
| |  GitHubでソースを表示 GitHubでソースを表示 | |
このチュートリアルでは、Deep&Cross Network(DCN)を使用して機能のクロスを効果的に学習する方法を示します。
バックグラウンド
機能クロスとは何ですか?なぜそれらが重要なのですか?ブレンダーを顧客に販売するためのレコメンダーシステムを構築していると想像してみてください。その後、のような顧客の過去の購買履歴purchased_bananasとpurchased_cooking_books 、または地理的特徴は、単一機能です。 1は、バナナやクッキングブックの両方を購入した場合、この顧客は、より多くの可能性が高い推奨ブレンダーをクリックします。組み合わせpurchased_bananasとpurchased_cooking_books個々の機能を超えて追加の相互作用情報を提供する機能クロスと呼ばれています。
特徴の交差を学習する際の課題は何ですか? Webスケールのアプリケーションでは、データはほとんどがカテゴリであり、大きくてまばらな特徴空間になります。この設定で効果的な特徴交差を特定するには、多くの場合、手動の特徴エンジニアリングまたは徹底的な検索が必要です。従来のフィードフォワード多層パーセプトロン(MLP)モデルは、普遍関数近似器です。しかしながら、それらは効率的であっても2または3次特徴交雑[近づけることができない1 、 2 ]。
Deep&Cross Network(DCN)とは何ですか? DCNは、明示的で有界のクロスフィーチャをより効果的に学習するように設計されています。これは、複数の断面層を含む相互ネットワーク続い入力層(典型的には、埋め込み層)、で始まること深いネットワークとその後モデル明示的な特徴との相互作用、及びコンバインモデル暗黙の機能競合こと。
- クロスネットワーク。これがDCNのコアです。これは、各レイヤーでフィーチャクロスを明示的に適用し、最高の多項式次数はレイヤーの深さとともに増加します。次の図に示す \((i+1)\)クロス層目。
- ディープネットワーク。これは、従来のフィードフォワード多層パーセプトロン(MLP)です。
深いネットワークと相互ネットワークは、次に、DCN【形成するために結合される1 ]。通常、クロスネットワーク(スタック構造)の上に深いネットワークをスタックできます。それらを並列に配置することもできます(並列構造)。
以下では、最初におもちゃの例でDCNの利点を示し、次にMovieLen-1Mデータセットを使用してDCNを利用するいくつかの一般的な方法を説明します。
まず、このコラボに必要なパッケージをインストールしてインポートしましょう。
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
おもちゃの例
DCNの利点を説明するために、簡単な例を見てみましょう。顧客がブレンダー広告をクリックする可能性をモデル化しようとしているデータセットがあり、その機能とラベルは次のように記述されているとします。
| 機能/ラベル | 説明 | 値のタイプ/範囲 |
|---|---|---|
| \(x_1\) =国 | この顧客が住んでいる国 | [0、199]の整数 |
| \(x_2\) =バナナ | #顧客が購入したバナナ | [0、23]の整数 |
| \(x_3\) =料理 | #顧客が購入した料理本 | [0、5]の整数 |
| \(y\) | ブレンダー広告をクリックする可能性 | - |
次に、データを次の基本的な分布に従うようにします。
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
どこ尤度 \(y\) 両方の機能に直線的に依存 \(x_i\)さん、もの間乗法の相互作用の \(x_i\)s 'を。私たちのケースでは、我々は、ブレンダー(購入の可能性と言うでしょう\(y\))バナナ(買い上だけでなく、依存\(x_2\))または料理(\(x_3\)()、だけでなく、一緒にバナナと料理本を買いに\(x_2x_3\))。
このためのデータは次のように生成できます。
合成データの生成
まず定義 \(f(x_1, x_2, x_3)\) 上記のように。
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
分布に従うデータを生成し、データをトレーニング用に90%、テスト用に10%に分割してみましょう。
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
モデル構築
