
La biblioteca TensorFlow Ranking lo ayuda a crear aprendizaje escalable para clasificar modelos de aprendizaje automático utilizando enfoques y técnicas bien establecidos de investigaciones recientes. Un modelo de clasificación toma una lista de elementos similares, como páginas web, y genera una lista optimizada de esos elementos, por ejemplo, las páginas más relevantes a las menos relevantes. Aprender a clasificar los modelos tiene aplicaciones en la búsqueda, la respuesta a preguntas, los sistemas de recomendación y los sistemas de diálogo. Puede utilizar esta biblioteca para acelerar la creación de un modelo de clasificación para su aplicación mediante la API de Keras . La biblioteca de clasificación también proporciona utilidades de flujo de trabajo para facilitar la ampliación de la implementación de su modelo para trabajar de manera efectiva con grandes conjuntos de datos utilizando estrategias de procesamiento distribuido.
Esta descripción general proporciona un breve resumen del desarrollo del aprendizaje para clasificar modelos con esta biblioteca, presenta algunas técnicas avanzadas admitidas por la biblioteca y analiza las utilidades de flujo de trabajo proporcionadas para admitir el procesamiento distribuido para clasificar aplicaciones.
Desarrollo del aprendizaje para clasificar modelos
La construcción de un modelo con la biblioteca TensorFlow Ranking sigue estos pasos generales:
- Especifique una función de puntuación usando capas de Keras (
tf.keras.layers) - Defina las métricas que desea utilizar para la evaluación, como
tfr.keras.metrics.NDCGMetric - Especifique una función de pérdida, como
tfr.keras.losses.SoftmaxLoss - Compile el modelo con
tf.keras.Model.compile()y entrénelo con sus datos
El tutorial Recomendar películas lo guía a través de los conceptos básicos para crear un modelo de aprendizaje para clasificar con esta biblioteca. Consulte la sección Soporte de clasificación distribuida para obtener más información sobre la creación de modelos de clasificación a gran escala.
Técnicas de clasificación avanzadas
La biblioteca TensorFlow Ranking brinda soporte para aplicar técnicas de clasificación avanzadas investigadas e implementadas por investigadores e ingenieros de Google. Las siguientes secciones brindan una descripción general de algunas de estas técnicas y cómo comenzar a usarlas en su aplicación.
Orden de entrada de la lista BERT
La biblioteca de clasificación proporciona una implementación de TFR-BERT, una arquitectura de puntuación que combina BERT con el modelado LTR para optimizar el orden de las entradas de la lista. Como ejemplo de aplicación de este enfoque, considere una consulta y una lista de n documentos que desea clasificar en respuesta a esta consulta. En lugar de aprender una representación BERT puntuada de forma independiente en pares de <query, document> , los modelos LTR aplican una pérdida de clasificación para aprender conjuntamente una representación BERT que maximiza la utilidad de toda la lista clasificada con respecto a las etiquetas de verdad en el terreno. La siguiente figura ilustra esta técnica:
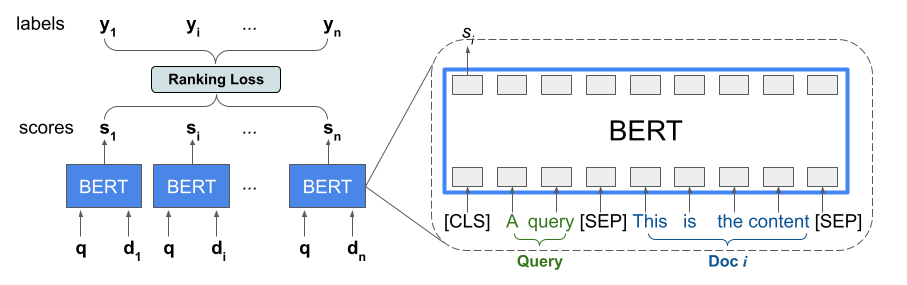
Este enfoque aplana una lista de documentos para clasificar en respuesta a una consulta en una lista de tuplas <query, document> . Estas tuplas luego se introducen en un modelo de lenguaje BERT previamente entrenado. Las salidas BERT agrupadas para la lista completa de documentos se ajustan conjuntamente con una de las pérdidas de clasificación especializadas disponibles en TensorFlow Ranking.
