
概要
概要
このチュートリアルは、TensorFlow Extended (TFX) と Apache Airflow をオーケストレーターとして使用して、独自の機械学習パイプラインを作成する方法を学習できるように設計されています。 Vertex AI Workbench 上で実行され、TFX および TensorBoard との統合、および Jupyter Lab 環境での TFX との対話を示します。
何をするつもりですか?
TFX を使用して ML パイプラインを作成する方法を学習します。
- TFX パイプラインは有向非巡回グラフ、つまり「DAG」です。パイプラインを DAG と呼ぶこともよくあります。
- TFX パイプラインは、実稼働 ML アプリケーションをデプロイする場合に適しています。
- TFX パイプラインは、データセットが大きい場合、またはデータセットが大きくなる可能性がある場合に適しています。
- TFX パイプラインは、トレーニング/サービスの一貫性が重要な場合に適しています
- TFX パイプラインは、推論のためのバージョン管理が重要な場合に適しています
- Google は本番環境の ML に TFX パイプラインを使用しています
詳細については、 TFX ユーザー ガイドを参照してください。
一般的な ML 開発プロセスに従います。
- データの取り込み、理解、クリーニング
- 特徴量エンジニアリング
- トレーニング
- モデルのパフォーマンスの分析
- 泡立てて、洗い流して、を繰り返す
- 生産準備完了
パイプライン オーケストレーションのための Apache Airflow
TFX オーケストレーターは、パイプラインによって定義された依存関係に基づいて、TFX パイプラインのコンポーネントをスケジュールする責任を負います。 TFX は、複数の環境およびオーケストレーション フレームワークに移植できるように設計されています。 TFX でサポートされるデフォルトのオーケストレーターの 1 つは、 Apache Airflowです。このラボでは、TFX パイプライン オーケストレーションのための Apache Airflow の使用について説明します。 Apache Airflow は、ワークフローをプログラムで作成、スケジュール、監視するためのプラットフォームです。 TFX は、Airflow を使用して、タスクの有向非巡回グラフ (DAG) としてワークフローを作成します。豊富なユーザー インターフェイスにより、実稼働環境で実行されているパイプラインを簡単に視覚化し、進行状況を監視し、必要に応じて問題のトラブルシューティングを行うことができます。 Apache Airflow ワークフローはコードとして定義されます。これにより、メンテナンス性、バージョン管理性、テスト性が向上し、共同作業が容易になります。 Apache Airflow はバッチ処理パイプラインに適しています。軽量で学びやすいです。
この例では、Airflow を手動で設定して、インスタンス上で TFX パイプラインを実行します。
TFX でサポートされる他のデフォルト オーケストレーターは、Apache Beam と Kubeflow です。 Apache Beam は、複数のデータ処理バックエンド (Beam Ruunner) 上で実行できます。 Cloud Dataflow は、TFX パイプラインの実行に使用できるビーム ランナーの 1 つです。 Apache Beam は、ストリーミング パイプラインとバッチ処理パイプラインの両方に使用できます。
Kubeflow は、Kubernetes 上での機械学習 (ML) ワークフローのデプロイメントをシンプル、ポータブル、スケーラブルにすることに特化したオープンソース ML プラットフォームです。 Kubeflow は、TFFX パイプラインを Kubernetes クラスターにデプロイする必要がある場合に、そのパイプラインのオーケストレーターとして使用できます。さらに、独自のカスタム オーケストレーターを使用して TFX パイプラインを実行することもできます。
エアフローの詳細については、こちらをご覧ください。
シカゴのタクシー データセット


シカゴ市がリリースしたTaxi Trips データセットを使用します。
モデルの目標 - 二項分類
顧客のチップは 20% より多くなりますか、それとも少なくなりますか?