クロスネットワークとディープネットワークの両方を試して、クロスネットワークが推奨者にもたらす利点を説明します。作成したデータには2次の特徴の相互作用しか含まれていないため、単層のクロスネットワークで説明するだけで十分です。高次の機能の相互作用をモデル化する場合は、複数のクロスレイヤーをスタックし、マルチレイヤーのクロスネットワークを使用できます。構築する2つのモデルは次のとおりです。
- クロスレイヤーが1つしかないクロスネットワーク。
- より広く、より深いReLUレイヤーを備えたディープネットワーク。
最初に、損失が平均二乗誤差である統合モデルクラスを構築します。
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
次に、クロスネットワーク(サイズ3のクロスレイヤーが1つ)とReLUベースのDNN(レイヤーサイズ[512、256、128])を指定します。
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
モデルトレーニング
データとモデルの準備ができたので、モデルをトレーニングします。まず、データをシャッフルしてバッチ処理し、モデルトレーニングの準備をします。
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
次に、エポック数と学習率を定義します。
epochs = 100
learning_rate = 0.4
これですべての準備が整いました。モデルをコンパイルしてトレーニングしましょう。あなたは、設定することができverbose=Trueあなたはどのようにモデルの進行を確認したい場合。
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
モデル評価
評価データセットでモデルのパフォーマンスを検証し、二乗平均平方根誤差(RMSE、低いほど良い)を報告します。
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
我々は、クロスネットワークの大きさ、より少ないパラメータで、ReLUベースDNNより大き低いRMSEを達成していることがわかり。これは、機能クロスの学習におけるクロスネットワークの効率を示唆しています。
モデルの理解
データでどの特徴の交差が重要であるかはすでにわかっています。モデルが実際に重要な特徴の交差を学習したかどうかを確認するのは楽しいでしょう。これは、DCNで学習した重み行列を視覚化することで実行できます。重量 \(W_{ij}\) フィーチャ間の相互作用の重要性を学んだ表し \(x_i\) と \(x_j\)。
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
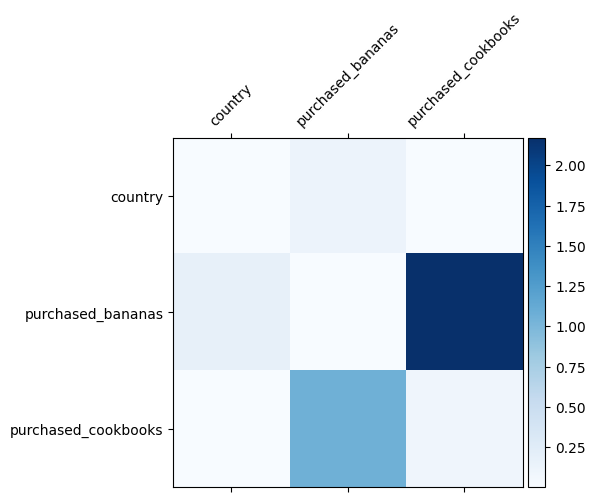
色が濃いほど、学習した相互作用が強くなります。この場合、モデルがババナと料理本を一緒に購入することが重要であることを学習したことは明らかです。
あなたがより複雑な合成データを試すことに興味がある場合は、チェックアウトしてお気軽にこの論文を。
Movielens1Mの例
私たちは今、実世界のデータセットでDCNの有効性を調べる:Movielens 1M [ 3 ]。 Movielens 1Mは、推奨研究のための人気のあるデータセットです。ユーザー関連の機能と映画関連の機能を指定して、ユーザーの映画のレーティングを予測します。このデータセットを使用して、DCNを利用するいくつかの一般的な方法を示します。
情報処理
データ処理手順は、同様の手順を、以下の基本的なランキングのチュートリアル。
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
次に、データをランダムにトレーニング用に80%、テスト用に20%に分割します。
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
次に、各機能の語彙を作成します。
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
モデル構築
構築するモデルアーキテクチャは、埋め込みレイヤーから始まります。埋め込みレイヤーは、クロスネットワークに供給され、その後にディープネットワークが続きます。埋め込みサイズは、すべての機能で32に設定されています。機能ごとに異なる埋め込みサイズを使用することもできます。
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
モデルトレーニング
トレーニングデータとテストデータをシャッフル、バッチ処理、キャッシュします。
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
