
דוגמה לרכיב מפתח של TensorFlow Extended
 צפה במקור ב-GitHub
צפה במקור ב-GitHubמחברת colab לדוגמה זו ממחישה כיצד ניתן להשתמש ב- TensorFlow Data Validation (TFDV) כדי לחקור ולהמחיש את מערך הנתונים שלך. זה כולל הסתכלות על סטטיסטיקה תיאורית, הסקת סכימה, בדיקה ותיקון חריגות ובדיקת סחיפה והטיה במערך הנתונים שלנו. חשוב להבין את המאפיינים של מערך הנתונים שלך, כולל כיצד הוא עשוי להשתנות לאורך זמן בצינור הייצור שלך. חשוב גם לחפש חריגות בנתונים שלך, ולהשוות את מערכי ההדרכה, ההערכה וההגשה שלך כדי לוודא שהם עקביים.
נשתמש בנתונים ממערך הנתונים של Taxi Trips שפרסמה עיריית שיקגו.
קרא עוד על מערך הנתונים ב- Google BigQuery . חקור את מערך הנתונים המלא בממשק המשתמש של BigQuery .
העמודות במערך הנתונים הן:
| אזור_קהילת_איסוף | דמי נסיעה | חודש_תחילת_טיול |
| שעה_התחלה_טיול | יום_התחלה_טיול | trip_start_timestamp |
| pickup_latitude | איסוף_אורך | dropoff_latitude |
| dropoff_longitude | trip_miles | אוסף_מפקד האוכלוסין |
| ערכת_מפקד_הורדה | סוג תשלום | חֶברָה |
| trip_seconds | אזור_קהילת ירידה | טיפים |
התקן ויבוא חבילות
התקן את החבילות עבור TensorFlow Data Validation.
שדרוג פיפ
כדי להימנע משדרוג Pip במערכת בעת הפעלה מקומית, בדוק כדי לוודא שאנו פועלים ב-Colab. ניתן כמובן לשדרג מערכות מקומיות בנפרד.
try:
import colab
!pip install --upgrade pip
except:
pass
התקן חבילות אימות נתונים
התקן את חבילות אימות הנתונים והתלות של TensorFlow, אשר לוקח כמה דקות. ייתכן שתראה אזהרות ושגיאות לגבי גרסאות תלות לא תואמות, אותן תפתור בסעיף הבא.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
ייבא את TensorFlow וטען מחדש חבילות מעודכנות
השלב הקודם מעדכן את חבילות ברירת המחדל בסביבת Google Colab, כך שעליך לטעון מחדש את משאבי החבילה כדי לפתור את התלות החדשה.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
בדוק את הגירסאות של TensorFlow ואת אימות הנתונים לפני שתמשיך.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
טען את מערך הנתונים
נוריד את מערך הנתונים שלנו מ-Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
חישוב והצג סטטיסטיקה
ראשית נשתמש ב- tfdv.generate_statistics_from_csv כדי לחשב נתונים סטטיסטיים עבור נתוני ההדרכה שלנו. (התעלם מהאזהרות המטומטמות)
TFDV יכול לחשב נתונים סטטיסטיים תיאוריים המספקים סקירה מהירה של הנתונים במונחים של התכונות הקיימות והצורות של התפלגויות הערך שלהן.
