
TensorFlow Lattice เป็นไลบรารีที่ใช้โมเดล Lattice ที่ยืดหยุ่น ควบคุม และตีความได้ ไลบรารีช่วยให้คุณสามารถแทรกความรู้โดเมนลงในกระบวนการเรียนรู้ผ่าน ข้อจำกัดด้านรูป แบบสามัญสำนึกหรือนโยบาย ซึ่งทำได้โดยใช้คอลเลกชันของ เลเยอร์ Keras ที่สามารถตอบสนองข้อจำกัด เช่น ความซ้ำซ้อน ความนูน และความไว้วางใจแบบคู่ ไลบรารียังมี โมเดลที่สร้างไว้ล่วงหน้า ที่ติดตั้งง่ายอีกด้วย
แนวคิด
ส่วนนี้เป็นเวอร์ชันที่เรียบง่ายของคำอธิบายใน Monotonic Calibrated Interpolated Look-Up Tables , JMLR 2016
ขัดแตะ
ตาข่าย คือตารางค้นหาแบบสอดแทรกซึ่งสามารถประมาณความสัมพันธ์อินพุต-เอาท์พุตตามอำเภอใจในข้อมูลของคุณ โดยจะซ้อนทับตารางปกติลงในพื้นที่อินพุตของคุณและเรียนรู้ค่าสำหรับเอาต์พุตในจุดยอดของตาราง สำหรับจุดทดสอบ \(x\)- \(f(x)\) ถูกประมาณค่าเชิงเส้นตรงจากค่าขัดแตะโดยรอบ \(x\)-
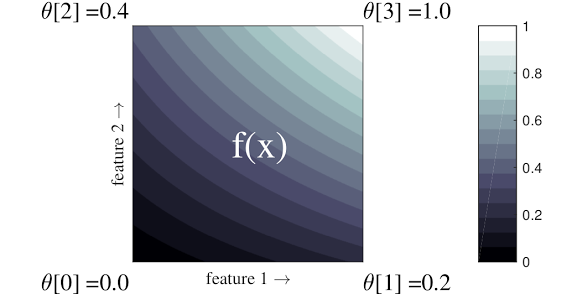
ตัวอย่างง่ายๆ ข้างต้นคือฟังก์ชันที่มีคุณสมบัติอินพุต 2 รายการและพารามิเตอร์ 4 ตัว:\(\theta=[0, 0.2, 0.4, 1]\)ซึ่งเป็นค่าของฟังก์ชันที่มุมของพื้นที่อินพุต ฟังก์ชันที่เหลือจะถูกประมาณค่าจากพารามิเตอร์เหล่านี้
ฟังก์ชั่น \(f(x)\) สามารถจับภาพการโต้ตอบที่ไม่เป็นเชิงเส้นระหว่างคุณสมบัติต่างๆ คุณสามารถนึกถึงพารามิเตอร์ขัดแตะว่าเป็นความสูงของเสาที่วางบนพื้นบนตารางปกติ และฟังก์ชันที่ได้ก็เหมือนกับผ้าที่ดึงแน่นกับเสาทั้งสี่
กับ \(D\) คุณลักษณะและจุดยอด 2 จุดในแต่ละมิติ โดยจะมีโครงตาข่ายปกติ \(2^D\) พารามิเตอร์ เพื่อให้พอดีกับฟังก์ชันที่ยืดหยุ่นมากขึ้น คุณสามารถระบุโครงตาข่ายที่มีความละเอียดมากขึ้นเหนือพื้นที่คุณลักษณะโดยมีจุดยอดมากขึ้นในแต่ละมิติ ฟังก์ชันการถดถอยแบบแลตทิซมีความต่อเนื่องและสามารถหาอนุพันธ์ได้อย่างไม่มีที่สิ้นสุด
การสอบเทียบ
สมมติว่าโครงตาข่ายตัวอย่างก่อนหน้านี้แสดงถึง ความสุขของผู้ใช้ ที่ได้เรียนรู้ โดยมีร้านกาแฟในพื้นที่ที่แนะนำซึ่งคำนวณโดยใช้ฟีเจอร์:
- ราคากาแฟในช่วง 0 ถึง 20 ดอลลาร์
