
Introdução
Este tutorial foi desenvolvido para apresentar o TensorFlow Extended (TFX) e o AIPlatform Pipelines e ajudar você a aprender a criar seus próprios pipelines de machine learning no Google Cloud. Ele mostra integração com TFX, AI Platform Pipelines e Kubeflow, bem como interação com TFX em notebooks Jupyter.
Ao final deste tutorial, você terá criado e executado um pipeline de ML hospedado no Google Cloud. Você poderá visualizar os resultados de cada execução e visualizar a linhagem dos artefatos criados.
Você seguirá um processo típico de desenvolvimento de ML, começando examinando o conjunto de dados e terminando com um pipeline funcional completo. Ao longo do caminho, você explorará maneiras de depurar e atualizar seu pipeline e medir o desempenho.
Conjunto de dados de táxi de Chicago


Você está usando o conjunto de dados Taxi Trips divulgado pela cidade de Chicago.
Você pode ler mais sobre o conjunto de dados no Google BigQuery . Explore o conjunto de dados completo na IU do BigQuery .
Objetivo do modelo – Classificação binária
O cliente dará gorjeta maior ou menor que 20%?
1. Configure um projeto do Google Cloud
1.a Configure seu ambiente no Google Cloud
Para começar, você precisa de uma conta do Google Cloud. Se você já tiver um, vá para Criar novo projeto .
Acesse o Console do Google Cloud .
Concorde com os termos e condições do Google Cloud
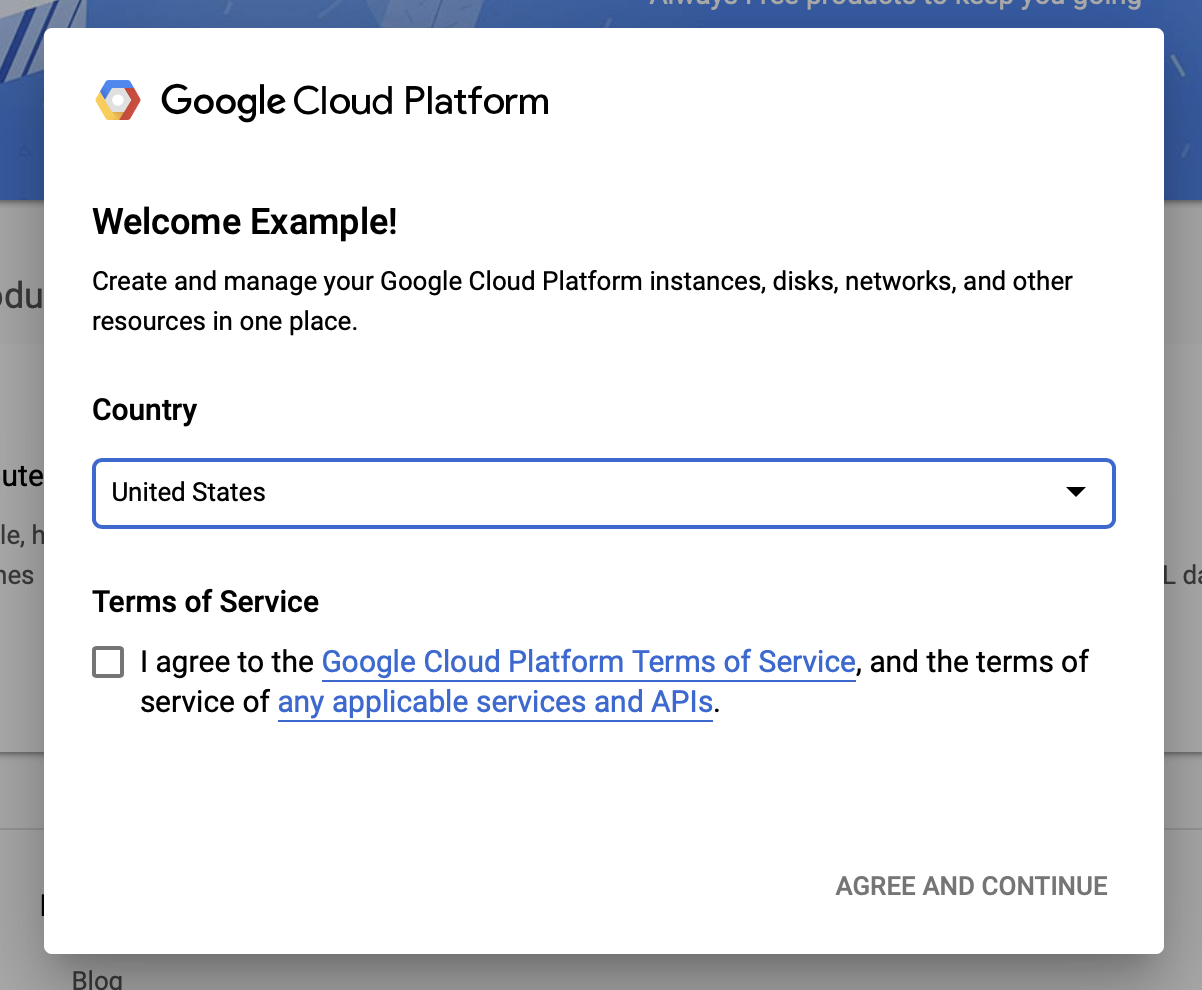
Se desejar começar com uma conta de teste gratuita, clique em Experimente gratuitamente (ou Comece gratuitamente ).
