
O uso de processadores especializados, como GPUs, NPUs ou DSPs para aceleração de hardware pode melhorar drasticamente o desempenho da inferência (inferência até 10x mais rápida em alguns casos) e a experiência do usuário do seu aplicativo Android habilitado para ML. No entanto, dada a variedade de hardware e drivers que seus usuários podem ter, escolher a configuração ideal de aceleração de hardware para o dispositivo de cada usuário pode ser um desafio. Além disso, habilitar a configuração errada em um dispositivo pode criar uma experiência ruim para o usuário devido à alta latência ou, em alguns casos raros, erros de tempo de execução ou problemas de precisão causados por incompatibilidades de hardware.
O Acceleration Service para Android é uma API que ajuda você a escolher a configuração ideal de aceleração de hardware para um determinado dispositivo de usuário e seu modelo .tflite , ao mesmo tempo que minimiza o risco de erros de tempo de execução ou problemas de precisão.
O Acceleration Service avalia diferentes configurações de aceleração nos dispositivos do usuário executando benchmarks de inferência interna com seu modelo do TensorFlow Lite. Essas execuções de teste normalmente são concluídas em alguns segundos, dependendo do seu modelo. Você pode executar os benchmarks uma vez em cada dispositivo do usuário antes do tempo de inferência, armazenar em cache o resultado e usá-lo durante a inferência. Esses benchmarks são executados fora do processo; o que minimiza o risco de falhas no seu aplicativo.
Forneça seu modelo, amostras de dados e resultados esperados (entradas e saídas "de ouro") e o Acceleration Service executará um benchmark de inferência TFLite interno para fornecer recomendações de hardware.
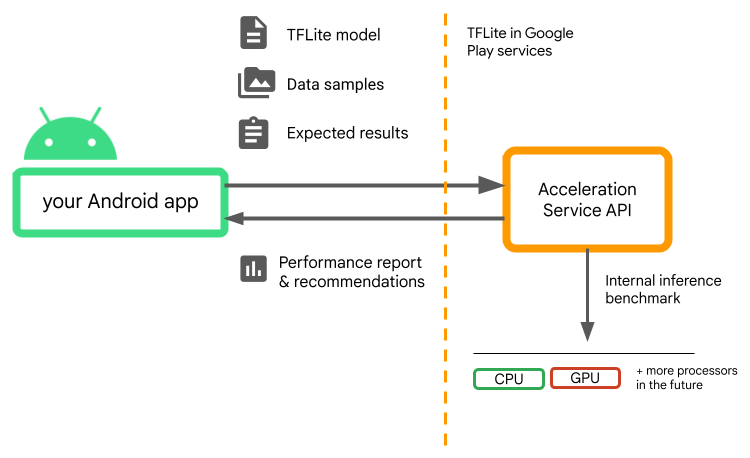
O Acceleration Service faz parte da pilha de ML personalizada do Android e funciona com o TensorFlow Lite no Google Play Services .
Adicione as dependências ao seu projeto
Adicione as seguintes dependências ao arquivo build.gradle do seu aplicativo:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.0.0-beta01"
A API Acceleration Service funciona com o TensorFlow Lite no Google Play Services . Se você ainda não estiver usando o tempo de execução do TensorFlow Lite fornecido pelo Play Services, será necessário atualizar suas dependências .
Como usar a API do serviço de aceleração
Para usar o Acceleration Service, comece criando a configuração de aceleração que deseja avaliar para seu modelo (por exemplo, GPU com OpenGL). Em seguida, crie uma configuração de validação com seu modelo, alguns dados de amostra e a saída esperada do modelo. Por fim, chame validateConfig() passando a configuração de aceleração e a configuração de validação.

Criar configurações de aceleração
As configurações de aceleração são representações das configurações de hardware que são traduzidas em delegados durante o tempo de execução. O Serviço de Aceleração usará essas configurações internamente para realizar inferências de teste.
