
การแนะนำ
บทช่วยสอนนี้ออกแบบมาเพื่อแนะนำ TensorFlow Extended (TFX) และ AIPlatform Pipelines และช่วยให้คุณเรียนรู้การสร้างไปป์ไลน์ Machine Learning ของคุณเองบน Google Cloud โดยแสดงการผสานรวมกับ TFX, AI Platform Pipelines และ Kubeflow รวมถึงการโต้ตอบกับ TFX ในสมุดบันทึก Jupyter
ในตอนท้ายของบทช่วยสอนนี้ คุณจะได้สร้างและเรียกใช้ ML Pipeline ซึ่งโฮสต์บน Google Cloud คุณจะสามารถเห็นภาพผลลัพธ์ของการวิ่งแต่ละครั้ง และดูเชื้อสายของสิ่งประดิษฐ์ที่สร้างขึ้น
คุณจะปฏิบัติตามกระบวนการพัฒนา ML ทั่วไป โดยเริ่มจากการตรวจสอบชุดข้อมูล และจบลงด้วยขั้นตอนการทำงานที่สมบูรณ์ ตลอดเส้นทาง คุณจะได้สำรวจวิธีแก้ไขข้อบกพร่องและอัปเดตไปป์ไลน์ของคุณ และวัดประสิทธิภาพ
ชุดข้อมูลแท็กซี่ชิคาโก


คุณกำลังใช้ ชุดข้อมูล Taxi Trips ที่เผยแพร่โดยเมืองชิคาโก
คุณสามารถ อ่านเพิ่มเติม เกี่ยวกับชุดข้อมูลใน Google BigQuery สำรวจชุดข้อมูลทั้งหมดใน BigQuery UI
เป้าหมายแบบจำลอง - การจำแนกไบนารี
ลูกค้าจะให้ทิปมากหรือน้อยกว่า 20% หรือไม่?
1. ตั้งค่าโครงการ Google Cloud
1.a ตั้งค่าสภาพแวดล้อมของคุณบน Google Cloud
ในการเริ่มต้น คุณต้องมีบัญชี Google Cloud หากคุณมีอยู่แล้ว ให้ข้ามไปที่ สร้างโครงการใหม่
ไปที่ คอนโซล Google Cloud
ยอมรับข้อกำหนดและเงื่อนไขของ Google Cloud
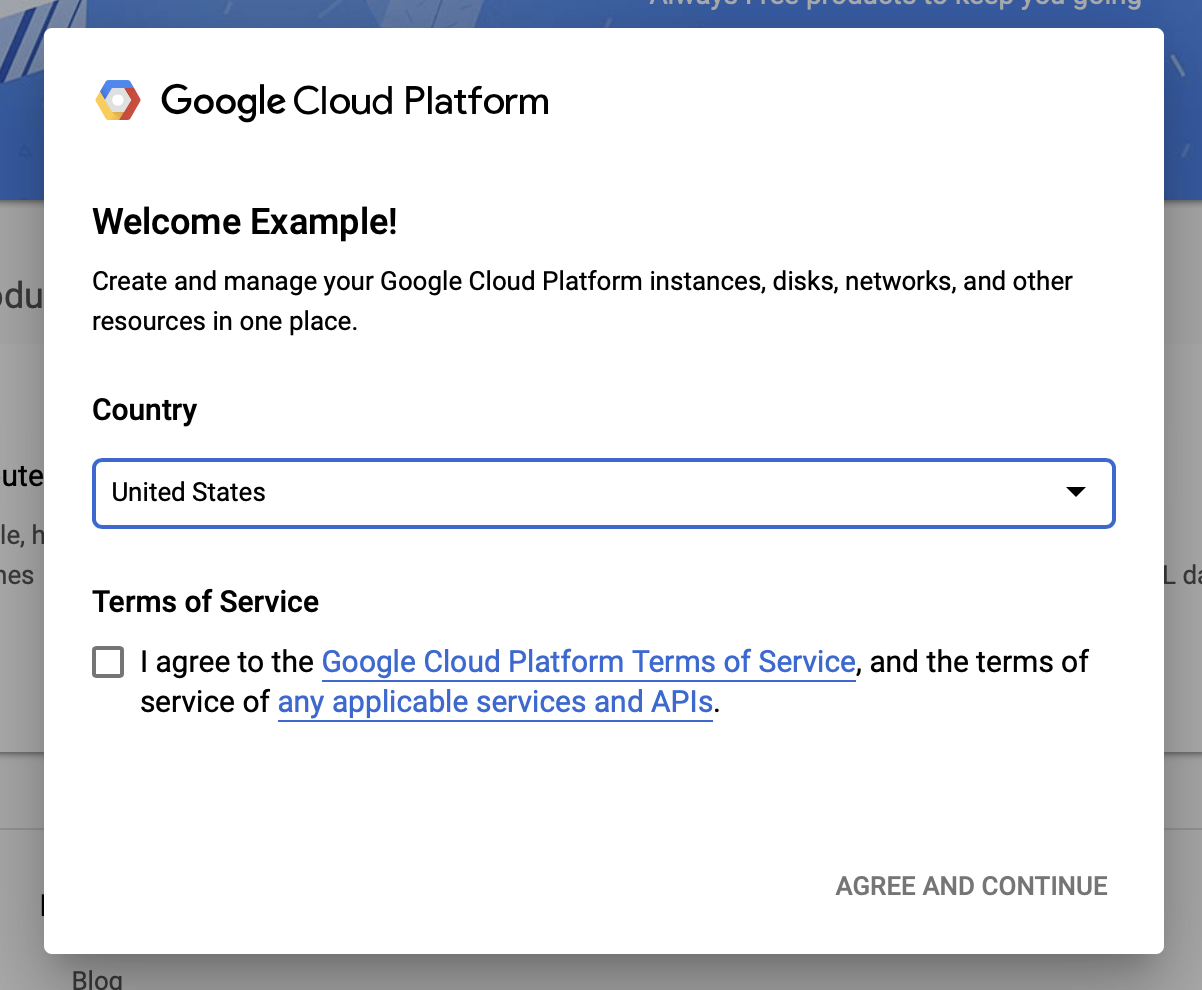
หากคุณต้องการเริ่มต้นด้วยบัญชีทดลองใช้ฟรี ให้คลิกที่ ทดลองใช้ฟรี (หรือ เริ่มต้นใช้งานฟรี )
เลือกประเทศของคุณ
ยอมรับข้อกำหนดในการให้บริการ
ป้อนรายละเอียดการเรียกเก็บเงิน
คุณจะไม่ถูกเรียกเก็บเงิน ณ จุดนี้ หากคุณไม่มีโปรเจ็กต์ Google Cloud อื่นๆ คุณสามารถทำตามบทช่วยสอนนี้ให้เสร็จสิ้นได้โดยไม่เกินขีดจำกัด ของ Google Cloud Free Tier ซึ่งรวมถึงคอร์ที่ทำงานพร้อมกันสูงสุด 8 คอร์
1.b สร้างโครงการใหม่
- จาก แดชบอร์ดหลักของ Google Cloud คลิกเมนูแบบเลื่อนลงโครงการถัดจากส่วนหัว Google Cloud Platform และเลือก โครงการใหม่
- ตั้งชื่อโครงการของคุณและป้อนรายละเอียดโครงการอื่นๆ
- เมื่อคุณสร้างโปรเจ็กต์แล้ว อย่าลืมเลือกจากเมนูดรอปดาวน์โปรเจ็กต์
2. ตั้งค่าและปรับใช้ AI Platform Pipeline บนคลัสเตอร์ Kubernetes ใหม่
ไปที่หน้า คลัสเตอร์ไปป์ไลน์แพลตฟอร์ม AI
ใต้เมนูการนำทางหลัก: ≡ > แพลตฟอร์ม AI > ไปป์ไลน์
คลิก + อินสแตนซ์ใหม่ เพื่อสร้างคลัสเตอร์ใหม่
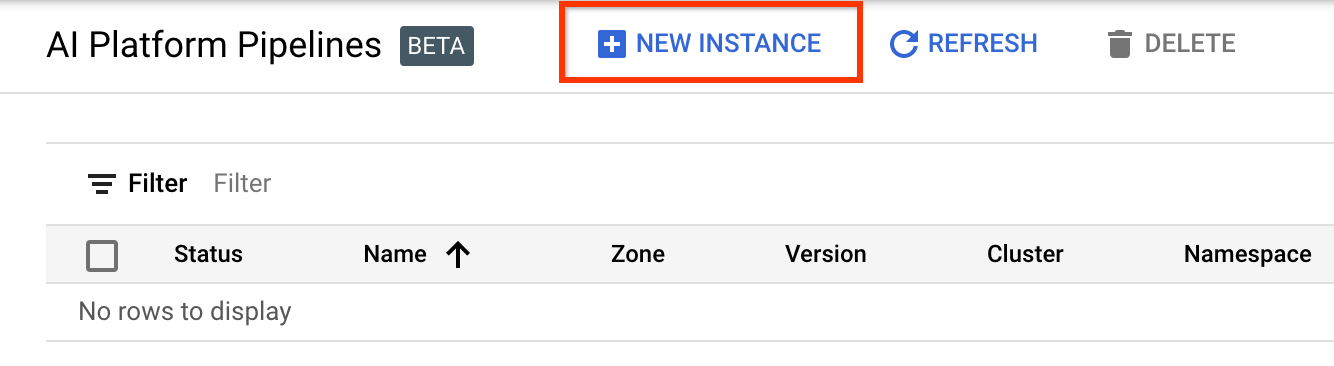
ในหน้าภาพ รวมไปป์ไลน์ Kubeflow คลิก กำหนดค่า

คลิก "เปิดใช้งาน" เพื่อเปิดใช้งาน Kubernetes Engine API
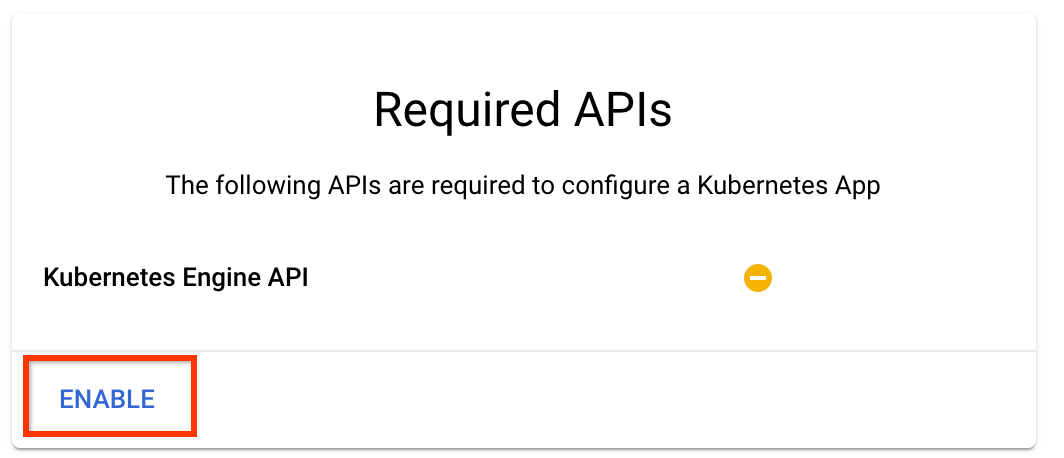
ในหน้า Deploy Kubeflow Pipelines :
เลือก โซน (หรือ "ภูมิภาค") สำหรับคลัสเตอร์ของคุณ สามารถตั้งค่าเครือข่ายและเครือข่ายย่อยได้ แต่สำหรับวัตถุประสงค์ของบทช่วยสอนนี้ เราจะปล่อยให้เป็นค่าเริ่มต้น
