
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | | |
Przegląd
To klasyfikuje notebooków filmowe opinii jako pozytywne lub negatywne wykorzystujące tekst przeglądu. To jest przykład klasyfikacji binarnej, ważnym i powszechnie stosowanego rodzaju problemu uczenia maszynowego.
W tym zeszycie zademonstrujemy użycie regularyzacji wykresów, budując wykres na podstawie danych wejściowych. Ogólna recepta na zbudowanie modelu z uregulowanym wykresem przy użyciu struktury Neural Structured Learning (NSL), gdy dane wejściowe nie zawierają wyraźnego wykresu, jest następująca:
- Utwórz osadzania dla każdej próbki tekstu w danych wejściowych. Można to zrobić za pomocą wstępnie przeszkolony modele takie jak word2vec , Swivel , BERT etc.
- Zbuduj wykres na podstawie tych osadzeń, używając metryki podobieństwa, takiej jak odległość „L2”, odległość „cosinus” itp. Węzły na wykresie odpowiadają próbkom, a krawędzie na wykresie odpowiadają podobieństwom między parami próbek.
- Wygeneruj dane treningowe z powyższego zsyntetyzowanego wykresu i przykładowych funkcji. Otrzymane dane treningowe będą zawierały cechy sąsiednie oprócz oryginalnych cech węzła.
- Utwórz sieć neuronową jako model bazowy, korzystając z sekwencyjnego, funkcjonalnego lub podklasy API Keras.
- Otocz model podstawowy klasą otoki GraphRegularization, która jest dostarczana przez platformę NSL, aby utworzyć nowy model Keras grafów. Ten nowy model będzie zawierał utratę regularyzacji wykresu jako termin regularyzacji w swoim celu treningowym.
- Trenuj i oceniaj wykres modelu Kerasa.
Wymagania
- Zainstaluj pakiet Neural Structured Learning.
- Zainstaluj koncentrator tensorflow.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
Zależności i importy
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Zbiór danych IMDB
IMDB zbiór danych zawiera tekst 50.000 recenzje filmów z Bazy Internet Movie . Są one podzielone na 25 000 recenzji do szkolenia i 25 000 recenzji do testów. Zestawy treningowe i testowe są zrównoważone, co oznacza, że zawierają taką samą liczbę pozytywnych i negatywnych opinii.
W tym samouczku użyjemy wstępnie przetworzonej wersji zestawu danych IMDB.
Pobierz wstępnie przetworzony zbiór danych IMDB
Zestaw danych IMDB jest dostarczany w pakiecie z TensorFlow. Został on już wstępnie przetworzony w taki sposób, że recenzje (sekwencje słów) zostały przekonwertowane na ciągi liczb całkowitych, gdzie każda liczba całkowita reprezentuje określone słowo w słowniku.
Poniższy kod pobiera zestaw danych IMDB (lub używa kopii z pamięci podręcznej, jeśli została już pobrana):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
Argument num_words=10000 utrzymuje najwyższe 10.000 najczęściej występujących słów w danych treningowych. Rzadkie słowa są odrzucane, aby utrzymać rozmiar słownictwa w zarządzaniu.
Przeglądaj dane
Poświęćmy chwilę, aby zrozumieć format danych. Zestaw danych jest wstępnie przetworzony: każdy przykład to tablica liczb całkowitych reprezentujących słowa recenzji filmu. Każda etykieta jest wartością całkowitą równą 0 lub 1, gdzie 0 to negatywna recenzja, a 1 to pozytywna recenzja.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
Tekst recenzji został przekonwertowany na liczby całkowite, gdzie każda liczba oznacza określone słowo w słowniku. Oto jak wygląda pierwsza recenzja:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
Recenzje filmów mogą mieć różną długość. Poniższy kod pokazuje liczbę słów w pierwszej i drugiej recenzji. Ponieważ dane wejściowe do sieci neuronowej muszą mieć tę samą długość, będziemy musieli rozwiązać ten problem później.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
Konwertuj liczby całkowite z powrotem na słowa
Warto wiedzieć, jak przekonwertować liczby całkowite z powrotem na odpowiedni tekst. Tutaj utworzymy funkcję pomocniczą do zapytania obiektu słownika zawierającego odwzorowanie liczby całkowitej na ciąg znaków:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
Teraz możemy użyć decode_review funkcję do wyświetlania tekstu na pierwszy test:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
Budowa wykresu
Konstrukcja wykresu obejmuje tworzenie osadzeń dla próbek tekstowych, a następnie użycie funkcji podobieństwa do porównania osadzeń.