No momento, o serviço de aceleração permite avaliar configurações de GPU (convertidas em delegado de GPU durante o tempo de execução) com GpuAccelerationConfig e inferência de CPU (com CpuAccelerationConfig ). Estamos trabalhando para oferecer suporte a mais delegados para acessar outros hardwares no futuro.
Configuração de aceleração de GPU
Crie uma configuração de aceleração de GPU conforme a seguir:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
Você deve especificar se seu modelo está ou não usando quantização com setEnableQuantizedInference() .
Configuração de aceleração de CPU
Crie a aceleração da CPU da seguinte forma:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
Use o método setNumThreads() para definir o número de threads que você deseja usar para avaliar a inferência da CPU.
Criar configurações de validação
As configurações de validação permitem definir como você deseja que o Acceleration Service avalie as inferências. Você os usará para passar:
- amostras de entrada,
- resultados esperados,
- lógica de validação de precisão.
Certifique-se de fornecer amostras de entrada para as quais você espera um bom desempenho do seu modelo (também conhecidas como amostras “de ouro”).
Crie um ValidationConfig com CustomValidationConfig.Builder da seguinte maneira:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
Especifique o número de amostras douradas com setBatchSize() . Passe as entradas de suas amostras douradas usando setGoldenInputs() . Forneça a saída esperada para a entrada passada com setGoldenOutputs() .
Você pode definir um tempo máximo de inferência com setInferenceTimeoutMillis() (5000 ms por padrão). Se a inferência demorar mais do que o tempo definido, a configuração será rejeitada.
Opcionalmente, você também pode criar um AccuracyValidator personalizado da seguinte maneira:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
Certifique-se de definir uma lógica de validação que funcione para o seu caso de uso.
Observe que se os dados de validação já estiverem incorporados em seu modelo, você poderá usar EmbeddedValidationConfig .
Gerar resultados de validação
As saídas douradas são opcionais e, desde que você forneça entradas douradas, o Serviço de Aceleração poderá gerar internamente as saídas douradas. Você também pode definir a configuração de aceleração usada para gerar essas saídas douradas chamando setGoldenConfig() :
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
Validar configuração de aceleração
Depois de criar uma configuração de aceleração e uma configuração de validação, você poderá avaliá-las para o seu modelo.
Certifique-se de que o tempo de execução do TensorFlow Lite com Play Services esteja inicializado corretamente e que o delegado da GPU esteja disponível para o dispositivo executando:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
Instancie o AccelerationService chamando AccelerationService.create() .
Você pode então validar a configuração de aceleração do seu modelo chamando validateConfig() :
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
Você também pode validar múltiplas configurações chamando validateConfigs() e passando um objeto Iterable<AccelerationConfig> como parâmetro.
validateConfig() retornará um Task< ValidatedAccelerationConfigResult > da API de tarefas do Google Play Services que permite tarefas assíncronas.
Para obter o resultado da chamada de validação, adicione um retorno de chamada addOnSuccessListener() .
Use configuração validada em seu intérprete
Depois de verificar se ValidatedAccelerationConfigResult retornado no retorno de chamada é válido, você pode definir a configuração validada como uma configuração de aceleração para seu intérprete chamando interpreterOptions.setAccelerationConfig() .
Cache de configuração
É improvável que a configuração de aceleração ideal para o seu modelo mude no dispositivo. Assim, depois de receber uma configuração de aceleração satisfatória, você deve armazená-la no dispositivo e deixar seu aplicativo recuperá-la e usá-la para criar suas InterpreterOptions durante as sessões seguintes, em vez de executar outra validação. Os métodos serialize() e deserialize() em ValidatedAccelerationConfigResult facilitam o processo de armazenamento e recuperação.
Exemplo de aplicação
Para revisar uma integração in-situ do Acceleration Service, dê uma olhada no aplicativo de exemplo .
