
| |  GitHubでソースを表示 GitHubでソースを表示 | |
概要
このチュートリアルでは、アドオンパッケージの循環学習率の使用方法を示します。
循環学習率
ニューラルネットワークのトレーニングが進むにつれて、学習率を調整することが有益であることが示されています。鞍点の回復から、逆伝播中に発生する可能性のある数値の不安定性の防止まで、さまざまな利点があります。しかし、特定のトレーニングタイムスタンプに関してどの程度調整する必要があるかをどのようにして知ることができますか? 2015年、レスリー・スミスは、損失の状況をより速く横断するために学習率を上げたいが、収束に近づくときは学習率を下げたいと考えていることに気づきました。このアイデアを実現するために、彼が提案した循環ラーニング料金は、関数のサイクルに対する学習率を調整します(CLR)を。視覚的なデモンストレーションのために、あなたがチェックアウトすることができますこのブログを。 CLRがTensorFlowAPIとして利用できるようになりました。詳細については、オリジナルの紙をチェックしてくださいここに。
設定
pip install -q -U tensorflow_addons
from tensorflow.keras import layers
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.random.set_seed(42)
np.random.seed(42)
データセットをロードして準備する
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
ハイパーパラメータを定義する
BATCH_SIZE = 64
EPOCHS = 10
INIT_LR = 1e-4
MAX_LR = 1e-2
モデル構築およびモデルトレーニングユーティリティを定義する
def get_training_model():
model = tf.keras.Sequential(
[
layers.InputLayer((28, 28, 1)),
layers.experimental.preprocessing.Rescaling(scale=1./255),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.SpatialDropout2D(0.2),
layers.GlobalAvgPool2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model
def train_model(model, optimizer):
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
validation_data=(x_test, y_test),
epochs=EPOCHS)
return history
再現性のために、初期モデルの重みはシリアル化されており、これを使用して実験を実行します。
initial_model = get_training_model()
initial_model.save("initial_model")
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2021-11-12 19:14:52.355642: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: initial_model/assets
CLRなしでモデルをトレーニングする
standard_model = tf.keras.models.load_model("initial_model")
no_clr_history = train_model(standard_model, optimizer="sgd")
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 5s 4ms/step - loss: 2.2089 - accuracy: 0.2180 - val_loss: 1.7581 - val_accuracy: 0.4137 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 1.2951 - accuracy: 0.5136 - val_loss: 0.9583 - val_accuracy: 0.6491 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 1.0096 - accuracy: 0.6189 - val_loss: 0.9155 - val_accuracy: 0.6588 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.9269 - accuracy: 0.6572 - val_loss: 0.8495 - val_accuracy: 0.7011 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8855 - accuracy: 0.6722 - val_loss: 0.8361 - val_accuracy: 0.6685 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8482 - accuracy: 0.6852 - val_loss: 0.7975 - val_accuracy: 0.6830 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8219 - accuracy: 0.6941 - val_loss: 0.7630 - val_accuracy: 0.6990 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7995 - accuracy: 0.7011 - val_loss: 0.7280 - val_accuracy: 0.7263 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7830 - accuracy: 0.7059 - val_loss: 0.7156 - val_accuracy: 0.7445 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7636 - accuracy: 0.7136 - val_loss: 0.7026 - val_accuracy: 0.7462
CLRスケジュールを定義する
tfa.optimizers.CyclicalLearningRateオプティマイザに渡すことができ、直接スケジュールを返すモジュール。スケジュールは、入力としてステップを取り、ペーパーに記載されているCLR式を使用して計算された値を出力します。
steps_per_epoch = len(x_train) // BATCH_SIZE
clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=INIT_LR,