Zanim przejdziemy dalej, najpierw utworzymy katalog do przechowywania artefaktów utworzonych w tym samouczku.
mkdir -p /tmp/imdb
Utwórz przykładowe osadzenia
Użyjemy pretrained zanurzeń obrotowy, aby utworzyć zanurzeń w tf.train.Example formacie dla każdej próbki w wejściu. Będziemy przechowywać wynikające zanurzeń w TFRecord formacie wraz z dodatkową funkcją, która reprezentuje identyfikator każdej próbki. Jest to ważne i pozwoli nam później dopasować przykładowe osadzenia do odpowiednich węzłów na wykresie.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
Zbuduj wykres
Teraz, gdy mamy osadzenia próbek, użyjemy ich do zbudowania grafu podobieństwa, tj. węzły w tym grafie będą odpowiadały próbkom, a krawędzie w tym grafie będą odpowiadały podobieństwu między parami węzłów.
Neural Structured Learning zapewnia bibliotekę do budowania wykresów, która umożliwia tworzenie wykresów na podstawie przykładowych osadzeń. Wykorzystuje cosinus podobieństwa jako miara podobieństwa porównać zanurzeń i budować krawędzie między nimi. Pozwala nam również określić próg podobieństwa, który można wykorzystać do odrzucenia niepodobnych krawędzi z końcowego wykresu. W tym przykładzie, używając 0,99 jako progu podobieństwa i 12345 jako losowego ziarna, otrzymujemy wykres, który ma 429 415 dwukierunkowych krawędzi. Tutaj używamy wsparcia na wykresie budowniczego dla miejscowości wrażliwe mieszający (LSH) w celu przyspieszenia tworzenia wykresu. Aby uzyskać szczegółowe informacje na temat korzystania z pomocy LSH wykresie budowniczego, zobacz build_graph_from_config dokumentacji API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
Każda dwukierunkowa krawędź jest reprezentowana przez dwie skierowane krawędzie w wyjściowym pliku TSV, więc plik zawiera 429 415 * 2 = 858 830 wierszy ogółem:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
Przykładowe funkcje
Tworzymy przykładowe możliwości dla naszego problemu z wykorzystaniem tf.train.Example formatu i utrzymują je w TFRecord formacie. Każda próbka będzie zawierać następujące trzy funkcje:
- ID: identyfikator węzła próbki.
- słowa: Lista Int64 identyfikatory zawierające słowo.
- Etykieta: Singleton Int64 identyfikujący klasę docelową przeglądu.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
Rozszerz dane treningowe o sąsiadów wykresu
Ponieważ dysponujemy przykładowymi funkcjami i zsyntetyzowanym wykresem, możemy wygenerować rozszerzone dane treningowe dla uczenia strukturalnego neuronowego. Struktura NSL zapewnia bibliotekę do łączenia wykresu i przykładowych funkcji w celu uzyskania ostatecznych danych treningowych do regularyzacji wykresów. Otrzymane dane treningowe będą zawierać oryginalne cechy próbki, a także cechy ich odpowiednich sąsiadów.
W tym samouczku rozważymy nieskierowane krawędzie i użyjemy maksymalnie 3 sąsiadów na próbkę, aby uzupełnić dane treningowe o sąsiadów wykresu.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
Model podstawowy
Jesteśmy teraz gotowi do zbudowania modelu bazowego bez regularyzacji grafów. W celu zbudowania tego modelu możemy albo użyć osadzeń, które zostały użyte do budowy wykresu, albo wspólnie z zadaniem klasyfikacji możemy uczyć się nowych osadzeń. Na potrzeby tego notatnika zrobimy to drugie.
