
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ภาพรวม
บทช่วยสอนนี้เป็นภาพรวมของข้อจำกัดและตัวปรับมาตรฐานที่จัดเตรียมโดยไลบรารี TensorFlow Lattice (TFL) ที่นี่เราใช้ตัวประมาณค่ากระป๋อง TFL กับชุดข้อมูลสังเคราะห์ แต่โปรดทราบว่าทุกอย่างในบทช่วยสอนนี้สามารถทำได้ด้วยแบบจำลองที่สร้างจากเลเยอร์ TFL Keras
ก่อนดำเนินการต่อ ตรวจสอบให้แน่ใจว่ารันไทม์ของคุณมีแพ็คเกจที่จำเป็นทั้งหมดติดตั้งอยู่ (ตามที่นำเข้ามาในเซลล์โค้ดด้านล่าง)
ติดตั้ง
การติดตั้งแพ็คเกจ TF Lattice:
pip install -q tensorflow-lattice
การนำเข้าแพ็คเกจที่จำเป็น:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
ค่าเริ่มต้นที่ใช้ในคู่มือนี้:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
ชุดข้อมูลการฝึกอบรมสำหรับการจัดอันดับร้านอาหาร
ลองนึกภาพสถานการณ์ง่ายๆ ที่เราต้องการตัดสินว่าผู้ใช้จะคลิกผลการค้นหาร้านอาหารหรือไม่ งานคือการคาดการณ์อัตราการคลิกผ่าน (CTR) ที่กำหนดคุณสมบัติการป้อนข้อมูล:
- คะแนนเฉลี่ย (
avg_rating): คุณลักษณะที่เป็นตัวเลขที่มีค่าในช่วง [1,5] - จำนวนความคิดเห็น (
num_reviews): คุณลักษณะที่เป็นตัวเลขที่มีค่าต่อยอดที่ 200 ซึ่งเราใช้เป็นตัวชี้วัดของ trendiness - คะแนนดอลลาร์ (
dollar_rating): คุณลักษณะเด็ดขาดด้วยค่าสตริงในชุด { "D", "DD", "DDD", "DDDD"}
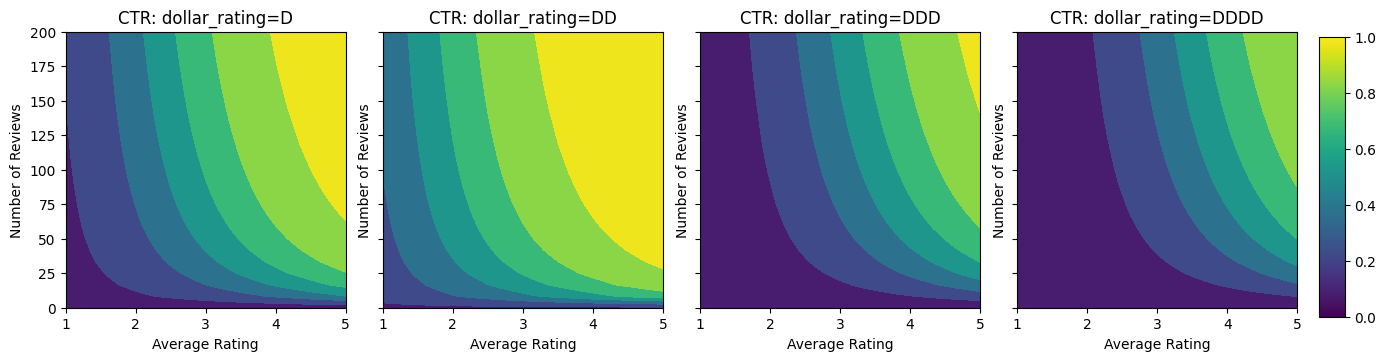
ที่นี่ เราสร้างชุดข้อมูลสังเคราะห์โดยที่สูตรกำหนด CTR จริง:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
ที่ \(b(\cdot)\) แปลแต่ละ dollar_rating กับมูลค่าพื้นฐาน:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
สูตรนี้สะท้อนถึงรูปแบบผู้ใช้ทั่วไป เช่น เมื่อแก้ไขทุกอย่างแล้ว ผู้ใช้ชอบร้านอาหารที่มีระดับดาวสูงกว่า และร้านอาหาร "\$\$" จะได้รับคลิกมากกว่า "\$" ตามด้วย "\$\$\$" และ "\$\$\$ \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
มาดูแผนภาพของฟังก์ชัน CTR กัน
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
กำลังเตรียมข้อมูล
ตอนนี้เราจำเป็นต้องสร้างชุดข้อมูลสังเคราะห์ของเรา เราเริ่มต้นด้วยการสร้างชุดข้อมูลจำลองร้านอาหารและคุณลักษณะต่างๆ
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
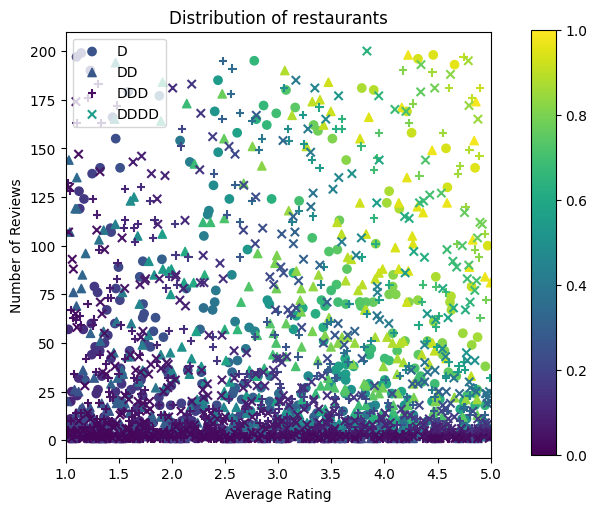
มาสร้างชุดข้อมูลการฝึกอบรม การตรวจสอบ และการทดสอบกัน เมื่อมีการดูร้านอาหารในผลการค้นหา เราสามารถบันทึกการมีส่วนร่วมของผู้ใช้ (คลิกหรือไม่คลิก) เป็นจุดตัวอย่าง
ในทางปฏิบัติ ผู้ใช้มักจะไม่อ่านผลการค้นหาทั้งหมด ซึ่งหมายความว่าผู้ใช้มักจะเห็นเฉพาะร้านอาหารที่ถือว่า "ดี" แล้วตามรูปแบบการจัดอันดับที่ใช้งานอยู่ในปัจจุบัน ด้วยเหตุนี้ ร้านอาหารที่ "ดี" จึงมักจะประทับใจและนำเสนอมากเกินไปในชุดข้อมูลการฝึกอบรม เมื่อใช้คุณลักษณะเพิ่มเติม ชุดข้อมูลการฝึกอบรมอาจมีช่องว่างขนาดใหญ่ในส่วนที่ "ไม่ดี" ของพื้นที่คุณลักษณะ
