
|
|
|
 View source on GitHub View source on GitHub
|
|
In this example you will explore the result of McClean, 2019 that says not just any quantum neural network structure will do well when it comes to learning. In particular you will see that a certain large family of random quantum circuits do not serve as good quantum neural networks, because they have gradients that vanish almost everywhere. In this example you won't be training any models for a specific learning problem, but instead focusing on the simpler problem of understanding the behaviors of gradients.
Setup
Install TensorFlow and TensorFlow Quantum:
# In Colab, you will be asked to restart the session after this finishes.pip install tensorflow==2.18.1 tensorflow-quantum==0.7.6
Configure the use of Keras 2:
import os
# Keras 2 must be selected before importing TensorFlow or TensorFlow Quantum:
os.environ["TF_USE_LEGACY_KERAS"] = "1"
Now import TensorFlow, TensorFlow Quantum, and other modules needed:
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2026-04-18 07:39:57.648943: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered WARNING: All log messages before absl::InitializeLog() is called are written to STDERR E0000 00:00:1776512397.670505 20513 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered E0000 00:00:1776512397.677155 20513 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered 2026-04-18 07:40:02.222593: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:152] failed call to cuInit: INTERNAL: CUDA error: Failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. Summary
Random quantum circuits with many blocks that look like this (\(R_{P}(\theta)\) is a random Pauli rotation):
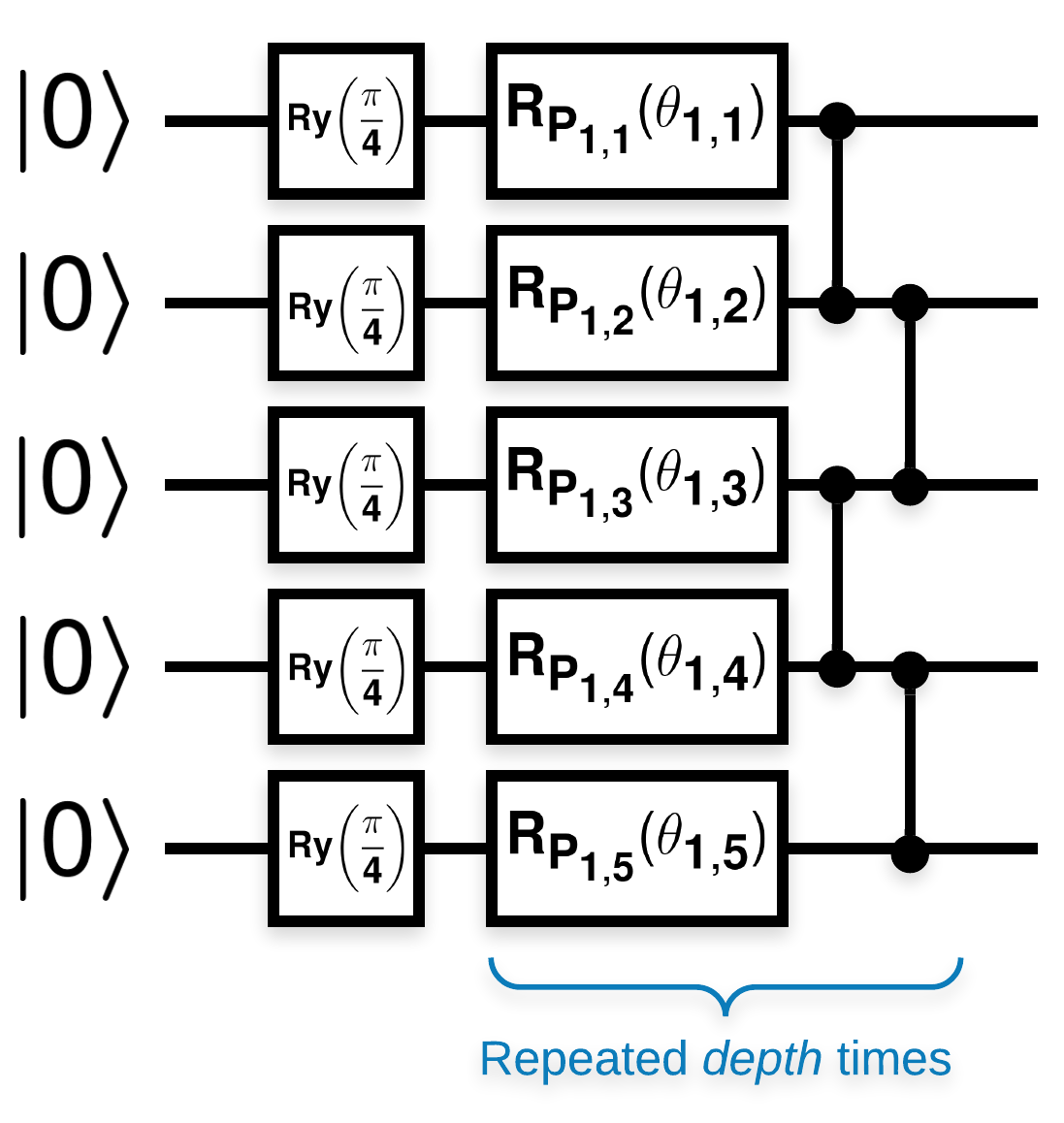
Where if \(f(x)\) is defined as the expectation value w.r.t. \(Z_{a}Z_{b}\) for any qubits \(a\) and \(b\), then there is a problem that \(f'(x)\) has a mean very close to 0 and does not vary much. You will see this below:
2. Generating random circuits
The construction from the paper is straightforward to follow. The following implements a simple function that generates a random quantum circuit—sometimes referred to as a quantum neural network (QNN)—with the given depth on a set of qubits:
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
The authors investigate the gradient of a single parameter \(\theta_{1,1}\). Let's follow along by placing a sympy.Symbol in the circuit where \(\theta_{1,1}\) would be. Since the authors do not analyze the statistics for any other symbols in the circuit, let's replace them with random values now instead of later.