Zmienne globalne
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
Hiperparametry
Użyjemy wystąpienie HParams do inclue różne hiperparametrów i stałych wykorzystywanych do szkolenia i oceny. Poniżej krótko opisujemy każdy z nich:
num_classes: Istnieją 2 Ćwiczenia - pozytywne i negatywne.
max_seq_length: Jest to maksymalna liczba słów uznawanych z każdego przeglądu filmowego w tym przykładzie.
vocab_size: To jest wielkość słownictwa uważany za tym przykładzie.
distance_type: Jest to odległość metryczny używany w celu uregulowania próbki z sąsiadami.
graph_regularization_multiplier: Steruje względnej masie terminu wykres regularyzacji w ogólnej funkcji strat.
num_neighbors: liczba sąsiadów wykorzystywanych do wykresu uregulowania. Ta wartość musi być mniejsza lub równa
max_nbrsargumentu używanego powyżej podczas wywoływaniansl.tools.pack_nbrs.num_fc_units: Liczba jednostek w pełni połączone warstwy sieci neuronowych.
train_epochs: liczba epok szkoleniowych.
Wielkość partii wykorzystywane do szkolenia i oceny: batch_size.
eval_steps: Numer partii do procesu przed uznania zakonczeniu. Jeśli ustawione na
None, wszystkie instancje w zestawie testowym są oceniane.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
Przygotuj dane
Przeglądy — tablice liczb całkowitych — muszą zostać przekonwertowane na tensory przed wprowadzeniem ich do sieci neuronowej. Tę konwersję można wykonać na kilka sposobów:
Konwersja do macierzy wektorów
0s i1s, co wskazuje na występowanie słowo, podobny do kodowania jednorazowo gorąco. Na przykład, sekwencja[3, 5]stanie się10000wymiarową wektor to same zera oprócz wskaźników3i5, które są z nich. Następnie zrobić to pierwsza warstwa w naszej sieci-aDensewarstwy, które mogą obsługiwać danych zmiennoprzecinkowych wektorowej. Podejście to jest pamięć intensywne, choć wymaganum_words * num_reviewsmatrycy rozmiarze.Alternatywnie, możemy pad tablice więc wszystkie one mają taką samą długość, a następnie utworzyć tensor całkowitą kształt
max_length * num_reviews. Możemy użyć warstwy osadzania zdolnej do obsługi tego kształtu jako pierwszej warstwy w naszej sieci.
W tym samouczku użyjemy drugiego podejścia.
Ponieważ recenzje filmów muszą być tej samej długości, użyjemy pad_sequence funkcję zdefiniowaną poniżej w celu ujednolicenia długości.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
Zbuduj model
Sieć neuronowa jest tworzona przez układanie warstw — wymaga to dwóch głównych decyzji architektonicznych:
- Ile warstw użyć w modelu?
- Ile ukryte jednostki użyć dla każdej warstwy?
W tym przykładzie dane wejściowe składają się z tablicy indeksów słów. Etykiety do przewidzenia to 0 lub 1.
W tym samouczku użyjemy dwukierunkowego LSTM jako naszego modelu podstawowego.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
Warstwy są skutecznie układane w stos sekwencyjny, aby zbudować klasyfikator:
- Pierwsza warstwa jest
Inputwarstwa, która trwa do słownika całkowitą kodowane. - Kolejna warstwa jest
Embeddingwarstwy, która odbywa słownictwo całkowitą kodowane i szuka osadzania wektora dla każdego słowa wskaźniku. Te wektory są uczone jako ciągi modelu. Wektory dodają wymiar do tablicy wyjściowej. Uzyskane wymiary są następujące:(batch, sequence, embedding). - Następnie dwukierunkowa warstwa LSTM zwraca wektor wyjściowy o stałej długości dla każdego przykładu.
