
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
Это руководство представляет собой обзор ограничений и регуляризаторов, предоставляемых библиотекой TensorFlow Lattice (TFL). Здесь мы используем стандартные оценщики TFL для синтетических наборов данных, но обратите внимание, что все в этом руководстве также можно сделать с моделями, построенными из слоев TFL Keras.
Прежде чем продолжить, убедитесь, что в вашей среде выполнения установлены все необходимые пакеты (импортированные в ячейки кода ниже).
Настраивать
Установка пакета TF Lattice:
pip install -q tensorflow-lattice
Импорт необходимых пакетов:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Значения по умолчанию, используемые в этом руководстве:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Набор обучающих данных для ранжирования ресторанов
Представьте себе упрощенный сценарий, в котором мы хотим определить, будут ли пользователи нажимать на результат поиска ресторана. Задача состоит в том, чтобы предсказать рейтинг кликов (CTR) с учетом входных характеристик:
- Средняя оценка (
avg_rating): числовая функция со значениями в диапазоне [1,5]. - Количество отзывов (
num_reviews): числовая функция со значениями блокированных в 200, которые мы используем в качестве меры ультрасовременности. - Рейтинг доллара (
dollar_rating): категорическая функция со значениями строк в наборе { "D", "DD", "DDD", "DDDD"}.
Здесь мы создаем синтетический набор данных, где истинный CTR задается по формуле:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
где \(b(\cdot)\) переводит каждый dollar_rating к базовому значению:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Эта формула отражает типичные пользовательские шаблоны. например, если все остальное исправлено, пользователи предпочитают рестораны с более высоким рейтингом, и рестораны "\ $ \ $" получат больше кликов, чем "\ $", за которым следуют "\ $ \ $ \ $" и "\ $ \ $ \ $" \ $ ".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Давайте посмотрим на контурные графики этой функции CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
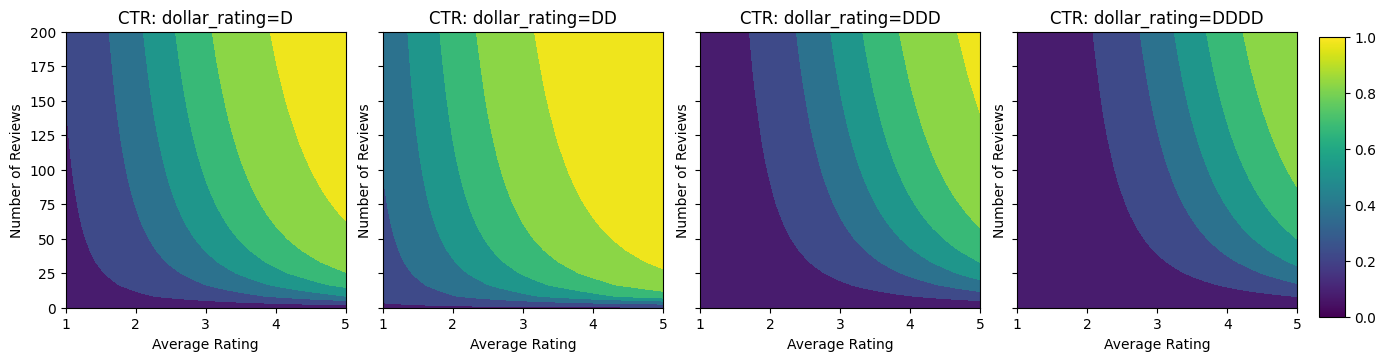
Подготовка данных
Теперь нам нужно создать наши синтетические наборы данных. Начнем с создания смоделированного набора данных о ресторанах и их характеристиках.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
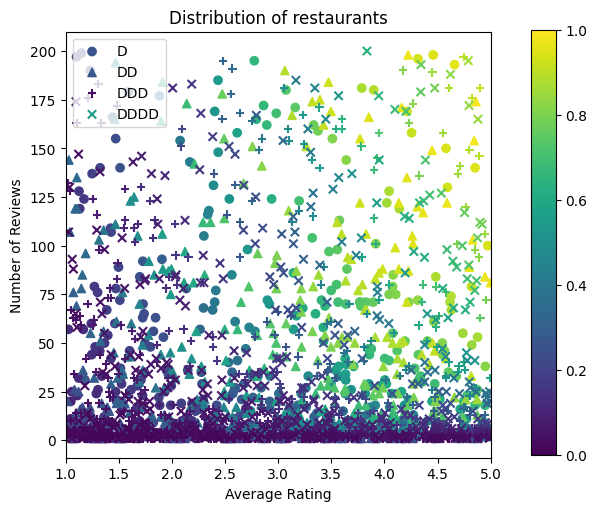
Создадим наборы данных для обучения, проверки и тестирования. Когда ресторан просматривается в результатах поиска, мы можем записать участие пользователя (щелчок или отсутствие щелчка) в качестве точки выборки.
На практике пользователи часто просматривают не все результаты поиска. Это означает, что пользователи, скорее всего, будут видеть только те рестораны, которые уже считаются «хорошими» в соответствии с текущей используемой моделью рейтинга. В результате «хорошие» рестораны чаще поражаются и чрезмерно представлены в наборах данных для обучения. При использовании большего количества функций обучающий набор данных может иметь большие пробелы в «плохих» частях пространства функций.
Когда модель используется для ранжирования, она часто оценивается по всем релевантным результатам с более равномерным распределением, которое недостаточно хорошо представлено в обучающем наборе данных. В этом случае гибкая и сложная модель может потерпеть неудачу из-за переобучения избыточно представленных точек данных и, следовательно, отсутствия возможности обобщения. Мы справиться с этой проблемой, применяя знания предметной области , чтобы добавить ограничения формы , которые определяют модель , чтобы сделать обоснованные прогнозы , когда он не может забрать их из обучающего набора данных.
В этом примере набор обучающих данных в основном состоит из взаимодействия пользователей с хорошими и популярными ресторанами. Набор данных тестирования имеет равномерное распределение для имитации настройки оценки, описанной выше. Обратите внимание, что такой набор данных тестирования не будет доступен в условиях реальной проблемы.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