เมื่อใช้แบบจำลองสำหรับการจัดอันดับ มักจะได้รับการประเมินในผลลัพธ์ที่เกี่ยวข้องทั้งหมดด้วยการกระจายที่สม่ำเสมอกว่าซึ่งไม่ได้นำเสนออย่างดีโดยชุดข้อมูลการฝึกอบรม โมเดลที่ยืดหยุ่นและซับซ้อนอาจล้มเหลวในกรณีนี้เนื่องจากการใส่จุดข้อมูลที่มีการแสดงมากเกินไปจนเกินพอดี และทำให้ขาดความสามารถในการสรุปรวม เราจัดการปัญหานี้โดยใช้ความรู้ในการเพิ่มโดเมน จำกัด รูปร่างที่เป็นแนวทางในรูปแบบที่จะทำให้การคาดการณ์ที่เหมาะสมเมื่อมันไม่สามารถเลือกพวกเขาขึ้นมาจากชุดข้อมูลการฝึกอบรม
ในตัวอย่างนี้ ชุดข้อมูลการฝึกอบรมส่วนใหญ่ประกอบด้วยการโต้ตอบของผู้ใช้กับร้านอาหารที่ดีและเป็นที่นิยม ชุดข้อมูลการทดสอบมีการกระจายแบบสม่ำเสมอเพื่อจำลองการตั้งค่าการประเมินที่กล่าวถึงข้างต้น โปรดทราบว่าชุดข้อมูลการทดสอบดังกล่าวจะไม่พร้อมใช้งานในการตั้งค่าปัญหาจริง
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

การกำหนด input_fns ที่ใช้สำหรับการฝึกอบรมและการประเมิน:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
เหมาะสมการไล่ระดับต้นไม้ที่เพิ่มขึ้น
ขอเริ่มต้นด้วยเพียงสองคุณสมบัติ: avg_rating และ num_reviews
เราสร้างฟังก์ชันเสริมบางอย่างสำหรับการพล็อตและคำนวณการตรวจสอบความถูกต้องและเมตริกการทดสอบ
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
เราสามารถใส่แผนผังการตัดสินใจที่เพิ่มการไล่ระดับสีของ TensorFlow ลงในชุดข้อมูลได้:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

แม้ว่าแบบจำลองจะจับรูปร่างทั่วไปของ CTR ที่แท้จริงและมีตัววัดการตรวจสอบที่เหมาะสม แต่ก็มีพฤติกรรมที่ตอบโต้กับสัญชาตญาณในหลายส่วนของพื้นที่ป้อนข้อมูล: CTR โดยประมาณจะลดลงเมื่อคะแนนเฉลี่ยหรือจำนวนบทวิจารณ์เพิ่มขึ้น เนื่องจากขาดจุดตัวอย่างในพื้นที่ที่ชุดข้อมูลการฝึกอบรมไม่ครอบคลุม โมเดลไม่มีทางสรุปพฤติกรรมที่ถูกต้องได้จากข้อมูลเพียงอย่างเดียว
ในการแก้ปัญหานี้ เราบังคับใช้ข้อจำกัดด้านรูปร่างที่โมเดลต้องแสดงค่าที่เพิ่มขึ้นอย่างซ้ำซากจำเจ โดยคำนึงถึงทั้งคะแนนเฉลี่ยและจำนวนรีวิว เราจะมาดูวิธีการนำไปใช้ใน TFL ในภายหลัง
การติดตั้ง DNN
เราสามารถทำซ้ำขั้นตอนเดียวกันกับตัวแยกประเภท DNN เราสามารถสังเกตรูปแบบที่คล้ายคลึงกัน: การมีจุดตัวอย่างไม่เพียงพอกับบทวิจารณ์จำนวนน้อยส่งผลให้เกิดการประมาณการที่ไร้สาระ โปรดทราบว่าแม้ว่าตัววัดการตรวจสอบความถูกต้องจะดีกว่าโซลูชันแบบต้นไม้ แต่ตัววัดการทดสอบนั้นแย่กว่ามาก
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

ข้อจำกัดรูปร่าง
TensorFlow Lattice (TFL) มุ่งเน้นไปที่การบังคับใช้ข้อจำกัดด้านรูปร่างเพื่อปกป้องพฤติกรรมของโมเดลนอกเหนือจากข้อมูลการฝึก ข้อจำกัดรูปร่างเหล่านี้ใช้กับเลเยอร์ TFL Keras รายละเอียดของพวกเขาสามารถพบได้ใน กระดาษ JMLR ของเรา
ในบทช่วยสอนนี้ เราใช้ตัวประมาณค่ากระป๋อง TF เพื่อครอบคลุมข้อจำกัดของรูปร่างต่างๆ แต่โปรดทราบว่าขั้นตอนเหล่านี้สามารถทำได้ด้วยแบบจำลองที่สร้างจากเลเยอร์ TFL Keras
เช่นเดียวกับการประมาณการ TensorFlow อื่น ๆ TFL กระป๋องประมาณค่าใช้ คอลัมน์คุณลักษณะ ในการกำหนดรูปแบบการป้อนข้อมูลและใช้ input_fn การฝึกอบรมที่จะผ่านในข้อมูล การใช้ตัวประมาณค่ากระป๋อง TFL ยังต้องการ:
- การตั้งค่ารูปแบบ: การกำหนดสถาปัตยกรรมรูปแบบและต่อคุณลักษณะ จำกัด รูปร่างและ regularizers
- input_fn คุณลักษณะการวิเคราะห์: ก TF input_fn ผ่านข้อมูลสำหรับการเริ่มต้น TFL