モデルを複数回実行し、複数の実行からモデルのRMSE平均と標準偏差を返す関数を定義しましょう。
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
モデルにいくつかのハイパーパラメータを設定します。これらのハイパーパラメータは、デモンストレーションの目的ですべてのモデルに対してグローバルに設定されていることに注意してください。各モデルで最高のパフォーマンスを得る場合、またはモデル間で公正な比較を行う場合は、ハイパーパラメーターを微調整することをお勧めします。モデルアーキテクチャと最適化スキームが絡み合っていることを忘れないでください。
epochs = 8
learning_rate = 0.01
DCN(スタック)。最初に、スタック構造のDCNモデルをトレーニングします。つまり、入力はクロスネットワークに送られ、続いてディープネットワークに送られます。
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
低ランクのDCN。トレーニングとサービングのコストを削減するために、低ランクの手法を利用してDCN重み行列を近似します。ランクは、引数を介して渡されprojection_dim 。小さなprojection_dim低コストでの結果。そのノートprojection_dimニーズがコストを削減する(入力サイズ)/ 2よりも小さくします。実際には、ランク(入力サイズ)/ 4の低ランクDCNを使用すると、フルランクDCNの精度が一貫して維持されることがわかりました。
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN。参照として同じサイズのDNNモデルをトレーニングします。
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
テストデータでモデルを評価し、5回の実行からの平均と標準偏差を報告します。
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
DCNは、ReLUレイヤーを備えた同じサイズのDNNよりも優れたパフォーマンスを達成したことがわかります。さらに、低ランクのDCNは、精度を維持しながらパラメータを削減することができました。
DCNの詳細。上記実証されwhat'veほか、DCN [利用するより創造まだ実用的な方法がある1 ]。
並列構造を有するDCN。入力は、クロスネットワークとディープネットワークに並列に供給されます。
クロスレイヤーの連結。入力は、補完的なフィーチャクロスをキャプチャするために、複数のクロスレイヤーに並列に供給されます。
モデルの理解
重み行列 \(W\) DCNにおける機能は、モデルが重要であることを学んだ横切るものを明らかにする。リコールとの間の相互作用の前玩具例において、重要その \(i\)番目と \(j\)(によって捕捉される番目の特徴\(i, j\)の)番目の要素 \(W\)。
何ここでビット異なるのは、特徴埋め込みが故に代わりサイズ1からサイズ32である、重要度によって特徴付けられるであろうということである \((i, j)\)番目のブロック\(W_{i,j}\) 我々は、以下32によって寸法32であります[フロベニウスノルムを可視化4 ] \(||W_{i,j}||_F\) 各ブロックのを、より大きなノルム(フィーチャの埋め込みが類似尺度であると仮定して)より高い重要性を示唆しています。
ブロックノルムに加えて、マトリックス全体、または各ブロックの平均/中央値/最大値を視覚化することもできます。
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
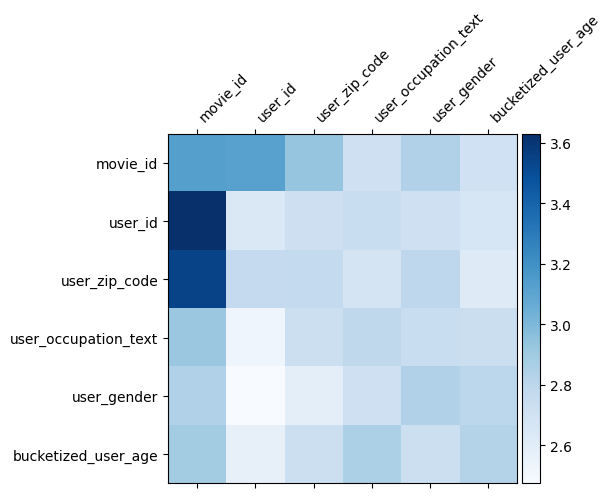
このコラボは以上です。 DCNのいくつかの基本と、DCNを利用する一般的な方法を楽しんでいただけたことを願っています。 :あなたはもっと学ぶことに興味を持っている場合は、2枚の関連する書類チェックアウトすることができDCN-V1-紙、 DCN-V2-紙を。
参考文献
DCN V2:改善されたディープ&クロスネットワークとランクシステムにWebスケールの学習のための実用的なレッスン。
Ruoxi Wang、Rakesh Shivanna、Derek Zhiyuan Cheng、Sagar Jain、Dong Lin、Lichan Hong、Ed Chi (2020)
広告クリックの予測のためのディープ&クロスネットワーク。
Ruoxi Wang、Bin Fu、Gang Fu、Mingliang Wang (AdKDD 2017)