
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Descripción general
Este instructivo es una descripción general de las restricciones y los regularizadores proporcionados por la biblioteca TensorFlow Lattice (TFL). Aquí usamos estimadores enlatados de TFL en conjuntos de datos sintéticos, pero tenga en cuenta que todo en este tutorial también se puede hacer con modelos construidos a partir de capas de TFL Keras.
Antes de continuar, asegúrese de que su tiempo de ejecución tenga todos los paquetes requeridos instalados (como se importaron en las celdas de código a continuación).
Configuración
Instalación del paquete TF Lattice:
pip install -q tensorflow-lattice
Importación de paquetes requeridos:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Valores predeterminados utilizados en esta guía:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Conjunto de datos de formación para la clasificación de restaurantes
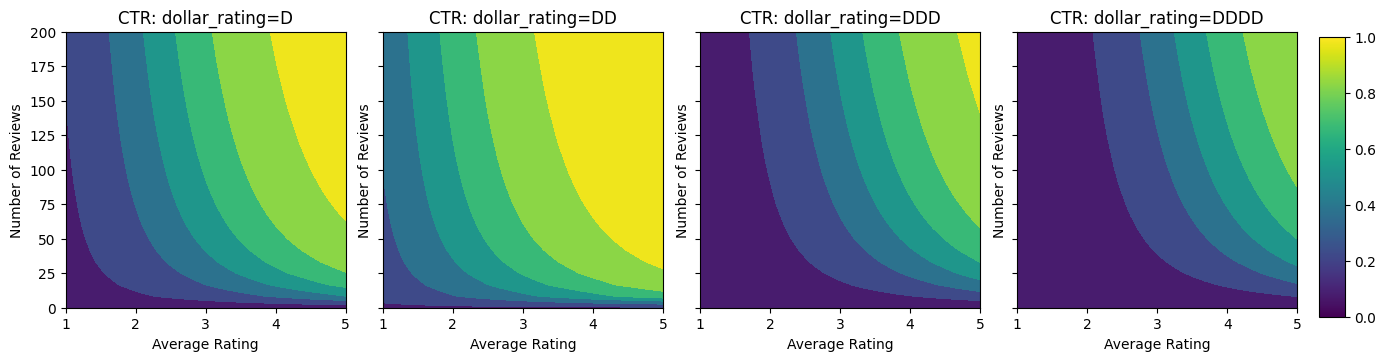
Imagine un escenario simplificado en el que queremos determinar si los usuarios harán clic en el resultado de la búsqueda de un restaurante o no. La tarea es predecir la tasa de clics (CTR) dadas las características de entrada:
- Evaluación media (
avg_rating): una característica numérico con valores en el intervalo [1,5]. - Número de comentarios (
num_reviews): una característica numérica con los valores de un tope de 200, que utilizamos como medida de trendiness. - Calificación dólar (
dollar_rating): una característica categórica con valores de cadena en el conjunto { "D", "DD", "DDD", "DDDD"}.
Aquí creamos un conjunto de datos sintéticos donde el verdadero CTR viene dado por la fórmula:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
donde \(b(\cdot)\) traduce cada dollar_rating a un valor de línea de base:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Esta fórmula refleja los patrones típicos de los usuarios. por ejemplo, dado que todo lo demás se solucionó, los usuarios prefieren restaurantes con calificaciones de estrellas más altas, y los restaurantes "\ $ \ $" recibirán más clics que "\ $", seguidos de "\ $ \ $ \ $" y "\ $ \ $ \ $ PS
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Echemos un vistazo a los gráficos de contorno de esta función CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Preparando datos
Ahora necesitamos crear nuestros conjuntos de datos sintéticos. Comenzamos generando un conjunto de datos simulado de restaurantes y sus características.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
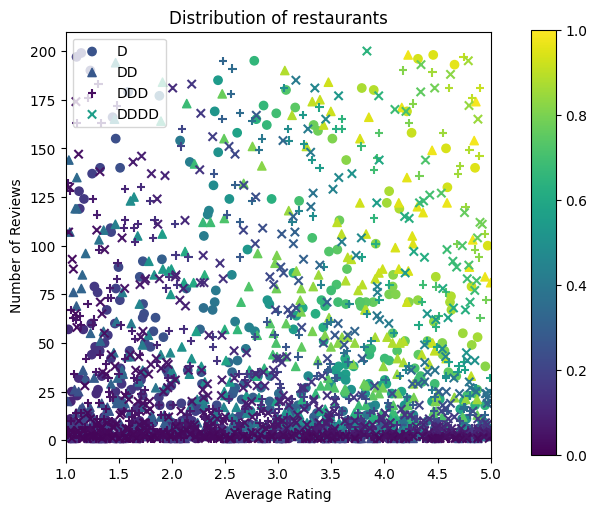
Produzcamos los conjuntos de datos de entrenamiento, validación y prueba. Cuando se ve un restaurante en los resultados de búsqueda, podemos registrar la participación del usuario (clic o no) como un punto de muestra.