สำคัญ ทำเครื่องหมายในช่องที่ระบุว่า อนุญาตให้เข้าถึง Cloud API ต่อไปนี้ (สิ่งนี้จำเป็นสำหรับคลัสเตอร์นี้เพื่อเข้าถึงส่วนอื่นๆ ของโปรเจ็กต์ของคุณ หากคุณพลาดขั้นตอนนี้ การแก้ไขในภายหลังอาจยุ่งยากเล็กน้อย)
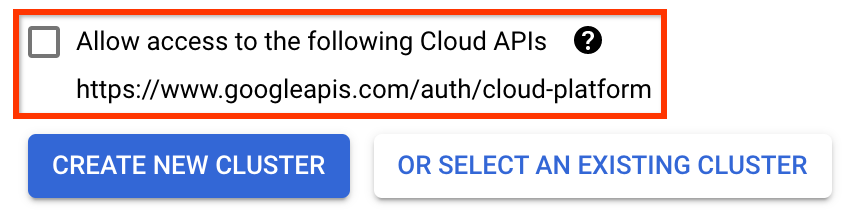
คลิก สร้างคลัสเตอร์ใหม่ และรอสักครู่จนกว่าคลัสเตอร์จะถูกสร้างขึ้น การดำเนินการนี้จะใช้เวลาสักครู่ เมื่อเสร็จแล้วคุณจะเห็นข้อความดังนี้:
สร้างคลัสเตอร์ "cluster-1" ในโซน "us-central1-a" สำเร็จแล้ว
เลือกเนมสเปซและชื่ออินสแตนซ์ (การใช้ค่าเริ่มต้นก็ใช้ได้) เพื่อวัตถุประสงค์ของบทช่วยสอนนี้ อย่าตรวจสอบ executor.emissary หรือ Managedstorage.enabled
คลิก ปรับใช้ และรอสักครู่จนกว่าไปป์ไลน์จะถูกปรับใช้ การปรับใช้ Kubeflow Pipelines แสดงว่าคุณยอมรับข้อกำหนดในการให้บริการ
3. ตั้งค่าอินสแตนซ์สมุดบันทึก Cloud AI Platform
ไปที่หน้า Vertex AI Workbench ครั้งแรกที่คุณรัน Workbench คุณจะต้องเปิดใช้งาน Notebooks API
ใต้เมนูนำทางหลัก: ≡ -> Vertex AI -> Workbench
หากได้รับแจ้ง ให้เปิดใช้งาน Compute Engine API
สร้าง โน้ตบุ๊กใหม่ ที่ติดตั้ง TensorFlow Enterprise 2.7 (หรือสูงกว่า)
โน้ตบุ๊กใหม่ -> TensorFlow Enterprise 2.7 -> ไม่มี GPU
เลือกภูมิภาคและโซน และตั้งชื่ออินสแตนซ์สมุดบันทึก
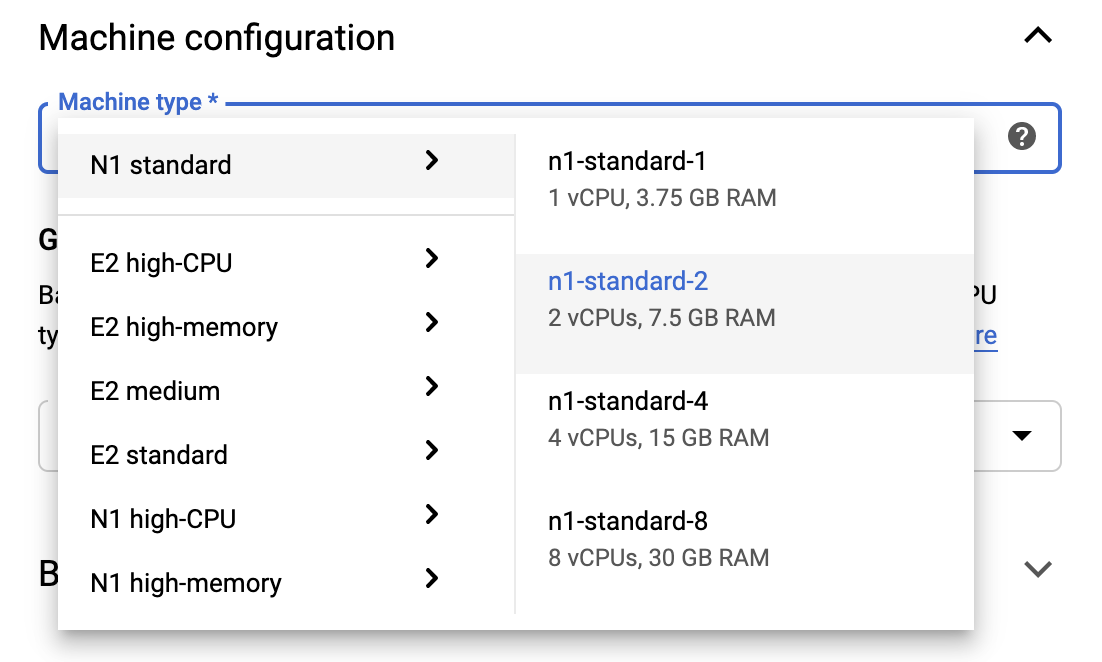
เพื่อให้อยู่ภายในขีดจำกัด Free Tier คุณอาจต้องเปลี่ยนการตั้งค่าเริ่มต้นที่นี่เพื่อลดจำนวน vCPU ที่ใช้ได้กับอินสแตนซ์นี้จาก 4 เป็น 2:
- เลือก ตัวเลือกขั้นสูง ที่ด้านล่างของแบบฟอร์ม สมุดบันทึกใหม่
ภายใต้ การกำหนดค่าเครื่อง คุณอาจต้องการเลือกการกำหนดค่าที่มี 1 หรือ 2 vCPU หากคุณต้องการคงระดับฟรีไว้
รอให้สร้างสมุดบันทึกใหม่ จากนั้นคลิก เปิดใช้งาน Notebooks API
4. เปิดสมุดบันทึกการเริ่มต้นใช้งาน
ไปที่หน้า คลัสเตอร์ไปป์ไลน์แพลตฟอร์ม AI
ใต้เมนูนำทางหลัก: ≡ -> แพลตฟอร์ม AI -> ไปป์ไลน์
บนบรรทัดสำหรับคลัสเตอร์ที่คุณใช้ในบทช่วยสอนนี้ คลิก เปิด Pipelines Dashboard

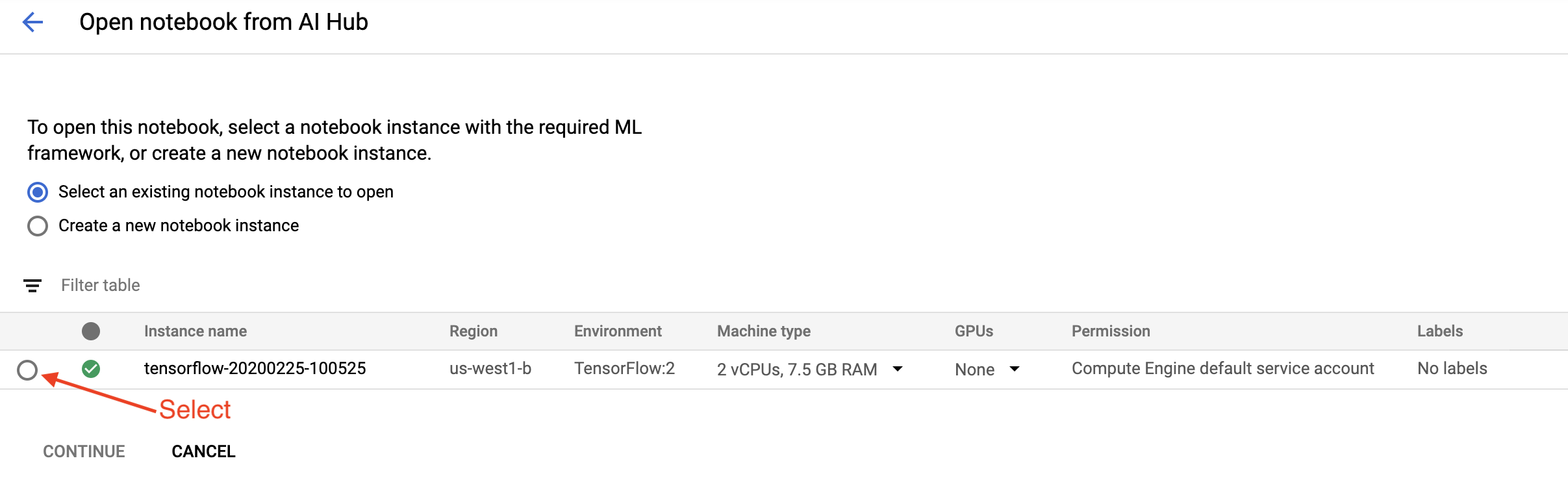
ในหน้า เริ่มต้นใช้งาน คลิก เปิดสมุดบันทึก Cloud AI Platform บน Google Cloud

เลือกอินสแตนซ์ Notebook ที่คุณใช้สำหรับบทช่วยสอนนี้ และ ดำเนินการต่อ จากนั้น ยืนยัน
5. ทำงานใน Notebook ต่อไป
ติดตั้ง
สมุดบันทึกการเริ่มต้นใช้งานเริ่มต้นด้วยการติดตั้ง TFX และ Kubeflow Pipelines (KFP) ลงใน VM ที่ Jupyter Lab กำลังทำงานอยู่
จากนั้นตรวจสอบว่าติดตั้ง TFX เวอร์ชันใด นำเข้า และตั้งค่าและพิมพ์รหัสโปรเจ็กต์:

เชื่อมต่อกับบริการ Google Cloud ของคุณ
การกำหนดค่าไปป์ไลน์ต้องใช้รหัสโปรเจ็กต์ของคุณ ซึ่งคุณสามารถรับผ่านโน้ตบุ๊กและตั้งค่าเป็นตัวแปรสภาพแวดล้อมได้
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
ตอนนี้ตั้งค่าปลายทางคลัสเตอร์ KFP ของคุณ
