
| | |  GitHub でソースを表示 GitHub でソースを表示 |
このガイドでは、アヤメの花を種ごとに分類する機械学習モデルを構築することによって、TensorFlow 用の Swift を紹介します。 TensorFlow に Swift を使用して次のことを行います。
- モデルを構築し、
- このモデルをサンプル データでトレーニングし、
- モデルを使用して、未知のデータについて予測を行います。
TensorFlow プログラミング
このガイドでは、次の高レベルの Swift for TensorFlow 概念を使用します。
- Epochs API を使用してデータをインポートします。
- Swift 抽象化を使用してモデルを構築します。
- 純粋な Swift ライブラリが利用できない場合は、Swift の Python 相互運用性を使用して Python ライブラリを使用します。
このチュートリアルは、多くの TensorFlow プログラムと同じように構成されています。
- データセットをインポートして解析します。
- モデルのタイプを選択します。
- モデルをトレーニングします。
- モデルの有効性を評価します。
- トレーニングされたモデルを使用して予測を行います。
セットアッププログラム
インポートの構成
TensorFlow といくつかの便利な Python モジュールをインポートします。
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
アイリス分類問題
あなたが植物学者で、見つけた各アイリスの花を自動的に分類する方法を探していると想像してください。機械学習は、花を統計的に分類するための多くのアルゴリズムを提供します。たとえば、高度な機械学習プログラムは、写真に基づいて花を分類できます。私たちの野心はもっと控えめで、萼片と花弁の長さと幅の測定に基づいてアイリスの花を分類するつもりです。
アヤメ属には約 300 種が含まれますが、私たちのプログラムでは次の 3 種のみを分類します。
- アイリスセトサ
- アイリス・バージニカ
- アイリス癜風
 |
| 図 1. Iris setosa ( Radomil作成、CC BY-SA 3.0)、 Iris versicolor ( Dlanglois作成、CC BY-SA 3.0)、およびIris virginica ( Frank Mayfield作成、CC BY-SA 2.0)。 |
幸いなことに、誰かがすでに120 個のアイリスの花のがく片と花びらの測定値を含むデータセットを作成しています。これは、初心者の機械学習の分類問題に人気のある古典的なデータセットです。
トレーニング データセットをインポートして解析する
データセット ファイルをダウンロードし、この Swift プログラムで使用できる構造に変換します。
データセットをダウンロードする
http://download.tensorflow.org/data/iris_training.csvからトレーニング データセット ファイルをダウンロードします。
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
データを検査する
このデータセットiris_training.csvは、カンマ区切り値 (CSV) 形式の表形式のデータを保存するプレーン テキスト ファイルです。最初の 5 つのエントリを見てみましょう。
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
このデータセットのビューから、次のことに注目してください。
- 最初の行は、データセットに関する情報を含むヘッダーです。
- 合計 120 の例があります。各例には 4 つの機能と 3 つの可能なラベル名のうちの 1 つがあります。
- 後続の行はデータ レコードであり、1 行に 1 つの例が示されています。
それをコードに書き出してみましょう。
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
各ラベルは文字列名 (たとえば、「setosa」) に関連付けられていますが、機械学習は通常、数値に依存します。ラベル番号は、次のような名前付き表現にマップされます。
-
0:アイリスセトサ 1: アイリス癜風2:アイリス・バージニカ
機能とラベルの詳細については、 「 Machine Learning Crash Course 」の「ML Terminology」セクションを参照してください。
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Epochs API を使用してデータセットを作成する
Swift for TensorFlow の Epochs API は、データを読み取り、トレーニングに使用される形式に変換するための高レベル API です。
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
ダウンロードしたデータセットは CSV 形式であるため、データを IrisBatch オブジェクトのリストとして読み込む関数を作成しましょう
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
CSV 読み込み関数を使用してトレーニング データセットを読み込み、 TrainingEpochsオブジェクトを作成できるようになりました。
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
TrainingEpochsオブジェクトは、エポックの無限のシーケンスです。各エポックにはIrisBatch含まれます。最初のエポックの最初の要素を見てみましょう。
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
最初のbatchSizeの例の特徴がfirstTrainFeaturesにグループ化 (またはバッチ化) され、最初のbatchSizeサイズのサンプルのラベルがfirstTrainLabelsにバッチ化されていることに注意してください。
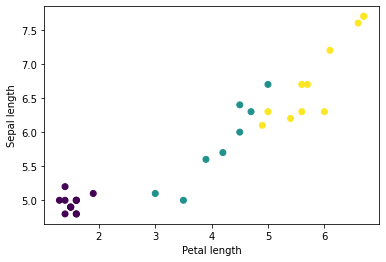
Python の matplotlib を使用して、バッチからいくつかの特徴をプロットすることで、いくつかのクラスターの確認を開始できます。
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
モデルのタイプを選択してください
なぜモデルなのか?