Esta arquitectura puede ofrecer mejoras significativas en el rendimiento del modelo de lenguaje previamente entrenado, produciendo un rendimiento de última generación para varias tareas de clasificación populares, especialmente cuando se combinan varios modelos de lenguaje previamente entrenados. Para obtener más información sobre esta técnica, consulte la investigación relacionada. Puede comenzar con una implementación simple en el código de ejemplo TensorFlow Ranking.
Modelos aditivos generalizados de clasificación neuronal (GAM)
Para algunos sistemas de clasificación, como la evaluación de la elegibilidad del préstamo, la orientación de la publicidad o la orientación para el tratamiento médico, la transparencia y la explicabilidad son consideraciones críticas. La aplicación de modelos aditivos generalizados (GAM) con factores de ponderación bien entendidos puede ayudar a que su modelo de clasificación sea más explicable e interpretable.
Los GAM se han estudiado ampliamente con tareas de clasificación y regresión, pero no está tan claro cómo aplicarlos a una aplicación de clasificación. Por ejemplo, mientras que los GAM se pueden aplicar simplemente para modelar cada elemento individual de la lista, modelar tanto las interacciones de los elementos como el contexto en el que se clasifican estos elementos es un problema más desafiante. TensorFlow Ranking proporciona una implementación de GAM de clasificación neuronal , una extensión de modelos aditivos generalizados diseñados para problemas de clasificación. La implementación de TensorFlow Ranking de GAM le permite agregar una ponderación específica a las características de su modelo.