En la práctica, los usuarios a menudo no revisan todos los resultados de búsqueda. Esto significa que es probable que los usuarios solo vean los restaurantes que ya se consideran "buenos" por el modelo de clasificación actual en uso. Como resultado, los "buenos" restaurantes quedan impresionados y sobrerrepresentados con mayor frecuencia en los conjuntos de datos de formación. Cuando se utilizan más funciones, el conjunto de datos de entrenamiento puede tener grandes lagunas en partes "malas" del espacio de funciones.
Cuando el modelo se utiliza para la clasificación, a menudo se evalúa en todos los resultados relevantes con una distribución más uniforme que no está bien representada por el conjunto de datos de entrenamiento. Un modelo flexible y complicado puede fallar en este caso debido a un ajuste excesivo de los puntos de datos sobrerrepresentados y, por lo tanto, a la falta de generalización. Nos ocupamos de este problema aplicando el conocimiento de dominio para agregar restricciones de forma que guían el modelo para hacer predicciones razonables cuando no puede recogerlos de la formación de datos.
En este ejemplo, el conjunto de datos de entrenamiento consiste principalmente en interacciones del usuario con restaurantes buenos y populares. El conjunto de datos de prueba tiene una distribución uniforme para simular la configuración de evaluación discutida anteriormente. Tenga en cuenta que dicho conjunto de datos de prueba no estará disponible en un entorno de problema real.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

Definición de input_fns usado para entrenamiento y evaluación:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Ajuste de árboles reforzados con degradado
Vamos a empezar con sólo dos características: avg_rating y num_reviews .
Creamos algunas funciones auxiliares para trazar y calcular métricas de validación y prueba.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Podemos ajustar los árboles de decisión potenciados por gradiente de TensorFlow en el conjunto de datos:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

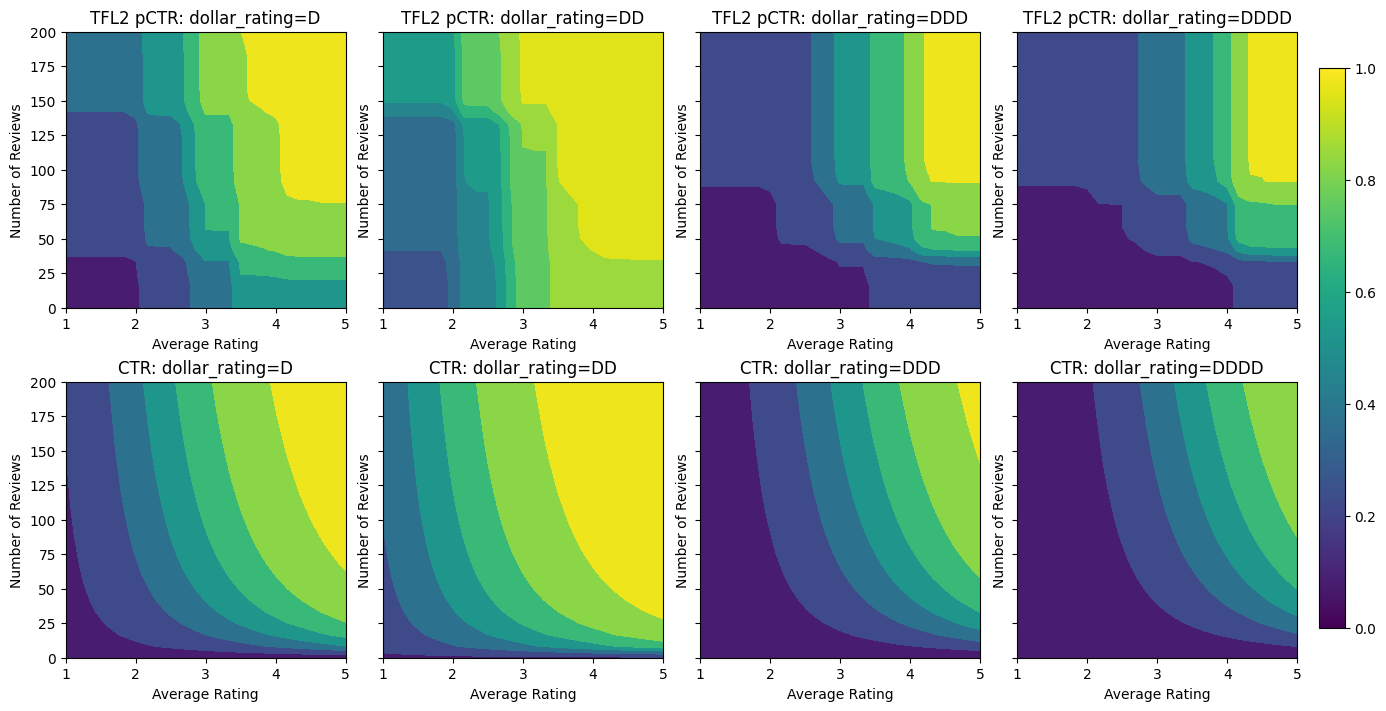
