
Copyright 2021 TF-AgentsAuthors。
| |  GitHubでソースを表示 GitHubでソースを表示 | |
序章
この例のショーはどのように訓練するソフト俳優評論家の上のエージェントをMinitaurの環境。
あなたはを通して働いてきた場合はDQNコラボこれは非常に身近な感じなければなりません。注目すべき変更点は次のとおりです。
- エージェントをDQNからSACに変更します。
- CartPoleよりもはるかに複雑な環境であるMinitaurのトレーニング。 Minitaur環境は、前進するために四足歩行ロボットを訓練することを目的としています。
- 分散強化学習のためのTF-AgentsActor-LearnerAPIの使用。
APIは、エクスペリエンスリプレイバッファーと変数コンテナー(パラメーターサーバー)を使用した分散データ収集と、複数のデバイスにわたる分散トレーニングの両方をサポートします。 APIは、非常にシンプルでモジュール式になるように設計されています。私たちは、利用リバーブをリプレイバッファと変数コンテナとの両方のためのTF DistributionStrategyのAPIのGPUとのTPU上の分散訓練のため。
次の依存関係をインストールしていない場合は、次を実行します。
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
設定
まず、必要なさまざまなツールをインポートします。
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
ハイパーパラメータ
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
環境
RLの環境は、私たちが解決しようとしているタスクまたは問題を表しています。標準的な環境では、簡単に使用してTF-エージェントで作成することができますsuites 。私たちは、異なる持っているsuites文字列の環境名を指定して、などOpenAIジム、アタリ、DMコントロール、などのソースから環境をロードするために。
それでは、PybulletスイートからMinituar環境をロードしましょう。
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

この環境での目標は、エージェントがMinitaurロボットを制御し、可能な限り速く前進させるポリシーをトレーニングすることです。エピソードは1000ステップ続き、リターンはエピソード全体の報酬の合計になります。
環境として提供される情報で見てみましょうobservation政策を生成するために使用するactions 。
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
観察はかなり複雑です。すべてのモーターの角度、速度、およびトルクを表す28の値を受け取ります。リターン環境は、間のアクションの8つの値期待[-1, 1]これらは、望ましいモーター角度です。
通常、2つの環境を作成します。1つはトレーニング中にデータを収集するためのもので、もう1つは評価のためのものです。環境は純粋なPythonで記述されており、Actor LearnerAPIが直接使用するnumpy配列を使用します。
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
流通戦略
DistributionStrategy APIを使用して、データ並列処理を使用して、複数のGPUやTPUなどの複数のデバイス間でトレインステップ計算を実行できるようにします。電車のステップ:
- トレーニングデータのバッチを受け取ります
- デバイス間で分割します
- フォワードステップを計算します
- 損失の平均を集計して計算します
- 後方ステップを計算し、勾配変数の更新を実行します
TF-Agents LearnerAPIとDistributionStrategyAPIを使用すると、以下のトレーニングロジックを変更せずに、GPUでのトレーニングステップの実行(MirroredStrategyを使用)からTPU(TPUStrategyを使用)への切り替えが非常に簡単になります。
GPUの有効化
GPUで実行してみる場合は、最初にノートブックでGPUを有効にする必要があります。
- [編集]→[ノートブック設定]に移動します
- [ハードウェアアクセラレータ]ドロップダウンから[GPU]を選択します
戦略を選ぶ
使用strategy_utils戦略を生成します。内部的には、パラメータを渡します。
-
use_gpu = False返すtf.distribute.get_strategy()CPUを使用して、 -
use_gpu = True返すtf.distribute.MirroredStrategy()一台のマシン上でTensorFlowに表示されている全てのGPUを使用し、
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
すべての変数とエージェントは、下に作成する必要がありますstrategy.scope()あなたは以下を参照してくださいますよう、。
エージェント
SACエージェントを作成するには、まず、トレーニングするネットワークを作成する必要があります。 SACはアクター批評家であるため、2つのネットワークが必要になります。
評論家は私たちのために価値の見積り与えるQ(s,a)つまり、観測とアクションを入力として受け取り、そのアクションが特定の状態に対してどれだけ優れているかを推定します。
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
私たちは、訓練するために、この評論家を使用するactorたちが観測与えられたアクションを生成することを可能にするネットワークを。
ActorNetwork TANH-押しつぶさためのパラメータを予測するMultivariateNormalDiagの分布。次に、アクションを生成する必要があるときはいつでも、この分布がサンプリングされ、現在の観測値を条件とします。
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
これらのネットワークが手元にあれば、エージェントをインスタンス化できます。
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
リプレイバッファ
環境から収集したデータを追跡するために、我々は、使用するリバーブ、Deepmindことにより、効率的で拡張性、そして使いやすい再生システムを。アクターによって収集され、トレーニング中に学習者によって消費された経験データを保存します。