สำหรับคำอธิบายที่ละเอียดยิ่งขึ้น โปรดดูบทแนะนำเครื่องมือประมาณค่าสำเร็จรูปหรือเอกสาร API
ความน่าเบื่อ
อันดับแรก เราจัดการกับข้อกังวลเรื่องความซ้ำซากจำเจโดยเพิ่มข้อจำกัดรูปร่างแบบโมโนโทนิกในทั้งสองคุณลักษณะ
การออกคำสั่ง TFL ในการบังคับใช้ข้อ จำกัด รูปร่างเราระบุข้อ จำกัด ในการกำหนดค่าคุณลักษณะ แสดงให้เห็นว่ารหัสต่อไปนี้วิธีการที่เราจะต้องออกไปเป็น monotonically เพิ่มขึ้นด้วยความเคารพทั้ง num_reviews และ avg_rating โดยการตั้งค่า monotonicity="increasing"
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

ใช้ CalibratedLatticeConfig สร้างลักษณนามกระป๋องแรกที่ใช้สอบเทียบให้กับแต่ละอินพุท (ชิ้นฉลาดฟังก์ชั่นเชิงเส้นสำหรับคุณสมบัติที่เป็นตัวเลข) ตามด้วยชั้นตาข่ายที่ไม่เป็นเส้นตรงฟิวส์คุณสมบัติปรับเทียบ เราสามารถใช้ tfl.visualization ที่จะเห็นภาพแบบ โดยเฉพาะอย่างยิ่ง แผนภาพต่อไปนี้แสดงเครื่องสอบเทียบที่ได้รับการฝึกอบรมสองตัวที่รวมอยู่ในตัวแยกประเภทแบบกระป๋อง
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

เมื่อเพิ่มข้อจำกัด CTR โดยประมาณจะเพิ่มขึ้นเสมอเมื่อคะแนนเฉลี่ยเพิ่มขึ้นหรือจำนวนบทวิจารณ์เพิ่มขึ้น ทำได้โดยตรวจสอบให้แน่ใจว่าเครื่องสอบเทียบและโครงตาข่ายเป็นแบบโมโนโทนิก
ผลตอบแทนลดลง
ผลตอบแทนลดลง หมายความว่ากำไรส่วนเพิ่มของการเพิ่มค่าคุณลักษณะบางอย่างจะลดลงในขณะที่เราเพิ่มค่า ในกรณีที่เราคาดหวังว่า num_reviews คุณลักษณะตามรูปแบบนี้เพื่อให้เราสามารถกำหนดค่าสอบเทียบตามความเหมาะสม ขอให้สังเกตว่า เราสามารถแบ่งผลตอบแทนที่ลดลงออกเป็นสองเงื่อนไขที่เพียงพอ:
- เครื่องสอบเทียบเพิ่มขึ้นแบบโมโนโทนิกและ
- เครื่องสอบเทียบเว้า
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
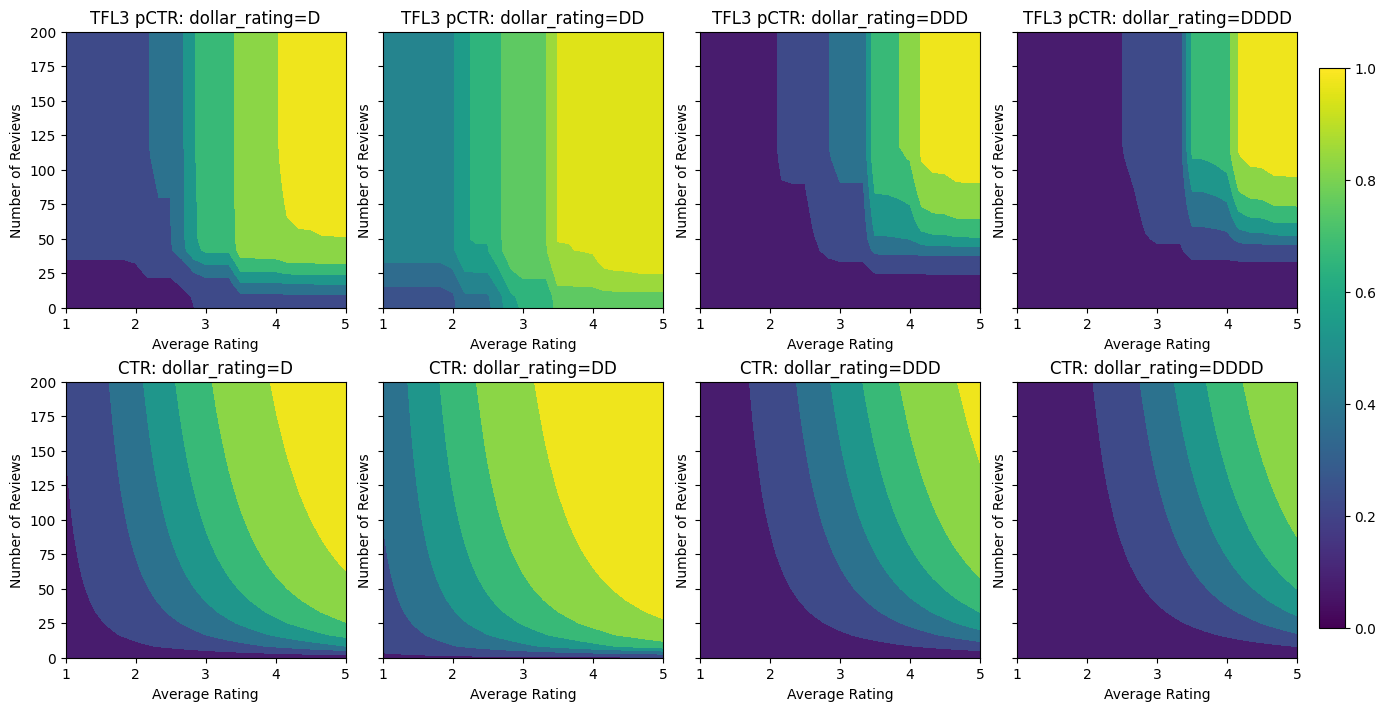

สังเกตว่าเมตริกการทดสอบดีขึ้นอย่างไรโดยการเพิ่มข้อจำกัดความเว้า พล็อตการทำนายยังคล้ายกับความจริงพื้น
ข้อจำกัดรูปร่าง 2 มิติ: ความน่าเชื่อถือ
การให้คะแนน 5 ดาวสำหรับร้านอาหารที่มีรีวิวเพียงหนึ่งหรือสองรายการมีแนวโน้มว่าจะเป็นคะแนนที่ไม่น่าเชื่อถือ (ร้านอาหารอาจไม่ค่อยดีนัก) ในขณะที่การให้คะแนนระดับ 4 ดาวสำหรับร้านอาหารที่มีรีวิวหลายร้อยรายการนั้นน่าเชื่อถือกว่ามาก (ร้านอาหารมีความน่าเชื่อถือมากกว่า ก็น่าจะดีในกรณีนี้) เราจะเห็นได้ว่าจำนวนรีวิวของร้านอาหารส่งผลต่อความไว้วางใจที่เราให้ไว้ในคะแนนเฉลี่ย
เราสามารถใช้ข้อจำกัดความเชื่อถือ TFL เพื่อแจ้งแบบจำลองว่าค่าที่มากกว่า (หรือน้อยกว่า) ของคุณลักษณะหนึ่งบ่งบอกถึงการพึ่งพาหรือความเชื่อถือของคุณลักษณะอื่นมากขึ้น นี้จะกระทำโดยการตั้งค่า reflects_trust_in การกำหนดค่าในการตั้งค่าคุณลักษณะ
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
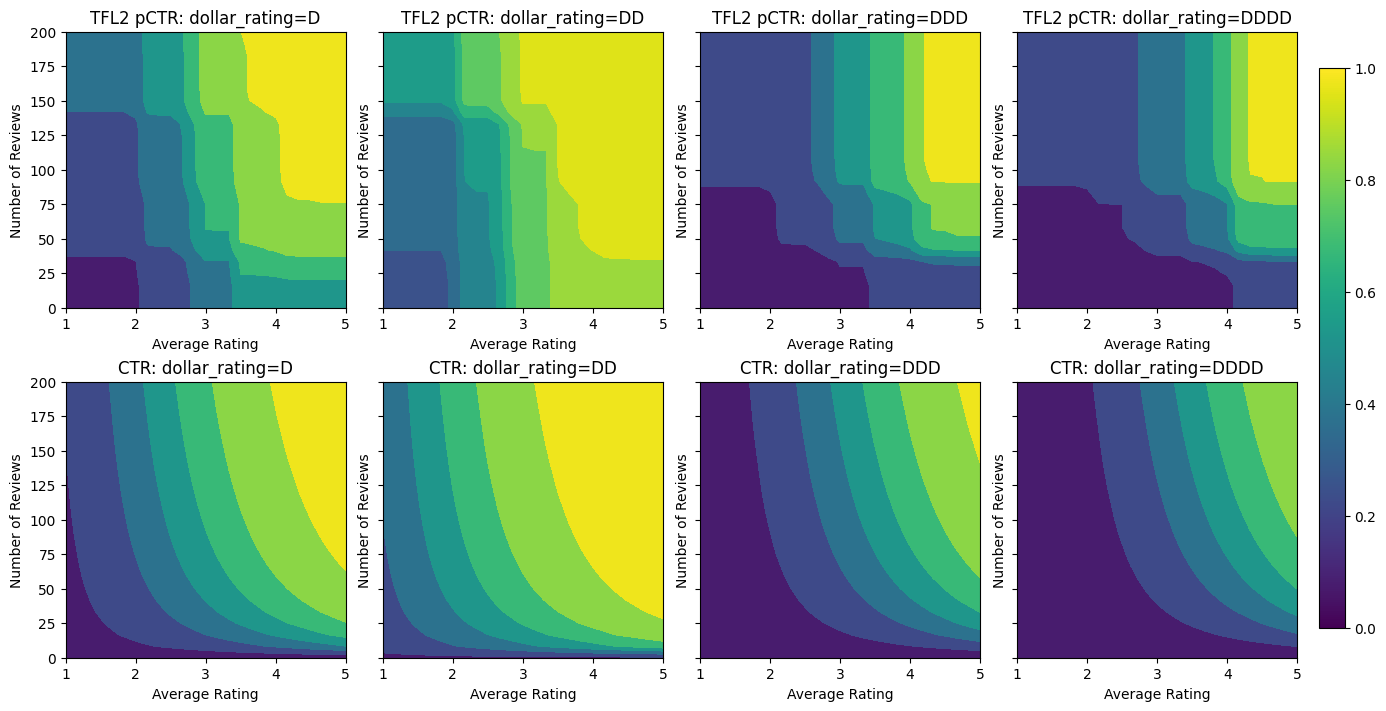

พล็อตต่อไปนี้แสดงฟังก์ชันขัดแตะที่ผ่านการฝึกอบรม เนื่องจากข้อ จำกัด ความไว้วางใจเราคาดว่าค่าขนาดใหญ่ของการสอบเทียบ num_reviews จะบังคับความลาดชันสูงเกี่ยวกับการสอบเทียบ avg_rating ส่งผลในการย้ายสำคัญมากขึ้นในการส่งออกตาข่าย
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