Google Cloud プロジェクトのセットアップ
[ラボの開始] ボタンをクリックする前に、次の手順をお読みください。ラボには時間が設定されており、一時停止することはできません。 [ラボを開始] をクリックするとタイマーが開始し、Google Cloud リソースが利用できるようになる時間を示します。
このハンズオン ラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境でラボ アクティビティを自分で行うことができます。これは、ラボの期間中、Google Cloud へのログインとアクセスに使用する新しい一時的な認証情報を提供することによって行われます。
必要なものこのラボを完了するには、次のものが必要です。
- 標準のインターネット ブラウザにアクセスします (Chrome ブラウザを推奨)。
- ラボを完了する時間です。
ラボを開始して Google Cloud コンソールにサインインする方法1. [ラボを開始]ボタンをクリックします。ラボの料金を支払う必要がある場合は、支払い方法を選択するためのポップアップが開きます。左側のパネルには、このラボで使用する必要がある一時的な認証情報が入力されています。
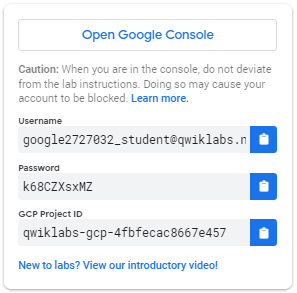
- ユーザー名をコピーし、 [Google コンソールを開く]をクリックします。ラボではリソースが起動され、別のタブが開き、サインインページが表示されます。
ヒント:タブを別のウィンドウで並べて開きます。
- [サインイン]ページで、左側のパネルからコピーしたユーザー名を貼り付けます。次に、パスワードをコピーして貼り付けます。
- 以降のページをクリックして進みます。
- 利用規約に同意します。
回復オプションや 2 要素認証を追加しないでください (これは一時的なアカウントであるため)。
無料トライアルにはサインアップしないでください。
しばらくすると、このタブで Cloud Console が開きます。
クラウドシェルをアクティブ化する
Cloud Shell は、開発ツールがロードされた仮想マシンです。永続的な 5 GB のホーム ディレクトリを提供し、Google Cloud 上で実行されます。 Cloud Shell は、Google Cloud リソースへのコマンドライン アクセスを提供します。
Cloud Console の右上ツールバーで、 「Cloud Shell をアクティブ化」ボタンをクリックします。
[続行] をクリックします。
