
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Dans le featurization tutoriel nous avons intégré plusieurs fonctionnalités dans nos modèles, mais les modèles se composent de seulement une couche d' enrobage. Nous pouvons ajouter des couches plus denses à nos modèles pour augmenter leur puissance expressive.
En général, les modèles plus profonds sont capables d'apprendre des modèles plus complexes que les modèles moins profonds. Par exemple, notre modèle utilisateur intègre ids utilisateur et horodatages aux préférences utilisateur modèle à un moment. Un modèle superficiel (par exemple, une seule couche d'intégration) peut n'être capable d'apprendre que les relations les plus simples entre ces fonctionnalités et les films : un film donné est le plus populaire au moment de sa sortie, et un utilisateur donné préfère généralement les films d'horreur aux comédies. Pour capturer des relations plus complexes, telles que les préférences des utilisateurs évoluant au fil du temps, nous pouvons avoir besoin d'un modèle plus profond avec plusieurs couches denses empilées.
Bien entendu, les modèles complexes ont aussi leurs inconvénients. Le premier est le coût de calcul, car les modèles plus grands nécessitent à la fois plus de mémoire et plus de calculs pour s'adapter et servir. Le second est le besoin de plus de données : en général, plus de données d'entraînement sont nécessaires pour tirer parti de modèles plus profonds. Avec plus de paramètres, les modèles profonds peuvent surdimensionner ou même simplement mémoriser les exemples d'entraînement au lieu d'apprendre une fonction qui peut généraliser. Enfin, la formation de modèles plus profonds peut être plus difficile, et il faut être plus prudent dans le choix de paramètres tels que la régularisation et le taux d'apprentissage.
Trouver une bonne architecture pour un système de recommender monde réel est un art complexe, nécessitant une bonne intuition et minutieuse mise au point de hyperparam'etre . Par exemple, des facteurs tels que la profondeur et la largeur du modèle, la fonction d'activation, le taux d'apprentissage et l'optimiseur peuvent changer radicalement les performances du modèle. Les choix de modélisation sont encore compliqués par le fait que de bonnes métriques d'évaluation hors ligne peuvent ne pas correspondre à de bonnes performances en ligne, et que le choix des éléments à optimiser est souvent plus critique que le choix du modèle lui-même.
Néanmoins, les efforts déployés pour construire et affiner des modèles plus grands portent souvent leurs fruits. Dans ce didacticiel, nous allons illustrer comment créer des modèles de récupération approfondie à l'aide des recommandateurs TensorFlow. Pour ce faire, nous allons créer des modèles de plus en plus complexes pour voir comment cela affecte les performances du modèle.
Préliminaires
Nous importons d'abord les packages nécessaires.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
Dans ce tutoriel , nous utiliserons les modèles à partir du tutoriel featurization pour générer incorporations. Par conséquent, nous n'utiliserons que les fonctionnalités d'ID utilisateur, d'horodatage et de titre de film.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Nous faisons également du ménage pour préparer les vocabulaires des fonctionnalités.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
Définition du modèle
Modèle de requête
Nous commençons par le modèle défini par l' utilisateur dans le tutoriel featurization que la première couche de notre modèle, chargé de convertir des exemples d'entrée brutes en fonctionnalités incorporations.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
La définition de modèles plus profonds nous obligera à empiler des couches de mode au-dessus de cette première entrée. Un empilement de couches progressivement plus étroit, séparé par une fonction d'activation, est un modèle courant :
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
Étant donné que le pouvoir expressif des modèles linéaires profonds n'est pas supérieur à celui des modèles linéaires peu profonds, nous utilisons des activations ReLU pour tout sauf la dernière couche cachée. La couche cachée finale n'utilise aucune fonction d'activation : l'utilisation d'une fonction d'activation limiterait l'espace de sortie des plongements finaux et pourrait avoir un impact négatif sur les performances du modèle. Par exemple, si des ReLU sont utilisées dans la couche de projection, tous les composants de l'intégration de sortie seraient non négatifs.
Nous allons essayer quelque chose de similaire ici. Pour faciliter l'expérimentation avec différentes profondeurs, définissons un modèle dont la profondeur (et la largeur) est définie par un ensemble de paramètres de constructeur.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
Le layer_sizes paramètre nous donne la profondeur et la largeur du modèle. Nous pouvons le faire varier pour expérimenter avec des modèles moins profonds ou plus profonds.
