
Juega un juego de mesa contra un agente, que se entrena con el aprendizaje por refuerzo y se implementa con TensorFlow Lite.
Empezar
Si es nuevo en TensorFlow Lite y está trabajando con Android, le recomendamos explorar la siguiente aplicación de ejemplo que puede ayudarlo a comenzar.
Si usa una plataforma que no sea Android, o si ya está familiarizado con las API de TensorFlow Lite , puede descargar nuestro modelo entrenado.
Cómo funciona
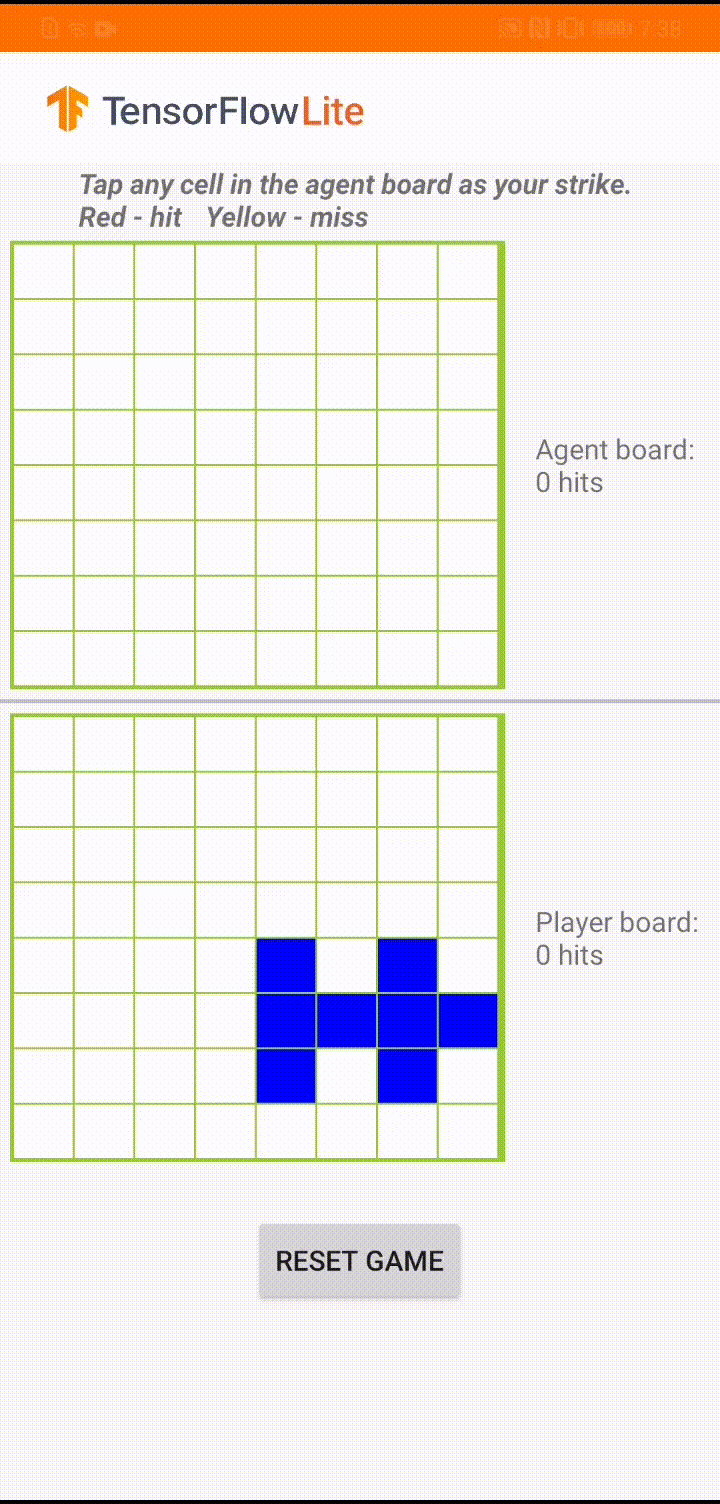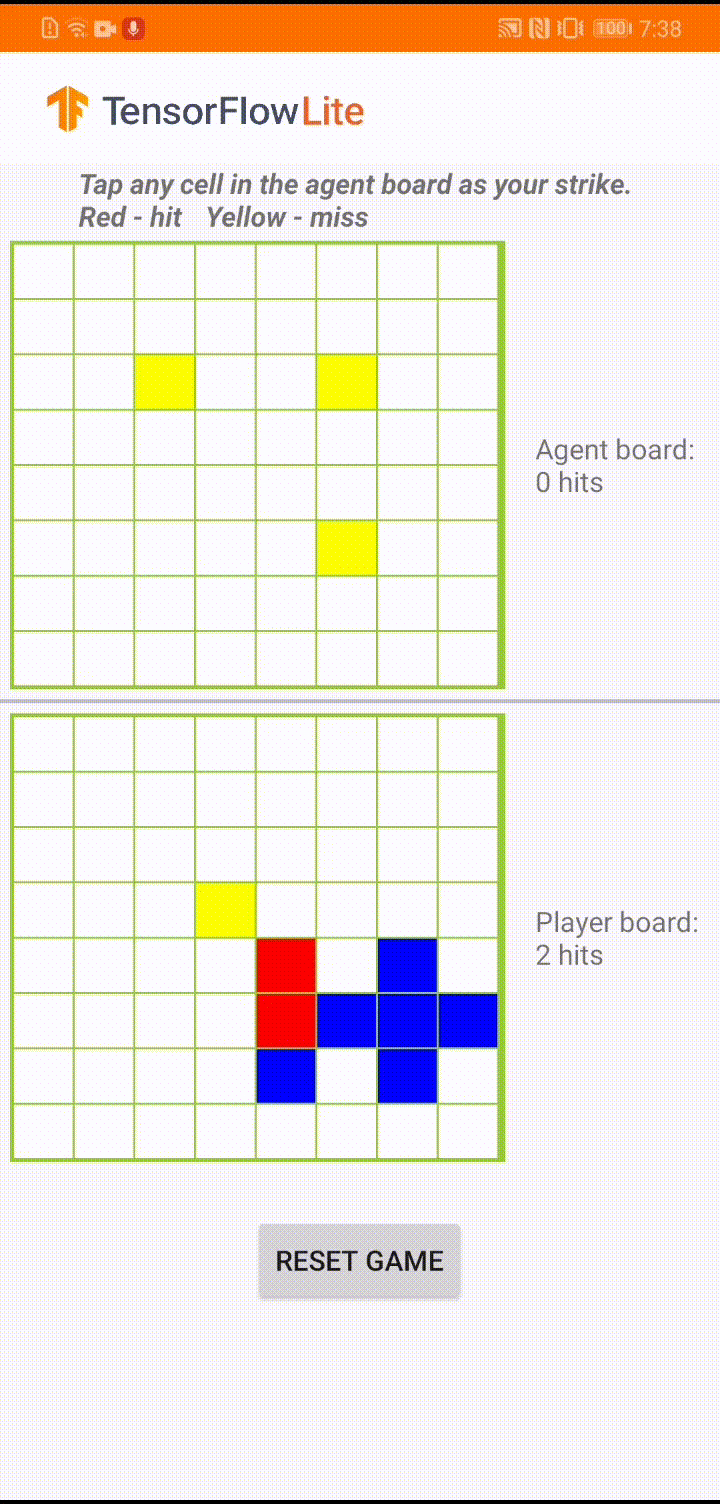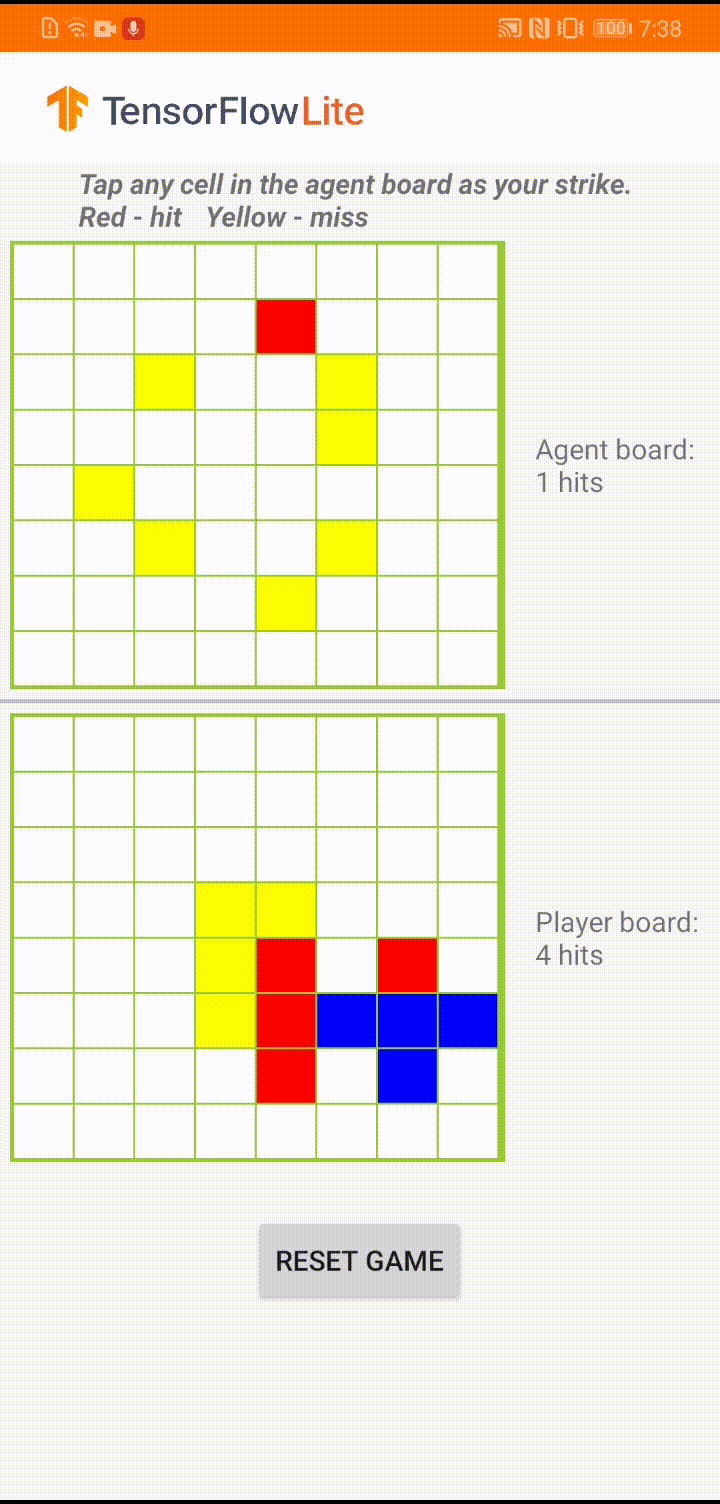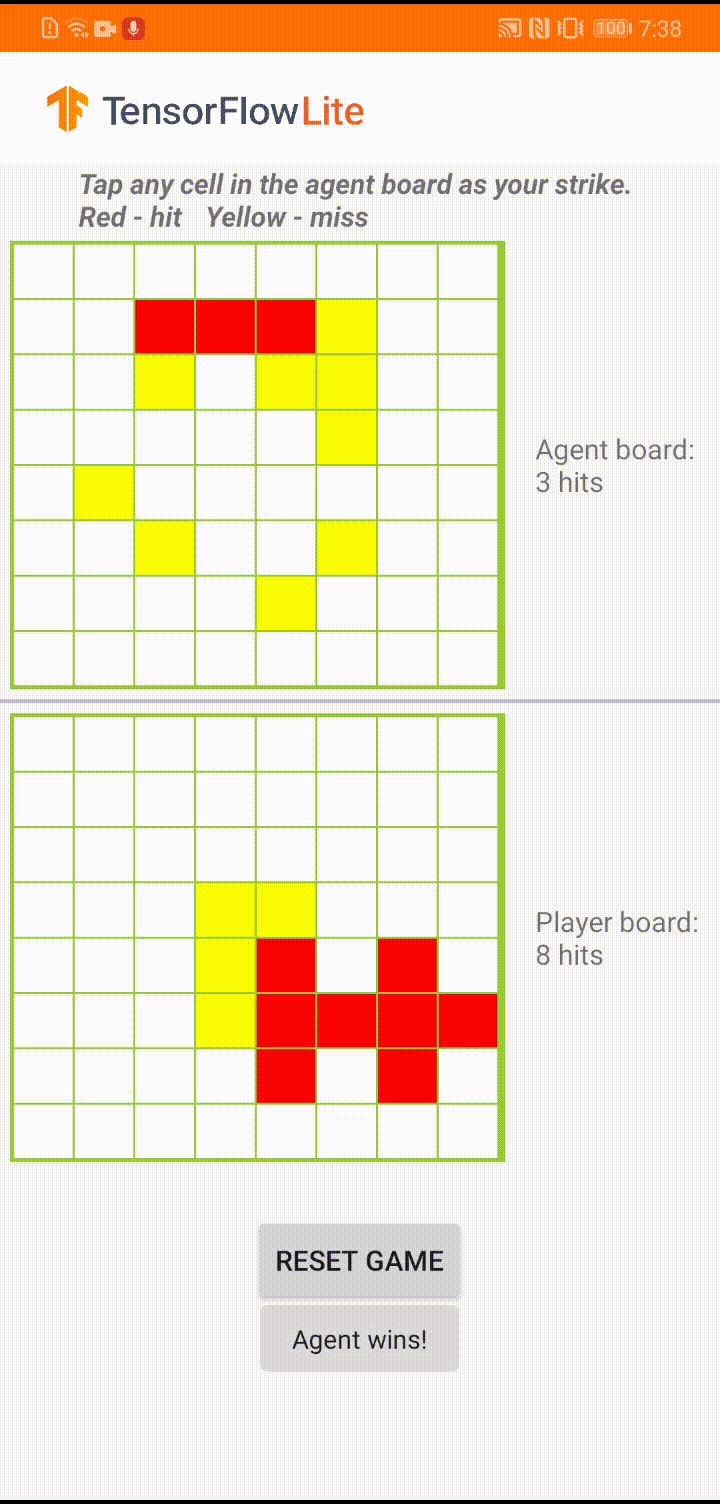