สามารถพบได้จาก URL ของแดชบอร์ดไปป์ไลน์ ไปที่แดชบอร์ด Kubeflow Pipeline และดูที่ URL ตำแหน่งข้อมูลคือทุกสิ่งใน URL ที่ขึ้นต้นด้วย https:// ไปจนถึง และรวมถึง googleusercontent.com
ENDPOINT='' # Enter YOUR ENDPOINT here.
สมุดบันทึกจะตั้งชื่อที่ไม่ซ้ำสำหรับอิมเมจ Docker แบบกำหนดเอง:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. คัดลอกเทมเพลตลงในไดเรกทอรีโครงการของคุณ
แก้ไขเซลล์สมุดบันทึกถัดไปเพื่อตั้งชื่อไปป์ไลน์ของคุณ ในบทช่วยสอนนี้ เราจะใช้ my_pipeline
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
จากนั้นสมุดบันทึกจะใช้ tfx CLI เพื่อคัดลอกเทมเพลตไปป์ไลน์ บทช่วยสอนนี้ใช้ชุดข้อมูล Chicago Taxi เพื่อดำเนินการจำแนกไบนารี ดังนั้นเทมเพลตจึงตั้งค่าโมเดลเป็น taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
สมุดบันทึกจะเปลี่ยนบริบท CWD เป็นไดเร็กทอรีโครงการ:
%cd {PROJECT_DIR}
เรียกดูไฟล์ไปป์ไลน์
ที่ด้านซ้ายมือของ Cloud AI Platform Notebook คุณจะเห็นไฟล์เบราว์เซอร์ ควรมีไดเร็กทอรีที่มีชื่อไปป์ไลน์ของคุณ ( my_pipeline ) เปิดและดูไฟล์ (คุณจะสามารถเปิดและแก้ไขจากสภาพแวดล้อมสมุดบันทึกได้เช่นกัน)
# You can also list the files from the shellls
คำสั่ง tfx template copy ด้านบนสร้างโครงร่างพื้นฐานของไฟล์ที่สร้างไปป์ไลน์ ซึ่งรวมถึงซอร์สโค้ด Python ข้อมูลตัวอย่าง และสมุดบันทึก Jupyter สิ่งเหล่านี้มีไว้สำหรับตัวอย่างนี้โดยเฉพาะ สำหรับไปป์ไลน์ของคุณเอง ไฟล์เหล่านี้จะเป็นไฟล์สนับสนุนที่ไปป์ไลน์ของคุณต้องการ
นี่คือคำอธิบายโดยย่อของไฟล์ Python
-
pipeline- ไดเร็กทอรีนี้มีคำจำกัดความของไปป์ไลน์-
configs.py— กำหนดค่าคงที่ทั่วไปสำหรับนักวิ่งไปป์ไลน์ -
pipeline.py— กำหนดส่วนประกอบ TFX และไปป์ไลน์
-
-
models- ไดเร็กทอรีนี้มีคำจำกัดความของโมเดล ML-
features.pyfeatures_test.py— กำหนดคุณสมบัติสำหรับโมเดล -
preprocessing.py/preprocessing_test.py- กำหนดงานการประมวลผลล่วงหน้าโดยใช้tf::Transform -
estimator- ไดเร็กทอรีนี้มีโมเดลที่ใช้ตัวประมาณค่า-
constants.py— กำหนดค่าคงที่ของโมเดล -
model.py/model_test.py- กำหนดโมเดล DNN โดยใช้ตัวประมาณค่า TF
-
-
keras- ไดเร็กทอรีนี้มีโมเดลที่ใช้ Keras-
constants.py— กำหนดค่าคงที่ของโมเดล -
model.py/model_test.py- กำหนดโมเดล DNN โดยใช้ Keras
-
-
-
beam_runner.py/kubeflow_runner.py- กำหนดรันเนอร์สำหรับเอ็นจิ้นการเรียบเรียงแต่ละรายการ
7. เรียกใช้ไปป์ไลน์ TFX แรกของคุณบน Kubeflow
โน้ตบุ๊กจะรันไปป์ไลน์โดยใช้คำสั่ง tfx run CLI
เชื่อมต่อกับที่เก็บข้อมูล
การเรียกใช้ไปป์ไลน์จะสร้างอาร์ติแฟกต์ที่ต้องจัดเก็บไว้ใน ML-Metadata อาร์ติแฟกต์หมายถึงเพย์โหลด ซึ่งเป็นไฟล์ที่ต้องจัดเก็บไว้ในระบบไฟล์หรือบล็อกพื้นที่เก็บข้อมูล สำหรับบทแนะนำนี้ เราจะใช้ GCS เพื่อจัดเก็บข้อมูลเพย์โหลดของข้อมูลเมตา โดยใช้ที่เก็บข้อมูลที่สร้างขึ้นโดยอัตโนมัติระหว่างการตั้งค่า ชื่อของมันจะเป็น <your-project-id>-kubeflowpipelines-default