באופן פנימי, TFDV משתמש במסגרת עיבוד הנתונים המקבילים של Apache Beam כדי להתאים את חישוב הסטטיסטיקה על פני מערכי נתונים גדולים. עבור יישומים המעוניינים להשתלב עמוק יותר עם TFDV (למשל, לצרף יצירת סטטיסטיקה בסוף צינור יצירת נתונים), ה-API גם חושף Beam PTransform להפקת סטטיסטיקות.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
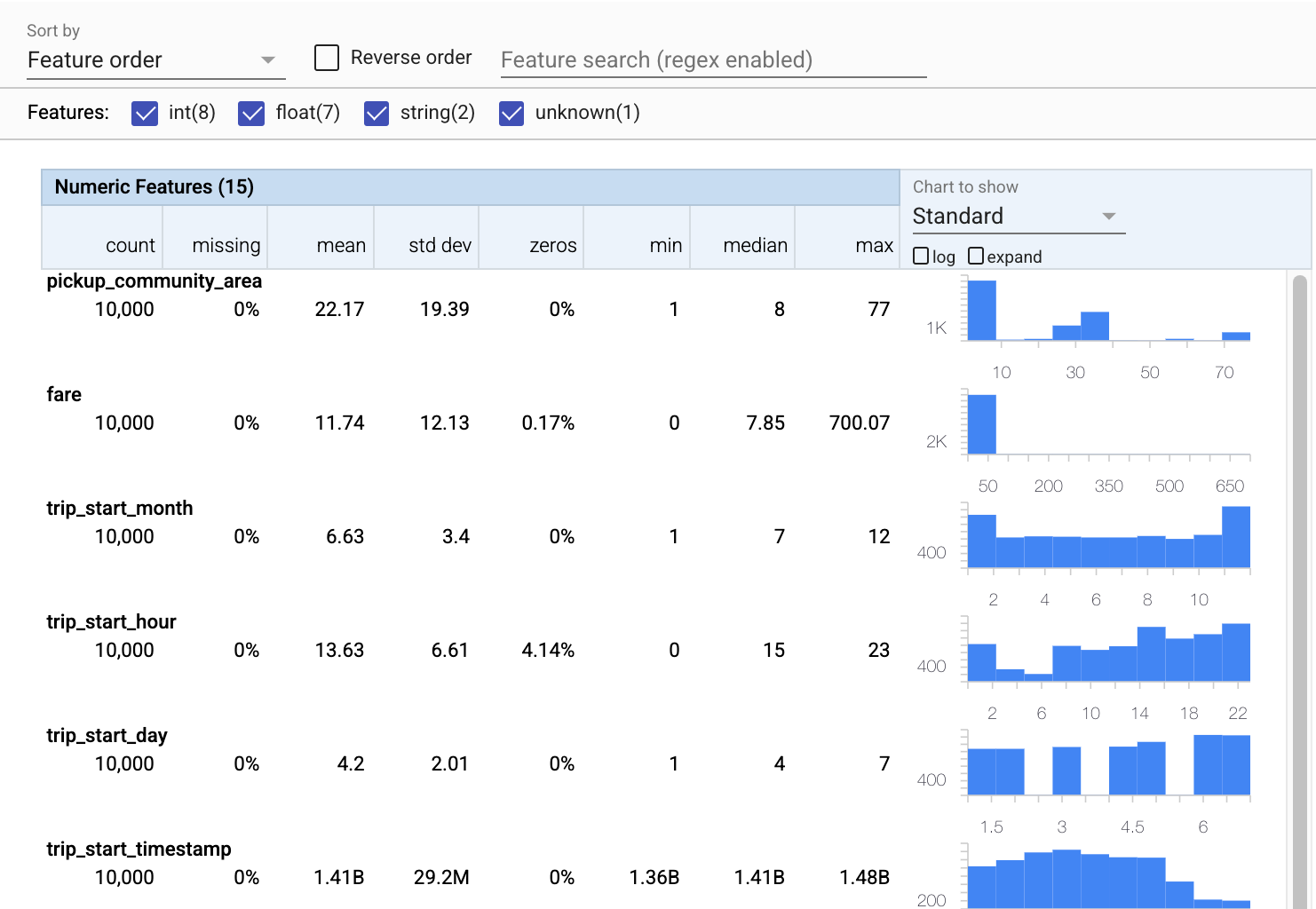
כעת נשתמש ב- tfdv.visualize_statistics , המשתמש ב- Facets כדי ליצור הדמיה תמציתית של נתוני האימון שלנו:
- שימו לב שמאפיינים מספריים ומאפיינים קטגוריים מוצגים בנפרד, ושתרשימים מוצגים המציגים את ההתפלגות של כל תכונה.