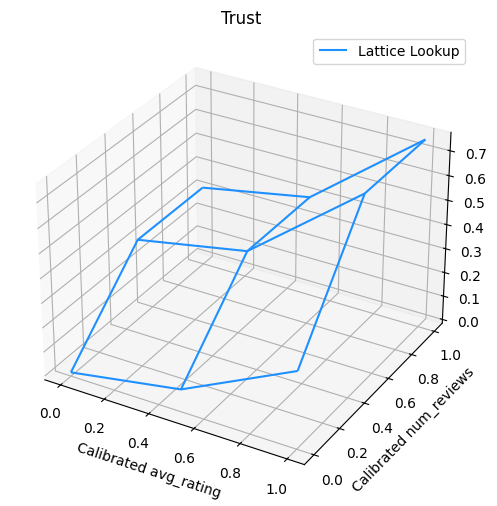
การปรับเทียบให้เรียบ
ตอนนี้ขอใช้เวลาดูที่สอบเทียบของที่ avg_rating แม้ว่าจะมีการเพิ่มขึ้นอย่างซ้ำซากจำเจ แต่การเปลี่ยนแปลงในเนินลาดนั้นกระทันหันและยากที่จะตีความ ที่แสดงให้เห็นว่าเราอาจต้องการที่จะต้องพิจารณาการปรับให้เรียบสอบเทียบนี้โดยใช้การตั้งค่า regularizer ใน regularizer_configs
ที่นี่เราใช้ wrinkle regularizer เพื่อลดการเปลี่ยนแปลงในโค้ง นอกจากนี้คุณยังสามารถใช้ laplacian regularizer จะแผ่สอบเทียบและ hessian regularizer ที่จะทำให้มันเส้นตรง
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


ขณะนี้เครื่องสอบเทียบมีความราบรื่น และ CTR โดยประมาณโดยรวมตรงกับความจริงภาคพื้นดินมากขึ้น สิ่งนี้สะท้อนให้เห็นทั้งในเมตริกการทดสอบและในแผนภาพ
ความซ้ำซากจำเจบางส่วนสำหรับการสอบเทียบตามหมวดหมู่
จนถึงตอนนี้ เราใช้คุณสมบัติตัวเลขเพียงสองอย่างในแบบจำลองนี้ ที่นี่เราจะเพิ่มคุณสมบัติที่สามโดยใช้ชั้นการสอบเทียบตามหมวดหมู่ เราเริ่มต้นด้วยการตั้งค่าฟังก์ชันตัวช่วยสำหรับการพล็อตและการคำนวณเมตริก
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
ที่จะเกี่ยวข้องกับคุณลักษณะที่สาม dollar_rating เราควรจะจำได้ว่าคุณสมบัติเด็ดขาดต้องมีการรักษาที่แตกต่างกันเล็กน้อยใน TFL ทั้งคอลัมน์คุณลักษณะและเป็นคุณลักษณะการกำหนดค่า ที่นี่เราบังคับใช้ข้อจำกัดความซ้ำซากจำเจบางส่วนที่เอาต์พุตสำหรับร้านอาหาร "DD" ควรมากกว่าร้านอาหาร "D" เมื่ออินพุตอื่น ๆ ทั้งหมดได้รับการแก้ไข นี้จะกระทำโดยใช้ monotonicity การตั้งค่าในการตั้งค่าคุณลักษณะ
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


เครื่องสอบเทียบตามหมวดหมู่นี้แสดงการตั้งค่าเอาต์พุตของแบบจำลอง: DD > D > DDD > DDDD ซึ่งสอดคล้องกับการตั้งค่าของเรา สังเกตว่ายังมีคอลัมน์สำหรับค่าที่หายไป แม้ว่าจะไม่มีคุณลักษณะที่ขาดหายไปในข้อมูลการฝึกอบรมและการทดสอบของเรา แต่แบบจำลองนี้ให้ข้อมูลแก่เราว่าค่าที่ขาดหายไปควรเกิดขึ้นระหว่างการให้บริการโมเดลดาวน์สตรีม
ที่นี่เรายังพล็อตที่คาดการณ์ CTR ของรุ่นนี้ปรับอากาศใน dollar_rating ขอให้สังเกตว่าข้อ จำกัด ทั้งหมดที่เราต้องการได้รับการเติมเต็มในแต่ละส่วน
การสอบเทียบเอาต์พุต
สำหรับโมเดล TFL ทั้งหมดที่เราฝึกมาจนถึงตอนนี้ เลเยอร์แลตทิซ (ระบุเป็น "แลตทิซ" ในกราฟโมเดล) จะส่งเอาต์พุตการทำนายโมเดลโดยตรง บางครั้งเราไม่แน่ใจว่าควรปรับขนาดเอาต์พุตแลตทิซเพื่อปล่อยเอาต์พุตของโมเดลหรือไม่:
- คุณสมบัติที่มี \(log\) ข้อหาขณะที่ป้ายชื่อที่มีการนับจำนวน
- โครงตาข่ายได้รับการกำหนดค่าให้มีจุดยอดน้อยมาก แต่การกระจายฉลากค่อนข้างซับซ้อน
ในกรณีเหล่านี้ เราสามารถเพิ่มตัวสอบเทียบอื่นระหว่างเอาต์พุตแลตทิซและเอาต์พุตของโมเดล เพื่อเพิ่มความยืดหยุ่นของโมเดล ในที่นี้ มาเพิ่มเลเยอร์เครื่องสอบเทียบที่มีจุดสำคัญ 5 จุดให้กับแบบจำลองที่เราเพิ่งสร้างขึ้น นอกจากนี้เรายังเพิ่มตัวปรับมาตรฐานสำหรับตัวปรับเทียบเอาต์พุตเพื่อให้ฟังก์ชันทำงานได้อย่างราบรื่น
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