Aunque el modelo ha capturado la forma general del verdadero CTR y tiene métricas de validación decentes, tiene un comportamiento contrario a la intuición en varias partes del espacio de entrada: el CTR estimado disminuye a medida que aumenta la calificación promedio o el número de reseñas. Esto se debe a la falta de puntos de muestra en áreas que no están bien cubiertas por el conjunto de datos de entrenamiento. El modelo simplemente no tiene forma de deducir el comportamiento correcto únicamente a partir de los datos.
Para resolver este problema, aplicamos la restricción de forma de que el modelo debe generar valores que aumentan monótonamente con respecto tanto a la calificación promedio como al número de revisiones. Más adelante veremos cómo implementar esto en TFL.
Colocación de un DNN
Podemos repetir los mismos pasos con un clasificador DNN. Podemos observar un patrón similar: no tener suficientes puntos de muestra con un número pequeño de revisiones da como resultado una extrapolación sin sentido. Tenga en cuenta que aunque la métrica de validación es mejor que la solución de árbol, la métrica de prueba es mucho peor.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

Restricciones de forma
TensorFlow Lattice (TFL) se centra en imponer restricciones de forma para salvaguardar el comportamiento del modelo más allá de los datos de entrenamiento. Estas restricciones de forma se aplican a las capas de TFL Keras. Sus detalles se pueden encontrar en nuestro documento JMLR .
En este tutorial usamos estimadores enlatados TF para cubrir varias restricciones de forma, pero tenga en cuenta que todos estos pasos se pueden realizar con modelos creados a partir de capas de TFL Keras.
Al igual que con cualquier otro estimador TensorFlow, TFL en lata estimadores utilizan columnas de características para definir el formato de entrada y utilizar un input_fn formación acontecerá en los datos. El uso de estimadores enlatados de TFL también requiere:
- un modelo de config: definición de la arquitectura de modelo y de las limitaciones y regularizers forma por-feature.
- un input_fn análisis de características: a TF input_fn pasar datos para TFL inicialización.
Para obtener una descripción más detallada, consulte el tutorial de estimadores predefinidos o los documentos de la API.
Monotonicidad
Primero abordamos las preocupaciones de monotonicidad agregando restricciones de forma de monotonicidad a ambas características.
