
このチュートリアルでは、 TensorFlow Transform ( tf.Transformライブラリ) を使用して機械学習 (ML) のデータ前処理を実装する方法を示します。 TensorFlow のtf.Transformライブラリを使用すると、データ前処理パイプラインを通じてインスタンス レベルとフルパスの両方のデータ変換を定義できます。これらのパイプラインはApache Beamで効率的に実行され、副産物として TensorFlow グラフを作成して、モデルの提供時と同じ変換を予測中に適用します。
このチュートリアルでは、Apache Beam のランナーとしてDataflowを使用するエンドツーエンドの例を提供します。 BigQuery 、Dataflow、 Vertex AI 、TensorFlow Keras API に精通していることを前提としています。また、 Vertex AI Workbenchなどの Jupyter Notebook の使用経験があることも前提としています。
また、このチュートリアルは、「ML のデータ前処理: オプションと推奨事項」で説明されているように、Google Cloud での前処理のタイプ、課題、オプションの概念を理解していることを前提としています。
目的
tf.Transformライブラリを使用して Apache Beam パイプラインを実装します。- Dataflow でパイプラインを実行します。
-
tf.Transformライブラリを使用して TensorFlow モデルを実装します。 - モデルをトレーニングして予測に使用します。
コスト
このチュートリアルでは、Google Cloud の次の課金対象コンポーネントを使用します。
このチュートリアルの実行コストを見積もるには、すべてのリソースを 1 日中使用すると仮定して、事前構成された料金計算ツールを使用します。
始める前に
Google Cloud コンソールのプロジェクト セレクタ ページで、 Google Cloud プロジェクトを選択または作成します。
クラウド プロジェクトに対して課金が有効になっていることを確認してください。プロジェクトで課金が有効になっているかどうかを確認する方法を学習します。
Dataflow、Vertex AI、Notebooks API を有効にします。 API を有効にする
このソリューション用の Jupyter ノートブック
次の Jupyter ノートブックは実装例を示しています。
- ノートブック 1ではデータの前処理について説明します。詳細については、後の「Apache Beam パイプラインの実装」セクションで説明します。
- Notebook 2ではモデルのトレーニングについて説明します。詳細については、後の「TensorFlow モデルの実装」セクションで説明します。
次のセクションでは、これらのノートブックを複製し、ノートブックを実行して、実装例がどのように機能するかを学習します。
ユーザー管理のノートブック インスタンスを起動する
Google Cloud コンソールで、 Vertex AI Workbenchページに移動します。
[ユーザー管理のノートブック]タブで、 [+新しいノートブック]をクリックします。
インスタンス タイプとしてGPU なしの TensorFlow Enterprise 2.8 (LTS あり)を選択します。
「作成」をクリックします。
ノートブックを作成した後、JupyterLab へのプロキシの初期化が完了するまで待ちます。準備が完了すると、ノートブック名の横に「Open JupyterLab」と表示されます。
ノートブックのクローンを作成する
[ユーザー管理のノートブック] タブで、ノートブック名の横にある[JupyterLab を開く]をクリックします。 JupyterLab インターフェイスが新しいタブで開きます。
JupyterLab に「推奨ビルド」ダイアログが表示された場合は、 「キャンセル」をクリックして提案されたビルドを拒否します。
[ランチャー] タブで、 [ターミナル]をクリックします。
ターミナル ウィンドウで、ノートブックのクローンを作成します。
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Apache Beam パイプラインを実装する
このセクションと次のセクション「Dataflow でパイプラインを実行する」では、ノートブック 1 の概要とコンテキストを説明します。このノートブックでは、 tf.Transformライブラリを使用してデータを前処理する方法を説明する実践的な例が提供されます。この例では、さまざまな入力に基づいて赤ちゃんの体重を予測するために使用される Natality データセットを使用します。データは BigQuery の公開出生表に保存されます。
ノートブック 1 を実行する
JupyterLab インターフェイスで、 [ファイル] > [パスから開く]をクリックし、次のパスを入力します。
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynb[編集] > [すべての出力をクリア] をクリックします。
「必要なパッケージのインストール」セクションで、最初のセルを実行して
pip install apache-beamコマンドを実行します。出力の最後の部分は次のとおりです。
