
TensorFlow Lattice 库可帮助开发者实现灵活、受控和可解释的点阵式模型。使用该库,您可以通过以常识或策略驱动的形状约束将领域知识注入到学习过程中。为此,需要使用能够满足诸如单调性、凸性和成对信任等约束的 Keras 层集合。该库还提供了易于设置的 Canned Estimator。
概念
本部分为 JMLR 在 2016 年发表的 Monotonic Calibrated Interpolated Look-Up Tables 一文的精简版本。
点阵
点阵是一种能够逼近数据中任意输入-输出关系的插值查找表。点阵会将规则的网格覆盖到您的输入空间上,并学习网格顶点处输出的值。对于测试点 \(x\),\(f(x)\) 基于 \(x\) 周围的点阵值通过线性插值法求得。
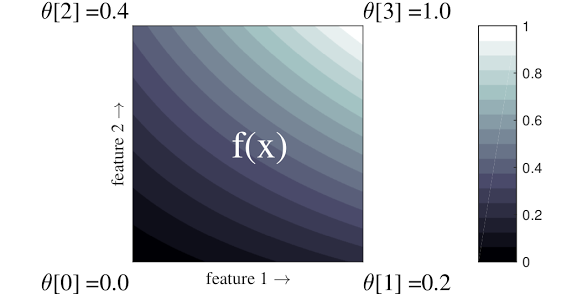
以上简短示例中的函数包含 2 个输入特征和 4 个参数:\(\theta=[0, 0.2, 0.4, 1]\),即输入空间各个角处的函数值;其余函数值基于这些参数通过插值法求得。
函数 \(f(x)\) 可以捕获特征之间的非线性交互。您可以将点阵参数设想为以规则的网格为地面,在上方安装的电线杆的高度;生成的函数就如同紧紧系在四条电线杆上的衣服。
规则的点阵在每个维度上具有 \(D\) 个特征和 2 个顶点,因此将有 \(2^D\) 个参数。为了拟合更加灵活的函数,您可以在每个维度包含更多顶点的特征空间上指定细粒度程度更高的点阵。点阵回归函数是连续的分段无穷可微函数。
校准
我们假定前例中的点阵代表使用以下特征学习的当地推荐咖啡店的用户满意度:
- 咖啡价格,在 0 至 20 美元区间内
- 用户距离,在 0 至 30 公里区间内
我们希望我们的模型能够学习当地推荐咖啡店的用户满意度。TensorFlow Lattice 模型可以使用分段线性函数(通过 tfl.layers.PWLCalibration)针对点阵所接受的区间(上例中的点阵区间为 0.0 至 1.0)校准和归一化输入特征。以下示例所展示的此类校准函数包含 10 个关键点:
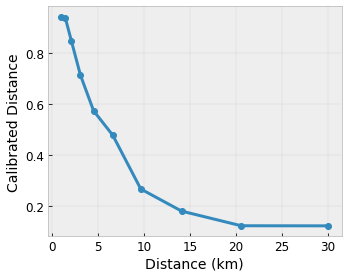
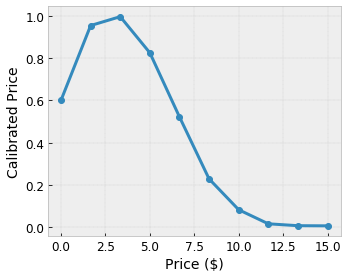
将特征的分位数作为输入关键点是一种有效方法。TensorFlow Lattice Canned Estimator 可自动将输入关键点设置为特征分位数。
对于分类特征,TensorFlow Lattice 支持基于类似的输出边界进行分类校准(使用 tfl.layers.CategoricalCalibration)以将数据馈入点阵。
集成
点阵层的参数数量随输入特征的数量呈指数式增长,因此无法很好地扩展到非常高的维度。为了克服这一限制,TensorFlow Lattice 提供了点阵集成功能,可组合(平均)多个小型点阵,该功能使模型可以随特征数量呈线性增长。
库提供了这些集成的两种变体:
随机小型点阵 (RTL):每个子模型使用随机的特征子集(有放回抽样)。
晶体:晶体算法首先训练一个预拟合模型,此模型会估算成对的特征交互。然后,它将对最终集成进行排列,使具有更多非线性交互的特征处于同一点阵中。
为何使用 TensorFlow Lattice?