สร้างไปป์ไลน์
สมุดบันทึกจะอัปโหลดข้อมูลตัวอย่างของเราไปยังบัคเก็ต GCS เพื่อให้เรานำไปใช้ในไปป์ไลน์ของเราในภายหลัง
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv สมุดบันทึกจะใช้คำสั่ง tfx pipeline create เพื่อสร้างไปป์ไลน์
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
ขณะสร้างไปป์ไลน์ Dockerfile จะถูกสร้างขึ้นเพื่อสร้างอิมเมจ Docker อย่าลืมเพิ่มไฟล์เหล่านี้ลงในระบบควบคุมแหล่งที่มาของคุณ (เช่น git) พร้อมกับไฟล์ต้นฉบับอื่นๆ
เรียกใช้ไปป์ไลน์
จากนั้นโน้ตบุ๊กจะใช้คำสั่ง tfx run create เพื่อเริ่มดำเนินการเรียกใช้ไปป์ไลน์ของคุณ คุณจะเห็นการดำเนินการนี้แสดงอยู่ในรายการการทดสอบในแดชบอร์ดไปป์ไลน์ของ Kubeflow
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}คุณสามารถดูไปป์ไลน์ของคุณได้จากแดชบอร์ด Kubeflow Pipelines
8. ตรวจสอบข้อมูลของคุณ
งานแรกในวิทยาศาสตร์ข้อมูลหรือโปรเจ็กต์ ML คือการทำความเข้าใจและล้างข้อมูล
- ทำความเข้าใจประเภทข้อมูลสำหรับแต่ละฟีเจอร์
- มองหาความผิดปกติและค่าที่หายไป
- ทำความเข้าใจการแจกแจงของแต่ละฟีเจอร์
ส่วนประกอบ


- ExampleGen นำเข้าและแยกชุดข้อมูลอินพุต
- StatisticsGen คำนวณสถิติสำหรับชุดข้อมูล
- SchemaGen SchemaGen ตรวจสอบสถิติและสร้างสคีมาข้อมูล
- ExampleValidator ค้นหาความผิดปกติและค่าที่หายไปในชุดข้อมูล
ในตัวแก้ไขไฟล์ Jupyter lab:
ใน pipeline pipeline.py ให้ยกเลิกการใส่เครื่องหมายบรรทัดที่ต่อท้ายส่วนประกอบเหล่านี้เข้ากับไปป์ไลน์ของคุณ:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen ถูกเปิดใช้งานแล้วเมื่อมีการคัดลอกไฟล์เทมเพลต)
อัปเดตไปป์ไลน์แล้วรันใหม่
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
ตรวจสอบท่อ
สำหรับ Kubeflow Orchestrator โปรดไปที่แดชบอร์ด KFP และค้นหาเอาต์พุตไปป์ไลน์ในหน้าสำหรับการเรียกใช้ไปป์ไลน์ของคุณ คลิกแท็บ "การทดสอบ" ทางด้านซ้าย และ "การทำงานทั้งหมด" ในหน้าการทดสอบ คุณควรจะสามารถค้นหาการรันด้วยชื่อไปป์ไลน์ของคุณได้
ตัวอย่างขั้นสูงเพิ่มเติม
ตัวอย่างที่นำเสนอนี้มีไว้เพื่อให้คุณเริ่มต้นเท่านั้น สำหรับตัวอย่างขั้นสูง โปรดดู TensorFlow Data Validation Colab
หากต้องการข้อมูลเพิ่มเติมเกี่ยวกับการใช้ TFDV เพื่อสำรวจและตรวจสอบชุดข้อมูล โปรด ดูตัวอย่างที่ tensorflow.org
9. วิศวกรรมคุณสมบัติ
คุณสามารถเพิ่มคุณภาพเชิงคาดการณ์ของข้อมูลและ/หรือลดมิติข้อมูลได้ด้วยวิศวกรรมฟีเจอร์
- คุณสมบัติไม้กางเขน
- คำศัพท์
- การฝัง
- พีซีเอ
- การเข้ารหัสหมวดหมู่
ข้อดีอย่างหนึ่งของการใช้ TFX ก็คือ คุณจะเขียนโค้ดการเปลี่ยนแปลงเพียงครั้งเดียว และการแปลงผลลัพธ์จะสอดคล้องกันระหว่างการฝึกและการให้บริการ
ส่วนประกอบ

- การแปลง ดำเนินการทางวิศวกรรมคุณลักษณะบนชุดข้อมูล