Successfully installed ...出力内の依存関係エラーは無視できます。まだカーネルを再起動する必要はありません。
2 番目のセルを実行して
pip install tensorflow-transformコマンドを実行します。出力の最後の部分は次のとおりです。Successfully installed ... Note: you may need to restart the kernel to use updated packages.出力内の依存関係エラーは無視できます。
[カーネル] > [カーネルの再起動]をクリックします。
「インストールされたパッケージの確認」セクションと「Dataflow コンテナーにパッケージをインストールするための setup.py の作成」セクションのセルを実行します。
[グローバル フラグの設定]セクションで、
PROJECTとBUCKETの横にあるyour-projectをクラウド プロジェクト ID に置き換えて、セルを実行します。ノートブックの最後のセルまでの残りのセルをすべて実行します。各セルで何を行うかについては、ノートブックの指示を参照してください。
パイプラインの概要
ノートブックの例では、Dataflow はtf.Transformパイプラインを大規模に実行して、データを準備し、変換アーティファクトを生成します。このドキュメントの後のセクションでは、パイプラインの各ステップを実行する関数について説明します。パイプライン全体の手順は次のとおりです。
- BigQuery からトレーニング データを読み取ります。
-
tf.Transformライブラリを使用してトレーニング データを分析および変換します。 - 変換されたトレーニング データをTFRecord形式で Cloud Storage に書き込みます。
- BigQuery から評価データを読み取ります。
- ステップ 2 で生成された
transform_fnグラフを使用して評価データを変換します。 - 変換されたトレーニング データを TFRecord 形式で Cloud Storage に書き込みます。
- 変換アーティファクトを Cloud Storage に書き込みます。これは、後でモデルの作成とエクスポートに使用されます。
次の例は、パイプライン全体の Python コードを示しています。以下のセクションでは、各ステップの説明とコードのリストを示します。
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
BigQuery から生のトレーニング データを読み取る
最初のステップは、 read_from_bq関数を使用して BigQuery から生のトレーニング データを読み取ることです。この関数は、BigQuery から抽出されたraw_datasetオブジェクトを返します。 data_size値を渡し、 trainまたはevalのstep値を渡します。次の例に示すように、BigQuery ソース クエリはget_source_query関数を使用して構築されます。
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
tf.Transform前処理を実行する前に、マップ、フィルター、グループ、ウィンドウ処理などの一般的な Apache Beam ベースの処理を実行する必要がある場合があります。この例では、コードはbeam.Map(prep_bq_row)メソッドを使用して BigQuery から読み取られたレコードをクリーンアップします。ここで、 prep_bq_rowはカスタム関数です。このカスタム関数は、カテゴリ特徴量の数値コードを人間が判読できるラベルに変換します。
さらに、 tf.Transformライブラリを使用して BigQuery から抽出されたraw_dataオブジェクトを分析および変換するには、 raw_dataとraw_metadataオブジェクトのタプルであるraw_datasetオブジェクトを作成する必要があります。 raw_metadataオブジェクトは、次のようにcreate_raw_metadata関数を使用して作成されます。
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
このメソッドを定義するセルの直後にあるノートブック内のセルを実行すると、 raw_metadata.schemaオブジェクトの内容が表示されます。これには次の列が含まれます。
-
gestation_weeks(タイプ:FLOAT) -
is_male(タイプ:BYTES) -
mother_age(タイプ:FLOAT) -
mother_race(タイプ:BYTES) -
plurality(タイプ:FLOAT) -
weight_pounds(タイプ:FLOAT)
生のトレーニング データを変換する
ML 用に準備するために、トレーニング データの入力生の特徴に一般的な前処理変換を適用すると想像してください。次の表に示すように、これらの変換にはフルパス レベルの操作とインスタンス レベルの操作の両方が含まれます。
| 入力機能 | 変換 | 必要な統計 | タイプ | 出力機能 |
|---|---|---|---|---|
weight_pound | なし | なし | NA | weight_pound |
mother_age | ノーマライズ | 平均、var | フルパス | mother_age_normalized |