- ระยะทางถึงผู้ใช้ในช่วง 0 ถึง 30 กิโลเมตร
เราต้องการให้โมเดลของเราเรียนรู้ความสุขของผู้ใช้ด้วยคำแนะนำของร้านกาแฟในพื้นที่ โมเดล TensorFlow Lattice สามารถใช้ ฟังก์ชันเชิงเส้นแบบเป็นชิ้นๆ (ด้วย tfl.layers.PWLCalibration ) เพื่อปรับเทียบและทำให้คุณสมบัติอินพุตเป็นมาตรฐานตามช่วงที่ Lattice ยอมรับ: 0.0 ถึง 1.0 ในตัวอย่าง Lattice ด้านบน ต่อไปนี้แสดงตัวอย่างฟังก์ชันการสอบเทียบที่มีจุดสำคัญ 10 จุด:
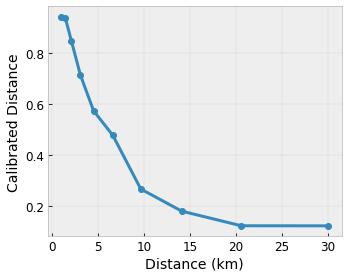
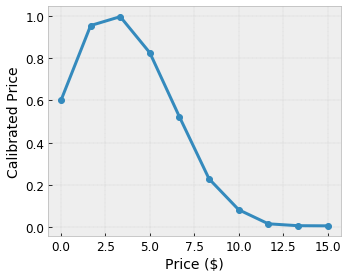
บ่อยครั้งเป็นความคิดที่ดีที่จะใช้ควอนไทล์ของฟีเจอร์เป็นจุดสำคัญของอินพุต โมเดลที่สร้างไว้ล่วงหน้า ของ TensorFlow Lattice สามารถตั้งค่าจุดสำคัญอินพุตให้กับควอนไทล์ของฟีเจอร์ได้โดยอัตโนมัติ
สำหรับคุณสมบัติเชิงหมวดหมู่ TensorFlow Lattice ให้การสอบเทียบตามหมวดหมู่ (ด้วย tfl.layers.CategoricalCalibration ) โดยมีขอบเขตเอาต์พุตที่คล้ายกันเพื่อป้อนเข้าไปในโครงตาข่าย
วงดนตรี
จำนวนพารามิเตอร์ของชั้นตาข่ายจะเพิ่มขึ้นแบบทวีคูณตามจำนวนคุณลักษณะอินพุต ดังนั้นจึงไม่สามารถปรับขนาดให้เป็นขนาดที่สูงมากได้ เพื่อเอาชนะข้อจำกัดนี้ TensorFlow Lattice นำเสนอโครงตาข่ายหลายชุดที่รวมโครงตาข่าย เล็กๆ หลายอัน (โดยเฉลี่ย) เข้าด้วยกัน ซึ่งช่วยให้โมเดลขยายเชิงเส้นตามจำนวนคุณลักษณะได้
ห้องสมุดมีวงดนตรีเหล่านี้สองรูปแบบ:
Random Tiny Lattices (RTL): แต่ละโมเดลย่อยใช้ชุดย่อยแบบสุ่มของคุณสมบัติ (พร้อมการแทนที่)
Crystals : อัลกอริธึม Crystals จะฝึกแบบ จำลอง ล่วงหน้าก่อน ซึ่งจะประเมินการโต้ตอบของฟีเจอร์แบบคู่ จากนั้นจะจัดเรียงชุดสุดท้ายในลักษณะที่คุณลักษณะที่มีการโต้ตอบที่ไม่ใช่เชิงเส้นมากกว่าจะอยู่ในโครงข่ายเดียวกัน
ทำไมต้อง TensorFlow Lattice
คุณสามารถดูคำแนะนำโดยย่อเกี่ยวกับ TensorFlow Lattice ได้ใน โพสต์บล็อก TF นี้
การตีความ
เนื่องจากพารามิเตอร์ของแต่ละเลเยอร์เป็นเอาท์พุตของเลเยอร์นั้น จึงง่ายต่อการวิเคราะห์ ทำความเข้าใจ และดีบักแต่ละส่วนของโมเดล