- שימו לב שתכונות עם ערכים חסרים או אפס מציגים אחוז באדום כאינדיקטור חזותי לכך שעשויות להיות בעיות עם דוגמאות בתכונות אלו. האחוז הוא אחוז הדוגמאות שיש להן ערכים חסרים או אפס עבור תכונה זו.
- שימו לב שאין דוגמאות עם ערכים עבור
pickup_census_tract. זו הזדמנות להפחתת מימד! - נסה ללחוץ על "הרחב" מעל התרשימים כדי לשנות את התצוגה
- נסה לרחף מעל עמודים בתרשימים כדי להציג טווחים וספירות של דליים
- נסה לעבור בין הסולמות היומן והלינאריות, ושימו לב כיצד קנה המידה של היומן חושף הרבה יותר פרטים על התכונה הקטגורית
payment_type - נסה לבחור "כמויות" מתפריט "תרשים להצגה", ורחף מעל הסמנים כדי להציג את אחוזי הכמות
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
הסיק סכמה
כעת נשתמש ב- tfdv.infer_schema כדי ליצור סכימה עבור הנתונים שלנו. סכימה מגדירה אילוצים עבור הנתונים הרלוונטיים עבור ML. אילוצים לדוגמה כוללים את סוג הנתונים של כל תכונה, בין אם היא מספרית או קטגורית, או את תדירות הנוכחות שלה בנתונים. עבור מאפיינים קטגוריים הסכימה גם מגדירה את התחום - רשימת הערכים המקובלים. מכיוון שכתיבת סכימה יכולה להיות משימה מייגעת, במיוחד עבור מערכי נתונים עם הרבה תכונות, TFDV מספק שיטה ליצור גרסה ראשונית של הסכימה על סמך הנתונים הסטטיסטיים התיאוריים.
קבלת הסכימה נכונה היא חשובה מכיוון ששאר צינור הייצור שלנו יסתמך על הסכימה ש-TFDV מייצר תהיה נכונה. הסכמה מספקת גם תיעוד לנתונים, ולכן שימושית כאשר מפתחים שונים עובדים על אותם נתונים. בוא נשתמש ב- tfdv.display_schema כדי להציג את הסכימה המשוערת כדי שנוכל לסקור אותה.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
בדוק את נתוני ההערכה לאיתור שגיאות
עד כה הסתכלנו רק על נתוני האימונים. חשוב שנתוני ההערכה שלנו יהיו עקביים עם נתוני ההדרכה שלנו, כולל שהם ישתמשו באותה סכימה. חשוב גם שנתוני ההערכה יכללו דוגמאות לאותם טווחי ערכים בערך עבור המאפיינים המספריים שלנו כמו נתוני האימון שלנו, כך שהכיסוי שלנו של משטח האובדן במהלך ההערכה יהיה בערך כמו במהלך האימון. הדבר נכון גם לגבי מאפיינים קטגוריים. אחרת, ייתכן שיש לנו בעיות אימון שאינן מזוהות במהלך ההערכה, מכיוון שלא הערכנו חלק ממשטח ההפסד שלנו.