Определение input_fns, используемого для обучения и оценки:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Установка деревьев с градиентным усилением
Давайте начнем с только две особенности: avg_rating и num_reviews .
Мы создаем несколько вспомогательных функций для построения графиков и расчета показателей валидации и тестирования.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Мы можем поместить деревья решений с градиентным усилением TensorFlow в набор данных:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

Несмотря на то, что модель отражает общую форму истинного CTR и имеет приличные показатели валидации, она имеет противоречивое поведение в нескольких частях входного пространства: расчетный CTR уменьшается по мере увеличения среднего рейтинга или количества отзывов. Это связано с отсутствием точек выборки в областях, не охваченных набором обучающих данных. Модель просто не имеет возможности вывести правильное поведение исключительно на основе данных.
Чтобы решить эту проблему, мы применяем ограничение формы, согласно которому модель должна выводить значения, монотонно возрастающие как по средней оценке, так и по количеству отзывов. Позже мы увидим, как реализовать это в TFL.
Установка DNN
Мы можем повторить те же шаги с классификатором DNN. Мы можем наблюдать аналогичную картину: нехватка точек выборки при небольшом количестве обзоров приводит к бессмысленной экстраполяции. Обратите внимание, что даже несмотря на то, что метрика проверки лучше, чем решение в виде дерева, метрика тестирования намного хуже.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

Ограничения формы
TensorFlow Lattice (TFL) ориентирован на соблюдение ограничений формы для защиты поведения модели за пределами обучающих данных. Эти ограничения формы применяются к слоям TFL Keras. Их детали можно найти в нашем JMLR бумаге .
В этом руководстве мы используем стандартные оценщики TF для покрытия различных ограничений формы, но обратите внимание, что все эти шаги могут быть выполнены с моделями, созданными из слоев TFL Keras.
Как и с любым другим оценщиком TensorFlow, TFL консервированных оценщики используют полнометражные столбцы для определения формата входного сигнала и использовать учебный input_fn пройти в данных. Использование стандартных оценщиков TFL также требует:
- модель конфигурации: определение модели архитектуры и за функции ограничения формы и регуляризаторы.
- анализ особенность input_fn: а TF input_fn передачи данных для инициализации TFL.
Для более подробного описания см. Руководство по стандартным оценкам или документацию по API.
Монотонность
Сначала мы решаем проблемы монотонности, добавляя ограничения монотонности формы к обеим функциям.
Поручить TFL для обеспечения соблюдения ограничений формы, мы указываем ограничения в функции конфиги. Следующий код показывает , как мы можем требовать вывода монотонно возрастает по обоим num_reviews и avg_rating , установив monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