mother_age | 等しいサイズのバケット化 | 分位数 | フルパス | mother_age_bucketized |
mother_age | ログを計算する | なし | インスタンスレベル | mother_age_log |
plurality | 赤ちゃんが一人であるか複数であるかを示します | なし | インスタンスレベル | is_multiple |
is_multiple | 公称値を数値指数に変換 | 語彙 | フルパス | is_multiple_index |
gestation_weeks | 0 から 1 までのスケール | 最小、最大 | フルパス | gestation_weeks_scaled |
mother_race | 公称値を数値指数に変換 | 語彙 | フルパス | mother_race_index |
is_male | 公称値を数値指数に変換 | 語彙 | フルパス | is_male_index |
これらの変換はpreprocess_fn関数で実装されます。この関数はテンソルの辞書 ( input_features ) を期待し、処理された特徴の辞書 ( output_features ) を返します。
次のコードは、 tf.Transformフルパス変換 API (接頭辞tft.が付く) および TensorFlow (接頭辞tf.が付く) インスタンス レベルの操作を使用したpreprocess_fn関数の実装を示しています。
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
tf.Transformフレームワークには、前の例の変換に加えて、次の表に示す変換を含む他のいくつかの変換があります。
| 変換 | に適用されます | 説明 |
|---|---|---|
scale_by_min_max | 数値特徴 | 数値列を範囲 [ output_min 、 output_max ] にスケールします。 |
scale_to_0_1 | 数値特徴 | 範囲 [ 0 , 1 ] になるようにスケーリングされた入力列である列を返します。 |
scale_to_z_score | 数値特徴 | 平均 0、分散 1 の標準化された列を返します。 |
tfidf | テキスト機能 | x内の用語をその用語頻度 * 逆ドキュメント頻度にマッピングします。 |
compute_and_apply_vocabulary | カテゴリ特徴 | カテゴリ特徴量の語彙を生成し、この語彙を使用して整数にマッピングします。 |
ngrams | テキスト機能 | n-gram のSparseTensorを作成します |
hash_strings | カテゴリ特徴 | 文字列をバケットにハッシュします |
pca | 数値特徴 | 偏った共分散を使用してデータセットの PCA を計算します |
bucketize | 数値特徴 | 各入力にバケット インデックスが割り当てられた、等しいサイズの (分位数ベースの) バケット化された列を返します。 |
preprocess_fn関数で実装された変換を、パイプラインの前のステップで生成されたraw_train_datasetオブジェクトに適用するには、 AnalyzeAndTransformDatasetメソッドを使用します。このメソッドは、入力としてraw_datasetオブジェクトを想定し、 preprocess_fn関数を適用して、 transformed_datasetオブジェクトとtransform_fnグラフを生成します。次のコードは、この処理を示しています。
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
変換は、分析フェーズと変換フェーズの 2 つのフェーズで生データに適用されます。このドキュメントの後半の図 3 は、 AnalyzeAndTransformDatasetメソッドがどのようにAnalyzeDatasetメソッドとTransformDatasetメソッドに分解されるかを示しています。
分析フェーズ
分析フェーズでは、生のトレーニング データがフルパス プロセスで分析され、変換に必要な統計が計算されます。これには、平均、分散、最小値、最大値、分位数、および語彙の計算が含まれます。分析プロセスでは生のデータセット (生のデータと生のメタデータ) が必要であり、次の 2 つの出力が生成されます。
-
transform_fn: 分析フェーズから計算された統計と、インスタンス レベルの操作としての変換ロジック (統計を使用する) を含む TensorFlow グラフ。 「グラフの保存」で後述するように、transform_fnグラフはモデルのserving_fn関数にアタッチされるように保存されます。これにより、同じ変換をオンライン予測データ ポイントに適用することが可能になります。 -
transform_metadata: 変換後のデータの予想されるスキーマを記述するオブジェクト。
分析フェーズは、次の図 (図 1) に示されています。

tf.Transform分析フェーズ。 tf.Transform アナライザーには、 min 、 max 、 sum 、 size 、 mean 、 var 、 covariance 、 quantiles 、 vocabulary 、およびpcaが含まれます。
変換フェーズ
