
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | | |
Обзор
Это обзоры ноутбуков классифицируют кино как положительные или отрицательные , используя текст обзора. Это пример бинарной классификации, является важным и широко применимого родом проблем машинного обучения.
В этой записной книжке мы продемонстрируем использование регуляризации графа, построив граф из заданных входных данных. Общий рецепт построения модели с регуляризацией графа с использованием структуры нейронного структурированного обучения (NSL), когда входные данные не содержат явного графа, выглядит следующим образом:
- Создайте вложения для каждого образца текста во входных данных. Это может быть сделано с помощью заранее подготовленных моделей , таких как word2vec , вертлюг , БЕРТ и т.д.
- Постройте граф на основе этих вложений, используя метрику подобия, такую как расстояние «L2», расстояние «косинус» и т. Д. Узлы в графе соответствуют выборкам, а ребра в графе соответствуют подобию между парами выборок.
- Сгенерируйте обучающие данные из синтезированного выше графика и примеров функций. Результирующие обучающие данные будут содержать соседние функции в дополнение к исходным характеристикам узлов.
- Создайте нейронную сеть в качестве базовой модели с помощью последовательного, функционального или подклассового API Keras.
- Оберните базовую модель классом-оболочкой GraphRegularization, который предоставляется фреймворком NSL, чтобы создать новую модель графа Keras. Эта новая модель будет включать потерю регуляризации графа в качестве члена регуляризации в цели обучения.
- Обучите и оцените модель графа Кераса.
Требования
- Установите пакет нейронного структурированного обучения.
- Установите tenorflow-hub.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
Зависимости и импорт
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Набор данных IMDB
IMDB набор данных содержит текст 50000 обзоры фильмов из базы данных Internet Movie . Они разделены на 25 000 обзоров для обучения и 25 000 обзоров для тестирования. Тренировочные и контрольные наборы сбалансированы, то есть они содержат одинаковое количество положительных и отрицательных отзывов.
В этом руководстве мы будем использовать предварительно обработанную версию набора данных IMDB.
Скачать предварительно обработанный набор данных IMDB
Набор данных IMDB поставляется в комплекте с TensorFlow. Он уже был предварительно обработан, так что обзоры (последовательности слов) были преобразованы в последовательности целых чисел, где каждое целое число представляет определенное слово в словаре.
Следующий код загружает набор данных IMDB (или использует кэшированную копию, если она уже была загружена):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
Аргумент num_words=10000 сохраняет верхние 10000 наиболее часто встречающихся слов в обучающих данных. Редкие слова отбрасываются, чтобы объем словарного запаса оставался управляемым.
Изучите данные
Давайте потратим время, чтобы понять формат данных. Набор данных предварительно обработан: каждый пример представляет собой массив целых чисел, представляющих слова из обзора фильма. Каждая метка представляет собой целое число 0 или 1, где 0 - отрицательный отзыв, а 1 - положительный отзыв.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
Текст отзывов был преобразован в целые числа, где каждое целое число представляет собой определенное слово в словаре. Вот как выглядит первый обзор:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
Рецензии на фильмы могут быть разной длины. В приведенном ниже коде показано количество слов в первом и втором обзоре. Поскольку входные данные нейронной сети должны быть одинаковой длины, нам нужно будет решить эту проблему позже.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
Преобразуйте целые числа обратно в слова
Может быть полезно узнать, как преобразовать целые числа обратно в соответствующий текст. Здесь мы создадим вспомогательную функцию для запроса объекта словаря, который содержит преобразование целого числа в строку:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
Теперь мы можем использовать decode_review функцию для отображения текста для первого обзора:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
Построение графа
Построение графа включает создание вложений для образцов текста, а затем использование функции подобия для сравнения вложений.
Прежде чем продолжить, мы сначала создаем каталог для хранения артефактов, созданных в этом руководстве.
mkdir -p /tmp/imdb
Создать образцы встраиваний
Мы будем использовать pretrained вложения шарнирного создавать вложения в tf.train.Example формате для каждого образца на входе. Мы будем хранить полученные вложения в TFRecord формате вместе с дополнительной функцией , которая представляет собой идентификатор каждого образца. Это важно и позволит нам позже сопоставить образцы вложения с соответствующими узлами в графе.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
Построить график
Теперь, когда у нас есть образцы вложения, мы будем использовать их для построения графа подобия, то есть узлы в этом графе будут соответствовать образцам, а ребра в этом графе будут соответствовать подобию между парами узлов.