Использование CalibratedLatticeConfig создает консервированный классификатор , который сначала применяет калибратор для каждого входа (кусочно-линейной функции для числовых функций) , а затем с помощью решетки слоя к нелинейно предохранителям калиброванных особенностей. Мы можем использовать tfl.visualization визуализировать модель. В частности, на следующем графике показаны два обученных калибратора, включенных в стандартный классификатор.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

С добавленными ограничениями расчетный CTR всегда будет увеличиваться по мере увеличения среднего рейтинга или количества отзывов. Для этого нужно убедиться, что калибраторы и решетка монотонны.
Уменьшение прибыли
Убывающая отдача означает , что предельная выгода увеличения определенного значения признака будет уменьшаться по мере увеличения значения. В нашем случае мы ожидаем , что num_reviews особенность следует этой модели, поэтому мы можем настроить его калибратор соответственно. Обратите внимание, что мы можем разложить убывающую отдачу на два достаточных условия:
- калибратор монотонно увеличивается, и
- калибратор вогнутый.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
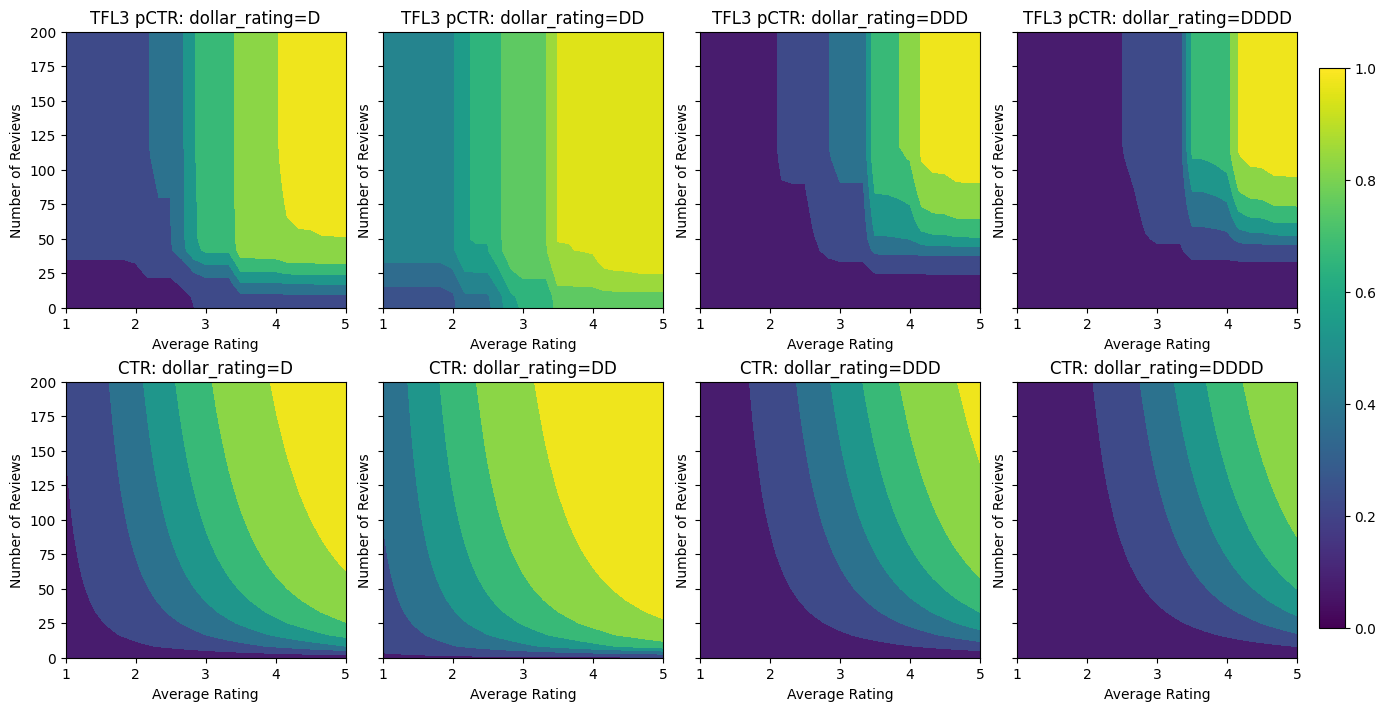