เมตริกและแผนภาพการทดสอบขั้นสุดท้ายแสดงให้เห็นว่าการใช้ข้อจำกัดทั่วไปช่วยให้โมเดลหลีกเลี่ยงพฤติกรรมที่ไม่คาดคิดและคาดการณ์ได้ดียิ่งขึ้นสำหรับพื้นที่อินพุตทั้งหมด
,| | | ดูแหล่งที่มาบน GitHub | |
ภาพรวม
บทช่วยสอนนี้เป็นภาพรวมของข้อจำกัดและตัวปรับมาตรฐานที่จัดเตรียมโดยไลบรารี TensorFlow Lattice (TFL) ที่นี่เราใช้ตัวประมาณค่ากระป๋อง TFL กับชุดข้อมูลสังเคราะห์ แต่โปรดทราบว่าทุกอย่างในบทช่วยสอนนี้สามารถทำได้ด้วยแบบจำลองที่สร้างจากเลเยอร์ TFL Keras
ก่อนดำเนินการต่อ ตรวจสอบให้แน่ใจว่ารันไทม์ของคุณมีแพ็คเกจที่จำเป็นทั้งหมดติดตั้งอยู่ (ตามที่นำเข้ามาในเซลล์โค้ดด้านล่าง)
ติดตั้ง
การติดตั้งแพ็คเกจ TF Lattice:
pip install -q tensorflow-lattice
การนำเข้าแพ็คเกจที่จำเป็น:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
ค่าเริ่มต้นที่ใช้ในคู่มือนี้:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
ชุดข้อมูลการฝึกอบรมสำหรับการจัดอันดับร้านอาหาร
ลองนึกภาพสถานการณ์ง่ายๆ ที่เราต้องการตัดสินว่าผู้ใช้จะคลิกผลการค้นหาร้านอาหารหรือไม่ งานคือการคาดการณ์อัตราการคลิกผ่าน (CTR) ที่กำหนดคุณสมบัติการป้อนข้อมูล:
- คะแนนเฉลี่ย (
avg_rating): คุณลักษณะที่เป็นตัวเลขที่มีค่าในช่วง [1,5] - จำนวนความคิดเห็น (
num_reviews): คุณลักษณะที่เป็นตัวเลขที่มีค่าต่อยอดที่ 200 ซึ่งเราใช้เป็นตัวชี้วัดของ trendiness - คะแนนดอลลาร์ (
dollar_rating): คุณลักษณะเด็ดขาดด้วยค่าสตริงในชุด { "D", "DD", "DDD", "DDDD"}
ที่นี่ เราสร้างชุดข้อมูลสังเคราะห์โดยที่สูตรกำหนด CTR จริง:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
ที่ \(b(\cdot)\) แปลแต่ละ dollar_rating กับมูลค่าพื้นฐาน:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
สูตรนี้สะท้อนถึงรูปแบบผู้ใช้ทั่วไป เช่น เมื่อแก้ไขทุกอย่างแล้ว ผู้ใช้ชอบร้านอาหารที่มีระดับดาวสูงกว่า และร้านอาหาร "\$\$" จะได้รับคลิกมากกว่า "\$" ตามด้วย "\$\$\$" และ "\$\$\$ \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
มาดูแผนภาพของฟังก์ชัน CTR กัน
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
กำลังเตรียมข้อมูล
ตอนนี้เราจำเป็นต้องสร้างชุดข้อมูลสังเคราะห์ของเรา เราเริ่มต้นด้วยการสร้างชุดข้อมูลจำลองร้านอาหารและคุณลักษณะต่างๆ
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
มาสร้างชุดข้อมูลการฝึกอบรม การตรวจสอบ และการทดสอบกัน เมื่อมีการดูร้านอาหารในผลการค้นหา เราสามารถบันทึกการมีส่วนร่วมของผู้ใช้ (คลิกหรือไม่คลิก) เป็นจุดตัวอย่าง
ในทางปฏิบัติ ผู้ใช้มักจะไม่อ่านผลการค้นหาทั้งหมด ซึ่งหมายความว่าผู้ใช้มักจะเห็นเฉพาะร้านอาหารที่ถือว่า "ดี" แล้วตามรูปแบบการจัดอันดับที่ใช้งานอยู่ในปัจจุบัน ด้วยเหตุนี้ ร้านอาหารที่ "ดี" จึงมักจะประทับใจและนำเสนอมากเกินไปในชุดข้อมูลการฝึกอบรม เมื่อใช้คุณลักษณะเพิ่มเติม ชุดข้อมูลการฝึกอบรมอาจมีช่องว่างขนาดใหญ่ในส่วนที่ "ไม่ดี" ของพื้นที่คุณลักษณะ