maximal_learning_rate=MAX_LR,
scale_fn=lambda x: 1/(2.**(x-1)),
step_size=2 * steps_per_epoch
)
optimizer = tf.keras.optimizers.SGD(clr)
ここでは、学習率の下限と上限を指定したスケジュールは、その範囲の間で振動する([1E-4、1E-2]この場合)。 scale_fnスケールアップし、所定の周期内の学習率を縮小でしょう関数を定義するために使用されます。 step_size単一サイクルの持続時間を定義します。 step_size 2つの手段は、あなたが1サイクルを完了するために4回の反復の合計が必要です。推奨値step_size次のとおりです。
factor * steps_per_epochここで、[2,8]の範囲内因子嘘。
同じではCLR紙、レスリーはまた率を学習するための境界を選択するシンプルかつエレガントな方法を提示しました。ぜひチェックしてみてください。このブログ記事は、メソッドへの素晴らしい紹介を提供します。
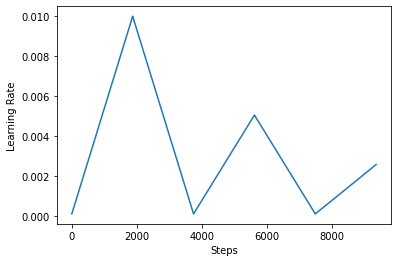
以下に、あなたはどのように視覚化するclrスケジュールルックスが好き。
step = np.arange(0, EPOCHS * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
CLRの効果をより適切に視覚化するために、ステップ数を増やしてスケジュールをプロットできます。
step = np.arange(0, 100 * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
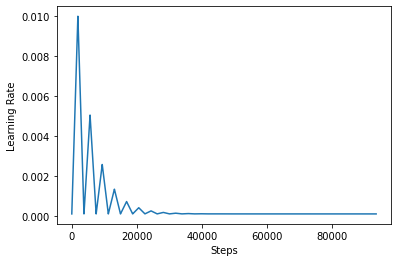
このチュートリアルで使用している関数は次のように呼ばれているtriangular2 CLR紙の方法。つまり、そこに調査された他の二つの機能がありtriangularとexp (ショート指数のためには)。
CLRでモデルをトレーニングする
clr_model = tf.keras.models.load_model("initial_model")
clr_history = train_model(clr_model, optimizer=optimizer)
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 4s 4ms/step - loss: 2.3005 - accuracy: 0.1165 - val_loss: 2.2852 - val_accuracy: 0.2378 Epoch 2/10 938/938 [==============================] - 3s 4ms/step - loss: 2.1931 - accuracy: 0.2398 - val_loss: 1.7386 - val_accuracy: 0.4530 Epoch 3/10 938/938 [==============================] - 3s 4ms/step - loss: 1.3132 - accuracy: 0.5052 - val_loss: 1.0110 - val_accuracy: 0.6482 Epoch 4/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0746 - accuracy: 0.5933 - val_loss: 0.9492 - val_accuracy: 0.6622 Epoch 5/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0528 - accuracy: 0.6028 - val_loss: 0.9439 - val_accuracy: 0.6519 Epoch 6/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0198 - accuracy: 0.6172 - val_loss: 0.9096 - val_accuracy: 0.6620 Epoch 7/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9778 - accuracy: 0.6339 - val_loss: 0.8784 - val_accuracy: 0.6746 Epoch 8/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9535 - accuracy: 0.6487 - val_loss: 0.8665 - val_accuracy: 0.6903 Epoch 9/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9510 - accuracy: 0.6497 - val_loss: 0.8691 - val_accuracy: 0.6857 Epoch 10/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9424 - accuracy: 0.6529 - val_loss: 0.8571 - val_accuracy: 0.6917
予想通り、損失は通常よりも高くなり始め、サイクルが進むにつれて安定します。以下のプロットでこれを視覚的に確認できます。
損失を視覚化する
(fig, ax) = plt.subplots(2, 1, figsize=(10, 8))
ax[0].plot(no_clr_history.history["loss"], label="train_loss")
ax[0].plot(no_clr_history.history["val_loss"], label="val_loss")
ax[0].set_title("No CLR")
ax[0].set_xlabel("Epochs")
ax[0].set_ylabel("Loss")
ax[0].set_ylim([0, 2.5])
ax[0].legend()
ax[1].plot(clr_history.history["loss"], label="train_loss")
ax[1].plot(clr_history.history["val_loss"], label="val_loss")
ax[1].set_title("CLR")
ax[1].set_xlabel("Epochs")
ax[1].set_ylabel("Loss")
ax[1].set_ylim([0, 2.5])
ax[1].legend()
fig.tight_layout(pad=3.0)
fig.show()
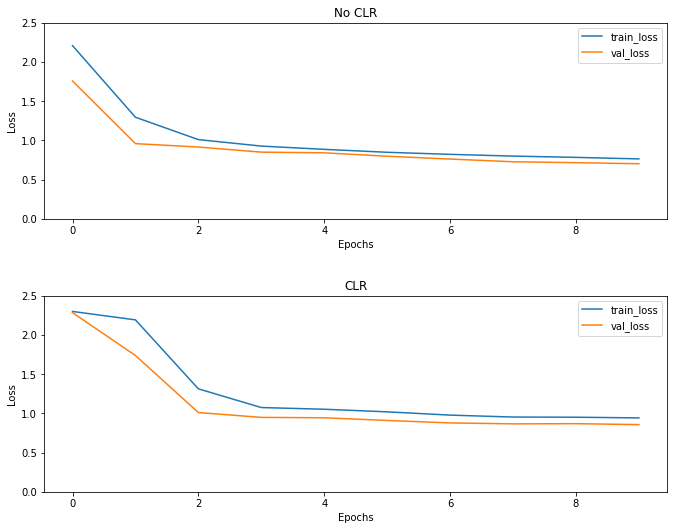
このおもちゃ例えば、あなたはCLRの影響をあまり見ませんでしたが、それは背後にある主要な成分の一つであることに留意されていてもスーパーコンバージェンスと持つことができ、本当に良い影響を与える大規模な設定で訓練するとき。