Selecione seu país.
Concorde com os termos de serviço.
Insira os detalhes de cobrança.
Você não será cobrado neste momento. Se você não tiver outros projetos do Google Cloud, poderá concluir este tutorial sem exceder os limites do nível gratuito do Google Cloud , que inclui no máximo oito núcleos em execução ao mesmo tempo.
1.b Crie um novo projeto.
- No painel principal do Google Cloud , clique no menu suspenso do projeto próximo ao cabeçalho do Google Cloud Platform e selecione Novo projeto .
- Dê um nome ao seu projeto e insira outros detalhes do projeto
- Depois de criar um projeto, certifique-se de selecioná-lo no menu suspenso do projeto.
2. Configurar e implantar um AI Platform Pipeline em um novo cluster Kubernetes
Acesse a página Clusters do AI Platform Pipelines .
No menu de navegação principal: ≡ > AI Platform > Pipelines
Clique em + Nova Instância para criar um novo cluster.
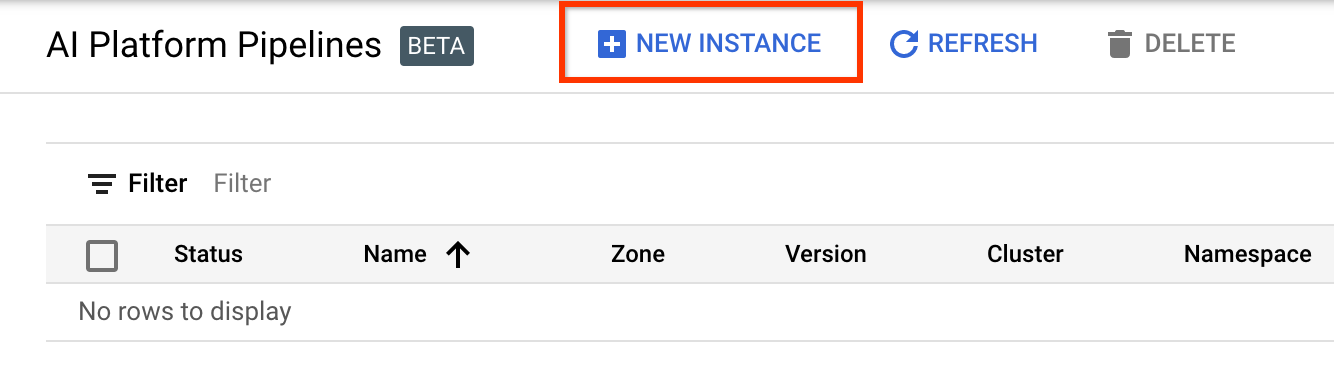
Na página de visão geral do Kubeflow Pipelines , clique em Configurar .