ในตัวแก้ไขไฟล์ Jupyter lab:
ใน pipeline pipeline.py ให้ค้นหาและยกเลิกการใส่เครื่องหมายข้อคิดเห็นบรรทัดที่ต่อท้าย Transform เข้ากับไปป์ไลน์
# components.append(transform)
อัปเดตไปป์ไลน์แล้วรันใหม่
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
ตรวจสอบเอาท์พุตของไปป์ไลน์
สำหรับ Kubeflow Orchestrator โปรดไปที่แดชบอร์ด KFP และค้นหาเอาต์พุตไปป์ไลน์ในหน้าสำหรับการเรียกใช้ไปป์ไลน์ของคุณ คลิกแท็บ "การทดสอบ" ทางด้านซ้าย และ "การทำงานทั้งหมด" ในหน้าการทดสอบ คุณควรจะสามารถค้นหาการรันด้วยชื่อไปป์ไลน์ของคุณได้
ตัวอย่างขั้นสูงเพิ่มเติม
ตัวอย่างที่นำเสนอนี้มีไว้เพื่อให้คุณเริ่มต้นเท่านั้น สำหรับตัวอย่างขั้นสูง โปรดดู TensorFlow Transform Colab
10. การฝึกอบรม
ฝึกฝนโมเดล TensorFlow ด้วยข้อมูลที่ได้รับการแปลงที่สวยงาม สะอาดตา
- รวมการเปลี่ยนแปลงจากขั้นตอนก่อนหน้าเพื่อให้นำไปใช้อย่างสม่ำเสมอ
- บันทึกผลลัพธ์เป็น SavedModel สำหรับการผลิต
- แสดงภาพและสำรวจกระบวนการฝึกอบรมโดยใช้ TensorBoard
- บันทึก EvalSavedModel เพื่อวิเคราะห์ประสิทธิภาพของโมเดลด้วย
ส่วนประกอบ
- เทรนเนอร์ ฝึกโมเดล TensorFlow
ในตัวแก้ไขไฟล์ Jupyter lab:
ใน pipeline pipeline.py ให้ค้นหาและยกเลิกการใส่เครื่องหมายข้อคิดเห็นที่ต่อท้าย Trainer เข้ากับไปป์ไลน์:
# components.append(trainer)
อัปเดตไปป์ไลน์แล้วรันใหม่
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
ตรวจสอบเอาท์พุตของไปป์ไลน์
สำหรับ Kubeflow Orchestrator โปรดไปที่แดชบอร์ด KFP และค้นหาเอาต์พุตไปป์ไลน์ในหน้าสำหรับการเรียกใช้ไปป์ไลน์ของคุณ คลิกแท็บ "การทดสอบ" ทางด้านซ้าย และ "การทำงานทั้งหมด" ในหน้าการทดสอบ คุณควรจะสามารถค้นหาการรันด้วยชื่อไปป์ไลน์ของคุณได้
ตัวอย่างขั้นสูงเพิ่มเติม
ตัวอย่างที่นำเสนอนี้มีไว้เพื่อให้คุณเริ่มต้นเท่านั้น สำหรับตัวอย่างขั้นสูง โปรดดู บทแนะนำ TensorBoard
11. การวิเคราะห์ประสิทธิภาพของโมเดล
ทำความเข้าใจมากกว่าแค่ตัวชี้วัดระดับบนสุด
- ผู้ใช้จะพบกับประสิทธิภาพของโมเดลสำหรับการสืบค้นเท่านั้น
- ประสิทธิภาพที่ไม่ดีในส่วนข้อมูลอาจถูกซ่อนไว้โดยเมตริกระดับบนสุด
- ความเป็นธรรมของแบบจำลองเป็นสิ่งสำคัญ
- บ่อยครั้งที่ชุดย่อยที่สำคัญของผู้ใช้หรือข้อมูลมีความสำคัญมาก และอาจมีขนาดเล็ก
- ประสิทธิภาพในสภาวะวิกฤติแต่ไม่ปกติ
- ประสิทธิภาพสำหรับกลุ่มเป้าหมายหลัก เช่น ผู้มีอิทธิพล
- หากคุณกำลังเปลี่ยนโมเดลที่อยู่ในการผลิตในปัจจุบัน ขั้นแรกตรวจสอบให้แน่ใจว่าโมเดลใหม่ดีกว่า
ส่วนประกอบ
- ผู้ประเมิน ทำการวิเคราะห์ผลการฝึกอบรมเชิงลึก
ในตัวแก้ไขไฟล์ Jupyter lab:
ใน pipeline pipeline.py ค้นหาและยกเลิกการใส่เครื่องหมายข้อคิดเห็นบรรทัดที่ต่อท้าย Evaluator เข้ากับไปป์ไลน์:
components.append(evaluator)
อัปเดตไปป์ไลน์แล้วรันใหม่
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