環境をプロビジョニングして接続するには、少し時間がかかります。接続すると、すでに認証されており、プロジェクトは _PROJECT IDに設定されます。例えば:

gcloud 、Google Cloud のコマンドライン ツールです。 Cloud Shell にプリインストールされており、タブ補完をサポートしています。
次のコマンドを使用して、アクティブなアカウント名を一覧表示できます。
gcloud auth list
(出力)
アクティブ: * アカウント:student-01-xxxxxxxxxxxx@qwiklabs.net アクティブなアカウントを設定するには、次を実行します: $ gcloud config set account
ACCOUNT
次のコマンドを使用してプロジェクト ID を一覧表示できます: gcloud config list project (出力)
[コア]プロジェクト =
(出力例)
[コア] プロジェクト = qwiklabs-gcp-44776a13dea667a6
gcloud の完全なドキュメントについては、 gcloud コマンドライン ツールの概要 を参照してください。
Google Cloud サービスを有効にする
- Cloud Shell で、gcloud を使用して、ラボで使用されるサービスを有効にします。
gcloud services enable notebooks.googleapis.com
Vertex Notebook インスタンスをデプロイする
- ナビゲーション メニューをクリックし、 Vertex AI 、次にWorkbenchに移動します。
[ノートブック インスタンス] ページで、 [新しいノートブック]をクリックします。
[インスタンスのカスタマイズ] メニューで、 [TensorFlow Enterprise]を選択し、 [TensorFlow Enterprise 2.x (LTS)] > [GPU なし]のバージョンを選択します。
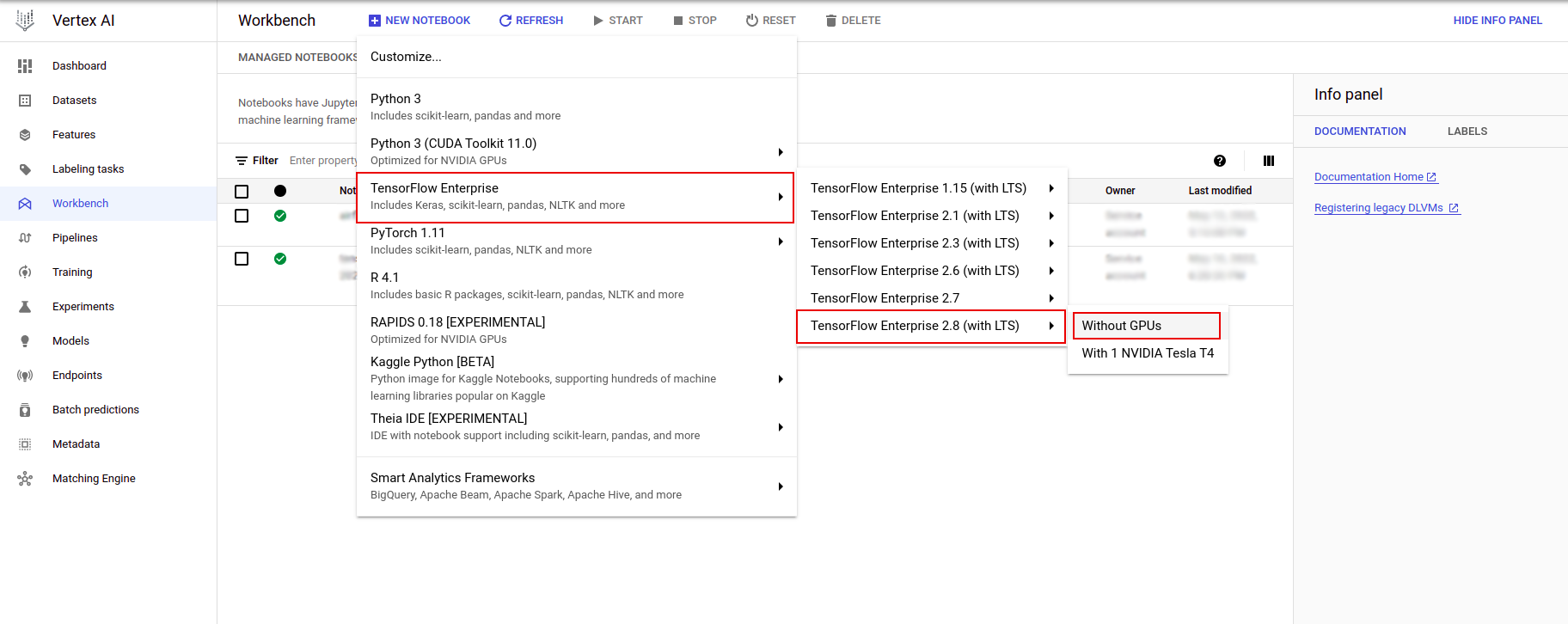
[新しいノートブック インスタンス]ダイアログで、鉛筆アイコンをクリックしてインスタンスのプロパティを編集します。
[インスタンス名]に、インスタンスの名前を入力します。
[Region]で
us-east1を選択し、 [ Zone]で選択したリージョン内のゾーンを選択します。[マシン構成] まで下にスクロールし、[マシン タイプ] として[e2-standard-2]を選択します。
残りのフィールドはデフォルトのままにして、 「作成」をクリックします。