モデルは、フィーチャとラベルの間の関係です。アヤメの分類問題の場合、モデルはがく片および花弁の測定値と予測されるアヤメの種の間の関係を定義します。一部の単純なモデルは数行の代数で説明できますが、複雑な機械学習モデルには要約するのが難しい多数のパラメーターがあります。
機械学習を使用せずに、 4 つの特徴とアヤメの種類との関係を判断できますか?つまり、従来のプログラミング手法 (たとえば、多数の条件文) を使用してモデルを作成できるでしょうか?おそらく、特定の種に対する花弁とがく片の測定値との関係を判断できるほど十分に長くデータセットを分析した場合です。そして、より複雑なデータセットではこれは困難になり、おそらく不可能になります。優れた機械学習アプローチにより、モデルが決定されます。十分な代表的な例を適切な機械学習モデル タイプに入力すると、プログラムが関係を見つけ出します。
モデルを選択してください
トレーニングするモデルの種類を選択する必要があります。モデルには多くの種類があり、適切なモデルを選択するには経験が必要です。このチュートリアルでは、ニューラル ネットワークを使用して虹彩分類問題を解決します。ニューラル ネットワークは、特徴とラベルの間の複雑な関係を見つけることができます。これは高度に構造化されたグラフであり、1 つ以上の隠れ層に編成されています。各隠れ層は 1 つ以上のニューロンで構成されます。ニューラル ネットワークにはいくつかのカテゴリがあり、このプログラムは高密度または完全に接続されたニューラル ネットワークを使用します。つまり、ある層のニューロンは、前の層のすべてのニューロンから入力接続を受け取ります。たとえば、図 2 は、入力層、2 つの隠れ層、および出力層で構成される高密度ニューラル ネットワークを示しています。
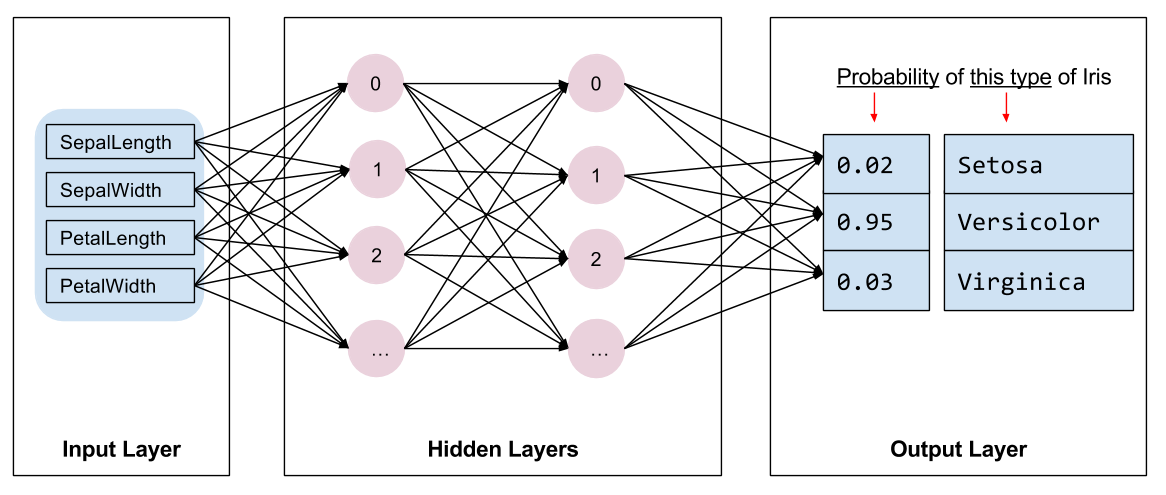 |
| 図 2.特徴、隠れ層、予測を備えたニューラル ネットワーク。 |
図 2 のモデルをトレーニングし、ラベルのない例を入力すると、この花が特定のアイリス種である可能性という 3 つの予測が得られます。この予測は推論と呼ばれます。この例では、出力予測の合計は 1.0 です。図 2 では、この予測の内訳は、 Iris setosaが0.02 、 Iris versicolorが0.95 、 Iris virginicaが0.03です。これは、ラベルのない例の花がIris versicolorであるとモデルが 95% の確率で予測することを意味します。
Swift for TensorFlow Deep Learning Library を使用してモデルを作成する
Swift for TensorFlow Deep Learning Library は、プリミティブ レイヤーとそれらを相互に接続するための規則を定義しているため、モデルの構築と実験が容易になります。
モデルはLayerに準拠するstructです。これは、入力Tensorを出力TensorにマップするcallAsFunction(_:)メソッドを定義することを意味します。 callAsFunction(_:)メソッドは、多くの場合、サブレイヤーを介して入力を単純にシーケンスします。 3 つのDenseサブレイヤを通じて入力をシーケンスするIrisModelを定義しましょう。
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
活性化関数は、層内の各ノードの出力形状を決定します。これらの非線形性は重要です。非線形性がなければ、モデルは単一層と同等になります。利用可能なアクティベーションは多数ありますが、隠れ層ではReLU が一般的です。
隠れ層とニューロンの理想的な数は、問題とデータセットによって異なります。機械学習の多くの側面と同様、ニューラル ネットワークの最適な形状を選択するには、知識と実験を組み合わせる必要があります。経験則として、隠れ層とニューロンの数を増やすと、通常、より強力なモデルが作成され、効果的にトレーニングするにはより多くのデータが必要になります。
モデルの使用
このモデルが一連の機能に対して何を行うかを簡単に見てみましょう。
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
ここで、各例は各クラスのロジットを返します。
これらのロジットをクラスごとの確率に変換するには、 softmax関数を使用します。
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