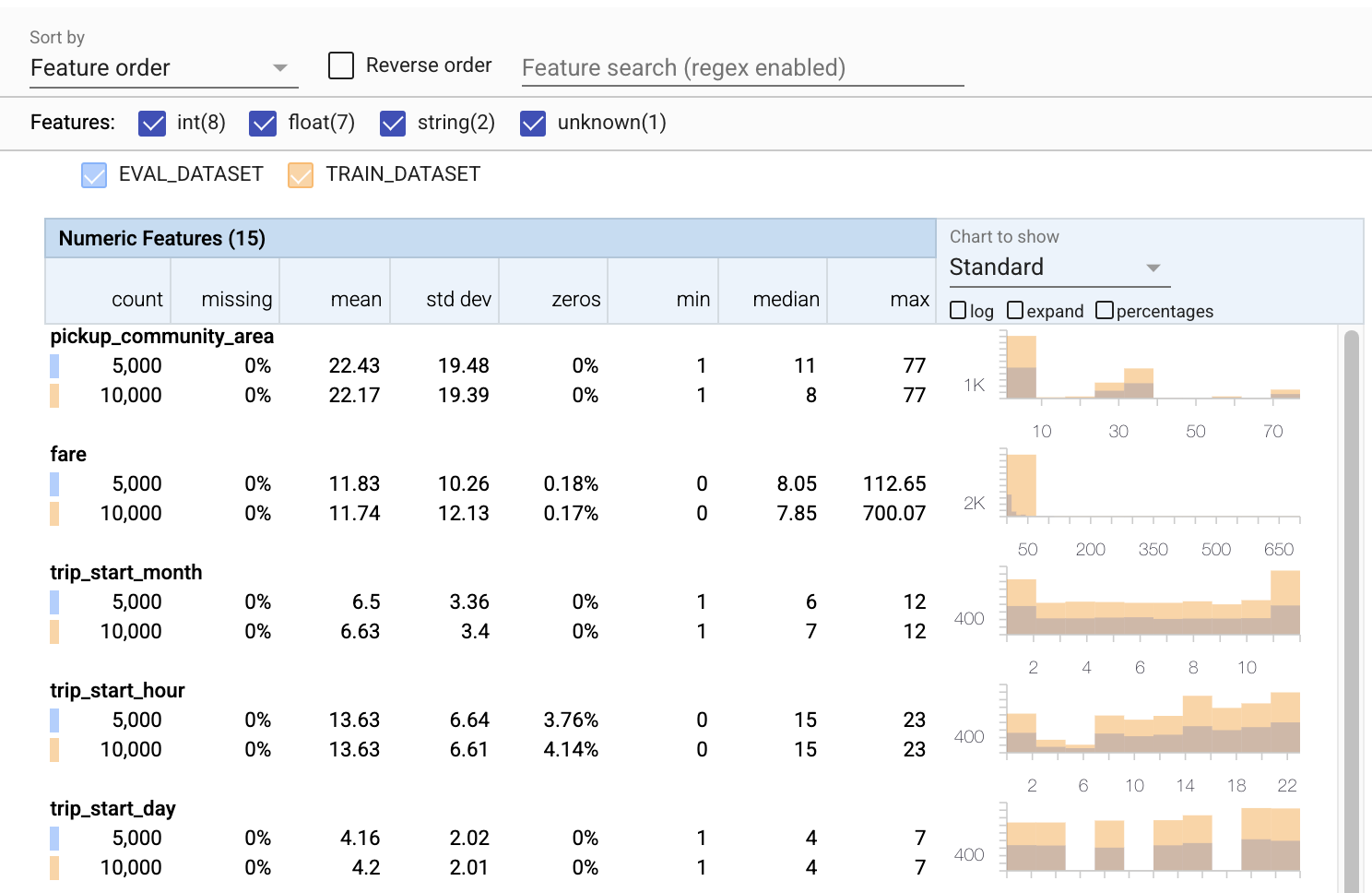
- שימו לב שכל תכונה כוללת כעת נתונים סטטיסטיים עבור מערכי הנתונים של ההדרכה וההערכה.
- שימו לב שהתרשימים כוללים כעת גם את מערכי הנתונים של ההדרכה וגם ההערכה, מה שמקל על ההשוואה ביניהם.
- שימו לב שהתרשימים כוללים כעת תצוגת אחוזים, אותה ניתן לשלב עם יומן או עם קנה המידה הליניארי המוגדר כברירת מחדל.