- Ten czas trwania wektora wyjściowego jest przetłaczany przez całkowicie połączonej (
Dense) warstwy 64 jednostek ukrytych. - Ostatnia warstwa jest gęsto połączona z pojedynczym węzłem wyjściowym. Używanie
sigmoidfunkcji aktywacji, wartość ta znajduje się pływak od 0 do 1, co oznacza prawdopodobieństwo lub poziom ufności.
Ukryte jednostki
Powyższy model posiada dwie pośrednie lub „ukryte” warstwy, pomiędzy wejściem i wyjściem z wyjątkiem Embedding warstwy. Liczba wyjść (jednostek, węzłów lub neuronów) jest wymiarem przestrzeni reprezentacyjnej warstwy. Innymi słowy, ilość swobody, jaką sieć ma dozwolona podczas uczenia się wewnętrznej reprezentacji.
Jeśli model ma więcej ukrytych jednostek (przestrzeń reprezentacji o wyższym wymiarze) i/lub więcej warstw, sieć może nauczyć się bardziej złożonych reprezentacji. Powoduje to jednak, że sieć jest bardziej kosztowna obliczeniowo i może prowadzić do uczenia się niepożądanych wzorców — wzorców, które poprawiają wydajność na danych uczących, ale nie na danych testowych. To się nazywa nadmiernego dopasowywania.
Funkcja strat i optymalizator
Model potrzebuje funkcji straty i optymalizatora do uczenia. Ponieważ jest binarny problemu klasyfikacji, a model wyjścia prawdopodobieństwem (warstwy pojedynczej jednostki z sigmoidalnej aktywacji) użyjemy binary_crossentropy funkcję strat.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Utwórz zestaw walidacyjny
Podczas uczenia chcemy sprawdzić dokładność modelu na danych, których wcześniej nie widział. Utwórz zestaw zatwierdzenie przez ustawienie poza ułamek oryginalnych danych treningowych. (Dlaczego nie skorzystać z zestawu testowego teraz? Naszym celem jest opracowanie i dostrojenie naszego modelu przy użyciu tylko danych uczących, a następnie wykorzystanie danych testowych tylko raz, aby ocenić naszą dokładność).
W tym samouczku bierzemy około 10% początkowych próbek treningowych (10% z 25000) jako dane oznaczone do treningu, a pozostałe jako dane walidacyjne. Ponieważ początkowy podział na pociąg/test wynosił 50/50 (25 000 próbek każda), efektywny podział na pociąg/walidację/test, jaki mamy teraz, to 5/45/50.
Zwróć uwagę, że „train_dataset” został już zgrupowany i przetasowany.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
Trenuj modelkę
Trenuj model w mini-partiach. Podczas uczenia monitoruj utratę i dokładność modelu na zbiorze walidacyjnym:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
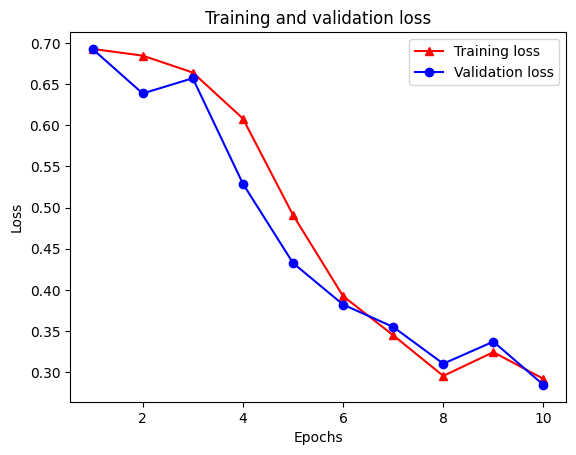
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
Oceń model
Zobaczmy teraz, jak sprawuje się model. Zwrócone zostaną dwie wartości. Strata (liczba, która reprezentuje nasz błąd, niższe wartości są lepsze) i dokładność.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
