los datos de capacitación y evaluación ahora son consistentes! Gracias TFDV ;)
Entornos de esquema
También separamos un conjunto de datos de "servicio" para este ejemplo, por lo que también debemos verificarlo. De manera predeterminada, todos los conjuntos de datos en una canalización deben usar el mismo esquema, pero a menudo hay excepciones. Por ejemplo, en el aprendizaje supervisado necesitamos incluir etiquetas en nuestro conjunto de datos, pero cuando servimos el modelo para la inferencia, las etiquetas no se incluirán. En algunos casos es necesario introducir ligeras variaciones de esquema.
Los entornos se pueden utilizar para expresar dichos requisitos. En particular, las características del esquema se pueden asociar con un conjunto de entornos utilizando default_environment , in_environment y not_in_environment .
Por ejemplo, en este conjunto de datos, la función de tips se incluye como etiqueta para la capacitación, pero falta en los datos de publicación. Sin el entorno especificado, aparecerá como una anomalía.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Nos ocuparemos de la función de tips a continuación. También tenemos un valor INT en nuestros segundos de viaje, donde nuestro esquema esperaba un FLOAT. Al hacernos conscientes de esa diferencia, TFDV ayuda a descubrir inconsistencias en la forma en que se generan los datos para la capacitación y el servicio. Es muy fácil no darse cuenta de problemas como ese hasta que el rendimiento del modelo sufre, a veces de manera catastrófica. Puede o no ser un problema importante, pero en cualquier caso debería ser motivo de una mayor investigación.
En este caso, podemos convertir con seguridad valores INT a FLOAT, por lo que queremos decirle a TFDV que use nuestro esquema para inferir el tipo. Hagamos eso ahora.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Ahora solo tenemos la función de tips (que es nuestra etiqueta) que aparece como una anomalía ("Columna descartada"). Por supuesto, no esperamos tener etiquetas en nuestros datos de publicación, así que digámosle a TFDV que ignore eso.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
Verifique la deriva y el sesgo
Además de verificar si un conjunto de datos se ajusta a las expectativas establecidas en el esquema, TFDV también brinda funcionalidades para detectar derivas y sesgos. TFDV realiza esta verificación comparando las estadísticas de los diferentes conjuntos de datos en función de los comparadores de deriva/sesgo especificados en el esquema.
Deriva
La detección de deriva es compatible con características categóricas y entre tramos de datos consecutivos (es decir, entre el tramo N y el tramo N+1), como entre diferentes días de datos de entrenamiento. Expresamos la desviación en términos de distancia L-infinito , y puede establecer la distancia umbral para recibir advertencias cuando la desviación sea mayor de lo aceptable. Establecer la distancia correcta suele ser un proceso iterativo que requiere conocimiento y experimentación del dominio.
Sesgar
TFDV puede detectar tres tipos diferentes de sesgo en sus datos: sesgo de esquema, sesgo de características y sesgo de distribución.
Sesgo de esquema
El sesgo de esquema ocurre cuando los datos de entrenamiento y servicio no se ajustan al mismo esquema. Se espera que tanto los datos de entrenamiento como los de servicio se adhieran al mismo esquema. Cualquier desviación esperada entre los dos (como que la característica de la etiqueta solo esté presente en los datos de entrenamiento pero no en el servicio) debe especificarse a través del campo de entornos en el esquema.
Característica sesgada
El sesgo de características se produce cuando los valores de características en los que se entrena un modelo son diferentes de los valores de características que ve en el momento de la publicación. Por ejemplo, esto puede suceder cuando:
- Una fuente de datos que proporciona algunos valores de características se modifica entre el entrenamiento y el tiempo de servicio
- Existe una lógica diferente para generar funciones entre el entrenamiento y el servicio. Por ejemplo, si aplica alguna transformación solo en una de las dos rutas de código.
Sesgo de distribución
El sesgo de distribución ocurre cuando la distribución del conjunto de datos de entrenamiento es significativamente diferente de la distribución del conjunto de datos de servicio. Una de las causas clave del sesgo de distribución es el uso de código diferente o fuentes de datos diferentes para generar el conjunto de datos de entrenamiento. Otro motivo es un mecanismo de muestreo defectuoso que elige una submuestra no representativa de los datos de servicio para entrenar.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
En este ejemplo, vemos cierta deriva, pero está muy por debajo del umbral que hemos establecido.
Congelar el esquema
Ahora que el esquema ha sido revisado y curado, lo almacenaremos en un archivo para reflejar su estado "congelado".
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
Cuándo usar TFDV
Es fácil pensar que TFDV solo se aplica al inicio de su proceso de capacitación, como hicimos aquí, pero de hecho tiene muchos usos. Aquí hay algunos más:
- Validación de nuevos datos para la inferencia para asegurarnos de que de repente no comenzamos a recibir malas características
- Validar nuevos datos para la inferencia para asegurarnos de que nuestro modelo se haya entrenado en esa parte de la superficie de decisión.
- Validar nuestros datos después de que los hayamos transformado y realizado la ingeniería de características (probablemente usando TensorFlow Transform ) para asegurarnos de que no hayamos hecho algo mal