このチュートリアルでは、これはよりも重要であるmax_size -しかし、非同期収集とトレーニングで、分散環境では、おそらくで実験したいと思うでしょうrate_limiters.SampleToInsertRatio例えば2〜1000のsamples_per_insertのどこかを使用して、:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
リプレイバッファを使用してエージェントから得られる格納されるテンソルを記述する仕様、使用して構築されるtf_agent.collect_data_spec 。
SACエージェントが現在と損失を計算するために、次の観測の両方を必要とするので、我々は設定sequence_length=2 。
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
次に、リバーブリプレイバッファーからTensorFlowデータセットを生成します。これを学習者に渡して、トレーニングの経験をサンプリングします。
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
ポリシー
TF-剤中、ポリシーは、RL内のポリシーの標準概念を表す:所与time_stepアクションまたはアクション上分布を生成します。主な方法があるpolicy_step = policy.step(time_step) policy_step名前タプルPolicyStep(action, state, info) 。 policy_step.actionあるaction環境に適用される、 stateステートフル(RNN)ポリシーとの状態を表すinfo 、このようなアクションのログ確率として補助情報を含むことができます。
エージェントには2つのポリシーが含まれています。
-
agent.policy-評価と展開に使用される主な政策。 -
agent.collect_policy-データ収集のために使用されている第二ポリシー。
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
ポリシーは、エージェントとは独立して作成できます。例えば、使用tf_agents.policies.random_py_policyランダムに各time_stepのアクションを選択するポリシーを作成します。
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
俳優
アクターは、ポリシーと環境の間の相互作用を管理します。
- 俳優・コンポーネントは、(などの環境のインスタンス含ま
py_environment)と政策変数のコピーを。 - 各Actorワーカーは、ポリシー変数のローカル値を指定して、一連のデータ収集ステップを実行します。
- 変数の更新が呼び出す前に、明示的にトレーニングスクリプトで変数コンテナのクライアントのインスタンスを使用して行われ
actor.run() - 観察された経験は、各データ収集ステップで再生バッファーに書き込まれます。
アクターがデータ収集ステップを実行すると、(状態、アクション、報酬)の軌跡がオブザーバーに渡され、オブザーバーはそれらをキャッシュしてリバーブリプレイシステムに書き込みます。
我々はフレームに対して軌跡を記憶している[(T0、T1)(T1、T2)(T2、T3)、...]なぜならstride_length=1 。
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
ランダムポリシーを使用してアクターを作成し、経験を収集してリプレイバッファーをシードします。
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
トレーニング中にさらに多くの経験を収集するために、収集ポリシーを使用してアクターをインスタンス化します。
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
トレーニング中にポリシーを評価するために使用されるアクターを作成します。我々は渡しactor.eval_metrics(num_eval_episodes)以降のメトリックをログに記録します。
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
学習者
Learnerコンポーネントにはエージェントが含まれており、再生バッファーからのエクスペリエンスデータを使用して、ポリシー変数に対して勾配ステップの更新を実行します。 1つ以上のトレーニング手順の後、学習者は新しい変数値のセットを変数コンテナーにプッシュできます。
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
指標と評価
私たちは、とevalの俳優をインスタンス化actor.eval_metrics政策評価の際に最も一般的に使用されるメトリックを作成する、上記:
- 平均収益。リターンは、エピソードの環境でポリシーを実行している間に得られた報酬の合計であり、通常、これを数回のエピソードで平均します。
- 平均エピソード長。
アクターを実行して、これらのメトリックを生成します。
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
チェックアウトメトリクスモジュールを異なるメトリックの他の標準実装のために。
エージェントのトレーニング
トレーニングループには、環境からのデータの収集とエージェントのネットワークの最適化の両方が含まれます。その過程で、エージェントのポリシーを評価して、私たちがどのように行動しているかを確認することがあります。
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
視覚化
プロット
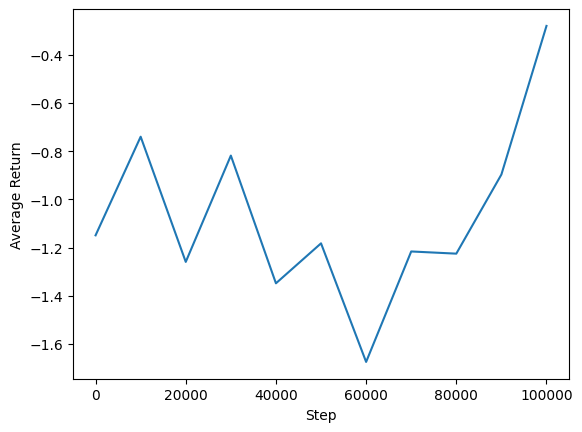
エージェントのパフォーマンスを確認するために、平均リターンとグローバルステップをプロットできます。でMinitaur 、報酬関数はminitaurは、1000のステップで歩くとエネルギー消費にペナルティを課すどのくらいに基づいています。
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
ビデオ
各ステップで環境をレンダリングすることにより、エージェントのパフォーマンスを視覚化すると便利です。その前に、まずこのコラボに動画を埋め込む関数を作成しましょう。
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
次のコードは、いくつかのエピソードに対するエージェントのポリシーを視覚化したものです。
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)