Обратите внимание, как улучшается метрика тестирования, добавляя ограничение вогнутости. Сюжет предсказания также больше напоминает наземную истину.
Ограничение 2D-формы: доверие
5-звездочный рейтинг ресторана с одним или двумя отзывами, скорее всего, ненадежный (ресторан на самом деле может быть не очень хорошим), тогда как 4-звездочный рейтинг для ресторана с сотнями отзывов гораздо более надежен (ресторан имеет скорее всего, в этом случае хорошо). Мы видим, что количество отзывов о ресторане влияет на то, насколько мы доверяем его средней оценке.
Мы можем применить ограничения доверия TFL, чтобы сообщить модели, что большее (или меньшее) значение одной функции указывает на большее доверие к другой функции. Это делается путем установки reflects_trust_in конфигурации в полнометражной конфигурации.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323

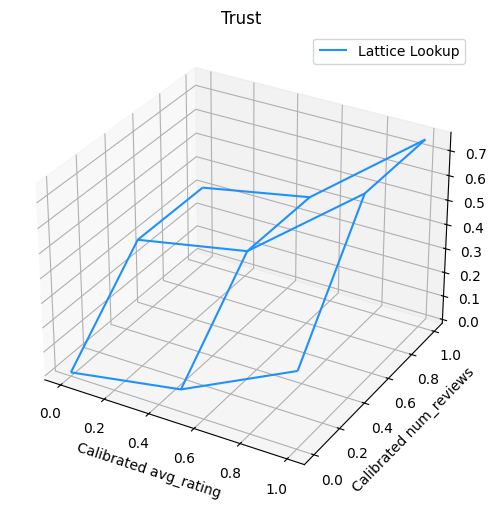
На следующем графике представлена обученная функция решетки. Из - за доверие ограничения, мы ожидаем , что большие значения калиброванных num_reviews вынудят более высокий наклон по отношению к калиброванной avg_rating , в результате чего более существенного движения в решетке выхода.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
Сглаживающие калибраторы
Давайте теперь посмотрим на калибратор avg_rating . Хотя он монотонно увеличивается, изменения его наклона резкие и трудно интерпретируемые. Это предполагает , что мы могли бы рассмотреть возможность сглаживания этого калибратора с помощью установки регуляризатора в regularizer_configs .
Здесь мы применяем wrinkle регуляризатором уменьшить изменения кривизны. Вы можете также использовать laplacian регуляризатором выравниваться калибратор и hessian регуляризатором , чтобы сделать его более линейным.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