変換フェーズでは、分析フェーズで生成されたtransform_fnグラフを使用して、インスタンスレベルのプロセスで生のトレーニングデータを変換し、変換されたトレーニングデータを生成します。変換されたトレーニング データは、変換されたメタデータ (分析フェーズによって生成される) とペアになって、 transformed_train_datasetデータセットが生成されます。
変換フェーズを次の図 (図 2) に示します。

tf.Transformの変換フェーズ。特徴を前処理するには、 preprocess_fn関数の実装で必要なtensorflow_transform変換 (コード内でtftとしてインポート) を呼び出します。たとえば、 tft.scale_to_z_score操作を呼び出すと、 tf.Transformライブラリはこの関数呼び出しを平均および分散アナライザーに変換し、分析フェーズで統計を計算し、これらの統計を適用して変換フェーズで数値特徴を正規化します。これはすべて、 AnalyzeAndTransformDataset(preprocess_fn)メソッドを呼び出すことによって自動的に行われます。
この呼び出しによって生成されるtransformed_metadata.schemaエンティティには、次の列が含まれます。
-
gestation_weeks_scaled(タイプ:FLOAT) -
is_male_index(タイプ:INT、 is_categorical:True) -
is_multiple_index(タイプ:INT、 is_categorical:True) -
mother_age_bucketized(タイプ:INT、 is_categorical:True) -
mother_age_log(タイプ:FLOAT) -
mother_age_normalized(タイプ:FLOAT) -
mother_race_index(タイプ:INT、 is_categorical:True) -
weight_pounds(タイプ:FLOAT)
このシリーズの最初の部分の前処理操作で説明したように、特徴変換はカテゴリ特徴を数値表現に変換します。変換後、カテゴリ特徴は整数値で表されます。 transformed_metadata.schemaエンティティでは、 INT型列のis_categoricalフラグは、列がカテゴリ特徴量を表すか真の数値特徴量を表すかを示します。
変換されたトレーニング データを書き込む
トレーニング データが分析フェーズと変換フェーズを通じてpreprocess_fn関数で前処理された後、TensorFlow モデルのトレーニングに使用するデータをシンクに書き込むことができます。 Dataflow を使用して Apache Beam パイプラインを実行する場合、シンクは Cloud Storage になります。それ以外の場合、シンクはローカル ディスクになります。データを固定幅形式のファイルの CSV ファイルとして書き込むこともできますが、TensorFlow データセットに推奨されるファイル形式は TFRecord 形式です。これは、 tf.train.Exampleプロトコル バッファ メッセージで構成される単純なレコード指向のバイナリ形式です。
各tf.train.Exampleレコードには 1 つ以上の機能が含まれています。これらは、トレーニングのためにモデルに供給されるときにテンソルに変換されます。次のコードは、変換されたデータセットを指定された場所の TFRecord ファイルに書き込みます。
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
評価データの読み取り、変換、書き込み
トレーニング データを変換し、 transform_fnグラフを生成した後、それを使用して評価データを変換できます。まず、「BigQuery から生のトレーニング データを読み取る」で前述したread_from_bq関数を使用して、BigQuery から評価データを読み取り、クリーンアップし、 stepパラメータにevalの値を渡します。次に、次のコードを使用して、生の評価データセット ( raw_dataset ) を、期待される変換形式 ( transformed_dataset ) に変換します。
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
評価データを変換する場合、 transform_fnグラフのロジックとトレーニング データの分析フェーズから計算された統計の両方を使用して、インスタンス レベルの操作のみが適用されます。つまり、評価データ内の数値特徴の Z スコア正規化の平均や分散などの新しい統計を計算するために、評価データをフルパス方式で分析することはありません。代わりに、トレーニング データから計算された統計を使用して、インスタンス レベルの方法で評価データを変換します。
したがって、トレーニング データのコンテキストでAnalyzeAndTransformメソッドを使用して、統計を計算し、データを変換します。同時に、評価データの変換のコンテキストでTransformDatasetメソッドを使用して、トレーニング データに対して計算された統計を使用してデータのみを変換します。