La siguiente ilustración de un sistema de clasificación de hoteles utiliza la relevancia, el precio y la distancia como características principales de clasificación. Este modelo aplica una técnica GAM para sopesar estas dimensiones de manera diferente, según el contexto del dispositivo del usuario. Por ejemplo, si la consulta proviene de un teléfono, la distancia se pondera más, suponiendo que los usuarios buscan un hotel cercano.
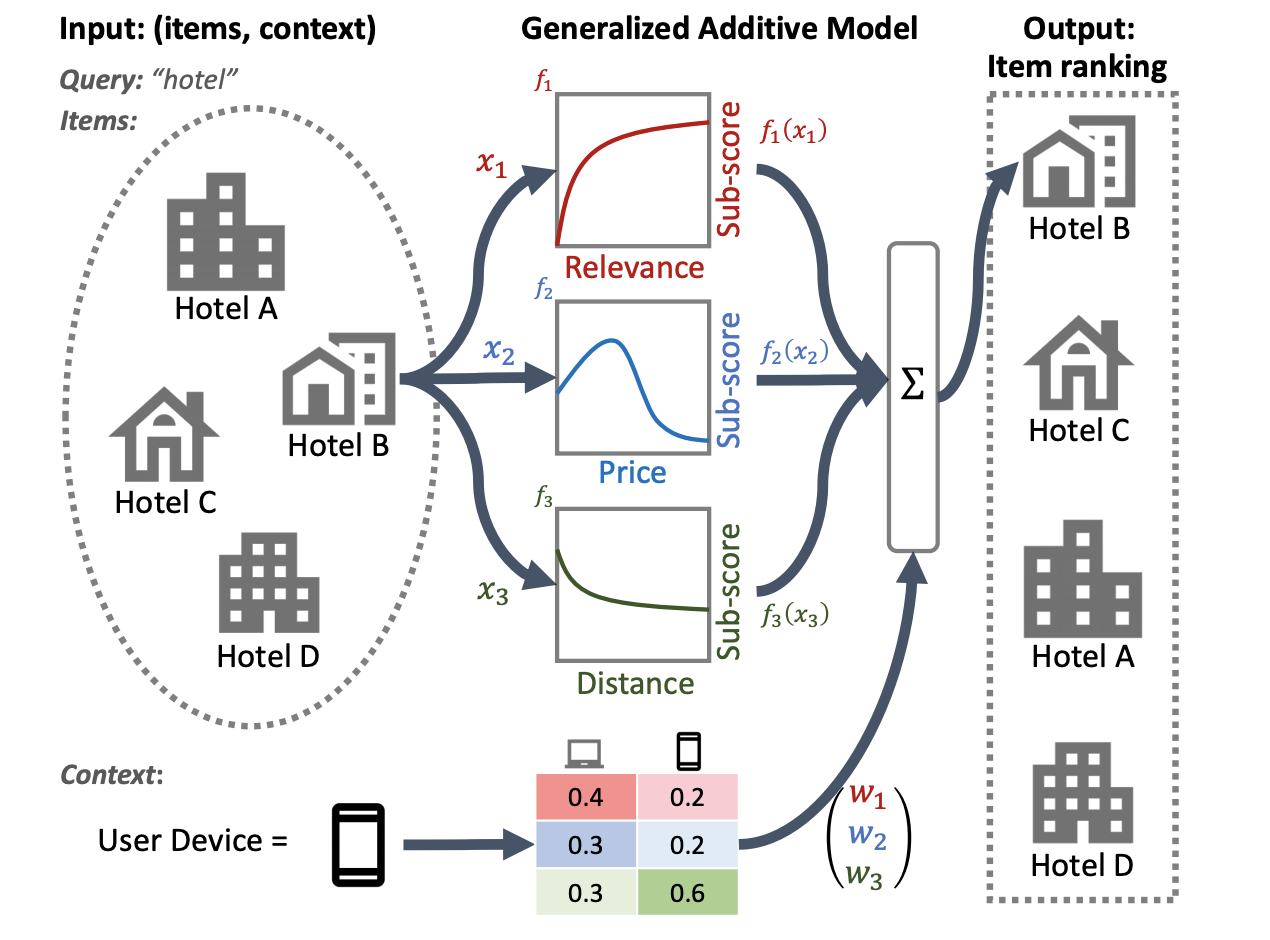
Para obtener más información sobre el uso de GAM con modelos de clasificación, consulte la investigación relacionada. Puede comenzar con una implementación de muestra de esta técnica en el código de ejemplo TensorFlow Ranking.
Soporte de clasificación distribuida
TensorFlow Ranking está diseñado para crear sistemas de clasificación a gran escala de principio a fin: incluido el procesamiento de datos, la creación de modelos, la evaluación y la implementación de producción. Puede manejar características dispersas y densas heterogéneas, escalar hasta millones de puntos de datos y está diseñado para admitir el entrenamiento distribuido para aplicaciones de clasificación a gran escala.
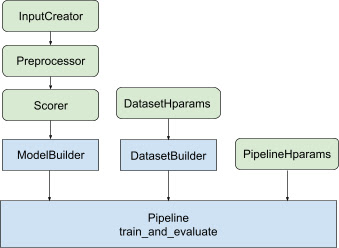
La biblioteca proporciona una arquitectura de tubería de clasificación optimizada, para evitar el código repetitivo y repetitivo y crear soluciones distribuidas que se pueden aplicar desde entrenar su modelo de clasificación hasta servirlo. La tubería de clasificación es compatible con la mayoría de las estrategias distribuidas de TensorFlow, incluidas MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy y ParameterServerStrategy . La canalización de clasificación puede exportar el modelo de clasificación entrenado en el formato tf.saved_model , que admite varias firmas de entrada . operaciones de entrenamiento.