- שימו לב שהממוצע והחציון עבור
trip_milesשונים עבור האימון לעומת מערכי הנתונים של ההערכה. האם זה יגרום לבעיות? - וואו,
tipsהמקסימליים שונים מאוד עבור ההדרכה לעומת מערכי הנתונים של ההערכה. האם זה יגרום לבעיות? - לחץ על הרחב בתרשים התכונות המספריות, ובחר את סולם היומן. סקור את תכונת
trip_seconds, ושם לב להבדל ב-max. האם הערכה תחמיץ חלקים ממשטח ההפסד?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
בדוק אם יש חריגות בהערכה
האם מערך הנתונים של ההערכה שלנו תואם את הסכימה מתוך מערך ההדרכה שלנו? זה חשוב במיוחד עבור מאפיינים קטגוריים, שבהם אנו רוצים לזהות את טווח הערכים המקובלים.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
תקן חריגות הערכה בסכימה
אופס! נראה שיש לנו כמה ערכים חדשים company בנתוני ההערכה שלנו, שלא היו לנו בנתוני ההדרכה שלנו. יש לנו גם ערך חדש עבור payment_type . אלה צריכים להיחשב חריגים, אבל מה שאנחנו מחליטים לעשות לגביהם תלוי בידע שלנו בתחום הנתונים. אם אנומליה באמת מצביעה על שגיאת נתונים, יש לתקן את הנתונים הבסיסיים. אחרת, נוכל פשוט לעדכן את הסכימה כך שתכלול את הערכים במערך הנתונים eval.
אלא אם כן נשנה את מערך הנתונים של ההערכה שלנו, לא נוכל לתקן הכל, אבל נוכל לתקן דברים בסכמה שנוח לנו לקבל. זה כולל הרגעת ההשקפה שלנו לגבי מה יש ומה אינו אנומליה עבור תכונות מסוימות, כמו גם עדכון הסכמה שלנו כך שתכלול ערכים חסרים עבור מאפיינים קטגוריים. TFDV אפשרה לנו לגלות מה אנחנו צריכים לתקן.
בוא נעשה את התיקונים האלה עכשיו, ואז נבדוק פעם נוספת.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
היי, תראה את זה! וידאנו שנתוני ההדרכה וההערכה עקביים כעת! תודה TFDV ;)
סביבות סכימה
אנחנו גם מפצלים מערך נתונים של 'הגשה' עבור הדוגמה הזו, אז כדאי לבדוק גם את זה. כברירת מחדל, כל מערכי הנתונים בצנרת צריכים להשתמש באותה סכימה, אך לעתים קרובות יש חריגים. לדוגמה, בלמידה מפוקחת עלינו לכלול תוויות במערך הנתונים שלנו, אך כאשר אנו מגישים את המודל להסקת מסקנות, התוויות לא ייכללו. במקרים מסוימים יש צורך להציג שינויים קלים בסכימה.
ניתן להשתמש בסביבות כדי לבטא דרישות כאלה. בפרט, ניתן לשייך תכונות בסכימה לקבוצה של סביבות המשתמשות ב- default_environment , in_environment ו- not_in_environment .
לדוגמה, במערך הנתונים הזה תכונת tips כלולה כתווית לאימון, אך היא חסרה בנתוני ההגשה. ללא ציון סביבה, זה יופיע כאנומליה.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
נעסוק בתכונת tips שלהלן. יש לנו גם ערך INT בשניות הנסיעה שלנו, כאשר הסכימה שלנו ציפתה ל-FLOAT. על ידי כך שאנו מודעים להבדל הזה, TFDV עוזרת לחשוף חוסר עקביות באופן שבו הנתונים נוצרים לצורך הדרכה והגשה. קל מאוד להיות לא מודע לבעיות כאלה עד שביצועי הדגם סובלים, לפעמים בצורה קטסטרופלית. ייתכן שזו בעיה משמעותית או לא, אבל בכל מקרה זו צריכה להיות סיבה לחקירה נוספת.