次に、トレーニング プロセス中に TensorFlow モデルを評価するために、データを TFRecord 形式でシンク (ランナーに応じて Cloud Storage またはローカル ディスク) に書き込みます。これを行うには、 「変換されたトレーニング データを書き込む」で説明されているwrite_tfrecords関数を使用します。次の図 (図 3) は、トレーニング データの分析フェーズで生成されたtransform_fnグラフを使用して評価データを変換する方法を示しています。

transform_fnを使用した評価データの変換。グラフを保存する
tf.Transform前処理パイプラインの最後のステップは、トレーニング データの分析フェーズによって生成されたtransform_fnグラフを含むアーティファクトを保存することです。アーティファクトを保存するコードは、次のwrite_transform_artefacts関数に示されています。
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
これらのアーティファクトは、後でモデルのトレーニングとサービス提供のためのエクスポートに使用されます。次のセクションで示すように、次のアーティファクトも生成されます。
-
saved_model.pb: 変換ロジック (transform_fnグラフ) を含む TensorFlow グラフを表します。これは、生のデータ ポイントを変換された形式に変換するためにモデル サービング インターフェイスにアタッチされます。 -
variables: トレーニング データの分析フェーズ中に計算された統計が含まれ、saved_model.pbアーティファクトの変換ロジックで使用されます。 -
assets:compute_and_apply_vocabularyメソッドで処理されたカテゴリ特徴ごとに 1 つずつ、入力生の名目値を数値インデックスに変換するために処理中に使用される語彙ファイルが含まれます。 -
transformed_metadata: 変換されたデータのスキーマを記述するschema.jsonファイルが含まれるディレクトリ。
Dataflow でパイプラインを実行する
tf.Transformパイプラインを定義した後、Dataflow を使用してパイプラインを実行します。次の図 (図 4) は、この例で説明されているtf.Transformパイプラインのデータフロー実行グラフを示しています。
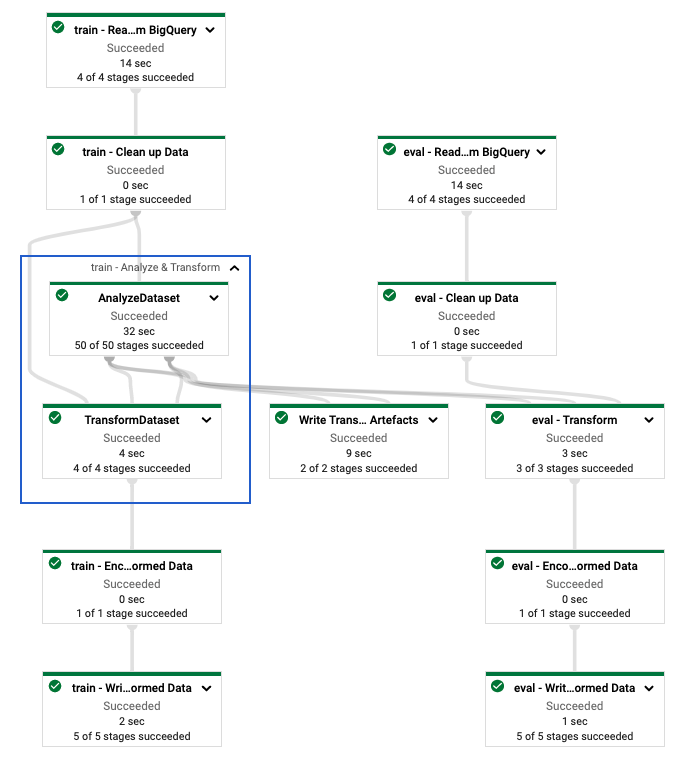
tf.Transformパイプラインのデータフロー実行グラフ。 Dataflow パイプラインを実行してトレーニング データと評価データを前処理した後、ノートブックの最後のセルを実行して、Cloud Storage で生成されたオブジェクトを探索できます。このセクションのコード スニペットは結果を示しています。YOUR_BUCKET_NAME YOUR_BUCKET_NAME Cloud Storage バケットの名前です。
TFRecord 形式で変換されたトレーニング データと評価データは、次の場所に保存されます。
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
変換アーティファクトは次の場所に生成されます。
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
次のリストはパイプラインの出力であり、生成されたデータ オブジェクトとアーティファクトを示しています。
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
TensorFlow モデルを実装する
このセクションと次のセクション「 予測用のモデルのトレーニングと使用」では、ノートブック 2 の概要とコンテキストを説明します。ノートブックには、赤ちゃんの体重を予測するための ML モデルの例が提供されます。この例では、Keras API を使用して TensorFlow モデルが実装されています。このモデルは、前に説明したtf.Transform前処理パイプラインによって生成されたデータとアーティファクトを使用します。
ノートブック 2 を実行する
JupyterLab インターフェイスで、 [ファイル] > [パスから開く]をクリックし、次のパスを入力します。
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynb[編集] > [すべての出力をクリア] をクリックします。
[必要なパッケージのインストール]セクションで、最初のセルを実行して
pip install tensorflow-transformコマンドを実行します。出力の最後の部分は次のとおりです。
Successfully installed ... Note: you may need to restart the kernel to use updated packages.出力内の依存関係エラーは無視できます。
[カーネル]メニューで、 [カーネルの再起動]を選択します。
「インストールされたパッケージの確認」セクションと「Dataflow コンテナーにパッケージをインストールするための setup.py の作成」セクションのセルを実行します。
[グローバル フラグの設定]セクションで、
PROJECTとBUCKETの横にあるyour-projectをクラウド プロジェクト ID に置き換えて、セルを実行します。ノートブックの最後のセルまでの残りのセルをすべて実行します。各セルで何を行うかについては、ノートブックの指示を参照してください。