La biblioteca de clasificación ayuda a crear una implementación de capacitación distribuida al proporcionar un conjunto de clases tfr.keras.pipeline , que toman como entrada un generador de modelos, un generador de datos e hiperparámetros. La clase tfr.keras.ModelBuilder basada en Keras le permite crear un modelo para el procesamiento distribuido y funciona con clases extensibles InputCreator, Preprocessor y Scorer:
Las clases de canalización de TensorFlow Ranking también funcionan con un DatasetBuilder para configurar datos de entrenamiento, que pueden incorporar hiperparámetros . Finalmente, la propia canalización puede incluir un conjunto de hiperparámetros como un objeto PipelineHparams .
Comience a crear modelos de clasificación distribuidos con el tutorial de clasificación distribuida .
,La biblioteca TensorFlow Ranking lo ayuda a crear aprendizaje escalable para clasificar modelos de aprendizaje automático utilizando enfoques y técnicas bien establecidos de investigaciones recientes. Un modelo de clasificación toma una lista de elementos similares, como páginas web, y genera una lista optimizada de esos elementos, por ejemplo, las páginas más relevantes a las menos relevantes. Aprender a clasificar los modelos tiene aplicaciones en la búsqueda, la respuesta a preguntas, los sistemas de recomendación y los sistemas de diálogo. Puede utilizar esta biblioteca para acelerar la creación de un modelo de clasificación para su aplicación mediante la API de Keras . La biblioteca de clasificación también proporciona utilidades de flujo de trabajo para facilitar la ampliación de la implementación de su modelo para trabajar de manera efectiva con grandes conjuntos de datos utilizando estrategias de procesamiento distribuido.
Esta descripción general proporciona un breve resumen del desarrollo del aprendizaje para clasificar modelos con esta biblioteca, presenta algunas técnicas avanzadas admitidas por la biblioteca y analiza las utilidades de flujo de trabajo proporcionadas para admitir el procesamiento distribuido para clasificar aplicaciones.
Desarrollo del aprendizaje para clasificar modelos
La construcción de un modelo con la biblioteca TensorFlow Ranking sigue estos pasos generales:
- Especifique una función de puntuación usando capas de Keras (
tf.keras.layers) - Defina las métricas que desea utilizar para la evaluación, como
tfr.keras.metrics.NDCGMetric - Especifique una función de pérdida, como
tfr.keras.losses.SoftmaxLoss - Compile el modelo con
tf.keras.Model.compile()y entrénelo con sus datos
El tutorial Recomendar películas lo guía a través de los conceptos básicos para crear un modelo de aprendizaje para clasificar con esta biblioteca. Consulte la sección Soporte de clasificación distribuida para obtener más información sobre la creación de modelos de clasificación a gran escala.
Técnicas de clasificación avanzadas
La biblioteca TensorFlow Ranking brinda soporte para aplicar técnicas de clasificación avanzadas investigadas e implementadas por investigadores e ingenieros de Google. Las siguientes secciones brindan una descripción general de algunas de estas técnicas y cómo comenzar a usarlas en su aplicación.
Orden de entrada de la lista BERT
La biblioteca de clasificación proporciona una implementación de TFR-BERT, una arquitectura de puntuación que combina BERT con el modelado LTR para optimizar el orden de las entradas de la lista. Como ejemplo de aplicación de este enfoque, considere una consulta y una lista de n documentos que desea clasificar en respuesta a esta consulta. En lugar de aprender una representación BERT puntuada de forma independiente en pares de <query, document> , los modelos LTR aplican una pérdida de clasificación para aprender conjuntamente una representación BERT que maximiza la utilidad de toda la lista clasificada con respecto a las etiquetas de verdad en el terreno. La siguiente figura ilustra esta técnica:
Este enfoque aplana una lista de documentos para clasificar en respuesta a una consulta en una lista de tuplas <query, document> . Estas tuplas luego se introducen en un modelo de lenguaje BERT previamente entrenado. Las salidas BERT agrupadas para la lista completa de documentos se ajustan conjuntamente con una de las pérdidas de clasificación especializadas disponibles en TensorFlow Ranking.