Instruir TFL para hacer cumplir las limitaciones de forma, especificamos las limitaciones en las configuraciones de características. Muestra el código siguiente cómo podemos requerir que la salida sea monótona creciente con respecto a ambos num_reviews y avg_rating mediante el establecimiento de monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

El uso de un CalibratedLatticeConfig crea un clasificador enlatada que primero se aplica un calibrador para cada entrada (una función lineal por tramos para las características numéricas) seguido por una capa de celosía para no linealmente fusible las características calibrados. Podemos utilizar tfl.visualization para visualizar el modelo. En particular, la siguiente gráfica muestra los dos calibradores entrenados incluidos en el clasificador enlatado.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

Con las restricciones agregadas, el CTR estimado siempre aumentará a medida que aumenta la calificación promedio o aumenta el número de reseñas. Esto se hace asegurándose de que los calibradores y la red sean monótonos.
Rendimientos decrecientes
Los rendimientos decrecientes medios que la ganancia marginal de aumentar la función de un determinado valor disminuirá a medida que aumente el valor. En nuestro caso, esperamos que la num_reviews función sigue este patrón, por lo que podemos configurar su calibrador en consecuencia. Observe que podemos descomponer los rendimientos decrecientes en dos condiciones suficientes:
- el calibrador aumenta monótonamente, y
- el calibrador es cóncavo.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
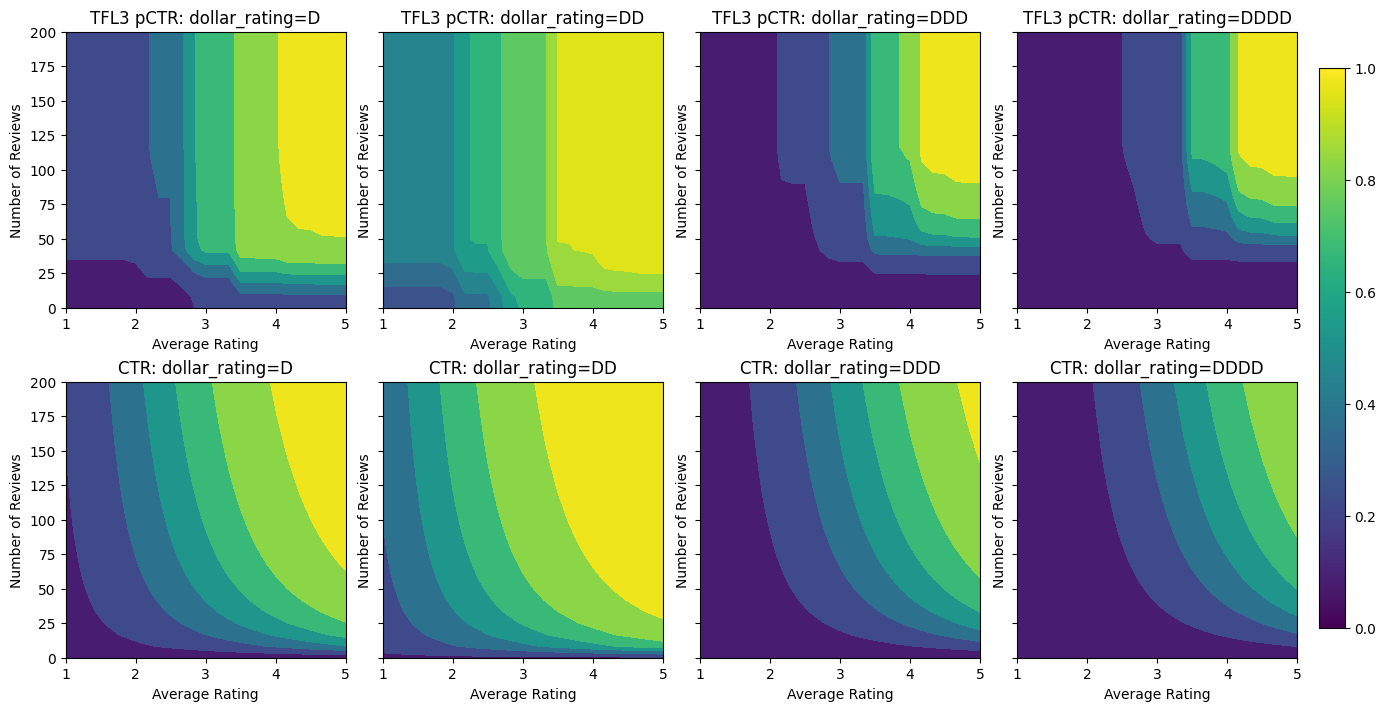

Observe cómo mejora la métrica de prueba al agregar la restricción de concavidad. La trama de predicción también se parece mejor a la verdad básica.