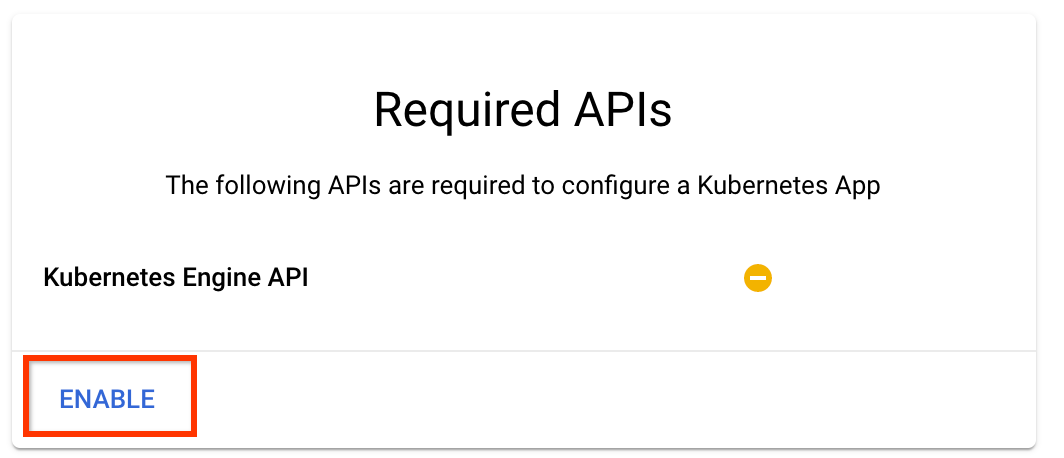
Clique em "Ativar" para ativar a API Kubernetes Engine
Na página Implantar Kubeflow Pipelines :
Selecione uma zona (ou "região") para o seu cluster. A rede e a sub-rede podem ser definidas, mas para os fins deste tutorial vamos deixá-las como padrão.
IMPORTANTE Marque a caixa Permitir acesso às seguintes APIs de nuvem . (Isso é necessário para que este cluster acesse as outras partes do seu projeto. Se você perder esta etapa, corrigi-la mais tarde será um pouco complicado.)
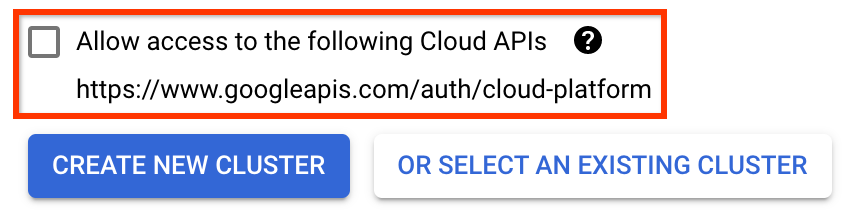
Clique em Criar novo cluster e aguarde alguns minutos até que o cluster seja criado. Isso levará alguns minutos. Quando terminar, você verá uma mensagem como:
Cluster "cluster-1" criado com sucesso na zona "us-central1-a".
Selecione um namespace e um nome de instância (usar os padrões é adequado). Para os fins deste tutorial, não marque executor.emissary ou managedstorage.enabled .
Clique em Implantar e aguarde alguns instantes até que o pipeline seja implantado. Ao implantar o Kubeflow Pipelines, você aceita os Termos de Serviço.
3. Configure a instância do Cloud AI Platform Notebook.
Acesse a página do Vertex AI Workbench . Na primeira vez que você executar o Workbench, será necessário ativar a API Notebooks.
No menu de navegação principal: ≡ -> Vertex AI -> Workbench
Se solicitado, ative a API Compute Engine.
Crie um novo notebook com o TensorFlow Enterprise 2.7 (ou superior) instalado.
Novo notebook -> TensorFlow Enterprise 2.7 -> Sem GPU
Selecione uma região e zona e dê um nome à instância do notebook.