ตรวจสอบเอาท์พุตของไปป์ไลน์
สำหรับ Kubeflow Orchestrator โปรดไปที่แดชบอร์ด KFP และค้นหาเอาต์พุตไปป์ไลน์ในหน้าสำหรับการเรียกใช้ไปป์ไลน์ของคุณ คลิกแท็บ "การทดสอบ" ทางด้านซ้าย และ "การทำงานทั้งหมด" ในหน้าการทดสอบ คุณควรจะสามารถค้นหาการรันด้วยชื่อไปป์ไลน์ของคุณได้
12. ให้บริการโมเดล
ถ้ารุ่นใหม่พร้อมก็จัดเลย
- Pusher ปรับใช้ SavedModels ไปยังสถานที่ที่มีชื่อเสียง
เป้าหมายการปรับใช้จะได้รับโมเดลใหม่จากสถานที่ที่มีชื่อเสียง
- การแสดง TensorFlow
- TensorFlow Lite
- เทนเซอร์โฟลว์ JS
- ศูนย์กลาง TensorFlow
ส่วนประกอบ
- Pusher ปรับใช้โมเดลกับโครงสร้างพื้นฐานที่ให้บริการ
ในตัวแก้ไขไฟล์ Jupyter lab:
ใน pipeline pipeline.py ค้นหาและยกเลิกการใส่เครื่องหมายข้อคิดเห็นบรรทัดที่ต่อท้าย Pusher เข้ากับไปป์ไลน์:
# components.append(pusher)
ตรวจสอบเอาท์พุตของไปป์ไลน์
สำหรับ Kubeflow Orchestrator โปรดไปที่แดชบอร์ด KFP และค้นหาเอาต์พุตไปป์ไลน์ในหน้าสำหรับการเรียกใช้ไปป์ไลน์ของคุณ คลิกแท็บ "การทดสอบ" ทางด้านซ้าย และ "การทำงานทั้งหมด" ในหน้าการทดสอบ คุณควรจะสามารถค้นหาการรันด้วยชื่อไปป์ไลน์ของคุณได้
เป้าหมายการปรับใช้ที่มีอยู่
ขณะนี้ คุณได้ฝึกฝนและตรวจสอบแบบจำลองของคุณแล้ว และแบบจำลองของคุณก็พร้อมสำหรับการผลิตแล้ว ตอนนี้คุณสามารถปรับใช้โมเดลของคุณกับเป้าหมายการปรับใช้ TensorFlow ใดก็ได้ รวมถึง:
- TensorFlow Serving สำหรับให้บริการโมเดลของคุณบนเซิร์ฟเวอร์หรือเซิร์ฟเวอร์ฟาร์ม และประมวลผลคำขอการอนุมาน REST และ/หรือ gRPC
- TensorFlow Lite สำหรับการรวมโมเดลของคุณในแอปพลิเคชันมือถือแบบเนทีฟของ Android หรือ iOS หรือในแอปพลิเคชัน Raspberry Pi, IoT หรือไมโครคอนโทรลเลอร์
- TensorFlow.js สำหรับการรันโมเดลของคุณในเว็บเบราว์เซอร์หรือแอปพลิเคชัน Node.JS
ตัวอย่างขั้นสูงเพิ่มเติม
ตัวอย่างที่นำเสนอข้างต้นมีไว้เพื่อให้คุณเริ่มต้นเท่านั้น ด้านล่างนี้คือตัวอย่างบางส่วนของการผสานรวมกับบริการคลาวด์อื่นๆ
ข้อควรพิจารณาเกี่ยวกับทรัพยากรของ Kubeflow Pipelines
การกำหนดค่าเริ่มต้นสำหรับการปรับใช้ Kubeflow Pipelines อาจตรงหรือไม่ตรงกับความต้องการของคุณ ทั้งนี้ขึ้นอยู่กับข้อกำหนดของปริมาณงานของคุณ คุณสามารถปรับแต่งการกำหนดค่าทรัพยากรได้โดยใช้ pipeline_operator_funcs ในการเรียก KubeflowDagRunnerConfig
pipeline_operator_funcs คือรายการ OpFunc ซึ่งจะแปลงอินสแตนซ์ ContainerOp ที่สร้างขึ้นทั้งหมดในข้อมูลจำเพาะไปป์ไลน์ KFP ซึ่งคอมไพล์จาก KubeflowDagRunner
ตัวอย่างเช่น ในการกำหนดค่าหน่วยความจำ เราสามารถใช้ set_memory_request เพื่อประกาศจำนวนหน่วยความจำที่ต้องการ วิธีทั่วไปในการทำเช่นนั้นคือการสร้าง wrapper สำหรับ set_memory_request และใช้เพื่อเพิ่มลงในรายการไปป์ไลน์ OpFunc :
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