Neural Structured Learning предоставляет библиотеку построения графиков для построения графиков на основе примеров внедрения. Он использует косинус сходства в качестве меры подобия для сравнения вложений и построение ребер между ними. Это также позволяет нам указать порог подобия, который можно использовать, чтобы отбросить несходные ребра из окончательного графа. В этом примере, используя 0,99 в качестве порога сходства и 12345 в качестве случайного начального числа, мы получаем граф, который имеет 429 415 двунаправленных ребер. Здесь мы используем поддержку графа строителя для местности чувствительного хеширования (LSH) , чтобы ускорить график строительства. Для получения дополнительной информации об использовании поддержки LSH графа строителя см build_graph_from_config документации по API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
Каждое двунаправленное ребро представлено двумя направленными ребрами в выходном файле TSV, так что этот файл содержит 429 415 * 2 = 858 830 строк:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
Примеры функций
Мы создаем образцы функции для нашей задачи , используя tf.train.Example формат и сохраняются их в TFRecord формате. Каждый образец будет включать следующие три функции:
- ID: Узел Идентификатор образца.
- слова: перечисляет int64 содержащих идентификаторы слов.
- метка: одноплодная int64 определения целевого класса обзора.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
Дополните обучающие данные соседями по графу
Поскольку у нас есть образцы функций и синтезированный график, мы можем сгенерировать расширенные обучающие данные для нейронно-структурированного обучения. Инфраструктура NSL предоставляет библиотеку для объединения графа и примеров функций для получения окончательных обучающих данных для регуляризации графа. Результирующие обучающие данные будут включать исходные образцы функций, а также характеристики их соответствующих соседей.
В этом руководстве мы рассматриваем неориентированные ребра и используем максимум 3 соседа на выборку, чтобы дополнить обучающие данные соседями графа.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
Базовая модель
Теперь мы готовы построить базовую модель без регуляризации графа. Чтобы построить эту модель, мы можем либо использовать вложения, которые использовались при построении графа, либо мы можем изучить новые вложения вместе с задачей классификации. В рамках этой записной книжки мы сделаем последнее.
Глобальные переменные
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
Гиперпараметры
Мы будем использовать экземпляр HParams для inclue различных гиперпараметров и констант , используемые для обучения и оценки. Кратко опишем каждый из них ниже:
num_classes: Есть 2 класса - положительные и отрицательные.
max_seq_length: Это максимальное количество слов , рассматриваемых в каждом обзоре фильма в этом примере.
vocab_size: Это размер словаря рассматривается в данном примере.
distance_type: Это расстояние показателя , используемое для упорядочения образца с его соседями.
graph_regularization_multiplier: Это контролирует относительный вес термина график регуляризации в общей функции потерь.
num_neighbors: Число соседей , используемых для графа регуляризации. Это значение должно быть меньше , чем или равен
max_nbrsаргумента , используемого выше , при вызовеnsl.tools.pack_nbrs.num_fc_units: Количество единиц в полностью подключенном слое нейронной сети.
train_epochs: Количество тренировочных эпох.
Размер Пакетное используется для обучения и оценки: batch_size.
eval_steps: Количество партий в процесс , прежде чем оценка сочтя завершено. Если установлено значение
None, все экземпляры в тестовом наборе оцениваются.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
Подготовьте данные
Обзоры - массивы целых чисел - должны быть преобразованы в тензоры перед подачей в нейронную сеть. Это преобразование можно выполнить двумя способами:
Преобразование массивов в векторы
0с и1с указанием вхождения слова, похожее на один горячее кодирование. Например, последовательность[3, 5]станет10000- мерным вектором, все нули для индексов , за исключением3-х и5, которые из них. Затем сделать это первый слой в нашей сети-аDenseслой-который может обрабатывать с плавающей точкой векторных данных. Такой подход является большим объемом памяти, однако, требуетnum_words * num_reviewsматрицы размера.С другой стороны , мы можем подушечка массивы , таким образом они все имеют одинаковую длину, а затем создать целое тензор формы
max_length * num_reviews. Мы можем использовать слой внедрения, способный обрабатывать эту форму, как первый слой в нашей сети.