Restricción de forma 2D: confianza
Una calificación de 5 estrellas para un restaurante con solo una o dos reseñas es probablemente una calificación poco confiable (es posible que el restaurante no sea bueno), mientras que una calificación de 4 estrellas para un restaurante con cientos de reseñas es mucho más confiable (el restaurante es probablemente bueno en este caso). Podemos ver que la cantidad de reseñas de un restaurante afecta la confianza que depositamos en su calificación promedio.
Podemos ejercer restricciones de confianza de TFL para informar al modelo que el valor mayor (o menor) de una característica indica más dependencia o confianza de otra característica. Esto se hace mediante el establecimiento de reflects_trust_in de configuración en la configuración característica.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323

La siguiente gráfica presenta la función de celosía entrenada. Debido a la restricción de confianza, esperamos que valores más grandes de calibrados num_reviews obligarían pendiente superior con respecto al calibrado avg_rating , lo que resulta en un movimiento más significativo en la salida de celosía.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
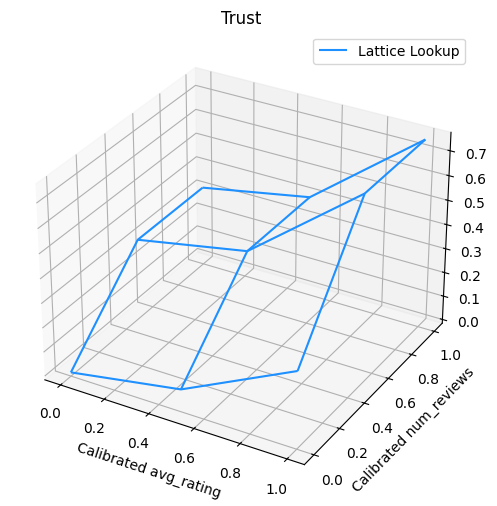
Calibradores de suavizado
Ahora vamos a echar un vistazo al calibrador de avg_rating . Aunque aumenta monótonamente, los cambios en sus pendientes son abruptos y difíciles de interpretar. Esto sugiere que podríamos desear considerar suavizar este calibrador utilizando una configuración regularizador en los regularizer_configs .
Aquí aplicamos una wrinkle regularizador para reducir los cambios en la curvatura. También puede utilizar el laplacian regularizador para aplanar el calibrador y la hessian regularizador para que sea más lineal.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


Los calibradores ahora son suaves y el CTR estimado general coincide mejor con la verdad del terreno. Esto se refleja tanto en la métrica de prueba como en los gráficos de contorno.
Monotonicidad parcial para calibración categórica
Hasta ahora hemos estado usando solo dos de las características numéricas del modelo. Aquí agregaremos una tercera característica usando una capa de calibración categórica. Nuevamente, comenzamos configurando funciones auxiliares para el trazado y el cálculo métrico.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Involucrar a la tercera característica, dollar_rating , debemos recordar que las características categóricas requieren un tratamiento ligeramente diferente en TFL, tanto como una columna de función y como característica de configuración. Aquí aplicamos la restricción de monotonicidad parcial de que las salidas para los restaurantes "DD" deben ser mayores que los restaurantes "D" cuando todas las demás entradas son fijas. Esto se hace usando la monotonicity establecer en la configuración característica.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


Este calibrador categórico muestra la preferencia de la salida del modelo: DD> D> DDD> DDDD, que es consistente con nuestra configuración. Observe que también hay una columna para los valores perdidos. Aunque no hay ninguna característica que falte en nuestros datos de entrenamiento y prueba, el modelo nos proporciona una imputación del valor faltante en caso de que ocurra durante la entrega del modelo en sentido descendente.
Aquí también representamos gráficamente el CTR predicho de este modelo condicionado a dollar_rating . Observe que todas las restricciones que requerimos se cumplen en cada uno de los cortes.