ฟังก์ชันการกำหนดค่าทรัพยากรที่คล้ายกัน ได้แก่:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
ลองใช้ BigQueryExampleGen
BigQuery เป็นคลังข้อมูลบนระบบคลาวด์แบบไร้เซิร์ฟเวอร์ ปรับขนาดได้สูง และคุ้มต้นทุน BigQuery สามารถใช้เป็นแหล่งที่มาสำหรับตัวอย่างการฝึกใน TFX ได้ ในขั้นตอนนี้ เราจะเพิ่ม BigQueryExampleGen ลงในไปป์ไลน์
ในตัวแก้ไขไฟล์ Jupyter lab:
ดับเบิลคลิกเพื่อเปิด pipeline.py ใส่เครื่องหมายความคิดเห็น CsvExampleGen และยกเลิกการใส่เครื่องหมายบรรทัดที่สร้างอินสแตนซ์ของ BigQueryExampleGen คุณต้องยกเลิกหมายเหตุอาร์กิวเมนต์ query ของฟังก์ชัน create_pipeline ด้วย
เราจำเป็นต้องระบุโปรเจ็กต์ GCP ที่จะใช้สำหรับ BigQuery และทำได้โดยการตั้งค่า --project ใน beam_pipeline_args เมื่อสร้างไปป์ไลน์
ดับเบิลคลิกเพื่อเปิด configs.py ยกเลิกหมายเหตุคำจำกัดความของ BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS และ BIG_QUERY_QUERY คุณควรแทนที่รหัสโปรเจ็กต์และค่าภูมิภาคในไฟล์นี้ด้วยค่าที่ถูกต้องสำหรับโปรเจ็กต์ GCP
เปลี่ยนไดเร็กทอรีขึ้นไปหนึ่งระดับ คลิกชื่อไดเร็กทอรีเหนือรายการไฟล์ ชื่อของไดเร็กทอรีคือชื่อของไปป์ไลน์ซึ่งเป็น my_pipeline หากคุณไม่ได้เปลี่ยนชื่อไปป์ไลน์
ดับเบิลคลิกเพื่อเปิด kubeflow_runner.py ยกเลิกหมายเหตุสองอาร์กิวเมนต์ query และ beam_pipeline_args สำหรับฟังก์ชัน create_pipeline
ตอนนี้ไปป์ไลน์ก็พร้อมที่จะใช้ BigQuery เป็นแหล่งที่มาตัวอย่างแล้ว อัปเดตไปป์ไลน์เหมือนเมื่อก่อนและสร้างการดำเนินการใหม่เหมือนที่เราทำในขั้นตอนที่ 5 และ 6
อัปเดตไปป์ไลน์แล้วรันใหม่
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
ลองใช้ Dataflow
คอมโพเนนต์ TFX จำนวนมากใช้ Apache Beam เพื่อใช้ไปป์ไลน์ข้อมูลแบบขนาน และหมายความว่าคุณสามารถกระจายปริมาณงานการประมวลผลข้อมูลโดยใช้ Google Cloud Dataflow ในขั้นตอนนี้ เราจะตั้งค่าตัวจัดการ Kubeflow ให้ใช้ Dataflow เป็นแบ็คเอนด์ประมวลผลข้อมูลสำหรับ Apache Beam
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
ดับเบิลคลิก pipeline เพื่อเปลี่ยนไดเร็กทอรี และดับเบิลคลิกเพื่อเปิด configs.py ยกเลิกหมายเหตุคำจำกัดความของ GOOGLE_CLOUD_REGION และ DATAFLOW_BEAM_PIPELINE_ARGS
เปลี่ยนไดเร็กทอรีขึ้นไปหนึ่งระดับ คลิกชื่อไดเร็กทอรีเหนือรายการไฟล์ ชื่อของไดเร็กทอรีคือชื่อของไปป์ไลน์ซึ่งเป็น my_pipeline หากคุณไม่ได้เปลี่ยนแปลง
ดับเบิลคลิกเพื่อเปิด kubeflow_runner.py ยกเลิกการใส่เครื่องหมายข้อคิดเห็น beam_pipeline_args (อย่าลืมใส่ความคิดเห็นเกี่ยวกับ beam_pipeline_args ปัจจุบันที่คุณเพิ่มไว้ในขั้นตอนที่ 7 ด้วย)
อัปเดตไปป์ไลน์แล้วรันใหม่
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
คุณค้นหางาน Dataflow ได้ใน Dataflow ใน Cloud Console
