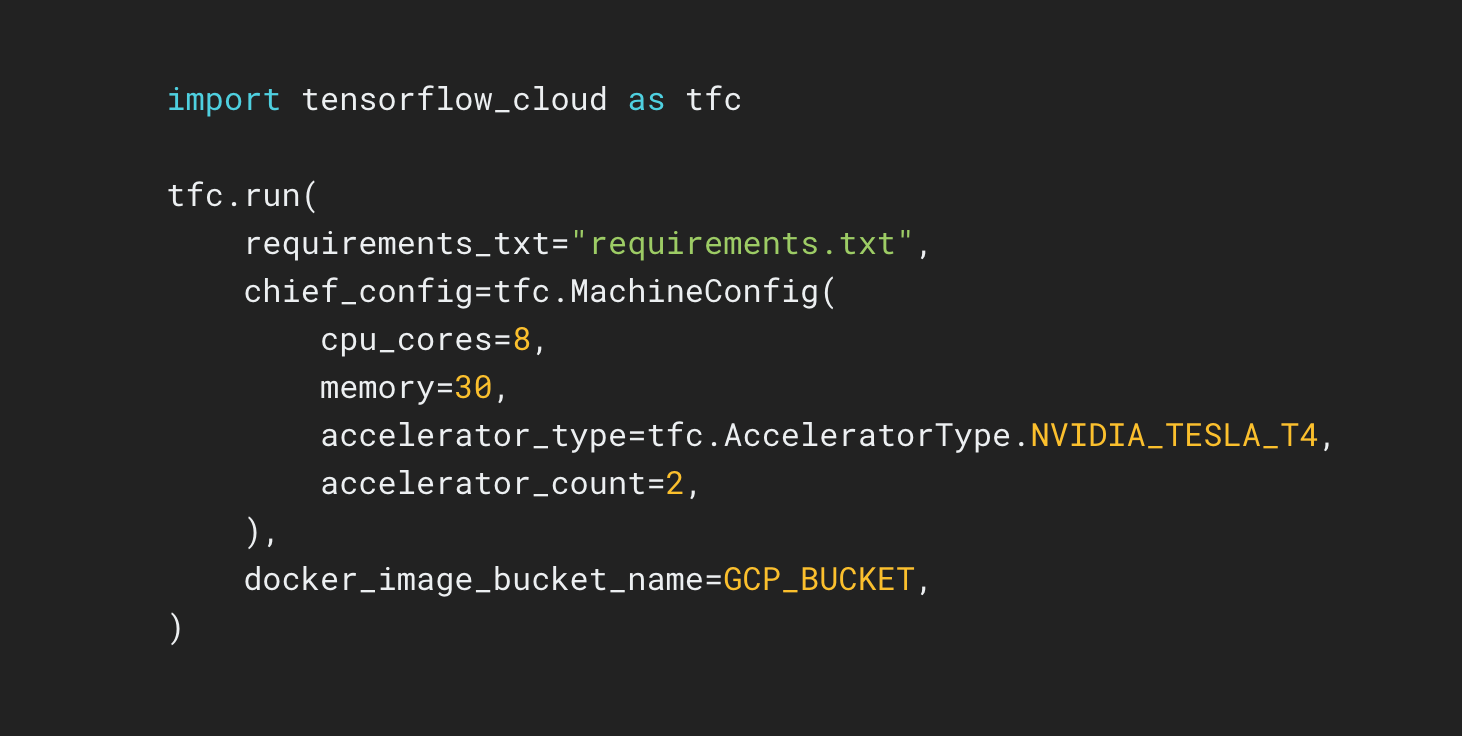
A TensorFlow Cloud é uma biblioteca para conectar seu ambiente local ao Google Cloud.
import tensorflow_cloud as tfc TF_GPU_IMAGE= "tensorflow/tensorflow:latest-gpu" run_parameters = [ distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} ] run(**run_parameters) # Runs your training on Google Cloud!
O repositório da TensorFlow Cloud oferece APIs que facilitam a transição da criação de modelos locais e depuração para o treinamento distribuído e o ajuste de hiperparâmetros no Google Cloud. Usando um notebook Colab ou Kaggle ou um arquivo de script local, é possível enviar seu modelo para ajustar ou treinar no Cloud diretamente sem precisar usar o Console do Cloud.