数分後、Vertex AI コンソールにインスタンス名が表示され、続いて[Jupyterlab を開く] が表示されます。
- 「JupyterLab を開く」をクリックします。 JupyterLab ウィンドウが新しいタブで開きます。
環境をセットアップする
ラボ リポジトリのクローンを作成する
次に、JupyterLab インスタンスにtfxリポジトリのクローンを作成します。 1. JupyterLab で、ターミナルアイコンをクリックして新しいターミナルを開きます。
Cancelをクリックします。
-
tfxGithub リポジトリのクローンを作成するには、次のコマンドを入力してEnter を押します。
git clone https://github.com/tensorflow/tfx.git
- リポジトリのクローンを作成したことを確認するには、
tfxディレクトリをダブルクリックし、その内容が表示されることを確認します。
ラボの依存関係をインストールする
- 次のコマンドを実行して
tfx/tfx/examples/airflow_workshop/taxi/setup/フォルダーに移動し、./setup_demo.shを実行してラボの依存関係をインストールします。
cd ~/tfx/tfx/examples/airflow_workshop/taxi/setup/
./setup_demo.sh
上記のコードは、
- 必要なパッケージをインストールします。
- ホームフォルダー内に
airflowフォルダーを作成します。 -
dagsフォルダーをtfx/tfx/examples/airflow_workshop/taxi/setup/フォルダーから~/airflow/フォルダーにコピーします。 - csv ファイルを
tfx/tfx/examples/airflow_workshop/taxi/setup/dataから~/airflow/dataにコピーします。
Airflow サーバーの構成
ブラウザでエアフローサーバーにアクセスするためのファイアウォールルールを作成します
<a href="https://console.cloud.google.com/networking/firewalls/list">https://console.cloud.google.com/networking/firewalls/list</a>にアクセスして、次のことを確認します。プロジェクト名は適切に選択されています- 上部の
CREATE FIREWALL RULEオプションをクリックします。
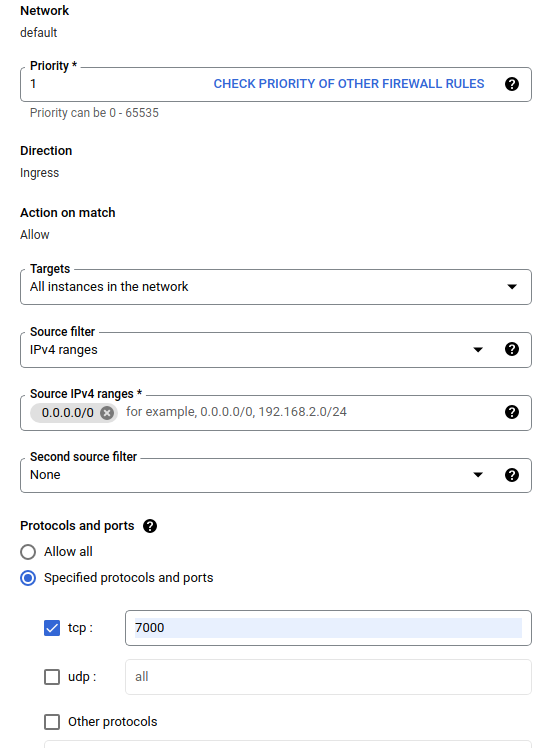