Limitações
O Serviço de Aceleração tem as seguintes limitações atuais:
- Apenas configurações de aceleração de CPU e GPU são suportadas no momento,
- Ele suporta apenas o TensorFlow Lite nos serviços do Google Play e você não pode usá-lo se estiver usando a versão agrupada do TensorFlow Lite,
- Ele não oferece suporte à biblioteca de tarefas do TensorFlow Lite, pois você não pode inicializar diretamente
BaseOptionscom o objetoValidatedAccelerationConfigResult. - O Acceleration Service SDK oferece suporte apenas à API de nível 22 e superior.
Ressalvas
Revise as advertências a seguir com atenção, especialmente se você planeja usar este SDK em produção:
Antes de sair do Beta e lançar a versão estável da API Acceleration Service, publicaremos um novo SDK que pode ter algumas diferenças do Beta atual. Para continuar usando o serviço de aceleração, você precisará migrar para esse novo SDK e enviar uma atualização para seu aplicativo em tempo hábil. Não fazer isso pode causar falhas, pois o SDK Beta pode não ser mais compatível com o Google Play Services após algum tempo.
Não há garantia de que um recurso específico da API do Acceleration Service ou da API como um todo se tornará disponível ao público em geral. Ele pode permanecer na versão Beta indefinidamente, ser encerrado ou combinado com outros recursos em pacotes projetados para públicos específicos de desenvolvedores. Alguns recursos da API Acceleration Service ou de toda a API podem eventualmente se tornar disponíveis para o público geral, mas não há um cronograma fixo para isso.
Termos e privacidade
Termos de serviço
O uso das APIs do Acceleration Service está sujeito aos Termos de Serviço das APIs do Google .
Além disso, as APIs do Acceleration Service estão atualmente em versão beta e, como tal, ao usá-las, você reconhece os possíveis problemas descritos na seção Advertências acima e reconhece que o Acceleration Service pode nem sempre funcionar conforme especificado.
Privacidade
Quando você usa as APIs do Acceleration Service, o processamento dos dados de entrada (por exemplo, imagens, vídeo, texto) ocorre integralmente no dispositivo, e o Acceleration Service não envia esses dados aos servidores do Google . Como resultado, você pode usar nossas APIs para processar dados de entrada que não devem sair do dispositivo.
As APIs do serviço de aceleração podem entrar em contato com os servidores do Google periodicamente para receber itens como correções de bugs, modelos atualizados e informações de compatibilidade de aceleradores de hardware. As APIs do serviço de aceleração também enviam ao Google métricas sobre o desempenho e a utilização das APIs no seu aplicativo. O Google usa esses dados de métricas para medir o desempenho, depurar, manter e melhorar as APIs e detectar uso indevido ou abuso, conforme descrito mais detalhadamente em nossa Política de Privacidade .
Você é responsável por informar os usuários do seu aplicativo sobre o processamento dos dados de métricas do Serviço de Aceleração pelo Google, conforme exigido pela lei aplicável.
Os dados que coletamos incluem o seguinte:
- Informações do dispositivo (como fabricante, modelo, versão do sistema operacional e compilação) e aceleradores de hardware de ML disponíveis (GPU e DSP). Usado para diagnósticos e análises de uso.
- Informações do aplicativo (nome do pacote/ID do pacote, versão do aplicativo). Usado para diagnósticos e análises de uso.
- Configuração da API (como formato e resolução da imagem). Usado para diagnósticos e análises de uso.
- Tipo de evento (como inicialização, modelo de download, atualização, execução, detecção). Usado para diagnósticos e análises de uso.
- Códigos de erro. Usado para diagnósticos.
- Métricas de desempenho. Usado para diagnósticos.
- Identificadores por instalação que não identificam exclusivamente um usuário ou dispositivo físico. Usado para operação de configuração remota e análise de uso.
- Endereços IP do remetente da solicitação de rede. Usado para diagnóstico de configuração remota. Os endereços IP coletados são retidos temporariamente.
Suporte e feedback
Você pode fornecer feedback e obter suporte por meio do TensorFlow Issue Tracker. Relate problemas e solicitações de suporte usando o modelo de problema do TensorFlow Lite no Google Play Services.