เมื่อใช้แบบจำลองสำหรับการจัดอันดับ มักจะได้รับการประเมินในผลลัพธ์ที่เกี่ยวข้องทั้งหมดด้วยการกระจายที่สม่ำเสมอกว่าซึ่งไม่ได้นำเสนออย่างดีโดยชุดข้อมูลการฝึกอบรม โมเดลที่ยืดหยุ่นและซับซ้อนอาจล้มเหลวในกรณีนี้เนื่องจากการใส่จุดข้อมูลที่มีการแสดงมากเกินไปจนเกินพอดี และทำให้ขาดความสามารถในการสรุปรวม เราจัดการปัญหานี้โดยใช้ความรู้ในการเพิ่มโดเมน จำกัด รูปร่างที่เป็นแนวทางในรูปแบบที่จะทำให้การคาดการณ์ที่เหมาะสมเมื่อมันไม่สามารถเลือกพวกเขาขึ้นมาจากชุดข้อมูลการฝึกอบรม
ในตัวอย่างนี้ ชุดข้อมูลการฝึกอบรมส่วนใหญ่ประกอบด้วยการโต้ตอบของผู้ใช้กับร้านอาหารที่ดีและเป็นที่นิยม ชุดข้อมูลการทดสอบมีการกระจายแบบสม่ำเสมอเพื่อจำลองการตั้งค่าการประเมินที่กล่าวถึงข้างต้น โปรดทราบว่าชุดข้อมูลการทดสอบดังกล่าวจะไม่พร้อมใช้งานในการตั้งค่าปัญหาจริง
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
การกำหนด input_fns ที่ใช้สำหรับการฝึกอบรมและการประเมิน:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
เหมาะสมการไล่ระดับต้นไม้ที่เพิ่มขึ้น
ขอเริ่มต้นด้วยเพียงสองคุณสมบัติ: avg_rating และ num_reviews
เราสร้างฟังก์ชันเสริมบางอย่างสำหรับการพล็อตและคำนวณการตรวจสอบความถูกต้องและเมตริกการทดสอบ
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
เราสามารถใส่แผนผังการตัดสินใจที่เพิ่มการไล่ระดับสีของ TensorFlow ลงในชุดข้อมูลได้:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
แม้ว่าแบบจำลองจะจับรูปร่างทั่วไปของ CTR ที่แท้จริงและมีตัววัดการตรวจสอบที่เหมาะสม แต่ก็มีพฤติกรรมที่ตอบโต้กับสัญชาตญาณในหลายส่วนของพื้นที่ป้อนข้อมูล: CTR โดยประมาณจะลดลงเมื่อคะแนนเฉลี่ยหรือจำนวนบทวิจารณ์เพิ่มขึ้น เนื่องจากขาดจุดตัวอย่างในพื้นที่ที่ชุดข้อมูลการฝึกอบรมไม่ครอบคลุม โมเดลไม่มีทางสรุปพฤติกรรมที่ถูกต้องได้จากข้อมูลเพียงอย่างเดียว
ในการแก้ปัญหานี้ เราบังคับใช้ข้อจำกัดด้านรูปร่างที่โมเดลต้องแสดงค่าที่เพิ่มขึ้นอย่างซ้ำซากจำเจ โดยคำนึงถึงทั้งคะแนนเฉลี่ยและจำนวนรีวิว เราจะมาดูวิธีการนำไปใช้ใน TFL ในภายหลัง
การติดตั้ง DNN
เราสามารถทำซ้ำขั้นตอนเดียวกันกับตัวแยกประเภท DNN เราสามารถสังเกตรูปแบบที่คล้ายคลึงกัน: การมีจุดตัวอย่างไม่เพียงพอกับบทวิจารณ์จำนวนน้อยส่งผลให้เกิดการประมาณการที่ไร้สาระ โปรดทราบว่าแม้ว่าตัววัดการตรวจสอบความถูกต้องจะดีกว่าโซลูชันแบบต้นไม้ แต่ตัววัดการทดสอบนั้นแย่กว่ามาก
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
ข้อจำกัดรูปร่าง
TensorFlow Lattice (TFL) มุ่งเน้นไปที่การบังคับใช้ข้อจำกัดด้านรูปร่างเพื่อปกป้องพฤติกรรมของโมเดลนอกเหนือจากข้อมูลการฝึก ข้อจำกัดรูปร่างเหล่านี้ใช้กับเลเยอร์ TFL Keras รายละเอียดของพวกเขาสามารถพบได้ใน กระดาษ JMLR ของเรา
ในบทช่วยสอนนี้ เราใช้ตัวประมาณค่ากระป๋อง TF เพื่อครอบคลุมข้อจำกัดของรูปร่างต่างๆ แต่โปรดทราบว่าขั้นตอนเหล่านี้สามารถทำได้ด้วยแบบจำลองที่สร้างจากเลเยอร์ TFL Keras
เช่นเดียวกับการประมาณการ TensorFlow อื่น ๆ TFL กระป๋องประมาณค่าใช้ คอลัมน์คุณลักษณะ ในการกำหนดรูปแบบการป้อนข้อมูลและใช้ input_fn การฝึกอบรมที่จะผ่านในข้อมูล การใช้ตัวประมาณค่ากระป๋อง TFL ยังต้องการ:
- การตั้งค่ารูปแบบ: การกำหนดสถาปัตยกรรมรูปแบบและต่อคุณลักษณะ จำกัด รูปร่างและ regularizers