ลองใช้การฝึกอบรมและการคาดการณ์แพลตฟอร์ม Cloud AI กับ KFP
TFX ทำงานร่วมกับบริการ GCP ที่มีการจัดการหลายอย่าง เช่น Cloud AI Platform for Training and Prediction คุณสามารถตั้งค่าส่วนประกอบ Trainer ให้ใช้ Cloud AI Platform Training ซึ่งเป็นบริการที่มีการจัดการสำหรับโมเดล ML การฝึก นอกจากนี้ เมื่อโมเดลของคุณถูกสร้างขึ้นและพร้อมที่จะให้บริการ คุณสามารถ ส่ง โมเดลของคุณไปที่ Cloud AI Platform Prediction เพื่อให้บริการได้ ในขั้นตอนนี้ เราจะตั้งค่าส่วนประกอบ Trainer และ Pusher ให้ใช้บริการ Cloud AI Platform
ก่อนที่จะแก้ไขไฟล์ คุณอาจต้องเปิดใช้งาน AI Platform Training & Prediction API ก่อน
ดับเบิลคลิก pipeline เพื่อเปลี่ยนไดเร็กทอรี และดับเบิลคลิกเพื่อเปิด configs.py ยกเลิกหมายเหตุคำจำกัดความของ GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS และ GCP_AI_PLATFORM_SERVING_ARGS เราจะใช้คอนเทนเนอร์อิมเมจที่สร้างขึ้นเองเพื่อฝึกโมเดลใน Cloud AI Platform Training ดังนั้นเราควรตั้ง masterConfig.imageUri ใน GCP_AI_PLATFORM_TRAINING_ARGS ให้เป็นค่าเดียวกันกับ CUSTOM_TFX_IMAGE ข้างต้น
เปลี่ยนไดเร็กทอรีขึ้นไปหนึ่งระดับแล้วดับเบิลคลิกเพื่อเปิด kubeflow_runner.py ไม่ใส่เครื่องหมายข้อคิดเห็น ai_platform_training_args และ ai_platform_serving_args
อัปเดตไปป์ไลน์แล้วรันใหม่
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
คุณสามารถหางานการฝึกอบรมของคุณได้ใน งาน Cloud AI Platform หากไปป์ไลน์ของคุณเสร็จสมบูรณ์ คุณจะพบโมเดลของคุณได้ใน Cloud AI Platform Models
14. ใช้ข้อมูลของคุณเอง
ในบทช่วยสอนนี้ คุณได้สร้างไปป์ไลน์สำหรับโมเดลโดยใช้ชุดข้อมูล Chicago Taxi ตอนนี้ลองใส่ข้อมูลของคุณเองลงในไปป์ไลน์ ข้อมูลของคุณสามารถจัดเก็บได้ทุกที่ที่ไปป์ไลน์สามารถเข้าถึงได้ รวมถึงไฟล์ Google Cloud Storage, BigQuery หรือ CSV
คุณต้องแก้ไขคำจำกัดความไปป์ไลน์เพื่อรองรับข้อมูลของคุณ
หากข้อมูลของคุณถูกจัดเก็บไว้ในไฟล์
- แก้ไข
DATA_PATHในkubeflow_runner.pyเพื่อระบุตำแหน่ง
หากข้อมูลของคุณจัดเก็บไว้ใน BigQuery
- แก้ไข
BIG_QUERY_QUERYใน configs.py เป็นคำสั่งสืบค้นของคุณ - เพิ่มคุณสมบัติใน
models/features.py - แก้ไข
models/preprocessing.pyเพื่อ แปลงข้อมูลอินพุตสำหรับการฝึกอบรม - แก้ไข
models/keras/model.pyและmodels/keras/constants.pyเพื่อ อธิบายโมเดล ML ของคุณ
เรียนรู้เพิ่มเติมเกี่ยวกับเทรนเนอร์
ดู คู่มือส่วนประกอบ Trainer สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับไปป์ไลน์การฝึกอบรม
ทำความสะอาด
หากต้องการล้างทรัพยากร Google Cloud ทั้งหมดที่ใช้ในโปรเจ็กต์นี้ คุณสามารถ ลบโปรเจ็กต์ Google Cloud ที่คุณใช้สำหรับบทแนะนำได้
หรือคุณสามารถล้างทรัพยากรแต่ละรายการได้โดยไปที่แต่ละคอนโซล: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine