
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial demuestra cómo utilizar Deep & Cross Network (DCN) para aprender eficazmente los cruces de funciones.
Fondo
¿Qué son los cruces de características y por qué son importantes? Imagínese que estamos construyendo un sistema de recomendación para vender una licuadora a los clientes. Entonces, más allá de la historia de compra de un cliente como purchased_bananas y purchased_cooking_books o características geográficas, son características individuales. Si uno ha comprado dos plátanos y libros de cocina, a continuación, este cliente más probable que haga clic en la licuadora recomendada. La combinación de purchased_bananas y purchased_cooking_books se conoce como una cruz característica, que proporciona información de interacción adicional más allá de las características individuales.
¿Cuáles son los desafíos en el aprendizaje de los cruces de características? En las aplicaciones a escala web, los datos son en su mayoría categóricos, lo que genera un espacio de características grande y escaso. La identificación de cruces de características efectivas en esta configuración a menudo requiere ingeniería de características manual o una búsqueda exhaustiva. Los modelos tradicionales de perceptrón multicapa de retroalimentación (MLP) son aproximadores de funciones universales; sin embargo, no pueden aproximarse de manera eficiente incluso 2º o 3º orden cruces de funciones [ 1 , 2 ].
¿Qué es Deep & Cross Network (DCN)? DCN fue diseñado para aprender características cruzadas explícitas y de grados delimitados de manera más efectiva. Se inicia con una capa de entrada (típicamente una capa de incrustación), seguido por una red transversal que contiene múltiples capas cruzadas que las interacciones modelos explícitos de función y luego se combina con una red profunda que los modelos de interacciones entre características implícitas.
- Red cruzada. Este es el núcleo de DCN. Aplica explícitamente el cruce de entidades en cada capa y el grado de polinomio más alto aumenta con la profundidad de la capa. La siguiente figura muestra la \((i+1)\)-ésima capa cruzada.
- Red profunda. Es un perceptrón multicapa de feedforward tradicional (MLP).
Se combinan entonces la red profunda y la red de cruz para formar DCN [ 1 ]. Normalmente, podríamos apilar una red profunda encima de la red cruzada (estructura apilada); también podríamos colocarlos en paralelo (estructura paralela).
A continuación, primero mostraremos la ventaja de DCN con un ejemplo de juguete, y luego lo guiaremos a través de algunas formas comunes de utilizar DCN utilizando el conjunto de datos MovieLen-1M.
Primero instalemos e importemos los paquetes necesarios para este colab.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
Ejemplo de juguete
Para ilustrar los beneficios de DCN, trabajemos con un ejemplo simple. Supongamos que tenemos un conjunto de datos en el que intentamos modelar la probabilidad de que un cliente haga clic en un anuncio de Blender, con sus características y etiqueta descritas a continuación.
| Características / Etiqueta | Descripción | Tipo / rango de valor |
|---|---|---|
| \(x_1\) = país | el país en el que vive este cliente | Int en [0, 199] |
| \(x_2\) = plátanos | # plátanos que el cliente ha comprado | Int en [0, 23] |
| \(x_3\) = libros de cocina | # libros de cocina que el cliente ha comprado | Int en [0, 5] |
| \(y\) | la probabilidad de hacer clic en un anuncio de Blender | - |
Luego, dejamos que los datos sigan la siguiente distribución subyacente:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
donde la probabilidad \(y\) depende linealmente tanto en las características \(x_i\)'s, sino también sobre las interacciones entre el multiplicativos \(x_i\)' s. En nuestro caso, podríamos decir que la probabilidad de adquirir una licuadora (\(y\)) depende no sólo de la compra de plátanos (\(x_2\)) o libros de cocina (\(x_3\)), sino también en la compra de plátanos y libros de cocina juntos (\(x_2x_3\)).
Podemos generar los datos para esto de la siguiente manera:
Generación de datos sintéticos
Primero definimos \(f(x_1, x_2, x_3)\) como se describió anteriormente.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
Generemos los datos que siguen la distribución y dividamos los datos en 90% para entrenamiento y 10% para pruebas.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
Construcción del modelo
Vamos a probar tanto la red cruzada como la red profunda para ilustrar la ventaja que una red cruzada puede brindar a los recomendadores. Como los datos que acabamos de crear solo contienen interacciones de características de segundo orden, sería suficiente ilustrarlo con una red cruzada de una sola capa. Si quisiéramos modelar interacciones de características de orden superior, podríamos apilar múltiples capas cruzadas y usar una red cruzada de múltiples capas. Los dos modelos que estaremos construyendo son:
- Red cruzada con una sola capa cruzada;
- Deep Network con capas ReLU más amplias y profundas.
Primero construimos una clase de modelo unificada cuya pérdida es el error cuadrático medio.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
Luego, especificamos la red cruzada (con 1 capa cruzada de tamaño 3) y el DNN basado en ReLU (con tamaños de capa [512, 256, 128]):
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
Entrenamiento de modelos
Ahora que tenemos los datos y los modelos listos, vamos a entrenar los modelos. Primero mezclamos y agrupamos los datos para prepararlos para el entrenamiento del modelo.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
Luego, definimos el número de épocas y la tasa de aprendizaje.
epochs = 100
learning_rate = 0.4
Muy bien, todo está listo ahora y compilemos y entrenemos los modelos. También podemos establecer verbose=True si desea ver cómo los avances modelo.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
Evaluación del modelo
Verificamos el rendimiento del modelo en el conjunto de datos de evaluación e informamos el error cuadrático medio de la raíz (RMSE, cuanto menor, mejor).
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
Vemos que la red de la Cruz magnitudes permiten reducir el RMSE de un DNN basada en RELU, con magnitudes menos parámetros. Esto ha sugerido la eficiencia de una red cruzada en el aprendizaje de cruces de características.
Comprensión del modelo
Ya sabemos qué características cruzadas son importantes en nuestros datos, sería divertido comprobar si nuestro modelo realmente ha aprendido la característica cruzada importante. Esto se puede hacer visualizando la matriz de peso aprendida en DCN. El peso \(W_{ij}\) representa la importancia aprendido de interacción entre característica \(x_i\) y \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
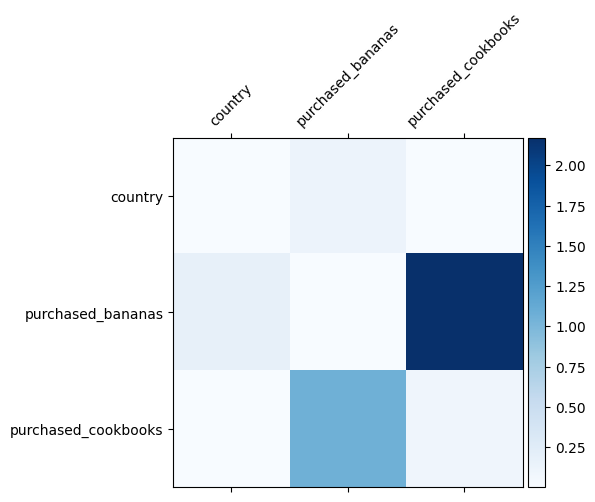
Los colores más oscuros representan interacciones aprendidas más fuertes; en este caso, está claro que el modelo aprendió que comprar babanas y libros de cocina juntos es importante.
Si está interesado en probar datos sintéticos más complicado, no dude en revisar este documento .
Ejemplo de Movielens 1M
A continuación se examina la eficacia de la DCN en un conjunto de datos del mundo real: Movielens 1 M [ 3 ]. Movielens 1M es un conjunto de datos popular para la investigación de recomendaciones. Predice las calificaciones de películas de los usuarios dadas las características relacionadas con el usuario y las características relacionadas con la película. Usamos este conjunto de datos para demostrar algunas formas comunes de utilizar DCN.
Procesamiento de datos
El procedimiento de procesamiento de datos sigue un procedimiento similar como el tutorial clasificación básica .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
A continuación, dividimos aleatoriamente los datos en 80% para entrenamiento y 20% para pruebas.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
Luego, creamos vocabulario para cada característica.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
Construcción del modelo
La arquitectura del modelo que construiremos comienza con una capa de incrustación, que se alimenta a una red cruzada seguida de una red profunda. La dimensión de incrustación se establece en 32 para todas las funciones. También puede usar diferentes tamaños de incrustación para diferentes funciones.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
Entrenamiento de modelos
Mezclamos, agrupamos y almacenamos en caché los datos de entrenamiento y prueba.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
Definamos una función que ejecute un modelo varias veces y devuelva la media de RMSE y la desviación estándar del modelo a partir de múltiples ejecuciones.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
Establecemos algunos hiperparámetros para los modelos. Tenga en cuenta que estos hiperparámetros se establecen globalmente para todos los modelos con fines de demostración. Si desea obtener el mejor rendimiento para cada modelo o realizar una comparación justa entre modelos, le sugerimos que ajuste los hiperparámetros. Recuerde que la arquitectura del modelo y los esquemas de optimización están entrelazados.
epochs = 8
learning_rate = 0.01
DCN (apilado). Primero entrenamos un modelo DCN con una estructura apilada, es decir, las entradas se alimentan a una red cruzada seguida de una red profunda.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
DCN de rango bajo. Para reducir el costo de capacitación y servicio, aprovechamos técnicas de bajo rango para aproximar las matrices de peso de DCN. El rango se pasa a través de argumentos projection_dim ; una más pequeña projection_dim resulta en un costo más bajo. Tenga en cuenta que projection_dim necesita ser más pequeño que (tamaño de la entrada) / 2 para reducir el costo. En la práctica, hemos observado que el uso de DCN de rango bajo con rango (tamaño de entrada) / 4 conservó de manera consistente la precisión de un DCN de rango completo.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. Entrenamos un modelo DNN del mismo tamaño como referencia.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
Evaluamos el modelo con datos de prueba e informamos la desviación estándar y media de 5 ejecuciones.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
Vemos que DCN logró un mejor rendimiento que un DNN del mismo tamaño con capas ReLU. Además, el DCN de rango bajo pudo reducir los parámetros manteniendo la precisión.
Más sobre DCN. Además żQué ha demostrado anteriormente, sin embargo, hay maneras más creativas útiles en la práctica de utilizar DCN [ 1 ].
DCN con una estructura paralela. Las entradas se alimentan en paralelo a una red cruzada y una red profunda.
Concatenación de capas cruzadas. Las entradas se alimentan en paralelo a múltiples capas cruzadas para capturar cruces de características complementarias.
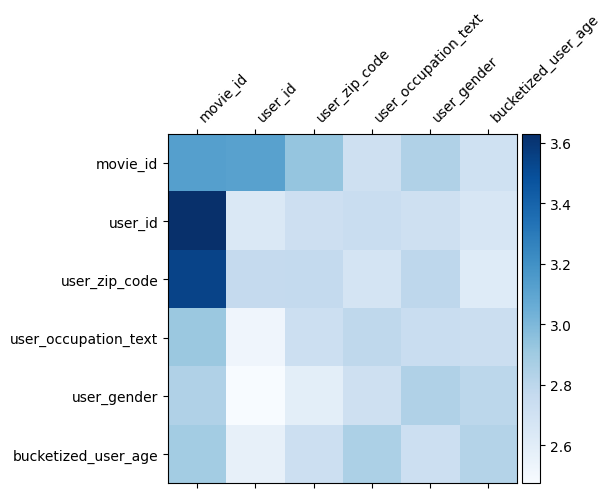
Comprensión del modelo
La matriz de pesos \(W\) en DCN revela lo cruza función del modelo ha aprendido a ser importante. Recordemos que en el ejemplo de juguete anterior, la importancia de las interacciones entre la \(i\)-ésimo y \(j\)-ésimo cuenta es capturado por el (\(i, j\)) elemento -ésimo de \(W\).
¿Qué es un poco diferente aquí es que las inclusiones de características son de tamaño 32 en lugar del tamaño 1. Por lo tanto, la importancia se caracterizan por la \((i, j)\)ésimo bloque\(W_{i,j}\) que es de dimensión de 32 por 32. En lo que sigue, visualizar la norma de Frobenius [ 4 ] \(||W_{i,j}||_F\) de cada bloque, y una norma más grande sugerirían mayor importancia (suponiendo incrustaciones las características son de escalas similares).
Además de la norma de bloque, también podríamos visualizar la matriz completa, o el valor medio / mediano / máximo de cada bloque.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
¡Eso es todo por esta colab! Esperamos que haya disfrutado aprendiendo algunos conceptos básicos de DCN y formas comunes de utilizarlo. Si usted está interesado en aprender más, se puede consultar dos documentos relevantes: DCN-v1-papel , DCN-v2-papel .
Referencias
DCN V2: Mejora de Deep & Cross Red y Lecciones prácticas para el Aprendizaje escala Web para clasificar los sistemas .
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, Ed Chi. (2020)
De profundidad y de la cruz de red para Predicciones clic en el anuncio .
Ruoxi Wang, Bin Fu, Gang Fu, Mingliang Wang. (AdKDD 2017)