- input_fn คุณลักษณะการวิเคราะห์: ก TF input_fn ผ่านข้อมูลสำหรับการเริ่มต้น TFL
สำหรับคำอธิบายที่ละเอียดยิ่งขึ้น โปรดดูบทแนะนำเครื่องมือประมาณค่าสำเร็จรูปหรือเอกสาร API
ความน่าเบื่อ
อันดับแรก เราจัดการกับข้อกังวลเรื่องความซ้ำซากจำเจโดยเพิ่มข้อจำกัดรูปร่างแบบโมโนโทนิกในทั้งสองคุณลักษณะ
การออกคำสั่ง TFL ในการบังคับใช้ข้อ จำกัด รูปร่างเราระบุข้อ จำกัด ในการกำหนดค่าคุณลักษณะ แสดงให้เห็นว่ารหัสต่อไปนี้วิธีการที่เราจะต้องออกไปเป็น monotonically เพิ่มขึ้นด้วยความเคารพทั้ง num_reviews และ avg_rating โดยการตั้งค่า monotonicity="increasing"
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
ใช้ CalibratedLatticeConfig สร้างลักษณนามกระป๋องแรกที่ใช้สอบเทียบให้กับแต่ละอินพุท (ชิ้นฉลาดฟังก์ชั่นเชิงเส้นสำหรับคุณสมบัติที่เป็นตัวเลข) ตามด้วยชั้นตาข่ายที่ไม่เป็นเส้นตรงฟิวส์คุณสมบัติปรับเทียบ เราสามารถใช้ tfl.visualization ที่จะเห็นภาพแบบ โดยเฉพาะอย่างยิ่ง แผนภาพต่อไปนี้แสดงเครื่องสอบเทียบที่ได้รับการฝึกอบรมสองตัวที่รวมอยู่ในตัวแยกประเภทแบบกระป๋อง
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
เมื่อเพิ่มข้อจำกัด CTR โดยประมาณจะเพิ่มขึ้นเสมอเมื่อคะแนนเฉลี่ยเพิ่มขึ้นหรือจำนวนบทวิจารณ์เพิ่มขึ้น ทำได้โดยตรวจสอบให้แน่ใจว่าเครื่องสอบเทียบและโครงตาข่ายเป็นแบบโมโนโทนิก
ผลตอบแทนลดลง
ผลตอบแทนลดลง หมายความว่ากำไรส่วนเพิ่มของการเพิ่มค่าคุณลักษณะบางอย่างจะลดลงในขณะที่เราเพิ่มค่า ในกรณีที่เราคาดหวังว่า num_reviews คุณลักษณะตามรูปแบบนี้เพื่อให้เราสามารถกำหนดค่าสอบเทียบตามความเหมาะสม ขอให้สังเกตว่า เราสามารถแบ่งผลตอบแทนที่ลดลงออกเป็นสองเงื่อนไขที่เพียงพอ:
- เครื่องสอบเทียบเพิ่มขึ้นแบบโมโนโทนิกและ
- เครื่องสอบเทียบเว้า
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
สังเกตว่าเมตริกการทดสอบดีขึ้นอย่างไรโดยการเพิ่มข้อจำกัดความเว้า พล็อตการทำนายยังคล้ายกับความจริงพื้น
ข้อจำกัดรูปร่าง 2 มิติ: ความน่าเชื่อถือ
การให้คะแนน 5 ดาวสำหรับร้านอาหารที่มีรีวิวเพียงหนึ่งหรือสองรายการมีแนวโน้มว่าจะเป็นคะแนนที่ไม่น่าเชื่อถือ (ร้านอาหารอาจไม่ค่อยดีนัก) ในขณะที่การให้คะแนนระดับ 4 ดาวสำหรับร้านอาหารที่มีรีวิวหลายร้อยรายการนั้นน่าเชื่อถือกว่ามาก (ร้านอาหารมีความน่าเชื่อถือมากกว่า ก็น่าจะดีในกรณีนี้) เราจะเห็นได้ว่าจำนวนรีวิวของร้านอาหารส่งผลต่อความไว้วางใจที่เราให้ไว้ในคะแนนเฉลี่ย
เราสามารถใช้ข้อจำกัดความเชื่อถือ TFL เพื่อแจ้งแบบจำลองว่าค่าที่มากกว่า (หรือน้อยกว่า) ของคุณลักษณะหนึ่งบ่งบอกถึงการพึ่งพาหรือความเชื่อถือของคุณลักษณะอื่นมากขึ้น นี้จะกระทำโดยการตั้งค่า reflects_trust_in การกำหนดค่าในการตั้งค่าคุณลักษณะ
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
พล็อตต่อไปนี้แสดงฟังก์ชันขัดแตะที่ผ่านการฝึกอบรม เนื่องจากข้อ จำกัด ความไว้วางใจเราคาดว่าค่าขนาดใหญ่ของการสอบเทียบ num_reviews จะบังคับความลาดชันสูงเกี่ยวกับการสอบเทียบ avg_rating ส่งผลในการย้ายสำคัญมากขึ้นในการส่งออกตาข่าย
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
การปรับเทียบให้เรียบ