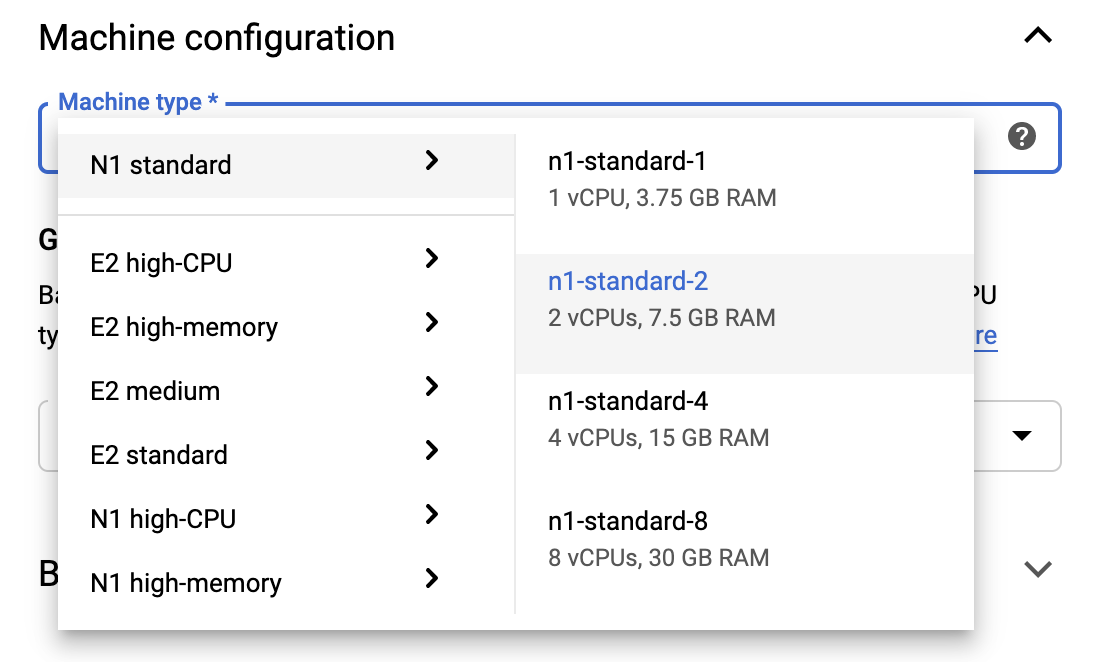
Para permanecer dentro dos limites do nível gratuito, talvez seja necessário alterar as configurações padrão aqui para reduzir o número de vCPUs disponíveis para esta instância de 4 para 2:
- Selecione Opções avançadas na parte inferior do formulário Novo bloco de notas .
Em Configuração da máquina, você pode selecionar uma configuração com 1 ou 2 vCPUs se precisar permanecer no nível gratuito.
Aguarde a criação do novo notebook e clique em Habilitar API de Notebooks
4. Inicie o caderno de primeiros passos
Acesse a página Clusters do AI Platform Pipelines .
No menu de navegação principal: ≡ -> AI Platform -> Pipelines
Na linha do cluster que você está usando neste tutorial, clique em Open Pipelines Dashboard .

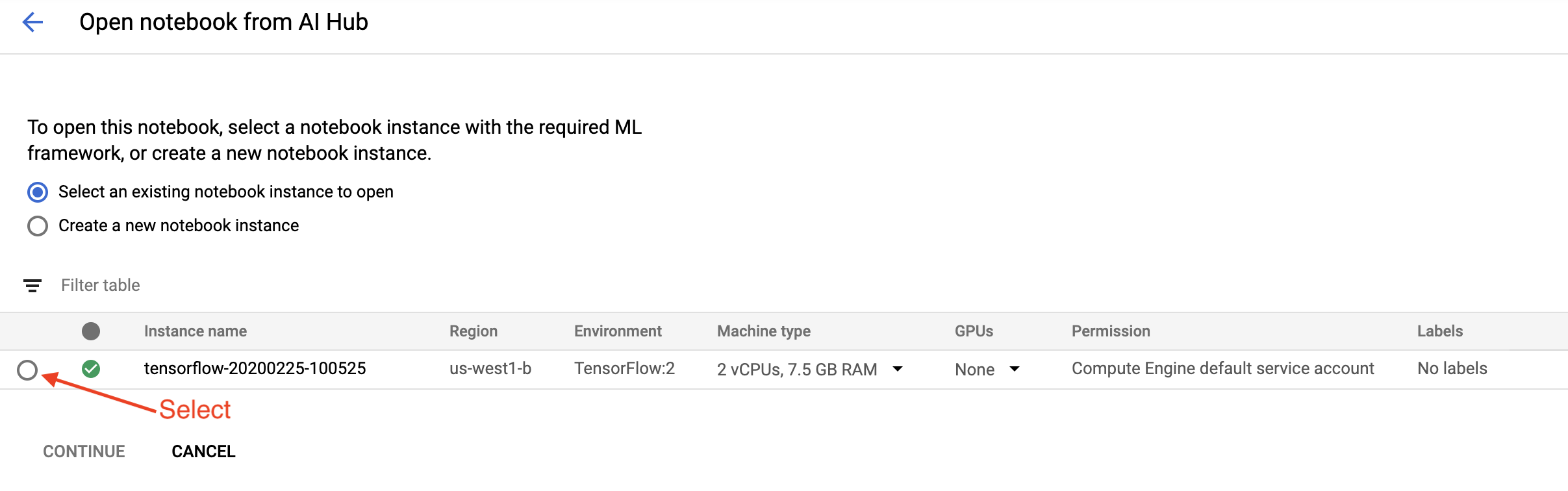
Na página Primeiros passos , clique em Abrir um notebook do Cloud AI Platform no Google Cloud .