クラス全体でargmax取得すると、予測されたクラス インデックスが得られます。ただし、モデルはまだトレーニングされていないため、これらは適切な予測ではありません。
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
モデルをトレーニングする
トレーニングは、モデルが徐々に最適化されるか、モデルがデータセットを学習する機械学習の段階です。目標は、トレーニング データセットの構造について十分に学習して、目に見えないデータについて予測できるようにすることです。トレーニング データセットについて学びすぎると、予測はそれが見たデータに対してのみ機能し、一般化できなくなります。この問題は過学習と呼ばれます。これは、問題の解決方法を理解するのではなく、答えを暗記するようなものです。
アヤメの分類問題は教師あり機械学習の一例です。モデルはラベルを含む例からトレーニングされます。教師なし機械学習では、例にはラベルが含まれません。代わりに、モデルは通常、特徴間のパターンを見つけます。
損失関数を選択してください
トレーニング段階と評価段階の両方で、モデルの損失を計算する必要があります。これは、モデルの予測が目的のラベルからどの程度外れているか、つまりモデルのパフォーマンスがどの程度悪いかを測定します。この値を最小化または最適化したいと考えています。
私たちのモデルは、モデルのクラス確率予測と目的のラベルを取得し、サンプル全体の平均損失を返すsoftmaxCrossEntropy(logits:labels:)関数を使用して損失を計算します。
現在のトレーニングされていないモデルの損失を計算してみましょう。
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
オプティマイザーを作成する
オプティマイザーは、計算された勾配をモデルの変数に適用して、 loss関数を最小限に抑えます。損失関数は曲面と考えることができ (図 3 を参照)、歩き回ってその最低点を見つけます。勾配は最も急な登りの方向を向いているため、反対方向に移動して丘を下ります。各バッチの損失と勾配を繰り返し計算することで、トレーニング中にモデルを調整します。モデルは徐々に、損失を最小限に抑えるための重みとバイアスの最適な組み合わせを見つけます。そして、損失が低いほど、モデルの予測はより適切になります。
 |
| 図 3. 3D 空間で時間の経過とともに視覚化された最適化アルゴリズム。 (出典:スタンフォード クラス CS231n 、MIT ライセンス、画像クレジット: Alec Radford ) |
Swift for TensorFlow には、トレーニングに使用できる最適化アルゴリズムが多数あります。このモデルは、確率的勾配降下法(SGD) アルゴリズムを実装する SGD オプティマイザーを使用します。 learningRate坂を下る各反復に必要なステップ サイズを設定します。これは、より良い結果を得るために通常調整するハイパーパラメータです。
let optimizer = SGD(for: model, learningRate: 0.01)
optimizerを使用して単一の勾配降下ステップを実行してみましょう。まず、モデルに関する損失の勾配を計算します。
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
次に、計算したばかりの勾配をオプティマイザーに渡し、それに応じてモデルの微分可能変数を更新します。
optimizer.update(&model, along: grads)
損失を再度計算すると、勾配降下ステップによって (通常) 損失が減少するため、損失は小さくなるはずです。
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
トレーニングループ
すべての部品を配置したら、モデルをトレーニングする準備が整いました。トレーニング ループは、より適切な予測を行うためにデータセットの例をモデルにフィードします。次のコード ブロックは、これらのトレーニング ステップを設定します。
- 各エポックを反復します。エポックとは、データセットを通過する 1 回のパスです。
- エポック内で、トレーニング エポックの各バッチを反復処理します。
- バッチを照合し、その特徴(
x) とラベル(y) を取得します。 - 照合されたバッチの機能を使用して予測を行い、それをラベルと比較します。予測の不正確さを測定し、それを使用してモデルの損失と勾配を計算します。
- 勾配降下法を使用してモデルの変数を更新します。
- 視覚化のためにいくつかの統計を追跡します。