Utwórz wykres dokładności/straty w czasie
model.fit() zwraca History obiektu, który zawiera słownik z wszystkiego, co wydarzyło się podczas szkolenia:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Istnieją cztery wpisy: po jednym dla każdej metryki monitorowanej podczas uczenia i walidacji. Możemy ich użyć do wykreślenia straty treningu i walidacji w celu porównania, a także dokładności treningu i walidacji:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
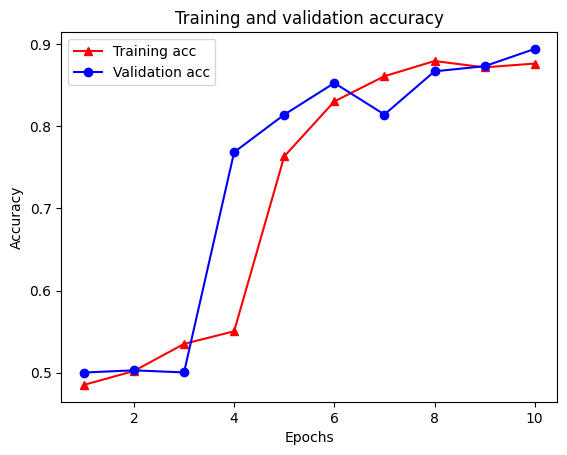
Zauważ, że utrata szkolenia zmniejsza się z każdej epoki oraz szkolenia dokładność zwiększa się z każdej epoki. Jest to oczekiwane podczas korzystania z optymalizacji gradientu — powinno to minimalizować żądaną ilość w każdej iteracji.
Uregulowanie wykresu
Jesteśmy teraz gotowi do wypróbowania regularyzacji wykresów przy użyciu modelu bazowego, który zbudowaliśmy powyżej. Użyjemy GraphRegularization klasy owijki dostarczonego przez Neural Structured ramy uczenia do zawijania wzoru bazowego (BI-LSTM) obejmuje wykres regularyzacji. Pozostałe kroki dotyczące uczenia i oceny modelu z wykresem uregulowanym są podobne do modelu podstawowego.
Utwórz model o regularnym wykresie
Aby ocenić przyrostowe korzyści z regularyzacji wykresów, utworzymy nową instancję modelu bazowego. To dlatego, że model został już przeszkolony przez kilka iteracji i ponownego wykorzystania tego wyszkolony modelu stworzyć model wykres-uregulowana nie będzie uczciwe porównanie model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Trenuj modelkę
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
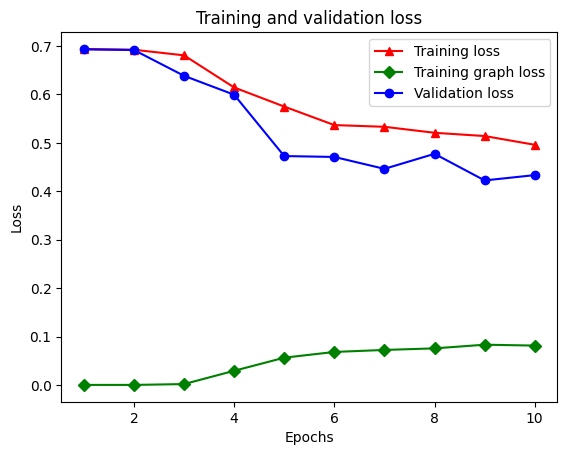
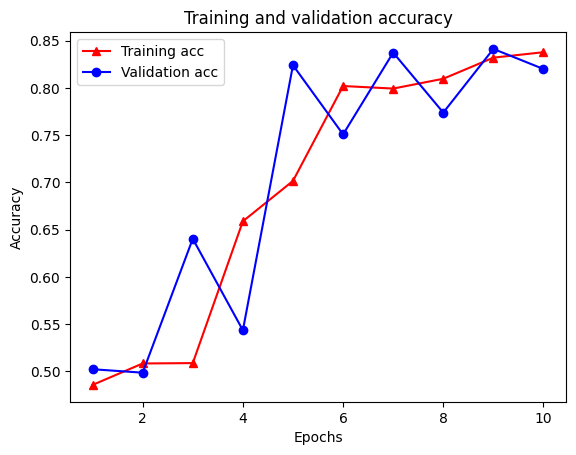
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
Oceń model
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
Utwórz wykres dokładności/straty w czasie
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
W słowniku znajduje się łącznie pięć wpisów: utrata treningu, dokładność treningu, utrata wykresu treningu, utrata walidacji i dokładność walidacji. Możemy wykreślić je wszystkie razem dla porównania. Zwróć uwagę, że utrata wykresu jest obliczana tylko podczas treningu.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
Siła częściowo nadzorowanego uczenia się
Częściowo nadzorowane uczenie się, a dokładniej regularyzacja wykresów w kontekście tego samouczka, może być naprawdę skuteczna, gdy ilość danych szkoleniowych jest niewielka. Brak danych uczących jest kompensowany przez wykorzystanie podobieństwa między próbkami uczącymi, co nie jest możliwe w tradycyjnym uczeniu nadzorowanym.