3. Running the circuits
Generate a few of these circuits along with an observable to test the claim that the gradients don't vary much. First, generate a batch of random circuits. Choose a random ZZ observable and batch calculate the gradients and variance using TensorFlow Quantum.
3.1 Batch variance computation
Let's write a helper function that computes the variance of the gradient of a given observable over a batch of circuits:
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 Set up and run
Choose the number of random circuits to generate along with their depth and the amount of qubits they should act on. Then plot the results.
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7fd7724039a0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
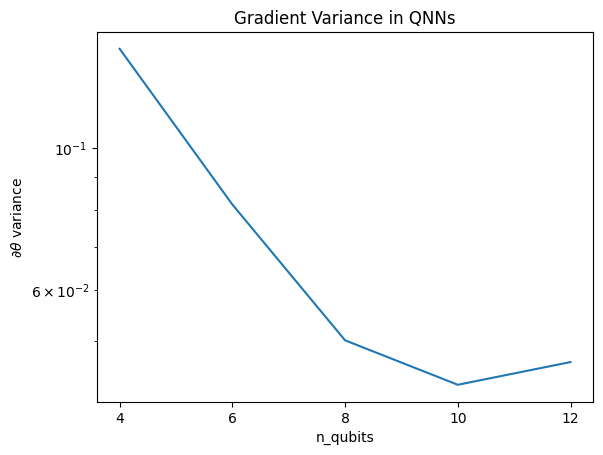
This plot shows that for quantum machine learning problems, you can't simply guess a random QNN ansatz and hope for the best. Some structure must be present in the model circuit in order for gradients to vary to the point where learning can happen.
4. Heuristics
An interesting heuristic by Grant, 2019 allows one to start very close to random, but not quite. Using the same circuits as McClean et al., the authors propose a different initialization technique for the classical control parameters to avoid barren plateaus. The initialization technique starts some layers with totally random control parameters—but, in the layers immediately following, choose parameters such that the initial transformation made by the first few layers is undone. The authors call this an identity block.
The advantage of this heuristic is that by changing just a single parameter, all other blocks outside of the current block will remain the identity—and the gradient signal comes through much stronger than before. This allows the user to pick and choose which variables and blocks to modify to get a strong gradient signal. This heuristic does not prevent the user from falling in to a barren plateau during the training phase (and restricts a fully simultaneous update), it just guarantees that you can start outside of a plateau.
4.1 New QNN construction
Now construct a function to generate identity block QNNs. This implementation is slightly different than the one from the paper. For now, look at the behavior of the gradient of a single parameter so it is consistent with McClean et al, so some simplifications can be made.
To generate an identity block and train the model, generally you need \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) and not \(U1(\theta_1) U1(\theta_1)^{\dagger}\). Initially \(\theta_{1a}\) and \(\theta_{1b}\) are the same angles but they are learned independently. Otherwise, you will always get the identity even after training. The choice for the number of identity blocks is empirical. The deeper the block, the smaller the variance in the middle of the block. But at the start and end of the block, the variance of the parameter gradients should be large.
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 Comparison
Here you can see that the heuristic does help to keep the variance of the gradient from vanishing as quickly:
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7fd7724039a0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
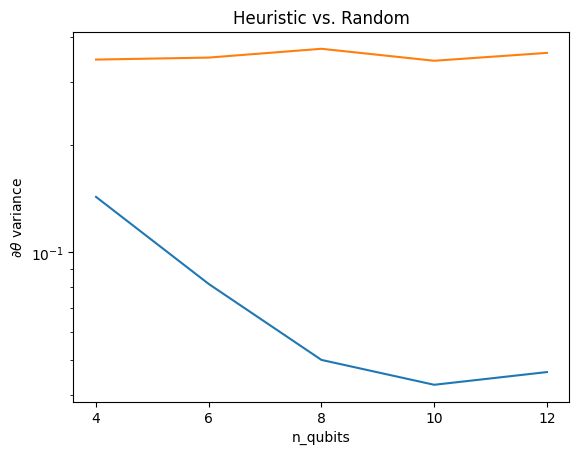
This is a great improvement in getting stronger gradient signals from (near) random QNNs.