モデル作成の概要
モデルを作成する手順は次のとおりです。
-
transformed_metadataディレクトリに保存されているスキーマ情報を使用して、機能列を作成します。 - 特徴列をモデルへの入力として使用し、Keras API でワイドでディープなモデルを作成します。
-
tfrecords_input_fn関数を作成し、変換アーティファクトを使用してトレーニング データと評価データを読み取り、解析します。 - モデルをトレーニングして評価します。
- トレーニング済みモデルをエクスポートするには、
transform_fnグラフがアタッチされたserving_fn関数を定義します。 -
saved_model_cliツールを使用して、エクスポートされたモデルを検査します。 - エクスポートしたモデルを予測に使用します。
このドキュメントではモデルの構築方法については説明していないため、モデルがどのように構築またはトレーニングされたかについては詳しく説明しません。ただし、次のセクションでは、 tf.Transformプロセスによって生成される、 transform_metadataディレクトリに保存されている情報を使用してモデルの特徴列を作成する方法を示します。このドキュメントでは、モデルが提供用にエクスポートされるときに、 transform_fnグラフ (これもtf.Transformプロセスによって生成されます) が、 serving_fn関数でどのように使用されるかについても示します。
生成された変換アーティファクトをモデルのトレーニングで使用する
TensorFlow モデルをトレーニングするときは、前のデータ処理ステップで生成された、変換されたtrainオブジェクトとevalオブジェクトを使用します。これらのオブジェクトは、TFRecord 形式のシャード ファイルとして保存されます。前の手順で生成されたtransformed_metadataディレクトリ内のスキーマ情報は、トレーニングと評価のためにモデルにフィードするデータ ( tf.train.Exampleオブジェクト) を解析する際に役立ちます。
データを解析する
TFRecord 形式でファイルを読み取ってモデルにトレーニング データと評価データを供給するため、ファイル内の各tf.train.Exampleオブジェクトを解析して特徴量 (テンソル) の辞書を作成する必要があります。これにより、モデルのトレーニングおよび評価インターフェイスとして機能する特徴列を使用して、特徴がモデル入力レイヤーに確実にマッピングされます。データを解析するには、前の手順で生成されたアーティファクトから作成されたTFTransformOutputオブジェクトを使用します。
「グラフの保存」セクションの説明に従って、前の前処理ステップで生成および保存されたアーティファクトから
TFTransformOutputオブジェクトを作成します。tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutputオブジェクトからfeature_specオブジェクトを抽出します。tf_transform_output.transformed_feature_spec()tfrecords_input_fn関数と同様に、feature_specオブジェクトを使用して、tf.train.Exampleオブジェクトに含まれる機能を指定します。def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
特徴列を作成する
パイプラインは、トレーニングと評価のためにモデルで予期される変換されたデータのスキーマを記述するスキーマ情報を、 transformed_metadataディレクトリに生成します。スキーマには、次のような機能名とデータ型が含まれます。
-
gestation_weeks_scaled(タイプ:FLOAT) -
is_male_index(タイプ:INT、 is_categorical:True) -
is_multiple_index(タイプ:INT、 is_categorical:True) -
mother_age_bucketized(タイプ:INT、 is_categorical:True) -
mother_age_log(タイプ:FLOAT) -
mother_age_normalized(タイプ:FLOAT) -
mother_race_index(タイプ:INT、 is_categorical:True) -
weight_pounds(タイプ:FLOAT)
この情報を表示するには、次のコマンドを使用します。
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
次のコードは、機能名を使用して機能列を作成する方法を示しています。
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
このコードは、数値特徴の場合はtf.feature_column.numeric_column列を作成し、カテゴリ特徴の場合はtf.feature_column.categorical_column_with_identity列を作成します。