您可以参阅这篇 TF 博文中的 TensorFlow Lattice 简介。
可解释性
由于每一层的参数都是该层的输出,因此很容易分析、理解和调试模型的各个部分。
准确而灵活的模型
使用细粒度点阵,您可以利用单个点阵层获得任意复杂度的函数。在实际工作中使用多层校准器和点阵通常非常理想,并且可以达到或优于相似大小的 DNN 模型的效果。
常识形状约束
现实中的训练数据可能无法充分代表运行时数据。在训练数据未能覆盖到的输入空间部分中,诸如 DNN 或随机森林等灵活的机器学习解决方案常会出现行为异常甚至失控的状况。如果有违政策或公平约束,那么这种行为将成为棘手的问题。
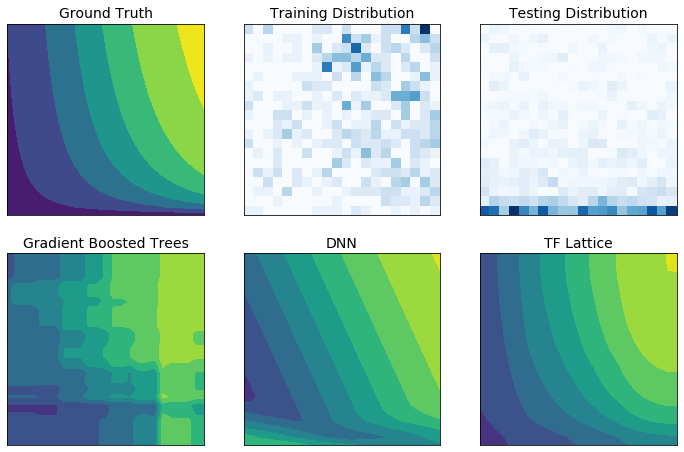
虽然常见形式的正则化可以提高外推的合理性,但标准正则化器仍不能保证整个输入空间内均能获得合理的模型行为,特别是针对高维度输入。如果改为采用行为可控性和可预测性更高的简单模型,可能会使模型准确率大幅降低。
TF Lattice 使您可以继续使用灵活的模型,同时提供多种选项,支持通过以语义上有意义的常识或策略驱动的形状约束将领域知识注入到学习过程中:
- 单调性:您可以指定输出相对于输入仅单调递增/递减。在我们的示例中,您可以指定增大消费者到咖啡店的距离仅应降低预测的用户偏好。
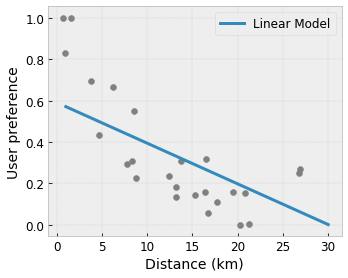
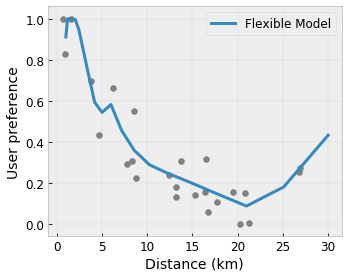

凸性/凹性:您可以指定函数形状为凸函数或凹函数。这种约束与单调性结合使用,可以强迫函数表示收益相对于给定特征递减。
单峰性:您可以指定函数应具有唯一的波峰或唯一的波谷。这种约束可用于表示针对某个特征具有最佳平衡点的函数。
成对信任:这种约束作用于一对特征,暗示一个输入特征在语义上能够反映出对另一个特征的信任。例如,评论数量越多,您就越信任餐厅的平均星级。当评论数量更多时,该模型相对于星级将更敏感(即相对于星级具有更大的斜率)。
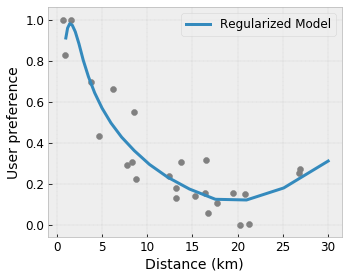
通过正则化器控制灵活性
除了形状约束,TensorFlow Lattice 还提供了许多正则化器,用于控制每层函数的灵活性和平滑性。
拉普拉斯正则化器:将点阵/校准顶点/关键点的输出朝其各自的近邻值进行正则化。这会使函数更加平坦 。
黑塞正则化器:针对 PWL 校准层的一阶导数应用罚分,使函数更线性。
褶皱正则化器:针对 PWL 校准层的二阶导数应用罚分,以避免曲率突然变化。该正则化器可使函数更加平滑。
扭转正则化器:以防止特征之间发生扭转为目标对点阵的输出进行正则化。换言之,模型将以提高特征贡献之间的独立性为目标进行正则化。
与其他 Keras 层搭配使用
您可以将 TF Lattice 层与其他 Keras 层组合使用,从而构造部分约束或正则化的模型。例如,可以在包含集成或其他 Keras 层的更深层网络的最后一层使用点阵或 PWL 校准层。
论文
- Deontological Ethics By Monotonicity Shape Constraints, Serena Wang, Maya Gupta, International Conference on Artificial Intelligence and Statistics (AISTATS), 2020
- Shape Constraints for Set Functions, Andrew Cotter, Maya Gupta, H. Jiang, Erez Louidor, Jim Muller, Taman Narayan, Serena Wang, Tao Zhu. International Conference on Machine Learning (ICML), 2019
- Diminishing Returns Shape Constraints for Interpretability and Regularization, Maya Gupta, Dara Bahri, Andrew Cotter, Kevin Canini, Advances in Neural Information Processing Systems (NeurIPS), 2018
- Deep Lattice Networks and Partial Monotonic Functions, Seungil You, Kevin Canini, David Ding, Jan Pfeifer, Maya R. Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2017
- Fast and Flexible Monotonic Functions with Ensembles of Lattices, Mahdi Milani Fard, Kevin Canini, Andrew Cotter, Jan Pfeifer, Maya Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2016
- Monotonic Calibrated Interpolated Look-Up Tables, Maya Gupta, Andrew Cotter, Jan Pfeifer, Konstantin Voevodski, Kevin Canini, Alexander Mangylov, Wojciech Moczydlowski, Alexander van Esbroeck, Journal of Machine Learning Research (JMLR), 2016
- Optimized Regression for Efficient Function Evaluation, Eric Garcia, Raman Arora, Maya R. Gupta, IEEE Transactions on Image Processing, 2012
- Lattice Regression, Eric Garcia, Maya Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2009
教程和 API 文档
对于常见的模型架构,您可以使用 Keras 预制模型或 Canned Estimator。您也可以使用 TF Lattice Keras 层创建自定义模型,或者搭配使用其他 Keras 层。有关详细信息,请参阅完整的 API 文档。