В этом уроке мы будем использовать второй подход.
Поскольку обзоры фильмов должны быть одинаковой длиной, мы будем использовать pad_sequence функцию , определенную ниже , чтобы стандартизировать длины.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
Построить модель
Нейронная сеть создается путем наложения слоев - это требует двух основных архитектурных решений:
- Сколько слоев использовать в модели?
- Сколько скрытых блоков использовать для каждого слоя?
В этом примере входные данные состоят из массива индексов слов. Метки для прогнозирования: 0 или 1.
Мы будем использовать двунаправленный LSTM в качестве нашей базовой модели в этом руководстве.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
Слои эффективно складываются последовательно для построения классификатора:
- Первый слой представляет собой
Inputслой , который принимает целое число в кодировке словаря. - Следующий слой представляет собой
Embeddingслой, который принимает целое число в кодировке словаря и ищет вложение вектора для каждого слова-индекса. Эти векторы изучаются по мере обучения модели. Векторы добавляют измерение к выходному массиву. Полученные размеры:(batch, sequence, embedding). - Затем двунаправленный уровень LSTM возвращает выходной вектор фиксированной длины для каждого примера.
- Этот выходной вектор фиксированной длины по трубопроводу через полностью подключено (
Denseслой) с 64 скрытых блоками. - Последний слой плотно связан с единственным выходным узлом. Использование
sigmoidфункции активации, это значение с плавающей точкой в диапазоне от 0 до 1, представляющей вероятности, или уровень достоверности.
Скрытые юниты
Выше модель имеет два промежуточных или «скрытых» слоев, между входом и выходом, а также за исключением Embedding слоя. Количество выходов (единиц, узлов или нейронов) - это размерность репрезентативного пространства для слоя. Другими словами, степень свободы, которую дает сеть при изучении внутреннего представления.
Если модель имеет больше скрытых единиц (пространство представления более высокой размерности) и / или более слоев, тогда сеть может изучить более сложные представления. Однако это делает сеть более затратной с точки зрения вычислений и может привести к изучению нежелательных шаблонов - шаблонов, которые улучшают производительность на обучающих данных, но не на тестовых данных. Это называется переобучение.
Функция потерь и оптимизатор
Модель нуждается в функции потерь и оптимизаторе для обучения. Так как это бинарная проблема классификации и модель выхода вероятности (один блок-слой с сигмовидной активацией), мы будем использовать binary_crossentropy функции потерь.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Создать набор для проверки
Во время обучения мы хотим проверить точность модели на данных, которых она раньше не видела. Создать набор проверки, установив обособленно часть исходных данных обучения. (Почему бы не использовать набор для тестирования сейчас? Наша цель - разработать и настроить нашу модель, используя только обучающие данные, а затем использовать тестовые данные только один раз, чтобы оценить нашу точность).
В этом руководстве мы берем примерно 10% исходных обучающих выборок (10% от 25000) как помеченные данные для обучения, а оставшиеся - как данные проверки. Поскольку начальное разделение поездов / тестов составляло 50/50 (по 25000 образцов каждый), эффективное разделение поездов / проверок / тестов, которое у нас сейчас есть, составляет 5/45/50.