Selecione a instância do Notebook que você está usando para este tutorial e Continue e, em seguida, Confirme .
5. Continue trabalhando no Notebook
Instalar
O caderno de primeiros passos começa com a instalação do TFX e do Kubeflow Pipelines (KFP) na VM em que o Jupyter Lab está sendo executado.
Em seguida, ele verifica qual versão do TFX está instalada, faz uma importação e define e imprime o ID do projeto:

Conecte-se aos seus serviços do Google Cloud
A configuração do pipeline precisa do ID do seu projeto, que você pode obter por meio do notebook e definir como uma variável ambiental.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
Agora defina o endpoint do cluster KFP.
Isso pode ser encontrado na URL do painel Pipelines. Vá para o painel do Kubeflow Pipeline e veja o URL. O ponto final é tudo no URL começando com https:// , até e incluindo googleusercontent.com .
ENDPOINT='' # Enter YOUR ENDPOINT here.
O notebook então define um nome exclusivo para a imagem personalizada do Docker:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. Copie um modelo para o diretório do seu projeto
Edite a próxima célula do notebook para definir um nome para seu pipeline. Neste tutorial usaremos my_pipeline .
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
O notebook então usa a CLI tfx para copiar o modelo de pipeline. Este tutorial usa o conjunto de dados Chicago Taxi para realizar a classificação binária, portanto, o modelo define o modelo como taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
O notebook então muda seu contexto CWD para o diretório do projeto:
%cd {PROJECT_DIR}
Navegue pelos arquivos do pipeline
No lado esquerdo do Cloud AI Platform Notebook, você verá um navegador de arquivos. Deve haver um diretório com o nome do seu pipeline ( my_pipeline ). Abra-o e visualize os arquivos. (Você também poderá abri-los e editá-los no ambiente do notebook.)
# You can also list the files from the shellls
O comando tfx template copy acima criou uma estrutura básica de arquivos que constroem um pipeline. Isso inclui códigos-fonte Python, dados de amostra e notebooks Jupyter. Eles se destinam a este exemplo específico. Para seus próprios pipelines, esses seriam os arquivos de suporte exigidos pelo pipeline.
Aqui está uma breve descrição dos arquivos Python.
-
pipeline- Este diretório contém a definição do pipeline-
configs.py— define constantes comuns para executores de pipeline -
pipeline.py— define componentes TFX e um pipeline
-
-
models- Este diretório contém definições de modelo de ML.-
features.pyfeatures_test.py— define recursos para o modelo -
preprocessing.py/preprocessing_test.py— define trabalhos de pré-processamento usandotf::Transform -
estimator- Este diretório contém um modelo baseado em Estimador.-
constants.py— define constantes do modelo -
model.py/model_test.py— define o modelo DNN usando o estimador TF
-
-
keras- Este diretório contém um modelo baseado em Keras.-
constants.py— define constantes do modelo -
model.py/model_test.py— define o modelo DNN usando Keras
-
-
-
beam_runner.py/kubeflow_runner.py— defina executores para cada mecanismo de orquestração
7. Execute seu primeiro pipeline TFX no Kubeflow
O notebook executará o pipeline usando o comando CLI tfx run .
Conecte-se ao armazenamento
A execução de pipelines cria artefatos que devem ser armazenados em ML-Metadata . Os artefatos referem-se a cargas úteis, que são arquivos que devem ser armazenados em um sistema de arquivos ou armazenamento em bloco. Neste tutorial, usaremos o GCS para armazenar nossas cargas de metadados, usando o bucket que foi criado automaticamente durante a configuração. Seu nome será <your-project-id>-kubeflowpipelines-default .
Crie o pipeline
O notebook fará upload de nossos dados de amostra para o bucket do GCS para que possamos usá-los em nosso pipeline posteriormente.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv O notebook então usa o comando tfx pipeline create para criar o pipeline.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
Ao criar um pipeline, Dockerfile será gerado para construir uma imagem Docker. Não se esqueça de adicionar esses arquivos ao seu sistema de controle de origem (por exemplo, git) junto com outros arquivos de origem.