[ファイアウォールの作成] ダイアログで、以下の手順に従います。
- [名前]に、
airflow-tfxと入力します。 - [優先度]で
1選択します。 - [ターゲット]で、
All instances in the networkを選択します。 - [ソース IPv4 範囲]で、
0.0.0.0/0を選択します。 - [プロトコルとポート]で、
tcpをクリックし、tcpの横のボックスに7000と入力します。 -
Createクリックします。
シェルからエアフローサーバーを実行する
Jupyter Lab ターミナル ウィンドウでホーム ディレクトリに変更し、 airflow users createコマンドを実行して Airflow の管理者ユーザーを作成します。
cd
airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin
次に、 airflow webserverとairflow schedulerコマンドを実行してサーバーを実行します。ファイアウォールの通過が許可されているため、ポート7000を選択します。
nohup airflow webserver -p 7000 &> webserver.out &
nohup airflow scheduler &> scheduler.out &
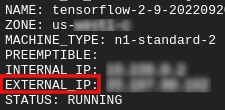
外部 IP を取得します
- Cloud Shell で、
gcloudを使用して外部 IP を取得します。
gcloud compute instances list
DAG/パイプラインの実行
ブラウザで
ブラウザを開いて http:// にアクセスします。
- ログイン ページで、
airflow users createコマンドの実行時に選択したユーザー名 (admin) とパスワード (admin) を入力します。
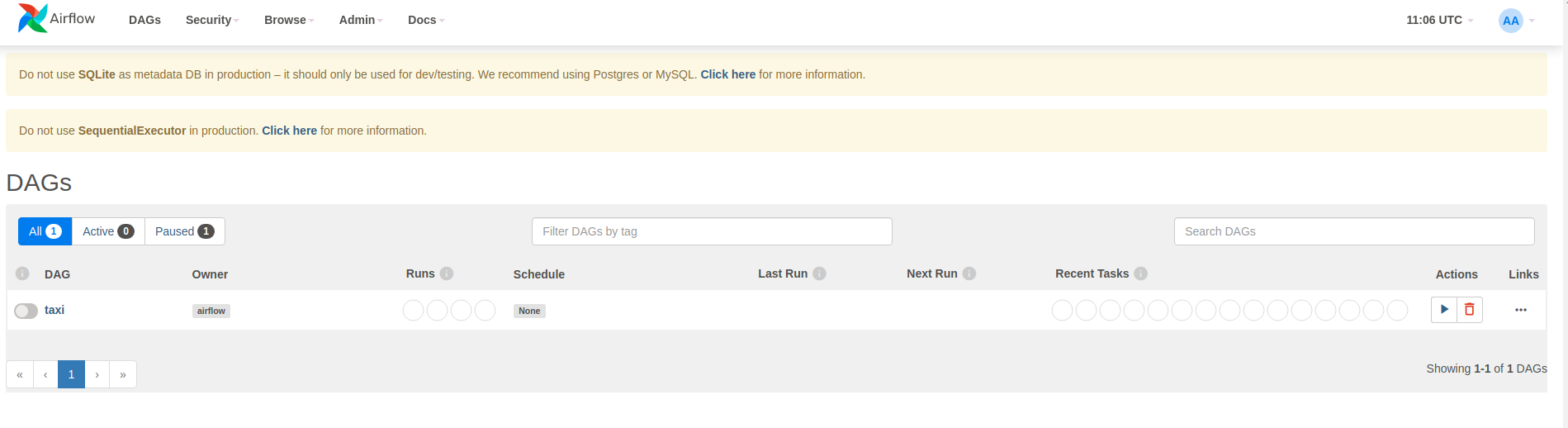
Airflow は、Python ソース ファイルから DAG を読み込みます。各ファイルを取得して実行します。次に、そのファイルから DAG オブジェクトを読み込みます。 DAG オブジェクトを定義するすべての.pyファイルは、airflow ホームページにパイプラインとしてリストされます。
このチュートリアルでは、Airflow は~/airflow/dags/フォルダーで DAG オブジェクトをスキャンします。