このシリーズの最初の部分のオプション C: TensorFlowで説明されているように、拡張機能列を作成することもできます。このシリーズで使用される例では、 tf.feature_column.crossed_columnフィーチャー列を使用してmother_raceとmother_age_bucketizedフィーチャーを交差させることにより、新しいフィーチャーmother_race_X_mother_age_bucketizedが作成されます。この交差した特徴の低次元の密な表現は、 tf.feature_column.embedding_column特徴列を使用して作成されます。
次の図 (図 5) は、変換されたデータと、変換されたメタデータを使用して TensorFlow モデルを定義およびトレーニングする方法を示しています。

予測を提供するためのモデルをエクスポートする
Keras API を使用して TensorFlow モデルをトレーニングした後、トレーニングされたモデルを SavedModel オブジェクトとしてエクスポートし、予測用の新しいデータ ポイントを提供できるようにします。モデルをエクスポートするときは、そのインターフェイス、つまり、提供中に予期される入力特徴スキーマを定義する必要があります。この入力特徴スキーマは、次のコードに示すように、 serving_fn関数で定義されます。
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
提供中、モデルはデータ ポイントが生の形式 (つまり、変換前の生の特徴) であることを期待します。したがって、 serving_fn関数は生の特徴を受け取り、それを Python 辞書としてfeaturesオブジェクトに保存します。ただし、前に説明したように、トレーニングされたモデルは、変換されたスキーマ内のデータ ポイントを期待します。未加工のフィーチャを、モデル インターフェイスで予期されるtransformed_featuresオブジェクトに変換するには、次の手順で、保存したtransform_fnグラフをfeaturesオブジェクトに適用します。
前の前処理ステップで生成および保存されたアーティファクトから
TFTransformOutputオブジェクトを作成します。tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutputオブジェクトからTransformFeaturesLayerオブジェクトを作成します。model.tft_layer = tf_transform_output.transform_features_layer()TransformFeaturesLayerオブジェクトを使用して、transform_fnグラフを適用します。transformed_features = model.tft_layer(features)
次の図 (図 6) は、提供するモデルをエクスポートする最終ステップを示しています。

transform_fnグラフをアタッチして提供します。 モデルをトレーニングして予測に使用する
ノートブックのセルを実行することで、モデルをローカルでトレーニングできます。コードをパッケージ化し、Vertex AI Training を使用してモデルを大規模にトレーニングする方法の例については、Google Cloud Cloudml-samples GitHub リポジトリのサンプルとガイドをご覧ください。
saved_model_cliツールを使用してエクスポートされた SavedModel オブジェクトを検査すると、次の例に示すように、シグネチャ定義signature_defのinputs要素に生の機能が含まれていることがわかります。
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
ノートブックの残りのセルには、エクスポートされたモデルをローカル予測に使用する方法と、Vertex AI Prediction を使用してモデルをマイクロサービスとしてデプロイする方法が示されています。どちらの場合も、入力 (サンプル) データ ポイントが生のスキーマ内にあることを強調することが重要です。
掃除
このチュートリアルで使用するリソースに対して Google Cloud アカウントに追加料金が発生しないようにするには、リソースを含むプロジェクトを削除してください。
プロジェクトを削除する
Google Cloud コンソールで、 [リソースの管理]ページに移動します。
プロジェクト リストで、削除するプロジェクトを選択し、 [削除] をクリックします。
ダイアログでプロジェクト ID を入力し、 「シャットダウン」をクリックしてプロジェクトを削除します。
次は何ですか
- Google Cloud での機械学習のためのデータ前処理の概念、課題、オプションについては、このシリーズの最初の記事「 ML のためのデータ前処理: オプションと推奨事項」をご覧ください。
- Dataflow で tf.Transform パイプラインを実装、パッケージ化、実行する方法の詳細については、 「国勢調査データセットを使用した収入の予測」サンプルを参照してください。
- Google Cloud で TensorFlowを使用した ML に関する Coursera の専門講座を受講してください。
- ML エンジニアリングのベスト プラクティスについては、「ML のルール」で学びます。
- リファレンス アーキテクチャ、図、ベスト プラクティスの詳細については、クラウド アーキテクチャ センターを参照してください。