โมเดลที่แม่นยำและยืดหยุ่น
เมื่อใช้ขัดแตะแบบละเอียด คุณจะได้รับฟังก์ชัน ที่ซับซ้อนโดยพลการ ด้วยชั้นขัดแตะชั้นเดียว การใช้เครื่องสอบเทียบและแลตทิชหลายชั้นมักจะทำงานได้ดีในทางปฏิบัติ และสามารถจับคู่หรือมีประสิทธิภาพดีกว่าโมเดล DNN ที่มีขนาดใกล้เคียงกัน
ข้อจำกัดของรูปร่างสามัญสำนึก
ข้อมูลการฝึกอบรมในโลกแห่งความเป็นจริงอาจไม่เพียงพอต่อการแสดงข้อมูลรันไทม์ โซลูชัน ML ที่ยืดหยุ่น เช่น DNN หรือฟอเรสต์ มักดำเนินการอย่างไม่คาดคิดและถึงขั้นรุนแรงในบางส่วนของพื้นที่ป้อนข้อมูลที่ไม่ครอบคลุมอยู่ในข้อมูลการฝึกอบรม พฤติกรรมนี้เป็นปัญหาโดยเฉพาะอย่างยิ่งเมื่อมีการละเมิดข้อจำกัดด้านนโยบายหรือความเป็นธรรม
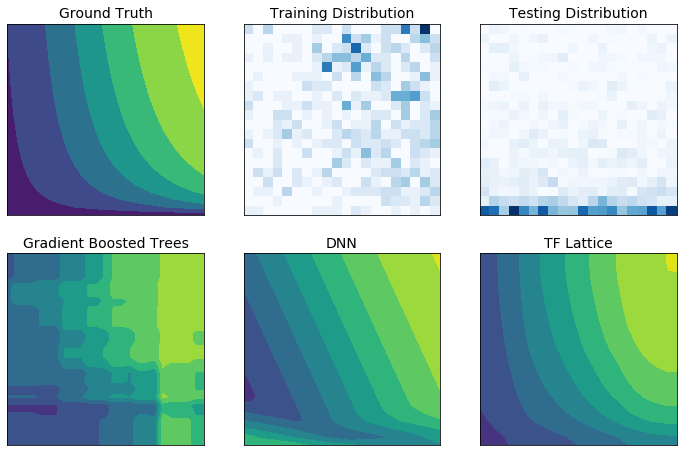
แม้ว่ารูปแบบทั่วไปของการทำให้เป็นมาตรฐานอาจส่งผลให้เกิดการประมาณค่าที่สมเหตุสมผลมากขึ้น แต่ตัวปรับมาตรฐานไม่สามารถรับประกันพฤติกรรมของโมเดลที่สมเหตุสมผลทั่วทั้งพื้นที่อินพุตทั้งหมด โดยเฉพาะอย่างยิ่งกับอินพุตมิติสูง การเปลี่ยนไปใช้โมเดลที่เรียบง่ายกว่าพร้อมพฤติกรรมที่ควบคุมและคาดการณ์ได้มากขึ้นอาจทำให้ความแม่นยำของโมเดลต้องเสียค่าใช้จ่ายสูง
TF Lattice ทำให้สามารถใช้แบบจำลองที่ยืดหยุ่นต่อไปได้ แต่มีตัวเลือกมากมายในการแทรกความรู้โดเมนเข้าไปในกระบวนการเรียนรู้ผ่าน ข้อจำกัดด้านรูปร่าง ที่มีความหมายตามความหมายหรือตามนโยบาย:
- Monotonicity : คุณสามารถระบุได้ว่าเอาต์พุตควรเพิ่ม/ลดตามอินพุตเท่านั้น ในตัวอย่างของเรา คุณอาจต้องการระบุว่าระยะทางที่เพิ่มขึ้นไปยังร้านกาแฟควรลดการตั้งค่าของผู้ใช้ที่คาดการณ์ไว้เท่านั้น
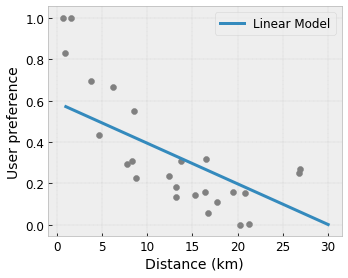
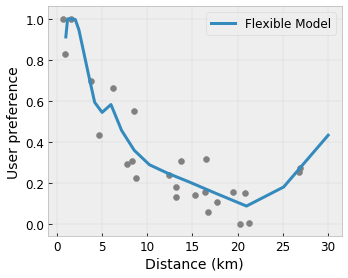
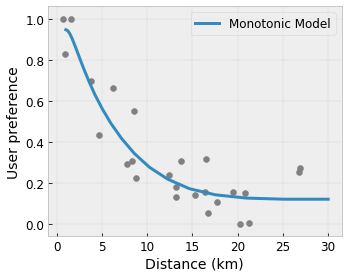
Concavity/Concavity : คุณสามารถระบุได้ว่ารูปร่างของฟังก์ชันสามารถนูนหรือเว้าได้ เมื่อผสมกับความซ้ำซากจำเจ สิ่งนี้สามารถบังคับให้ฟังก์ชันแสดงผลตอบแทนที่ลดลงตามคุณสมบัติที่กำหนด