ตอนนี้ขอใช้เวลาดูที่สอบเทียบของที่ avg_rating แม้ว่าจะมีการเพิ่มขึ้นอย่างซ้ำซากจำเจ แต่การเปลี่ยนแปลงในเนินลาดนั้นกระทันหันและยากที่จะตีความ ที่แสดงให้เห็นว่าเราอาจต้องการที่จะต้องพิจารณาการปรับให้เรียบสอบเทียบนี้โดยใช้การตั้งค่า regularizer ใน regularizer_configs
ที่นี่เราใช้ wrinkle regularizer เพื่อลดการเปลี่ยนแปลงในโค้ง นอกจากนี้คุณยังสามารถใช้ laplacian regularizer จะแผ่สอบเทียบและ hessian regularizer ที่จะทำให้มันเส้นตรง
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
ขณะนี้เครื่องสอบเทียบมีความราบรื่น และ CTR โดยประมาณโดยรวมตรงกับความจริงภาคพื้นดินมากขึ้น สิ่งนี้สะท้อนให้เห็นทั้งในเมตริกการทดสอบและในแผนภาพ
ความซ้ำซากจำเจบางส่วนสำหรับการสอบเทียบตามหมวดหมู่
จนถึงตอนนี้ เราใช้คุณสมบัติตัวเลขเพียงสองอย่างในแบบจำลองนี้ ที่นี่เราจะเพิ่มคุณสมบัติที่สามโดยใช้ชั้นการสอบเทียบตามหมวดหมู่ เราเริ่มต้นด้วยการตั้งค่าฟังก์ชันตัวช่วยสำหรับการพล็อตและการคำนวณเมตริก
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
ที่จะเกี่ยวข้องกับคุณลักษณะที่สาม dollar_rating เราควรจะจำได้ว่าคุณสมบัติเด็ดขาดต้องมีการรักษาที่แตกต่างกันเล็กน้อยใน TFL ทั้งคอลัมน์คุณลักษณะและเป็นคุณลักษณะการกำหนดค่า ที่นี่เราบังคับใช้ข้อจำกัดความซ้ำซากจำเจบางส่วนที่เอาต์พุตสำหรับร้านอาหาร "DD" ควรมากกว่าร้านอาหาร "D" เมื่ออินพุตอื่น ๆ ทั้งหมดได้รับการแก้ไข นี้จะกระทำโดยใช้ monotonicity การตั้งค่าในการตั้งค่าคุณลักษณะ
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
เครื่องสอบเทียบตามหมวดหมู่นี้แสดงการตั้งค่าเอาต์พุตของแบบจำลอง: DD > D > DDD > DDDD ซึ่งสอดคล้องกับการตั้งค่าของเรา สังเกตว่ายังมีคอลัมน์สำหรับค่าที่หายไป แม้ว่าจะไม่มีคุณลักษณะที่ขาดหายไปในข้อมูลการฝึกอบรมและการทดสอบของเรา แต่แบบจำลองนี้ให้ข้อมูลแก่เราว่าค่าที่ขาดหายไปควรเกิดขึ้นระหว่างการให้บริการโมเดลดาวน์สตรีม
ที่นี่เรายังพล็อตที่คาดการณ์ CTR ของรุ่นนี้ปรับอากาศใน dollar_rating ขอให้สังเกตว่าข้อ จำกัด ทั้งหมดที่เราต้องการได้รับการเติมเต็มในแต่ละส่วน
การสอบเทียบเอาต์พุต
สำหรับโมเดล TFL ทั้งหมดที่เราฝึกมาจนถึงตอนนี้ เลเยอร์แลตทิซ (ระบุเป็น "แลตทิซ" ในกราฟโมเดล) จะส่งเอาต์พุตการทำนายโมเดลโดยตรง บางครั้งเราไม่แน่ใจว่าควรปรับขนาดเอาต์พุตแลตทิซเพื่อปล่อยเอาต์พุตของโมเดลหรือไม่:
- คุณสมบัติที่มี \(log\) ข้อหาขณะที่ป้ายชื่อที่มีการนับจำนวน
- โครงตาข่ายได้รับการกำหนดค่าให้มีจุดยอดน้อยมาก แต่การกระจายฉลากค่อนข้างซับซ้อน
ในกรณีเหล่านี้ เราสามารถเพิ่มตัวสอบเทียบอื่นระหว่างเอาต์พุตแลตทิซและเอาต์พุตของโมเดล เพื่อเพิ่มความยืดหยุ่นของโมเดล ในที่นี้ มาเพิ่มเลเยอร์เครื่องสอบเทียบที่มีจุดสำคัญ 5 จุดให้กับแบบจำลองที่เราเพิ่งสร้างขึ้น นอกจากนี้เรายังเพิ่มตัวปรับมาตรฐานสำหรับตัวปรับเทียบเอาต์พุตเพื่อให้ฟังก์ชันทำงานได้อย่างราบรื่น
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
เมตริกและแผนภาพการทดสอบขั้นสุดท้ายแสดงให้เห็นว่าการใช้ข้อจำกัดทั่วไปช่วยให้โมเดลหลีกเลี่ยงพฤติกรรมที่ไม่คาดคิดและคาดการณ์ได้ดียิ่งขึ้นสำหรับพื้นที่อินพุตทั้งหมด