במקרה זה, אנו יכולים להמיר בבטחה ערכי INT ל- FLOATs, אז אנו רוצים לומר ל-TFDV להשתמש בסכימה שלנו כדי להסיק את הסוג. בוא נעשה את זה עכשיו.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
כעת יש לנו רק את תכונת tips (שהיא התווית שלנו) שמופיעה כאנומליה ('עמודה ירדה'). כמובן שאנחנו לא מצפים שיהיו תוויות בנתוני ההגשה שלנו, אז בואו נגיד ל-TFDV להתעלם מכך.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
בדוק אם יש סחיפה והטיה
בנוסף לבדיקה האם מערך נתונים תואם את הציפיות שנקבעו בסכימה, TFDV מספק גם פונקציונליות לזיהוי סחיפה והטיה. TFDV מבצע בדיקה זו על ידי השוואת הנתונים הסטטיסטיים של מערכי הנתונים השונים בהתבסס על השוואות הסחף/הטייה שצוינו בסכימה.
סְחִיפָה
זיהוי סחיפה נתמך עבור מאפיינים קטגוריים ובין טווחי נתונים עוקבים (כלומר, בין טווח N לטווח N+1), כגון בין ימי אימון שונים. אנו מבטאים סחיפה במונחים של מרחק L-אינסוף , ותוכל להגדיר את מרחק הסף כך שתקבל אזהרות כאשר הסחף גבוה מהמקובל. הגדרת המרחק הנכון היא בדרך כלל תהליך איטרטיבי הדורש ידע וניסוי בתחום.
לְסַלֵף
TFDV יכול לזהות שלושה סוגים שונים של הטיה בנתונים שלך - הטיית סכימה, הטיית תכונה והטיית הפצה.
Schema Skew
הטיית סכימה מתרחשת כאשר נתוני ההדרכה וההגשה אינם תואמים לאותה סכימה. נתוני ההדרכה וההגשה צפויים לעמוד באותה סכימה. יש לציין את כל הסטיות הצפויות בין השניים (כגון שתכונת התווית קיימת רק בנתוני ההדרכה אך לא בהגשה) באמצעות שדה הסביבות בסכימה.
הטיית תכונה
הטיית תכונה מתרחשת כאשר ערכי התכונה שעליהם מתאמן דגם שונים מערכי התכונה שהוא רואה בזמן ההגשה. לדוגמה, זה יכול לקרות כאשר:
- מקור נתונים המספק כמה ערכי תכונה משתנה בין אימון לזמן ההגשה
- יש היגיון שונה ליצירת תכונות בין אימון להגשה. לדוגמה, אם תחיל טרנספורמציה כלשהי רק באחד משני נתיבי הקוד.
הטיית הפצה
הטיית הפצה מתרחשת כאשר התפלגות מערך ההדרכה שונה באופן משמעותי מההפצה של מערך הנתונים המשרתים. אחת הסיבות העיקריות להטיית הפצה היא שימוש בקוד שונה או במקורות נתונים שונים כדי ליצור את מערך ההדרכה. סיבה נוספת היא מנגנון דגימה פגום שבוחר תת-דגימה לא מייצגת של נתוני ההגשה להתאמן עליו.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
בדוגמה זו אנו אכן רואים סחיפה מסוימת, אך היא נמצאת הרבה מתחת לסף שהגדרנו.
הקפאת הסכימה
כעת, לאחר שהסכימה נבדקה ואוצרה, נאחסן אותה בקובץ כדי לשקף את המצב ה"קפוא" שלה.
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
מתי להשתמש ב-TFDV
קל לחשוב על TFDV כחל רק על תחילת צינור האימונים שלך, כפי שעשינו כאן, אבל למעשה יש לו שימושים רבים. הנה עוד כמה:
- אימות נתונים חדשים להסקת מסקנות כדי לוודא שלא התחלנו פתאום לקבל תכונות גרועות
- אימות נתונים חדשים להסקת מסקנות כדי לוודא שהמודל שלנו התאמן על החלק הזה של משטח ההחלטה
- אימות הנתונים שלנו לאחר ששינינו אותם ועשינו הנדסת תכונות (כנראה באמצעות TensorFlow Transform ) כדי לוודא שלא עשינו משהו לא בסדר