Execute o pipeline
O notebook então usa o comando tfx run create para iniciar uma execução do seu pipeline. Você também verá esta execução listada em Experimentos no painel do Kubeflow Pipelines.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}Você pode visualizar seu pipeline no painel Kubeflow Pipelines.
8. Valide seus dados
A primeira tarefa em qualquer projeto de ciência de dados ou ML é compreender e limpar os dados.
- Entenda os tipos de dados de cada recurso
- Procure anomalias e valores ausentes
- Entenda as distribuições de cada recurso
Componentes


- ExampleGen ingere e divide o conjunto de dados de entrada.
- StatisticsGen calcula estatísticas para o conjunto de dados.
- SchemaGen SchemaGen examina as estatísticas e cria um esquema de dados.
- ExampleValidator procura anomalias e valores ausentes no conjunto de dados.
No editor de arquivos do laboratório Jupyter:
Em pipeline / pipeline.py , remova o comentário das linhas que acrescentam esses componentes ao seu pipeline:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen já estava habilitado quando os arquivos de modelo foram copiados.)
Atualize o pipeline e execute-o novamente
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Verifique o pipeline
Para o Kubeflow Orchestrator, visite o painel KFP e encontre as saídas do pipeline na página para a execução do pipeline. Clique na guia "Experimentos" à esquerda e em "Todas as execuções" na página Experimentos. Você deverá conseguir encontrar a execução com o nome do seu pipeline.
Exemplo mais avançado
O exemplo apresentado aqui serve apenas para você começar. Para obter um exemplo mais avançado, consulte o Colab de validação de dados do TensorFlow .
Para obter mais informações sobre como usar o TFDV para explorar e validar um conjunto de dados, consulte os exemplos em tensorflow.org .
9. Engenharia de recursos
Você pode aumentar a qualidade preditiva de seus dados e/ou reduzir a dimensionalidade com engenharia de recursos.
- Cruzamentos de recursos
- Vocabulários
- Incorporações
- PCA
- Codificação categórica
Um dos benefícios de usar o TFX é que você escreverá seu código de transformação uma vez e as transformações resultantes serão consistentes entre o treinamento e a veiculação.
Componentes

- Transform realiza engenharia de recursos no conjunto de dados.
No editor de arquivos do laboratório Jupyter:
Em pipeline / pipeline.py , encontre e remova o comentário da linha que anexa Transform ao pipeline.
# components.append(transform)
Atualize o pipeline e execute-o novamente
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Verifique as saídas do pipeline
Para o Kubeflow Orchestrator, visite o painel KFP e encontre as saídas do pipeline na página para a execução do pipeline. Clique na guia "Experimentos" à esquerda e em "Todas as execuções" na página Experimentos. Você deverá conseguir encontrar a execução com o nome do seu pipeline.
Exemplo mais avançado
O exemplo apresentado aqui serve apenas para você começar. Para obter um exemplo mais avançado, consulte TensorFlow Transform Colab .
10. Treinamento
Treine um modelo do TensorFlow com seus dados bonitos, limpos e transformados.
- Inclua as transformações da etapa anterior para que sejam aplicadas de forma consistente
- Salve os resultados como SavedModel para produção
- Visualize e explore o processo de treinamento usando o TensorBoard
- Salve também um EvalSavedModel para análise do desempenho do modelo
Componentes
- O Trainer treina um modelo do TensorFlow.
No editor de arquivos do laboratório Jupyter:
Em pipeline / pipeline.py , encontre e remova o comentário que anexa o Trainer ao pipeline:
# components.append(trainer)
Atualize o pipeline e execute-o novamente
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Verifique as saídas do pipeline
Para o Kubeflow Orchestrator, visite o painel KFP e encontre as saídas do pipeline na página para a execução do pipeline. Clique na guia "Experimentos" à esquerda e em "Todas as execuções" na página Experimentos. Você deverá conseguir encontrar a execução com o nome do seu pipeline.
Exemplo mais avançado
O exemplo apresentado aqui serve apenas para você começar. Para um exemplo mais avançado, consulte o Tutorial do TensorBoard .
11. Analisando o desempenho do modelo
Compreender mais do que apenas as métricas de nível superior.