Обратите внимание, что «train_dataset» уже был перемешан и перемешан.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
Обучите модель
Обучайте модель мини-сериями. Во время обучения следите за потерями и точностью модели на проверочном наборе:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
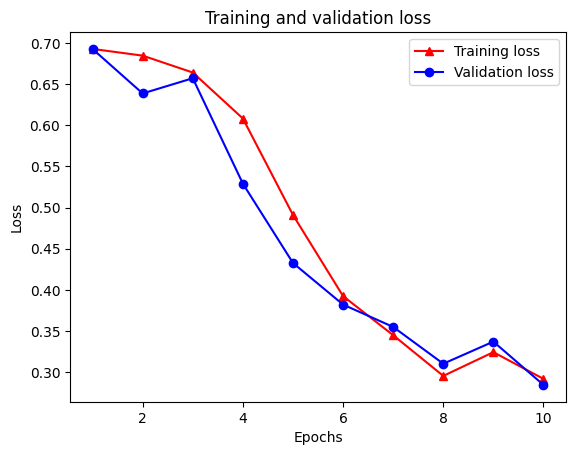
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
Оцените модель
Теперь посмотрим, как работает модель. Будут возвращены два значения. Потеря (число, которое представляет нашу ошибку, меньшие значения лучше) и точность.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
Создайте график точности / потерь с течением времени
model.fit() возвращает History объект , который содержит словарь со всем , что произошло во время тренировки:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Есть четыре записи: по одной для каждой отслеживаемой метрики во время обучения и проверки. Мы можем использовать их для построения графика потерь при обучении и проверке для сравнения, а также для оценки точности обучения и проверки:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
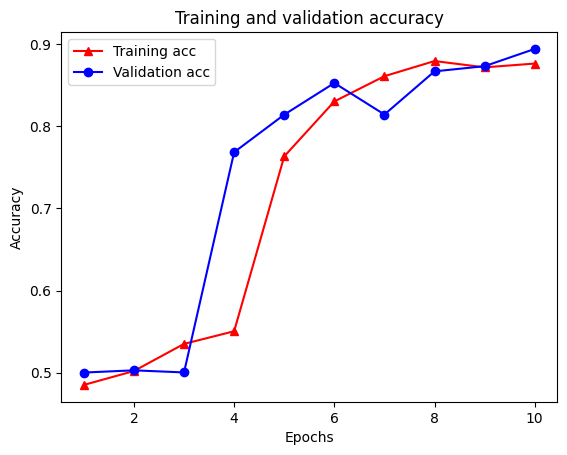
Обратите внимание , что потеря обучения уменьшается с каждой эпохой и обучение точности возрастает с каждой эпохой. Это ожидается при использовании оптимизации градиентного спуска - она должна минимизировать желаемое количество на каждой итерации.
Регуляризация графа
Теперь мы готовы попробовать регуляризацию графа, используя базовую модель, которую мы построили выше. Мы будем использовать GraphRegularization класса - оболочку , представленный Neural структурированной основой обучения обернуть модель (би-LSTM) основания для включения графа упорядочению. Остальные шаги для обучения и оценки модели с регуляризацией графа аналогичны шагам базовой модели.
Создать модель с регуляризацией графа
Чтобы оценить дополнительные преимущества регуляризации графа, мы создадим новый экземпляр базовой модели. Это потому , что model уже подготовлена несколько итераций, и повторное использование этой обученная модели , чтобы создать граф-регуляризованная модель не будет сравнением справедлива для model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Обучите модель
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
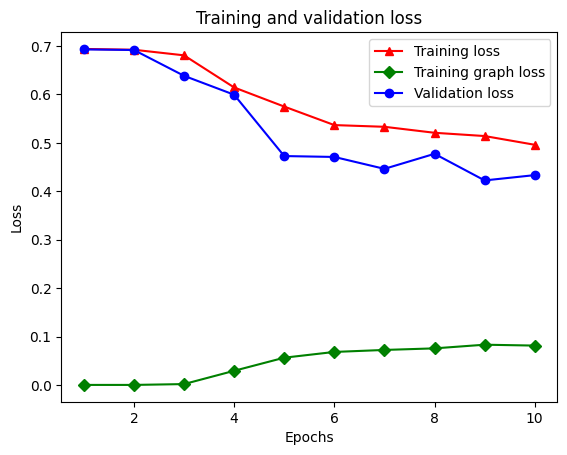
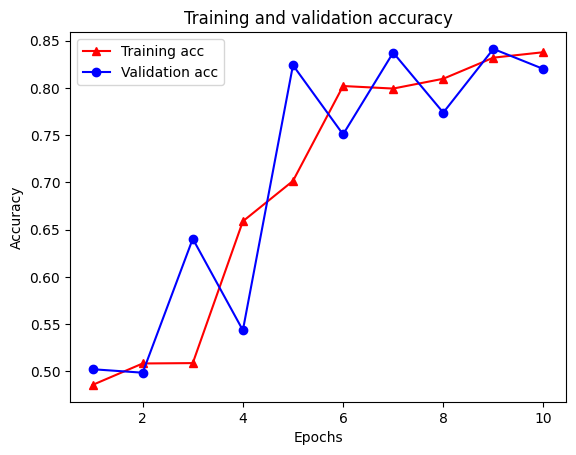
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
Оцените модель
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
Создайте график точности / потерь с течением времени
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
Всего в словаре пять записей: потеря обучения, точность обучения, потеря графа обучения, потеря проверки и точность проверки. Мы можем построить их все вместе для сравнения. Обратите внимание, что потеря графика вычисляется только во время обучения.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
Возможности обучения без учителя
Полу-контролируемое обучение и, в частности, регуляризация графиков в контексте этого руководства, могут быть действительно эффективными, когда объем обучающих данных невелик. Отсутствие обучающих данных компенсируется за счет использования сходства обучающих выборок, что невозможно при традиционном обучении с учителем.