Calibración de salida
Para todos los modelos TFL que hemos entrenado hasta ahora, la capa de celosía (indicada como "Lattice" en el gráfico del modelo) genera directamente la predicción del modelo. A veces no estamos seguros de si la salida de celosía debe reescalarse para emitir salidas de modelo:
- las características son \(log\) recuentos mientras que las etiquetas son conteos.
- la celosía está configurada para tener muy pocos vértices, pero la distribución de etiquetas es relativamente complicada.
En esos casos, podemos agregar otro calibrador entre la salida de celosía y la salida del modelo para aumentar la flexibilidad del modelo. Aquí agreguemos una capa de calibrador con 5 puntos clave al modelo que acabamos de construir. También agregamos un regularizador para el calibrador de salida para mantener la función sin problemas.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


La métrica de prueba final y los gráficos muestran cómo el uso de restricciones de sentido común puede ayudar al modelo a evitar comportamientos inesperados y extrapolar mejor a todo el espacio de entrada.
,| | | Ver fuente en GitHub | |
Descripción general
Este instructivo es una descripción general de las restricciones y los regularizadores proporcionados por la biblioteca TensorFlow Lattice (TFL). Aquí usamos estimadores enlatados de TFL en conjuntos de datos sintéticos, pero tenga en cuenta que todo en este tutorial también se puede hacer con modelos construidos a partir de capas de TFL Keras.
Antes de continuar, asegúrese de que su tiempo de ejecución tenga todos los paquetes requeridos instalados (como se importaron en las celdas de código a continuación).
Configuración
Instalación del paquete TF Lattice:
pip install -q tensorflow-lattice
Importación de paquetes requeridos:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Valores predeterminados utilizados en esta guía:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Conjunto de datos de formación para la clasificación de restaurantes
Imagine un escenario simplificado en el que queremos determinar si los usuarios harán clic en el resultado de la búsqueda de un restaurante o no. La tarea es predecir la tasa de clics (CTR) dadas las características de entrada:
- Evaluación media (
avg_rating): una característica numérico con valores en el intervalo [1,5]. - Número de comentarios (
num_reviews): una característica numérica con los valores de un tope de 200, que utilizamos como medida de trendiness. - Calificación dólar (
dollar_rating): una característica categórica con valores de cadena en el conjunto { "D", "DD", "DDD", "DDDD"}.
Aquí creamos un conjunto de datos sintéticos donde el verdadero CTR viene dado por la fórmula:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
donde \(b(\cdot)\) traduce cada dollar_rating a un valor de línea de base:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Esta fórmula refleja los patrones típicos de los usuarios. por ejemplo, dado que todo lo demás se solucionó, los usuarios prefieren restaurantes con calificaciones de estrellas más altas, y los restaurantes "\ $ \ $" recibirán más clics que "\ $", seguidos de "\ $ \ $ \ $" y "\ $ \ $ \ $ PS
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Echemos un vistazo a los gráficos de contorno de esta función CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Preparando datos
Ahora necesitamos crear nuestros conjuntos de datos sintéticos. Comenzamos generando un conjunto de datos simulado de restaurantes y sus características.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
Produzcamos los conjuntos de datos de entrenamiento, validación y prueba. Cuando se ve un restaurante en los resultados de búsqueda, podemos registrar la participación del usuario (clic o no) como un punto de muestra.
En la práctica, los usuarios a menudo no revisan todos los resultados de búsqueda. Esto significa que es probable que los usuarios solo vean los restaurantes que ya se consideran "buenos" por el modelo de clasificación actual en uso. Como resultado, los "buenos" restaurantes quedan impresionados y sobrerrepresentados con mayor frecuencia en los conjuntos de datos de formación. Cuando se utilizan más funciones, el conjunto de datos de entrenamiento puede tener grandes lagunas en partes "malas" del espacio de funciones.
Cuando el modelo se utiliza para la clasificación, a menudo se evalúa en todos los resultados relevantes con una distribución más uniforme que no está bien representada por el conjunto de datos de entrenamiento. Un modelo flexible y complicado puede fallar en este caso debido a un ajuste excesivo de los puntos de datos sobrerrepresentados y, por lo tanto, a la falta de generalización. Nos ocupamos de este problema aplicando el conocimiento de dominio para agregar restricciones de forma que guían el modelo para hacer predicciones razonables cuando no puede recogerlos de la formación de datos.