- Os usuários experimentam o desempenho do modelo apenas para suas consultas
- O baixo desempenho em fatias de dados pode ser ocultado por métricas de nível superior
- A justiça do modelo é importante
- Muitas vezes, os principais subconjuntos de usuários ou dados são muito importantes e podem ser pequenos
- Desempenho em condições críticas, mas incomuns
- Desempenho para públicos-chave, como influenciadores
- Se você estiver substituindo um modelo que está atualmente em produção, primeiro certifique-se de que o novo seja melhor
Componentes
- O avaliador realiza uma análise profunda dos resultados do treinamento.
No editor de arquivos do laboratório Jupyter:
Em pipeline / pipeline.py , encontre e remova o comentário da linha que anexa Evaluator ao pipeline:
components.append(evaluator)
Atualize o pipeline e execute-o novamente
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Verifique as saídas do pipeline
Para o Kubeflow Orchestrator, visite o painel KFP e encontre as saídas do pipeline na página para a execução do pipeline. Clique na guia "Experimentos" à esquerda e em "Todas as execuções" na página Experimentos. Você deverá conseguir encontrar a execução com o nome do seu pipeline.
12. Servindo o modelo
Se o novo modelo estiver pronto, faça-o.
- Pusher implanta SavedModels em locais bem conhecidos
Os alvos de implantação recebem novos modelos de locais conhecidos
- Envio do TensorFlow
- TensorFlow Lite
- TensorFlowJS
- Hub TensorFlow
Componentes
- Pusher implanta o modelo em uma infraestrutura de serviço.
No editor de arquivos do laboratório Jupyter:
Em pipeline / pipeline.py , encontre e remova o comentário da linha que anexa Pusher ao pipeline:
# components.append(pusher)
Verifique as saídas do pipeline
Para o Kubeflow Orchestrator, visite o painel KFP e encontre as saídas do pipeline na página para a execução do pipeline. Clique na guia "Experimentos" à esquerda e em "Todas as execuções" na página Experimentos. Você deverá conseguir encontrar a execução com o nome do seu pipeline.
Destinos de implantação disponíveis
Agora você treinou e validou seu modelo, e ele está pronto para produção. Agora você pode implantar seu modelo em qualquer um dos destinos de implantação do TensorFlow, incluindo:
- TensorFlow Serving , para servir seu modelo em um servidor ou farm de servidores e processar solicitações de inferência REST e/ou gRPC.
- TensorFlow Lite , para incluir seu modelo em um aplicativo móvel nativo Android ou iOS ou em um aplicativo Raspberry Pi, IoT ou microcontrolador.
- TensorFlow.js , para executar seu modelo em um navegador da web ou aplicativo Node.JS.
Exemplos mais avançados
O exemplo apresentado acima serve apenas para você começar. Abaixo estão alguns exemplos de integração com outros serviços Cloud.
Considerações sobre recursos do Kubeflow Pipelines
Dependendo dos requisitos da sua carga de trabalho, a configuração padrão para a implantação do Kubeflow Pipelines pode ou não atender às suas necessidades. Você pode personalizar suas configurações de recursos usando pipeline_operator_funcs em sua chamada para KubeflowDagRunnerConfig .
pipeline_operator_funcs é uma lista de itens OpFunc , que transforma todas as instâncias ContainerOp geradas na especificação de pipeline KFP que é compilada de KubeflowDagRunner .
Por exemplo, para configurar a memória podemos usar set_memory_request para declarar a quantidade de memória necessária. Uma maneira típica de fazer isso é criar um wrapper para set_memory_request e usá-lo para adicionar à lista de OpFunc s do pipeline:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
Funções semelhantes de configuração de recursos incluem:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
Experimente BigQueryExampleGen
O BigQuery é um data warehouse em nuvem sem servidor, altamente escalonável e econômico. O BigQuery pode ser usado como fonte para exemplos de treinamento no TFX. Nesta etapa, adicionaremos BigQueryExampleGen ao pipeline.
No editor de arquivos do laboratório Jupyter:
Clique duas vezes para abrir pipeline.py . Comente CsvExampleGen e remova o comentário da linha que cria uma instância de BigQueryExampleGen . Você também precisa descomentar o argumento query da função create_pipeline .
Precisamos especificar qual projeto GCP usar para BigQuery, e isso é feito definindo --project em beam_pipeline_args ao criar um pipeline.
Clique duas vezes para abrir configs.py . Remova o comentário da definição de BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS e BIG_QUERY_QUERY . Você deve substituir o ID do projeto e o valor da região neste arquivo pelos valores corretos para o seu projeto do GCP.