Unimodality : คุณสามารถระบุได้ว่าฟังก์ชันควรมีจุดสูงสุดหรือหุบเขาที่ไม่ซ้ำใคร ซึ่งช่วยให้คุณแสดงฟังก์ชันที่มี จุดที่น่าสนใจ เกี่ยวกับคุณลักษณะได้
ความไว้วางใจแบบคู่ : ข้อจำกัดนี้ใช้ได้กับคุณสมบัติคู่หนึ่ง และแนะนำว่าคุณสมบัติอินพุตหนึ่งรายการสะท้อนถึงความไว้วางใจในคุณสมบัติอื่นตามความหมาย ตัวอย่างเช่น จำนวนรีวิวที่มากขึ้นจะทำให้คุณมั่นใจมากขึ้นในการให้คะแนนดาวโดยเฉลี่ยของร้านอาหาร โมเดลจะมีความละเอียดอ่อนมากขึ้นเมื่อเทียบกับการให้ดาว (กล่าวคือ จะมีความชันมากขึ้นเมื่อเทียบกับการให้คะแนน) เมื่อจำนวนบทวิจารณ์สูงขึ้น
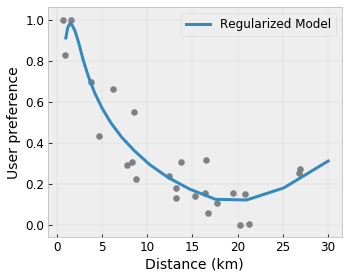
ควบคุมความยืดหยุ่นด้วย Regularizers
นอกเหนือจากข้อจำกัดด้านรูปร่างแล้ว TensorFlow lattice ยังมีตัวทำให้สม่ำเสมอจำนวนหนึ่งเพื่อควบคุมความยืดหยุ่นและความราบรื่นของฟังก์ชันสำหรับแต่ละเลเยอร์
Laplacian Regularizer : เอาท์พุตของแลตทิซ/จุดยอดการสอบเทียบ/จุดสำคัญจะถูกทำให้เป็นมาตรฐานตามค่าของเพื่อนบ้านที่เกี่ยวข้อง ส่งผลให้ฟังก์ชัน เรียบขึ้น
Hessian Regularizer : สิ่งนี้จะลงโทษอนุพันธ์อันดับหนึ่งของเลเยอร์การสอบเทียบ PWL เพื่อให้ฟังก์ชัน เป็นเส้นตรงมากขึ้น
Wrinkle Regularizer : สิ่งนี้จะลงโทษอนุพันธ์อันดับสองของชั้นการสอบเทียบ PWL เพื่อหลีกเลี่ยงการเปลี่ยนแปลงความโค้งกะทันหัน มันทำให้การทำงานราบรื่นขึ้น
Torsion Regularizer : ผลลัพธ์ของโครงตาข่ายจะถูกทำให้เป็นมาตรฐานเพื่อป้องกันการบิดงอระหว่างคุณสมบัติต่างๆ กล่าวอีกนัยหนึ่ง โมเดลจะถูกทำให้เป็นมาตรฐานโดยคำนึงถึงความเป็นอิสระระหว่างการมีส่วนร่วมของฟีเจอร์ต่างๆ
ผสมและจับคู่กับเลเยอร์ Keras อื่น ๆ
คุณสามารถใช้เลเยอร์ TF Lattice ร่วมกับเลเยอร์ Keras อื่นๆ เพื่อสร้างโมเดลที่มีข้อจำกัดบางส่วนหรือโมเดลที่ทำให้เป็นมาตรฐานได้ ตัวอย่างเช่น สามารถใช้เลเยอร์การปรับเทียบ Lattice หรือ PWL ในเลเยอร์สุดท้ายของเครือข่ายที่ลึกกว่าซึ่งรวมถึงการฝังหรือเลเยอร์ Keras อื่นๆ
เอกสาร