El modelo está diseñado para que un agente del juego juegue un pequeño juego de mesa llamado 'Plane Strike'. Para obtener una introducción rápida a este juego y sus reglas, consulte este LÉAME .
Debajo de la interfaz de usuario de la aplicación, hemos creado un agente que juega contra el jugador humano. El agente es un MLP de 3 capas que toma el estado del tablero como entrada y genera la puntuación pronosticada para cada una de las 64 posibles celdas del tablero. El modelo se entrena usando gradiente de política (REFORZAR) y puede encontrar el código de entrenamiento aquí . Después de entrenar al agente, convertimos el modelo en TFLite y lo implementamos en la aplicación de Android.
Durante el juego real en la aplicación de Android, cuando es el turno del agente de tomar acción, el agente mira el estado del tablero del jugador humano (el tablero en la parte inferior), que contiene información sobre ataques exitosos y fallidos anteriores (aciertos y errores) , y usa el modelo entrenado para predecir dónde golpear a continuación, de modo que pueda terminar el juego antes que el jugador humano.
Puntos de referencia de rendimiento
Los números de referencia de rendimiento se generan con la herramienta que se describe aquí .
| Nombre del modelo | Tamaño del modelo | Dispositivo | UPC |
|---|---|---|---|
| Gradiente de política | 84 Kb | Píxel 3 (Android 10) | 0,01 ms* |
| Píxel 4 (Android 10) | 0,01 ms* |
* 1 hilos utilizados.
Entradas
El modelo acepta un tensor 3-D float32 de (1, 8, 8) como estado de la placa.
Salidas
El modelo devuelve un tensor de forma 2-D float32 (1,64) como las puntuaciones predichas para cada una de las 64 posibles posiciones de ataque.
Entrena tu propio modelo
Puede entrenar su propio modelo para una placa más grande o más pequeña cambiando el parámetro BOARD_SIZE en el código de entrenamiento .