Zdefiniować jako stosunek nadzoru stosunku szkolenia próbek do całkowitej liczby próbek, które obejmuje szkolenie, poprawności oraz próbek testowych. W tym zeszycie zastosowaliśmy współczynnik nadzoru 0,05 (tj. 5% oznaczonych danych) do trenowania zarówno modelu podstawowego, jak i modelu uregulowanego wykresem. Wpływ wskaźnika nadzoru na dokładność modelu ilustrujemy w poniższej komórce.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
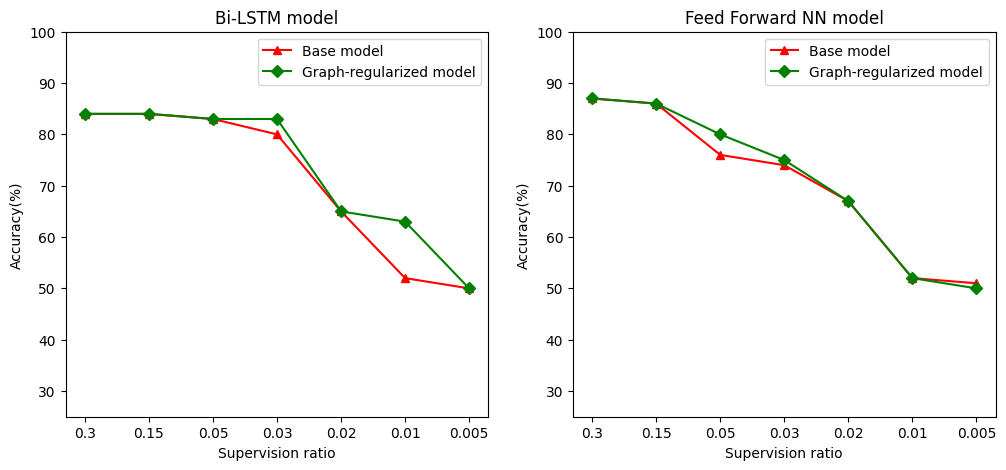
Można zauważyć, że wraz ze spadkiem współczynnika nadzoru spada również dokładność modelu. Dotyczy to zarówno modelu podstawowego, jak i modelu z uregulowaniem wykresu, niezależnie od używanej architektury modelu. Należy jednak zauważyć, że model z wykresem działa lepiej niż model podstawowy dla obu architektur. W szczególności, w modelu Bi LSTM, gdy stosunek Kontrola 0,01 dokładność modelu wykres, uregulowana jest około 20% wyższa niż w przypadku modelu bazowej. Wynika to przede wszystkim z częściowo nadzorowanego uczenia się w modelu z uregulowanym wykresem, w którym podobieństwo strukturalne między próbkami uczącymi jest używane oprócz samych próbek uczących.
Wniosek
Zademonstrowaliśmy użycie regularyzacji grafów przy użyciu struktury Neural Structured Learning (NSL), nawet jeśli dane wejściowe nie zawierają wyraźnego grafu. Rozważaliśmy zadanie klasyfikacji nastrojów recenzji filmów IMDB, dla których zsyntetyzowaliśmy wykres podobieństwa na podstawie osadzonych recenzji. Zachęcamy użytkowników do dalszych eksperymentów, zmieniając hiperparametry, zakres nadzoru i stosując różne architektury modeli.