En este ejemplo, el conjunto de datos de entrenamiento consiste principalmente en interacciones del usuario con restaurantes buenos y populares. El conjunto de datos de prueba tiene una distribución uniforme para simular la configuración de evaluación discutida anteriormente. Tenga en cuenta que dicho conjunto de datos de prueba no estará disponible en un entorno de problema real.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
Definición de input_fns usado para entrenamiento y evaluación:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Ajuste de árboles reforzados con degradado
Vamos a empezar con sólo dos características: avg_rating y num_reviews .
Creamos algunas funciones auxiliares para trazar y calcular métricas de validación y prueba.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Podemos ajustar los árboles de decisión potenciados por gradiente de TensorFlow en el conjunto de datos:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
Aunque el modelo ha capturado la forma general del verdadero CTR y tiene métricas de validación decentes, tiene un comportamiento contrario a la intuición en varias partes del espacio de entrada: el CTR estimado disminuye a medida que aumenta la calificación promedio o el número de reseñas. Esto se debe a la falta de puntos de muestra en áreas que no están bien cubiertas por el conjunto de datos de entrenamiento. El modelo simplemente no tiene forma de deducir el comportamiento correcto únicamente a partir de los datos.
Para resolver este problema, aplicamos la restricción de forma de que el modelo debe generar valores que aumentan monótonamente con respecto tanto a la calificación promedio como al número de revisiones. Más adelante veremos cómo implementar esto en TFL.
Colocación de un DNN
Podemos repetir los mismos pasos con un clasificador DNN. Podemos observar un patrón similar: no tener suficientes puntos de muestra con un número pequeño de revisiones da como resultado una extrapolación sin sentido. Tenga en cuenta que aunque la métrica de validación es mejor que la solución de árbol, la métrica de prueba es mucho peor.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
Restricciones de forma
TensorFlow Lattice (TFL) se centra en imponer restricciones de forma para salvaguardar el comportamiento del modelo más allá de los datos de entrenamiento. Estas restricciones de forma se aplican a las capas de TFL Keras. Sus detalles se pueden encontrar en nuestro documento JMLR .
En este tutorial usamos estimadores enlatados TF para cubrir varias restricciones de forma, pero tenga en cuenta que todos estos pasos se pueden realizar con modelos creados a partir de capas de TFL Keras.
Al igual que con cualquier otro estimador TensorFlow, TFL en lata estimadores utilizan columnas de características para definir el formato de entrada y utilizar un input_fn formación acontecerá en los datos. El uso de estimadores enlatados de TFL también requiere:
- un modelo de config: definición de la arquitectura de modelo y de las limitaciones y regularizers forma por-feature.
- un input_fn análisis de características: a TF input_fn pasar datos para TFL inicialización.
Para obtener una descripción más detallada, consulte el tutorial de estimadores predefinidos o los documentos de la API.
Monotonicidad
Primero abordamos las preocupaciones de monotonicidad agregando restricciones de forma de monotonicidad a ambas características.
Instruir TFL para hacer cumplir las limitaciones de forma, especificamos las limitaciones en las configuraciones de características. Muestra el código siguiente cómo podemos requerir que la salida sea monótona creciente con respecto a ambos num_reviews y avg_rating mediante el establecimiento de monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
El uso de un CalibratedLatticeConfig crea un clasificador enlatada que primero se aplica un calibrador para cada entrada (una función lineal por tramos para las características numéricas) seguido por una capa de celosía para no linealmente fusible las características calibrados. Podemos utilizar tfl.visualization para visualizar el modelo. En particular, la siguiente gráfica muestra los dos calibradores entrenados incluidos en el clasificador enlatado.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
Con las restricciones agregadas, el CTR estimado siempre aumentará a medida que aumenta la calificación promedio o aumenta el número de reseñas. Esto se hace asegurándose de que los calibradores y la red sean monótonos.
Rendimientos decrecientes
Los rendimientos decrecientes medios que la ganancia marginal de aumentar la función de un determinado valor disminuirá a medida que aumente el valor. En nuestro caso, esperamos que la num_reviews función sigue este patrón, por lo que podemos configurar su calibrador en consecuencia. Observe que podemos descomponer los rendimientos decrecientes en dos condiciones suficientes:
- el calibrador aumenta monótonamente, y
- el calibrador es cóncavo.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
Observe cómo mejora la métrica de prueba al agregar la restricción de concavidad. La trama de predicción también se parece mejor a la verdad básica.