- จริยธรรมทางทันตกรรมโดยข้อจำกัดด้านรูปร่างที่น่าเบื่อหน่าย , Serena Wang, Maya Gupta, การประชุมนานาชาติด้านปัญญาประดิษฐ์และสถิติ (AISTATS), 2020
- ข้อจำกัดด้านรูปร่างสำหรับฟังก์ชันการตั้งค่า , Andrew Cotter, Maya Gupta, H. Jiang, Erez Louidor, Jim Muller, Taman Narayan, Serena Wang, Tao Zhu การประชุมนานาชาติเรื่องการเรียนรู้ของเครื่อง (ICML) ปี 2562
- ข้อจำกัดด้านรูปร่างของผลตอบแทนที่ลดลงสำหรับการตีความและการทำให้เป็นมาตรฐาน , Maya Gupta, Dara Bahri, Andrew Cotter, Kevin Canini, ความก้าวหน้าในระบบประมวลผลสารสนเทศทางประสาท (NeurIPS), 2018
- เครือข่าย Deep Lattice และฟังก์ชัน Monotonic บางส่วน , Seungil You, Kevin Canini, David Ding, Jan Pfeifer, Maya R. Gupta, ความก้าวหน้าในระบบประมวลผลข้อมูลประสาท (NeurIPS), 2017
- ฟังก์ชั่นโมโนโทนิกที่รวดเร็วและยืดหยุ่นพร้อมชุด Lattices , Mahdi Milani Fard, Kevin Canini, Andrew Cotter, Jan Pfeifer, Maya Gupta, ความก้าวหน้าในระบบประมวลผลข้อมูลประสาท (NeurIPS), 2016
- ตารางค้นหาแบบ Interpolated ที่ปรับเทียบ Monotonic , Maya Gupta, Andrew Cotter, Jan Pfeifer, Konstantin Voevodski, Kevin Canini, Alexander Mangylov, Wojciech Moczydlowski, Alexander van Esbroeck, วารสาร Machine Learning Research (JMLR), 2016
- การถดถอยที่ปรับให้เหมาะสมเพื่อการประเมินฟังก์ชันที่มีประสิทธิภาพ , Eric Garcia, Raman Arora, Maya R. Gupta, ธุรกรรม IEEE เกี่ยวกับการประมวลผลภาพ, 2012
- Lattice Regression , Eric Garcia, Maya Gupta, ความก้าวหน้าในระบบประมวลผลข้อมูลประสาท (NeurIPS), 2009
บทช่วยสอนและเอกสาร API
สำหรับสถาปัตยกรรมโมเดลทั่วไป คุณสามารถใช้ โมเดลที่สร้างไว้ล่วงหน้าของ Keras ได้ คุณยังสามารถสร้างโมเดลแบบกำหนดเองโดยใช้ เลเยอร์ TF Lattice Keras หรือมิกซ์แอนด์แมตช์กับเลเยอร์ Keras อื่นๆ ได้อีกด้วย ตรวจสอบ เอกสาร API ฉบับเต็ม เพื่อดูรายละเอียด