Определим отношение надзора как отношение подготовки образцов к общему числу образцов , которые включает в себя подготовку, проверку и тестовые образцы. В этом блокноте мы использовали коэффициент наблюдения 0,05 (т. Е. 5% помеченных данных) для обучения как базовой модели, так и модели с регуляризацией графа. Мы проиллюстрируем влияние коэффициента наблюдения на точность модели в ячейке ниже.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
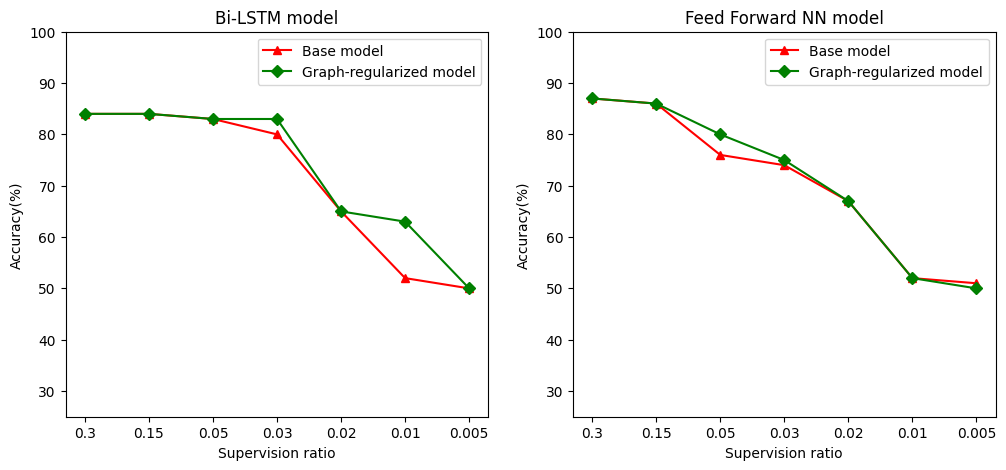
Можно заметить, что по мере уменьшения коэффициента контроля точность модели также снижается. Это верно как для базовой модели, так и для модели с регуляризацией графов, независимо от используемой архитектуры модели. Однако обратите внимание, что модель с регуляризацией графа работает лучше, чем базовая модель для обеих архитектур. В частности, для модели би-LSTM, когда отношение надзора составляет 0,01, точность графа-регуляризованный модели составляет ~ 20% выше , чем у базовой модели. Это в первую очередь из-за частично контролируемого обучения для модели с регуляризацией графов, где структурное сходство между обучающими выборками используется в дополнение к самим обучающим выборкам.
Вывод
Мы продемонстрировали использование регуляризации графа с помощью структуры нейронного структурированного обучения (NSL), даже если входные данные не содержат явного графа. Мы рассмотрели задачу тональной классификации обзоров фильмов IMDB, для которых синтезировали граф сходства на основе вложения обзоров. Мы поощряем пользователей к дальнейшим экспериментам, варьируя гиперпараметры, объем надзора и используя разные архитектуры моделей.