Mude o diretório um nível acima. Clique no nome do diretório acima da lista de arquivos. O nome do diretório é o nome do pipeline que é my_pipeline se você não alterou o nome do pipeline.
Clique duas vezes para abrir kubeflow_runner.py . Remova o comentário de dois argumentos, query e beam_pipeline_args , para a função create_pipeline .
Agora o pipeline está pronto para usar o BigQuery como fonte de exemplo. Atualize o pipeline como antes e crie uma nova execução como fizemos nas etapas 5 e 6.
Atualize o pipeline e execute-o novamente
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Experimente o Dataflow
Vários componentes do TFX usam o Apache Beam para implementar pipelines paralelos de dados, o que significa que você pode distribuir cargas de trabalho de processamento de dados usando o Google Cloud Dataflow . Nesta etapa, configuraremos o orquestrador Kubeflow para usar o Dataflow como back-end de processamento de dados para Apache Beam.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
Clique duas vezes pipeline para alterar o diretório e clique duas vezes para abrir configs.py . Remova o comentário da definição de GOOGLE_CLOUD_REGION e DATAFLOW_BEAM_PIPELINE_ARGS .
Mude o diretório um nível acima. Clique no nome do diretório acima da lista de arquivos. O nome do diretório é o nome do pipeline que é my_pipeline se você não mudou.
Clique duas vezes para abrir kubeflow_runner.py . Remova o comentário beam_pipeline_args . (Certifique-se também de comentar beam_pipeline_args atual que você adicionou na Etapa 7.)
Atualize o pipeline e execute-o novamente
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Você pode encontrar seus jobs do Dataflow no Dataflow no Console do Cloud .
Experimente o treinamento e previsão do Cloud AI Platform com KFP
O TFX interopera com vários serviços gerenciados do GCP, como Cloud AI Platform for Training and Prediction . Você pode configurar seu componente Trainer para usar o Cloud AI Platform Training, um serviço gerenciado para treinamento de modelos de ML. Além disso, quando seu modelo estiver criado e pronto para ser veiculado, você poderá enviá-lo para o Cloud AI Platform Prediction para veiculação. Nesta etapa, configuraremos nosso componente Trainer e Pusher para usar os serviços Cloud AI Platform.
Antes de editar arquivos, talvez seja necessário ativar a API AI Platform Training & Prediction .
Clique duas vezes pipeline para alterar o diretório e clique duas vezes para abrir configs.py . Remova o comentário da definição de GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS e GCP_AI_PLATFORM_SERVING_ARGS . Usaremos nossa imagem de contêiner personalizada para treinar um modelo no Cloud AI Platform Training, portanto, devemos definir masterConfig.imageUri em GCP_AI_PLATFORM_TRAINING_ARGS com o mesmo valor de CUSTOM_TFX_IMAGE acima.
Mude o diretório um nível acima e clique duas vezes para abrir kubeflow_runner.py . Remova o comentário ai_platform_training_args e ai_platform_serving_args .
Atualize o pipeline e execute-o novamente
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Você pode encontrar suas vagas de treinamento em Cloud AI Platform Jobs . Se o pipeline for concluído com sucesso, você poderá encontrar seu modelo em Cloud AI Platform Models .
14. Use seus próprios dados
Neste tutorial, você criou um pipeline para um modelo usando o conjunto de dados Chicago Taxi. Agora tente colocar seus próprios dados no pipeline. Seus dados podem ser armazenados em qualquer lugar onde o pipeline possa acessá-los, incluindo Google Cloud Storage, BigQuery ou arquivos CSV.
Você precisa modificar a definição do pipeline para acomodar seus dados.
Se seus dados estiverem armazenados em arquivos
- Modifique
DATA_PATHemkubeflow_runner.py, indicando o local.
Se seus dados estiverem armazenados no BigQuery
- Modifique
BIG_QUERY_QUERYem configs.py para sua instrução de consulta. - Adicione recursos em
models/features.py. - Modifique
models/preprocessing.pypara transformar os dados de entrada para treinamento . - Modifique
models/keras/model.pyemodels/keras/constants.pypara descrever seu modelo de ML .
Saiba mais sobre o Treinador
Consulte o guia do componente Trainer para obter mais detalhes sobre pipelines de treinamento.
Limpando
Para limpar todos os recursos do Google Cloud usados neste projeto, exclua o projeto do Google Cloud usado no tutorial.
Alternativamente, você pode limpar recursos individuais visitando cada console: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine