
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | | |
بررسی اجمالی
این بررسی طبقه بندی نوت بوک فیلم به عنوان مثبت یا منفی با استفاده از متن نظر. این یک نمونه از طبقه بندی باینری، یک نوع مهم و به طور گسترده ای قابل اجرا از مشکل یادگیری ماشین است.
ما با ساختن یک نمودار از ورودی داده شده، استفاده از منظم سازی نمودار را در این دفترچه نشان خواهیم داد. دستور کلی برای ساختن یک مدل منظم شده با نمودار با استفاده از چارچوب یادگیری ساختاریافته عصبی (NSL) زمانی که ورودی شامل گراف صریح نباشد به شرح زیر است:
- برای هر نمونه متن در ورودی، جاسازی ایجاد کنید. این را می توان با استفاده از مدل های از پیش آموزش دیده را به عنوان انجام word2vec ، مفصل گردنده ، برت و غیره
- با استفاده از یک متریک شباهت مانند فاصله "L2"، فاصله "کسینوس" و غیره، یک نمودار بر اساس این جاسازیها بسازید. گرهها در نمودار با نمونهها و یالهای نمودار با شباهت بین جفتهای نمونه مطابقت دارند.
- داده های آموزشی را از نمودار سنتز شده بالا و ویژگی های نمونه تولید کنید. دادههای آموزشی حاصل علاوه بر ویژگیهای گره اصلی شامل ویژگیهای همسایه خواهد بود.
- یک شبکه عصبی به عنوان مدل پایه با استفاده از API ترتیبی، عملکردی یا زیر کلاسی Keras ایجاد کنید.
- مدل پایه را با کلاس wrapper GraphRegularization که توسط چارچوب NSL ارائه شده است، بپیچید تا یک مدل کراس گراف جدید ایجاد کنید. این مدل جدید شامل از دست دادن منظم گراف به عنوان اصطلاح تنظیم در هدف آموزشی خود می شود.
- مدل کراس گراف را آموزش و ارزیابی کنید.
الزامات
- بسته یادگیری ساختار یافته عصبی را نصب کنید.
- tensorflow-hub را نصب کنید.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
وابستگی ها و واردات
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
مجموعه داده های IMDB
مجموعه داده IMDB حاوی متن 50،000 بررسی فیلم از بانک اطلاعات اینترنتی فیلمها . اینها به 25000 بررسی برای آموزش و 25000 بررسی برای آزمایش تقسیم می شوند. مجموعه آموزش و تست متعادل، بدین معنی که شامل تعداد مساوی از بررسی مثبت و منفی.
در این آموزش از نسخه پیش پردازش شده مجموعه داده های IMDB استفاده می کنیم.
مجموعه داده های IMDB از پیش پردازش شده را دانلود کنید
مجموعه داده IMDB با TensorFlow بسته بندی شده است. قبلاً به گونهای پیش پردازش شده است که بررسیها (توالی کلمات) به دنبالهای از اعداد صحیح تبدیل شدهاند که در آن هر عدد صحیح یک کلمه خاص را در فرهنگ لغت نشان میدهد.
کد زیر مجموعه داده IMDB را دانلود می کند (یا اگر قبلاً دانلود شده باشد از یک نسخه کش استفاده می کند):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
استدلال num_words=10000 بالای 10000 کلمات اغلب اتفاق می افتد در داده های آموزشی را نگه می دارد. لغات کمیاب کنار گذاشته می شوند تا اندازه واژگان قابل کنترل باشد.
داده ها را کاوش کنید
بیایید یک لحظه برای درک قالب داده ها وقت بگذاریم. مجموعه داده از پیش پردازش شده است: هر نمونه آرایه ای از اعداد صحیح است که کلمات مرور فیلم را نشان می دهد. هر برچسب یک مقدار صحیح 0 یا 1 است که 0 یک بررسی منفی و 1 یک بررسی مثبت است.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
متن بررسی ها به اعداد صحیح تبدیل شده است، که در آن هر عدد صحیح یک کلمه خاص را در فرهنگ لغت نشان می دهد. در اینجا اولین بررسی به نظر می رسد:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
بررسی های فیلم ممکن است طول های متفاوتی داشته باشند. کد زیر تعداد کلمات را در بررسی اول و دوم نشان می دهد. از آنجایی که طول ورودی های یک شبکه عصبی باید یکسان باشد، باید بعداً این موضوع را حل کنیم.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
اعداد صحیح را به کلمات تبدیل کنید
دانستن چگونگی تبدیل اعداد صحیح به متن مربوطه ممکن است مفید باشد. در اینجا، ما یک تابع کمکی برای پرس و جو از یک شی فرهنگ لغت که حاوی نگاشت عدد صحیح به رشته است ایجاد می کنیم:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
حالا ما می توانیم با استفاده از decode_review تابع برای نمایش متن برای بررسی برای اولین بار:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
ساخت نمودار
ساخت نمودار شامل ایجاد جاسازی برای نمونه های متن و سپس استفاده از تابع شباهت برای مقایسه جاسازی ها است.
قبل از ادامه، ابتدا یک دایرکتوری برای ذخیره مصنوعات ایجاد شده توسط این آموزش ایجاد می کنیم.
mkdir -p /tmp/imdb
تعبیههای نمونه ایجاد کنید
ما درونه گیریها مفصل گردنده pretrained به ایجاد درونه گیریها در استفاده خواهد کرد tf.train.Example فرمت برای هر نمونه در ورودی. ما در درونه گیریها و در نتیجه ذخیره خواهد شد TFRecord فرمت همراه با ویژگی های اضافی است که نشان دهنده ID از هر نمونه. این مهم است و به ما امکان می دهد جاسازی های نمونه را با گره های مربوطه در نمودار بعداً مطابقت دهیم.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
یک نمودار بسازید
اکنون که نمونههای جاسازی شده را داریم، از آنها برای ساختن یک نمودار شباهت استفاده میکنیم، یعنی گرههای این نمودار با نمونهها و یالهای این نمودار با شباهت بین جفت گرهها مطابقت دارند.
Neural Structured Learning یک کتابخانه ساخت گراف برای ساخت یک نمودار بر اساس جاسازی های نمونه فراهم می کند. آن استفاده می کند شباهت کسینوسی به عنوان اندازه گیری شباهت برای مقایسه درونه گیریها و لبه ساخت بین آنها. همچنین به ما اجازه میدهد تا آستانه شباهت را مشخص کنیم، که میتوان از آن برای حذف یالهای غیرمشابه از نمودار نهایی استفاده کرد. در این مثال، با استفاده از 0.99 به عنوان آستانه تشابه و 12345 به عنوان دانه تصادفی، به نموداری می رسیم که دارای 429415 یال دو جهته است. در اینجا ما با استفاده از پشتیبانی سازنده گراف برای حساس به محل هش (LSH) برای سرعت بخشیدن به ساخت و ساز نمودار. برای جزئیات در مورد پشتیبانی LSH سازنده نمودار است، ببینید build_graph_from_config مستندات API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
هر یال دو طرفه با دو یال جهتدار در فایل خروجی TSV نشان داده میشود، به طوری که آن فایل شامل 429415 * 2 = 858830 خط کل است:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
ویژگی های نمونه
ما ایجاد ویژگی های نمونه برای مشکل ما با استفاده از tf.train.Example فرمت و باقی بماند آنها را در TFRecord فرمت. هر نمونه شامل سه ویژگی زیر خواهد بود:
- ID: شناسه گره از نمونه است.
- کلمات: یک لیست int64 حاوی شناسه کلمه.
- برچسب ها: تک int64 شناسایی کلاس هدف از بررسی است.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
داده های آموزشی را با همسایگان گراف تقویت کنید
از آنجایی که ویژگیهای نمونه و نمودار سنتز شده را داریم، میتوانیم دادههای آموزشی تقویتشده را برای یادگیری ساختاریافته عصبی تولید کنیم. چارچوب NSL کتابخانه ای برای ترکیب نمودار و ویژگی های نمونه برای تولید داده های آموزشی نهایی برای تنظیم گراف فراهم می کند. دادههای آموزشی حاصل شامل ویژگیهای نمونه اصلی و همچنین ویژگیهای همسایگان مربوطه خواهد بود.
در این آموزش، لبه های بدون جهت را در نظر می گیریم و از حداکثر 3 همسایه در هر نمونه برای تقویت داده های آموزشی با همسایه های گراف استفاده می کنیم.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
مدل پایه
اکنون آماده ساخت یک مدل پایه بدون تنظیم گراف هستیم. برای ساخت این مدل، میتوانیم از تعبیههایی استفاده کنیم که در ساخت نمودار استفاده شدهاند، یا میتوانیم جاسازیهای جدید را بهطور مشترک همراه با کار طبقهبندی یاد بگیریم. برای هدف این دفترچه، دومی را انجام خواهیم داد.
متغیرهای جهانی
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
فراپارامترها
ما یک نمونه از استفاده خواهد کرد HParams به inclue hyperparameters و ثابت های مختلف مورد استفاده برای آموزش و ارزیابی است. در زیر به اختصار هر یک را توضیح می دهیم:
num_classes: 2 طبقات وجود دارد - مثبت و منفی.
max_seq_length: این حداکثر تعداد کلمات از هر بررسی فیلم در این مثال در نظر گرفته است.
vocab_size: این اندازه از واژگان برای این مثال در نظر گرفته است.
distance_type: این فاصله متریک استفاده می شود به قاعدهمند نمونه با همسایگان خود است.
graph_regularization_multiplier: این کنترل وزن نسبی از مدت قانونی نمودار در تابع از دست دادن کلی.
num_neighbors: تعداد همسایه مورد استفاده برای تنظیم نمودار. این مقدار را به کمتر یا برابر
max_nbrsاستدلال بالا را هنگام فراخوانیnsl.tools.pack_nbrs.num_fc_units: تعداد واحدهای در لایه به طور کامل متصل از شبکه های عصبی.
train_epochs: تعداد دوره های آموزشی.
اندازه دسته ای مورد استفاده برای آموزش و ارزیابی: batch_size.
eval_steps: تعداد دسته دسته به فرایند قبل از deeming ارزیابی کامل است. اگر به مجموعه ای از
None، همه موارد در مجموعه آزمون ارزیابی می شوند.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
داده ها را آماده کنید
بررسی ها - آرایه های اعداد صحیح - باید قبل از وارد شدن به شبکه عصبی به تانسور تبدیل شوند. این تبدیل را می توان به دو روش انجام داد:
تبدیل آرایه به بردار از
0و1ها نشان می دهد وقوع کلمه، شبیه به یک پشتیبانی می کند یک گرم است. به عنوان مثال، توالی[3, 5]یک تبدیل10000برداری بعدی است که تمام صفرهای جز شاخص3و5است که آنهایی که. سپس، این لایه برای اولین بار در شبکه ما یکDenseلایه که می تواند اداره داده های برداری ممیز شناور. این رویکرد حافظه فشرده است، هر چند، نیاز به یکnum_words * num_reviewsماتریس اندازه.روش دیگر، ما می توانید پد آرایه به طوری که آنها تمام طول یکسانی، سپس یک تانسور عدد صحیح از شکل ایجاد
max_length * num_reviews. ما می توانیم از یک لایه جاسازی که قادر به مدیریت این شکل است به عنوان اولین لایه در شبکه خود استفاده کنیم.
در این آموزش از روش دوم استفاده خواهیم کرد.
از آنجا که بررسی فیلم باید همان طول باشد، ما را به استفاده از pad_sequence تابع تعریف زیر برای استاندارد.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
مدل را بسازید
یک شبکه عصبی با انباشته کردن لایهها ایجاد میشود - این به دو تصمیم اصلی معماری نیاز دارد:
- از چند لایه در مدل استفاده کنیم؟
- چگونه بسیاری از واحد های پنهان برای استفاده برای هر یک از لایه؟
در این مثال، داده های ورودی از آرایه ای از شاخص های کلمه تشکیل شده است. برچسب هایی که باید پیش بینی کرد 0 یا 1 هستند.
ما در این آموزش از یک LSTM دو جهته به عنوان مدل پایه خود استفاده خواهیم کرد.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
لایه ها به طور موثر برای ساخت طبقه بندی کننده به صورت متوالی روی هم چیده می شوند:
- لایه اول است
Inputلایه که طول می کشد واژگان صحیح کد گذاری است. - لایه بعدی است
Embeddingلایه، که طول می کشد واژگان صحیح کد گذاری شده و به نظر می رسد تا بردار تعبیه برای هر کلمه شاخص. این بردارها به عنوان آموزش مدل یاد می شوند. بردارها یک بعد به آرایه خروجی اضافه می کنند. ابعاد و در نتیجه:(batch, sequence, embedding). - در مرحله بعد، یک لایه LSTM دو طرفه برای هر مثال یک بردار خروجی با طول ثابت را برمی گرداند.
- این طول ثابت بردار خروجی از طریق یک کامل متصل (لوله کشی
Denseلایه) با 64 واحد پنهان است. - آخرین لایه به طور متراکم با یک گره خروجی متصل است. با استفاده از
sigmoidتابع فعال، این مقدار یک شناور بین 0 و 1 است، به نمایندگی از احتمال، و یا سطح اعتماد به نفس.
واحدهای پنهان
مدل فوق دارای دو یا "پنهان" لایه میانی، بین ورودی و خروجی، و به استثنای Embedding لایه. تعداد خروجی ها (واحدها، گره ها یا نورون ها) بعد فضای نمایشی لایه است. به عبارت دیگر، میزان آزادی شبکه در هنگام یادگیری یک نمایش داخلی مجاز است.
اگر یک مدل واحدهای پنهان بیشتری (یک فضای نمایش با ابعاد بالاتر) و/یا لایه های بیشتری داشته باشد، شبکه می تواند نمایش های پیچیده تری را بیاموزد. با این حال، شبکه را از نظر محاسباتی گرانتر میکند و ممکن است به یادگیری الگوهای ناخواسته منجر شود - الگوهایی که عملکرد را در دادههای آموزشی بهبود میبخشند اما در دادههای آزمایشی نه. این Over-fitting خواهد نامیده می شود.
عملکرد از دست دادن و بهینه ساز
یک مدل برای آموزش به تابع ضرر و بهینه ساز نیاز دارد. از آنجایی که این مشکل طبقه بندی دودویی و مدل خروجی احتمال (یک لایه تک واحدی با فعال سازی سیگموئید) است، ما از استفاده از binary_crossentropy تابع از دست دادن.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
یک مجموعه اعتبار سنجی ایجاد کنید
هنگام آموزش، میخواهیم دقت مدل را روی دادههایی که قبلاً ندیده است بررسی کنیم. درست مجموعه اعتبار با تنظیم هم جدا کسری از داده های آموزشی اصلی است. (چرا اکنون از مجموعه تست استفاده نمی کنیم؟ هدف ما این است که مدل خود را فقط با استفاده از داده های آموزشی توسعه و تنظیم کنیم، سپس از داده های تست فقط یک بار برای ارزیابی دقت خود استفاده کنیم).
در این آموزش، ما تقریباً 10٪ از نمونه های آموزشی اولیه (10٪ از 25000) را به عنوان داده های برچسب دار برای آموزش و بقیه را به عنوان داده های اعتبار سنجی می گیریم. از آنجایی که تقسیم اولیه قطار/آزمایش 50/50 بود (هر کدام 25000 نمونه)، تقسیم موثر قطار/ اعتبارسنجی/آزمایشی که اکنون داریم 5/45/50 است.
توجه داشته باشید که «train_dataset» قبلاً دستهبندی و به هم ریخته شده است.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
مدل را آموزش دهید
مدل را در مینی دسته ها آموزش دهید. در حین آموزش، از دست دادن و دقت مدل در مجموعه اعتبارسنجی نظارت کنید:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
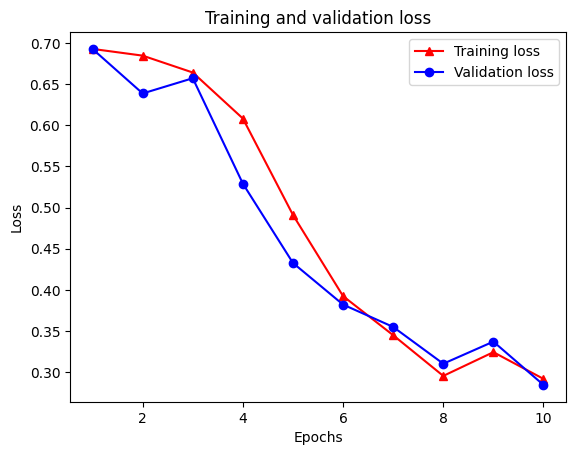
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
مدل را ارزیابی کنید
حال، بیایید ببینیم که مدل چگونه عمل می کند. دو مقدار برگردانده خواهد شد. ضرر (عددی که نشان دهنده خطای ما است، مقادیر کمتر بهتر است) و دقت.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
نموداری از دقت / ضرر در طول زمان ایجاد کنید
model.fit() برمی گرداند History شی که شامل یک فرهنگ لغت با هر چیزی که در آموزش اتفاق افتاده است:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
چهار ورودی وجود دارد: یکی برای هر معیار نظارت شده در طول آموزش و اعتبارسنجی. میتوانیم از اینها برای ترسیم از دست دادن آموزش و اعتبارسنجی برای مقایسه، و همچنین دقت آموزش و اعتبار سنجی استفاده کنیم:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
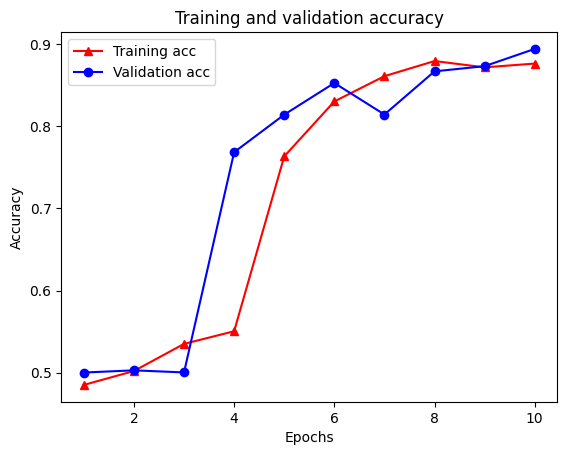
توجه داشته باشید که از دست دادن آموزش با هر دوره و آموزش دقت با هر دوره کاهش می یابد. هنگام استفاده از بهینهسازی نزولی گرادیان، این مورد انتظار میرود - باید مقدار مورد نظر را در هر تکرار به حداقل برساند.
منظم سازی نمودار
ما اکنون آماده هستیم تا با استفاده از مدل پایه ای که در بالا ساخته ایم، تنظیم نمودار را امتحان کنیم. ما در بر استفاده خواهد کرد GraphRegularization کلاس لفاف بسته بندی ارائه شده توسط چارچوب آموزش های عصبی سازه به بسته بندی مدل پایه (دو LSTM) شامل تنظیم نمودار. بقیه مراحل برای آموزش و ارزیابی مدل منظم شده با نمودار شبیه به مدل پایه است.
مدلی با نمودار منظم ایجاد کنید
برای ارزیابی مزیت افزایشی منظمسازی نمودار، یک نمونه مدل پایه جدید ایجاد میکنیم. دلیل این است که model در حال حاضر برای چند تکرار آموزش داده شده است، و استفاده مجدد از این مدل آموزش دیده برای ایجاد یک مدل-نمودار منظم نخواهد بود یک مقایسه عادلانه برای model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
مدل را آموزش دهید
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
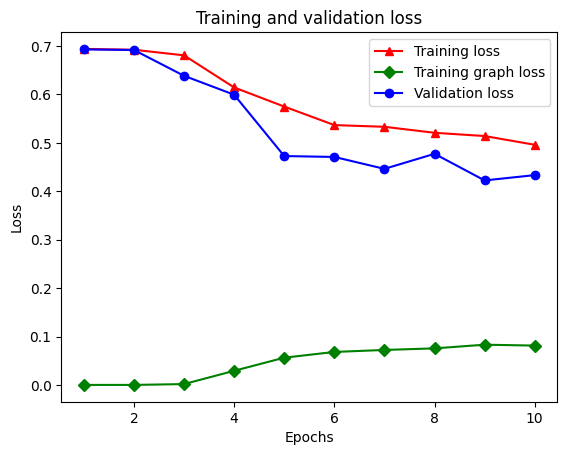
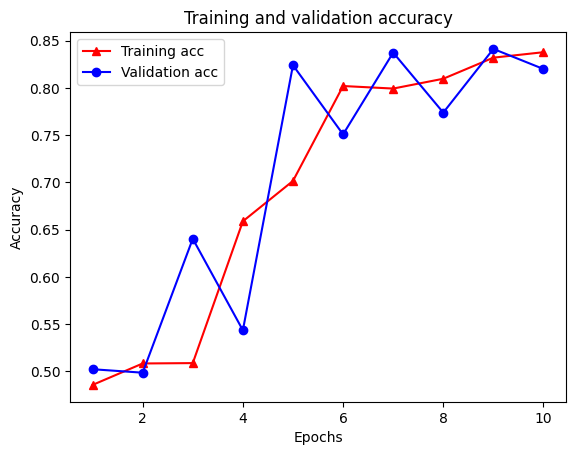
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
مدل را ارزیابی کنید
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
نموداری از دقت / ضرر در طول زمان ایجاد کنید
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
در کل پنج مدخل در فرهنگ لغت وجود دارد: از دست دادن آموزش، دقت آموزش، از دست دادن نمودار آموزشی، از دست دادن اعتبار و دقت اعتبار سنجی. ما می توانیم همه آنها را با هم برای مقایسه ترسیم کنیم. توجه داشته باشید که از دست دادن نمودار فقط در طول آموزش محاسبه می شود.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
قدرت یادگیری نیمه نظارتی
یادگیری نیمه نظارتی و به طور خاص تر، منظم کردن نمودار در چارچوب این آموزش، زمانی که حجم داده های آموزشی کم باشد، می تواند واقعا قدرتمند باشد. کمبود دادههای آموزشی با اعمال شباهت بین نمونههای آموزشی جبران میشود، که در یادگیری نظارت شده سنتی امکانپذیر نیست.
نسبت نظارت به عنوان نسبت آموزش نمونه ها به تعداد کل نمونه ها که شامل آموزش، اعتبار، و نمونه های آزمون تعریف می کنیم. در این نوت بوک، ما از نسبت نظارت 0.05 (یعنی 5٪ از داده های برچسب زده شده) برای آموزش مدل پایه و همچنین مدل منظم شده با نمودار استفاده کرده ایم. ما تأثیر نسبت نظارت بر دقت مدل را در سلول زیر نشان میدهیم.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
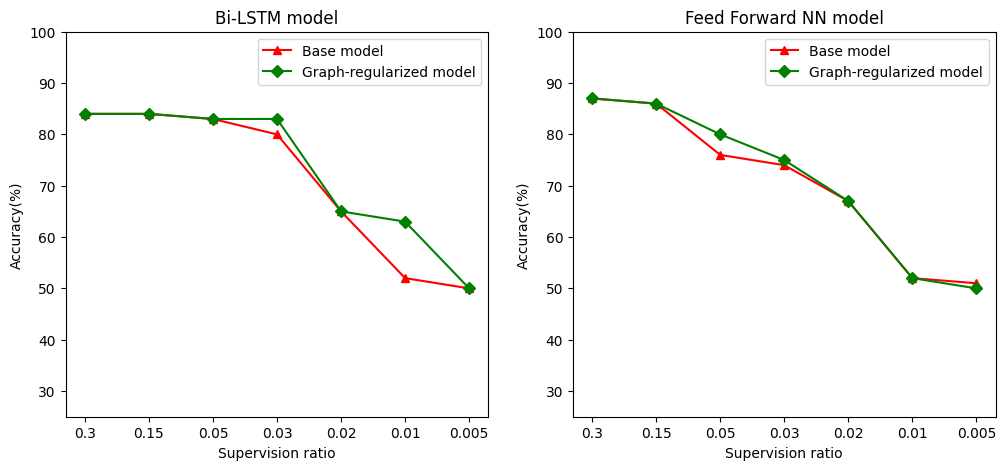
می توان مشاهده کرد که با کاهش نسبت نظارت، دقت مدل نیز کاهش می یابد. این هم برای مدل پایه و هم برای مدل منظم شده با نمودار، صرف نظر از معماری مدل استفاده شده صادق است. با این حال، توجه داشته باشید که مدل منظم شده با نمودار عملکرد بهتری نسبت به مدل پایه برای هر دو معماری دارد. به طور خاص، برای مدل بی LSTM، هنگامی که نسبت نظارت 0.01 است، از دقت و صحت مدل نمودار منظم است ~ 20٪ بالاتر از مدل پایه. این در درجه اول به دلیل یادگیری نیمه نظارت شده برای مدل تنظیم شده با نمودار است، که در آن شباهت ساختاری بین نمونه های آموزشی علاوه بر خود نمونه های آموزشی استفاده می شود.
نتیجه
ما استفاده از منظمسازی گراف را با استفاده از چارچوب یادگیری ساختاریافته عصبی (NSL) نشان دادهایم، حتی زمانی که ورودی شامل یک نمودار صریح نباشد. ما وظیفه طبقهبندی احساسات نقدهای فیلم IMDB را در نظر گرفتیم که برای آن یک نمودار شباهت بر اساس جاسازیهای مرور ترکیب کردیم. ما کاربران را تشویق میکنیم تا با تغییر فراپارامترها، میزان نظارت و استفاده از معماریهای مدلهای مختلف، آزمایش بیشتری انجام دهند.