~/airflow/dags/taxi_pipeline.pyを開いて一番下までスクロールすると、 DAG オブジェクトが作成され、 DAGという名前の変数に保存されていることがわかります。したがって、以下に示すように、エアフローのホームページにパイプラインとしてリストされます。
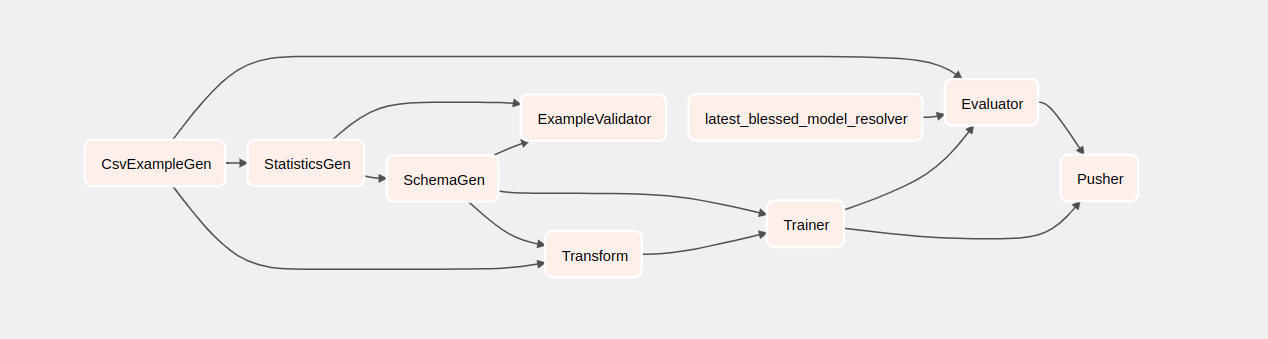
[タクシー] をクリックすると、DAG のグリッド ビューにリダイレクトされます。上部のGraphオプションをクリックすると、DAG のグラフ ビューを取得できます。
タクシー パイプラインをトリガーする
ホームページには、DAG と対話するために使用できるボタンが表示されます。
アクションヘッダーの下で、トリガーボタンをクリックしてパイプラインをトリガーします。
タクシーDAGページで、右側のボタンを使用して、パイプラインの実行中に DAG のグラフ ビューの状態を更新します。さらに、自動更新を有効にして、状態が変化したときにグラフ ビューを自動的に更新するように Airflow に指示できます。
ターミナルでAirflow CLI を使用して、DAG を有効にしてトリガーすることもできます。
# enable/disable
airflow pause <your DAG name>
airflow unpause <your DAG name>
# trigger
airflow trigger_dag <your DAG name>
パイプラインが完了するのを待っています
パイプラインをトリガーした後、DAG ビューで、実行中のパイプラインの進行状況を監視できます。各コンポーネントが実行されると、DAG グラフ内のコンポーネントの輪郭の色が変化してその状態が表示されます。コンポーネントの処理が完了すると、アウトラインが濃い緑色に変わり、処理が完了したことを示します。
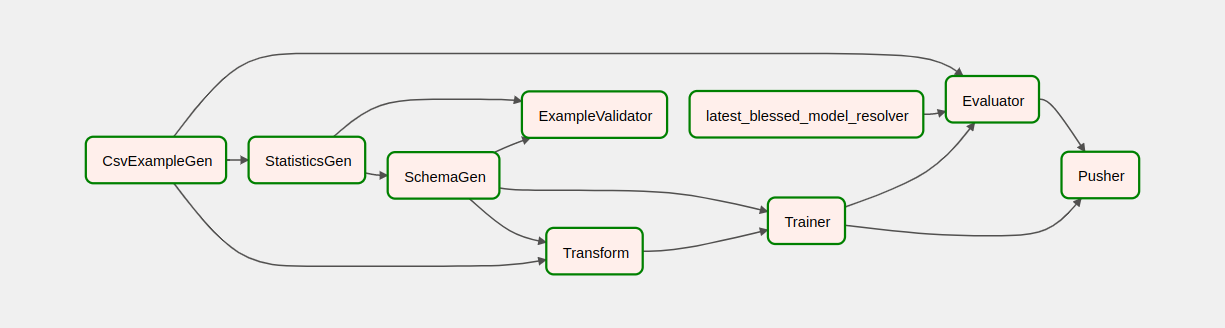
コンポーネントを理解する
次に、このパイプラインのコンポーネントを詳細に見て、パイプラインの各ステップによって生成される出力を個別に見ていきます。
JupyterLab で
~/tfx/tfx/examples/airflow_workshop/taxi/notebooks/に移動します。ノートブック.ipynb を開きます。

ノートブックでラボを続行し、[実行] (
 ) 画面上部のアイコン。あるいは、 SHIFT + ENTERを使用してセル内のコードを実行することもできます。
) 画面上部のアイコン。あるいは、 SHIFT + ENTERを使用してセル内のコードを実行することもできます。
説明を読んで、各細胞で何が起こっているのかを理解してください。