Калибраторы теперь работают плавно, а общий оценочный CTR лучше соответствует действительности. Это отражается как в метрике тестирования, так и в контурных графиках.
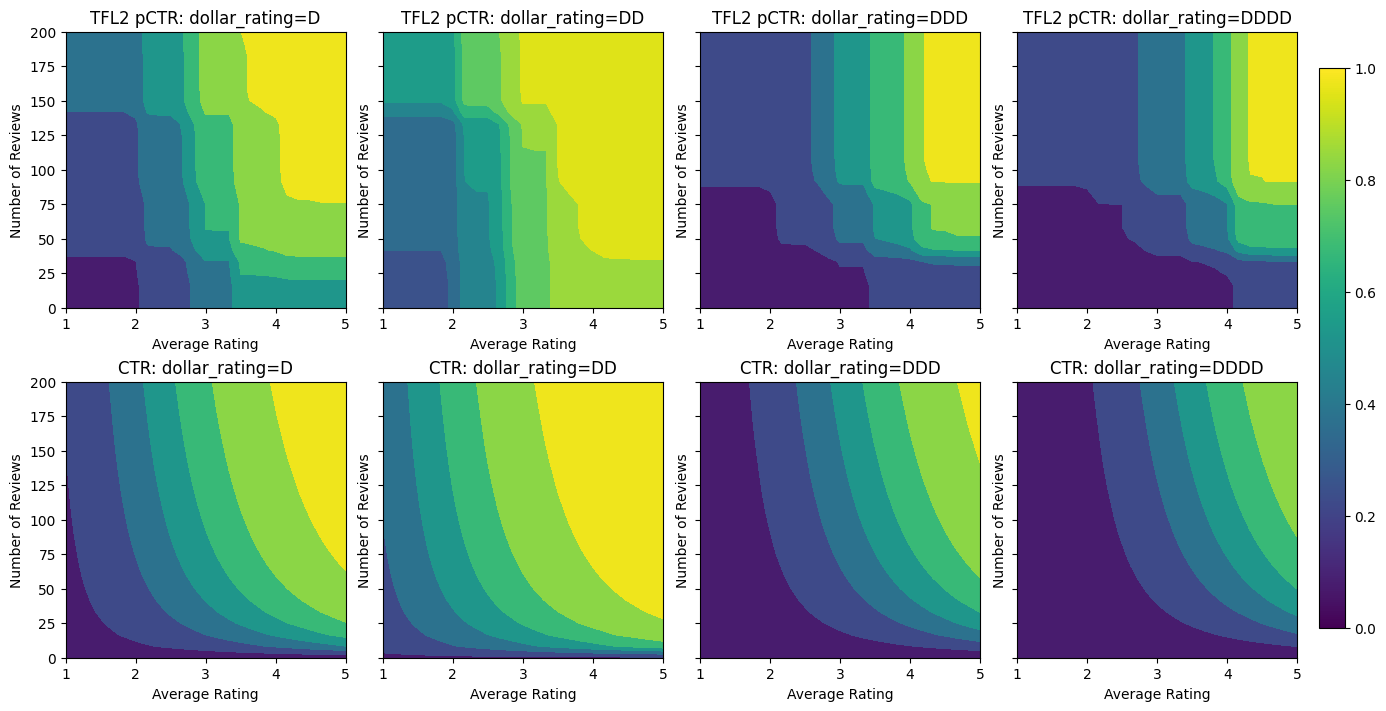
Частичная монотонность для категориальной калибровки
До сих пор мы использовали только две числовые функции в модели. Здесь мы добавим третью функцию, используя категориальный калибровочный слой. Снова мы начинаем с настройки вспомогательных функций для построения графиков и расчета показателей.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Для того, чтобы привлечь третью особенность, dollar_rating , мы должны помнить , что категориальные признаки требуют немного другого лечения в TFL, так как колонки функции и как особенность конфигурация. Здесь мы применяем ограничение частичной монотонности, согласно которому выходные данные для ресторанов «DD» должны быть больше, чем для ресторанов «D», когда все остальные входы фиксированы. Это делается с помощью monotonicity настройки в полнометражной конфигурации.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


Этот категориальный калибратор показывает предпочтение вывода модели: DD> D> DDD> DDDD, что согласуется с нашей настройкой. Обратите внимание, что есть также столбец с пропущенными значениями. Хотя в наших данных обучения и тестирования нет отсутствующих функций, модель предоставляет нам вменение недостающего значения, если это произойдет во время последующего обслуживания модели.
Здесь мы также построить прогнозируемое CTR этой модели условной на dollar_rating . Обратите внимание, что все необходимые ограничения выполняются в каждом из срезов.
Калибровка выхода
Для всех моделей TFL, которые мы обучили до сих пор, слой решетки (обозначенный как «Решетка» на графике модели) напрямую выводит прогноз модели. Иногда мы не уверены, нужно ли масштабировать выход решетки для получения выходных данных модели:
- в особенности \(log\) рассчитывает в то время как метка имеет значение.
- решетка сконфигурирована так, чтобы иметь очень мало вершин, но распределение меток относительно сложно.
В этих случаях мы можем добавить еще один калибратор между выходом решетки и выходом модели, чтобы повысить гибкость модели. Здесь давайте добавим слой калибратора с 5 ключевыми точками к модели, которую мы только что построили. Мы также добавляем регуляризатор для калибратора вывода, чтобы функция оставалась гладкой.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


Окончательная метрика тестирования и графики показывают, как использование ограничений здравого смысла может помочь модели избежать неожиданного поведения и лучше экстраполировать на все пространство ввода.