Modèle candidat
Nous pouvons adopter la même approche pour le modèle du film. Encore une fois, nous commençons par le MovieModel du featurization tutoriel:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
Et développez-le avec des calques cachés :
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
Modèle combiné
Avec les deux QueryModel et CandidateModel définis, nous pouvons mettre en place un modèle combiné et mettre en œuvre notre logique de perte et de mesures. Pour simplifier les choses, nous allons imposer que la structure du modèle est la même dans les modèles de requête et candidats.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
Entraîner le modèle
Préparer les données
Nous avons d'abord divisé les données en un ensemble d'apprentissage et un ensemble de test.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
Modèle peu profond
Nous sommes prêts à essayer notre premier modèle peu profond !
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
Cela nous donne une précision du top 100 d'environ 0,27. Nous pouvons l'utiliser comme point de référence pour évaluer des modèles plus profonds.
Modèle plus profond
Qu'en est-il d'un modèle plus profond avec deux couches ?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
La précision ici est de 0,29, bien meilleure que le modèle peu profond.
Nous pouvons tracer les courbes de précision de validation pour illustrer ceci :
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
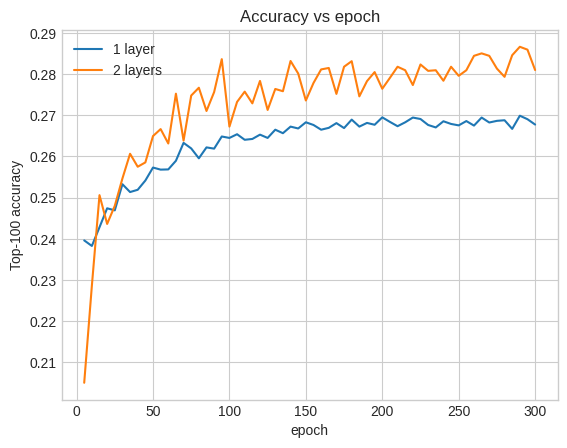
Même au début de la formation, le modèle plus grand a une avance claire et stable sur le modèle peu profond, ce qui suggère que l'ajout de profondeur aide le modèle à capturer des relations plus nuancées dans les données.
Cependant, des modèles encore plus profonds ne sont pas nécessairement meilleurs. Le modèle suivant étend la profondeur à trois couches :
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
En fait, nous ne voyons pas d'amélioration par rapport au modèle superficiel :
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
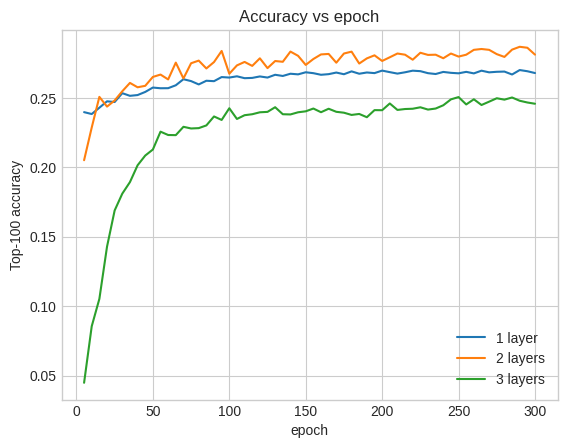
C'est une bonne illustration du fait que les modèles plus profonds et plus grands, bien que capables de performances supérieures, nécessitent souvent un réglage très minutieux. Par exemple, tout au long de ce didacticiel, nous avons utilisé un taux d'apprentissage unique et fixe. Des choix alternatifs peuvent donner des résultats très différents et méritent d'être explorés.
Avec un réglage approprié et des données suffisantes, l'effort consacré à la construction de modèles plus grands et plus profonds en vaut la peine dans de nombreux cas : des modèles plus grands peuvent conduire à des améliorations substantielles de la précision des prédictions.
Prochaines étapes
Dans ce didacticiel, nous avons étendu notre modèle de récupération avec des couches denses et des fonctions d'activation. Pour voir comment créer un modèle qui peut non seulement effectuer des tâches de récupération , mais également des tâches d' étoiles, jetez un oeil à ce tutoriel multitâches .