Restricción de forma 2D: confianza
Una calificación de 5 estrellas para un restaurante con solo una o dos reseñas es probablemente una calificación poco confiable (es posible que el restaurante no sea bueno), mientras que una calificación de 4 estrellas para un restaurante con cientos de reseñas es mucho más confiable (el restaurante es probablemente bueno en este caso). Podemos ver que la cantidad de reseñas de un restaurante afecta la confianza que depositamos en su calificación promedio.
Podemos ejercer restricciones de confianza de TFL para informar al modelo que el valor mayor (o menor) de una característica indica más dependencia o confianza de otra característica. Esto se hace mediante el establecimiento de reflects_trust_in de configuración en la configuración característica.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
La siguiente gráfica presenta la función de celosía entrenada. Debido a la restricción de confianza, esperamos que valores más grandes de calibrados num_reviews obligarían pendiente superior con respecto al calibrado avg_rating , lo que resulta en un movimiento más significativo en la salida de celosía.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
Calibradores de suavizado
Ahora vamos a echar un vistazo al calibrador de avg_rating . Aunque aumenta monótonamente, los cambios en sus pendientes son abruptos y difíciles de interpretar. Esto sugiere que podríamos desear considerar suavizar este calibrador utilizando una configuración regularizador en los regularizer_configs .
Aquí aplicamos una wrinkle regularizador para reducir los cambios en la curvatura. También puede utilizar el laplacian regularizador para aplanar el calibrador y la hessian regularizador para que sea más lineal.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
Los calibradores ahora son suaves y el CTR estimado general coincide mejor con la verdad del terreno. Esto se refleja tanto en la métrica de prueba como en los gráficos de contorno.
Monotonicidad parcial para calibración categórica
Hasta ahora hemos estado usando solo dos de las características numéricas del modelo. Aquí agregaremos una tercera característica usando una capa de calibración categórica. Nuevamente, comenzamos configurando funciones auxiliares para el trazado y el cálculo métrico.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Involucrar a la tercera característica, dollar_rating , debemos recordar que las características categóricas requieren un tratamiento ligeramente diferente en TFL, tanto como una columna de función y como característica de configuración. Aquí aplicamos la restricción de monotonicidad parcial de que las salidas para los restaurantes "DD" deben ser mayores que los restaurantes "D" cuando todas las demás entradas son fijas. Esto se hace usando la monotonicity establecer en la configuración característica.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
Este calibrador categórico muestra la preferencia de la salida del modelo: DD> D> DDD> DDDD, que es consistente con nuestra configuración. Observe que también hay una columna para los valores perdidos. Aunque no hay ninguna característica que falte en nuestros datos de entrenamiento y prueba, el modelo nos proporciona una imputación del valor faltante en caso de que ocurra durante la entrega del modelo en sentido descendente.
Aquí también representamos gráficamente el CTR predicho de este modelo condicionado a dollar_rating . Observe que todas las restricciones que requerimos se cumplen en cada uno de los cortes.
Calibración de salida
Para todos los modelos TFL que hemos entrenado hasta ahora, la capa de celosía (indicada como "Lattice" en el gráfico del modelo) genera directamente la predicción del modelo. A veces no estamos seguros de si la salida de celosía debe reescalarse para emitir salidas de modelo:
- las características son \(log\) recuentos mientras que las etiquetas son conteos.
- la celosía está configurada para tener muy pocos vértices, pero la distribución de etiquetas es relativamente complicada.
En esos casos, podemos agregar otro calibrador entre la salida de celosía y la salida del modelo para aumentar la flexibilidad del modelo. Aquí agreguemos una capa de calibrador con 5 puntos clave al modelo que acabamos de construir. También agregamos un regularizador para el calibrador de salida para mantener la función sin problemas.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
La métrica de prueba final y los gráficos muestran cómo el uso de restricciones de sentido común puede ayudar al modelo a evitar comportamientos inesperados y extrapolar mejor a todo el espacio de entrada.