Esta arquitectura puede ofrecer mejoras significativas en el rendimiento del modelo de lenguaje previamente entrenado, produciendo un rendimiento de última generación para varias tareas de clasificación populares, especialmente cuando se combinan varios modelos de lenguaje previamente entrenados. Para obtener más información sobre esta técnica, consulte la investigación relacionada. Puede comenzar con una implementación simple en el código de ejemplo TensorFlow Ranking.
Modelos aditivos generalizados de clasificación neuronal (GAM)
Para algunos sistemas de clasificación, como la evaluación de la elegibilidad del préstamo, la orientación de la publicidad o la orientación para el tratamiento médico, la transparencia y la explicabilidad son consideraciones críticas. La aplicación de modelos aditivos generalizados (GAM) con factores de ponderación bien entendidos puede ayudar a que su modelo de clasificación sea más explicable e interpretable.
Los GAM se han estudiado ampliamente con tareas de clasificación y regresión, pero no está tan claro cómo aplicarlos a una aplicación de clasificación. Por ejemplo, mientras que los GAM se pueden aplicar simplemente para modelar cada elemento individual de la lista, modelar tanto las interacciones de los elementos como el contexto en el que se clasifican estos elementos es un problema más desafiante. TensorFlow Ranking proporciona una implementación de GAM de clasificación neuronal , una extensión de modelos aditivos generalizados diseñados para problemas de clasificación. La implementación de TensorFlow Ranking de GAM le permite agregar una ponderación específica a las características de su modelo.
La siguiente ilustración de un sistema de clasificación de hoteles utiliza la relevancia, el precio y la distancia como características principales de clasificación. Este modelo aplica una técnica GAM para sopesar estas dimensiones de manera diferente, según el contexto del dispositivo del usuario. Por ejemplo, si la consulta proviene de un teléfono, la distancia se pondera más, suponiendo que los usuarios buscan un hotel cercano.
Para obtener más información sobre el uso de GAM con modelos de clasificación, consulte la investigación relacionada. Puede comenzar con una implementación de muestra de esta técnica en el código de ejemplo TensorFlow Ranking.
Soporte de clasificación distribuida
TensorFlow Ranking está diseñado para crear sistemas de clasificación a gran escala de principio a fin: incluido el procesamiento de datos, la creación de modelos, la evaluación y la implementación de producción. Puede manejar características dispersas y densas heterogéneas, escalar hasta millones de puntos de datos y está diseñado para admitir el entrenamiento distribuido para aplicaciones de clasificación a gran escala.
La biblioteca proporciona una arquitectura de tubería de clasificación optimizada, para evitar el código repetitivo y repetitivo y crear soluciones distribuidas que se pueden aplicar desde entrenar su modelo de clasificación hasta servirlo. La tubería de clasificación es compatible con la mayoría de las estrategias distribuidas de TensorFlow, incluidas MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy y ParameterServerStrategy . La canalización de clasificación puede exportar el modelo de clasificación entrenado en el formato tf.saved_model , que admite varias firmas de entrada . operaciones de entrenamiento.
La biblioteca de clasificación ayuda a crear una implementación de capacitación distribuida al proporcionar un conjunto de clases tfr.keras.pipeline , que toman como entrada un generador de modelos, un generador de datos e hiperparámetros. La clase tfr.keras.ModelBuilder basada en Keras le permite crear un modelo para el procesamiento distribuido y funciona con clases extensibles InputCreator, Preprocessor y Scorer:
Las clases de canalización de TensorFlow Ranking también funcionan con un DatasetBuilder para configurar datos de entrenamiento, que pueden incorporar hiperparámetros . Finalmente, la propia canalización puede incluir un conjunto de hiperparámetros como un objeto PipelineHparams .
Comience a crear modelos de clasificación distribuidos con el tutorial de clasificación distribuida .