- エポックごとに繰り返します。
epochCount変数は、データセット コレクションをループする回数です。直感に反しますが、モデルをより長くトレーニングしても、より良いモデルが保証されるわけではありません。 epochCount調整できるハイパーパラメータです。適切な番号を選択するには、通常、経験と実験の両方が必要です。
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
時間の経過に伴う損失関数を視覚化する
モデルのトレーニングの進行状況を出力することは役に立ちますが、多くの場合、この進行状況を確認する方がより役立ちます。 Python のmatplotlibモジュールを使用して基本的なチャートを作成できます。
これらのチャートを解釈するにはある程度の経験が必要ですが、損失が減少し、精度が向上することを本当に確認したいと考えています。
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
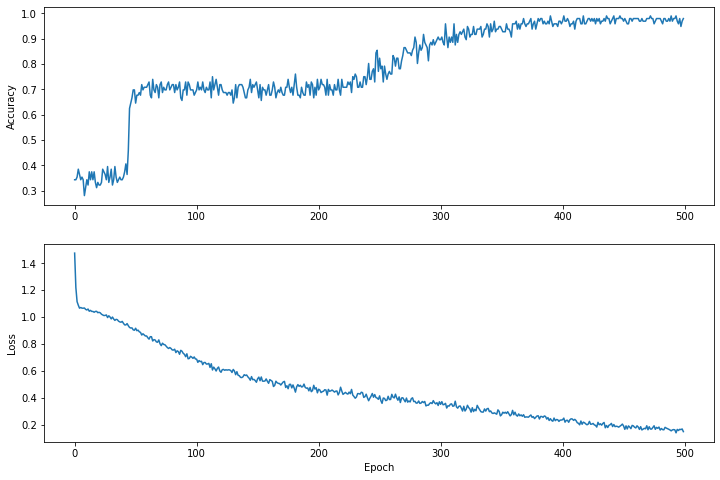
Use `print()` to show values.
グラフの Y 軸はゼロベースではないことに注意してください。
モデルの有効性を評価する
モデルがトレーニングされたので、そのパフォーマンスに関する統計を取得できます。
評価とは、モデルがどの程度効果的に予測を行うかを判断することを意味します。アヤメの分類におけるモデルの有効性を判断するには、がく片と花弁の測定値をモデルに渡し、それらがどのアヤメの種を表すかを予測するようにモデルに依頼します。次に、モデルの予測を実際のラベルと比較します。たとえば、入力例の半分で正しい種を選択したモデルの精度は0.5です。図 4 は、わずかに効果的なモデルを示しており、5 つの予測のうち 4 つが 80% の精度で正解しています。
| 機能例 | ラベル | モデル予測 | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| 図 4.精度 80% の虹彩分類器。 | |||||
テスト データセットをセットアップする
モデルの評価は、モデルのトレーニングと似ています。最大の違いは、サンプルがトレーニング セットではなく別のテスト セットから取得されていることです。モデルの有効性を公正に評価するには、モデルの評価に使用される例は、モデルのトレーニングに使用される例とは異なっていなければなりません。
テスト データセットのセットアップは、トレーニング データセットのセットアップと似ています。 http://download.tensorflow.org/data/iris_test.csvからテスト セットをダウンロードします。
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
次に、それをIrisBatchの配列にロードします。
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
テスト データセットでモデルを評価する
トレーニング段階とは異なり、モデルはテスト データの単一エポックのみを評価します。次のコード セルでは、テスト セット内の各例を反復し、モデルの予測を実際のラベルと比較します。これは、テスト セット全体にわたるモデルの精度を測定するために使用されます。
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
たとえば、最初のバッチでは、モデルが通常は正しいことがわかります。
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
トレーニングされたモデルを使用して予測を行う
私たちはモデルをトレーニングし、それがアヤメの種を分類するのに優れているが、完璧ではないことを実証しました。次に、トレーニングされたモデルを使用して、ラベルのない例について予測を行ってみましょう。つまり、機能は含まれるがラベルは含まれない例です。
実際には、ラベルのない例は、アプリ、CSV ファイル、データ フィードなど、さまざまなソースから取得される可能性があります。ここでは、ラベルを予測するために 3 つのラベルなしの例を手動で提供します。ラベル番号は次のように名前付き表現にマップされることを思い出してください。
-
0:アイリスセトサ 1: アイリス癜風2:アイリス・バージニカ
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])