
| |  GitHubでソースを表示 GitHubでソースを表示 |
このノートブックはに基づい英語翻訳スペイン語についての配列の配列に(seq2seq)モデル養成有効に注意をベースニューラル機械翻訳へのアプローチ。これは、次の知識があることを前提とした高度な例です。
- シーケンスからシーケンスモデル
- ケラスレイヤーの下のTensorFlowの基本:
- テンソルを直接操作する
- カスタムライティング
keras.Modelsおよびkeras.layers
このアーキテクチャは多少古くなっている間、それはまだ(に進む前に、注意メカニズムのより深い理解を得るに至るまでの仕事に非常に便利なプロジェクトですトランスフォーマー)。
「?¿todavia estanエンカーサ」このノートブックにモデルを訓練した後、次のような、スペイン語の文章を入力することができ、そして英語の翻訳を返します:「あなたは自宅ではまだですか?」
得られたモデルは、としてエクスポートされtf.saved_modelので、他のTensorFlow環境で使用することができます。
おもちゃの例では翻訳品質は妥当ですが、生成された注意プロットはおそらくもっと興味深いものです。これは、入力文のどの部分が翻訳中にモデルの注意を引くかを示しています。
設定
pip install tensorflow_text
import numpy as np
import typing
from typing import Any, Tuple
import tensorflow as tf
import tensorflow_text as tf_text
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
このチュートリアルでは、いくつかのレイヤーを最初から作成します。カスタム実装と組み込み実装を切り替える場合は、この変数を使用してください。
use_builtins = True
このチュートリアルでは、形状を間違えやすい低レベルのAPIを多数使用しています。このクラスは、チュートリアル全体で形状をチェックするために使用されます。
シェイプチェッカー
class ShapeChecker():
def __init__(self):
# Keep a cache of every axis-name seen
self.shapes = {}
def __call__(self, tensor, names, broadcast=False):
if not tf.executing_eagerly():
return
if isinstance(names, str):
names = (names,)
shape = tf.shape(tensor)
rank = tf.rank(tensor)
if rank != len(names):
raise ValueError(f'Rank mismatch:\n'
f' found {rank}: {shape.numpy()}\n'
f' expected {len(names)}: {names}\n')
for i, name in enumerate(names):
if isinstance(name, int):
old_dim = name
else:
old_dim = self.shapes.get(name, None)
new_dim = shape[i]
if (broadcast and new_dim == 1):
continue
if old_dim is None:
# If the axis name is new, add its length to the cache.
self.shapes[name] = new_dim
continue
if new_dim != old_dim:
raise ValueError(f"Shape mismatch for dimension: '{name}'\n"
f" found: {new_dim}\n"
f" expected: {old_dim}\n")
データ
我々はによって提供言語データセット使用しますhttp://www.manythings.org/anki/をこのデータセットは、フォーマットの言語翻訳のペアが含まれています。
May I borrow this book? ¿Puedo tomar prestado este libro?
さまざまな言語を利用できますが、英語とスペイン語のデータセットを使用します。
データセットをダウンロードして準備する
便宜上、このデータセットのコピーをGoogle Cloudでホストしていますが、独自のコピーをダウンロードすることもできます。データセットをダウンロードした後、データを準備するために実行する手順は次のとおりです。
- 各センテンスのトークン開始と終了を追加します。
- 特殊文字を削除して文をクリーンアップします。
- 単語インデックスと逆単語インデックスを作成します(単語→idおよびid→単語からの辞書マッピング)。
- 各文を最大長までパディングします。
# Download the file
import pathlib
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = pathlib.Path(path_to_zip).parent/'spa-eng/spa.txt'
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip 2646016/2638744 [==============================] - 0s 0us/step 2654208/2638744 [==============================] - 0s 0us/step
def load_data(path):
text = path.read_text(encoding='utf-8')
lines = text.splitlines()
pairs = [line.split('\t') for line in lines]
inp = [inp for targ, inp in pairs]
targ = [targ for targ, inp in pairs]
return targ, inp
targ, inp = load_data(path_to_file)
print(inp[-1])
Si quieres sonar como un hablante nativo, debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un músico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado.
print(targ[-1])
If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
tf.dataデータセットを作成します
文字列のこれらの配列からは、作成することができtf.data.Datasetそのシャッフルバッチそれらを効率的に文字列のを:
BUFFER_SIZE = len(inp)
BATCH_SIZE = 64
dataset = tf.data.Dataset.from_tensor_slices((inp, targ)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE)
for example_input_batch, example_target_batch in dataset.take(1):
print(example_input_batch[:5])
print()
print(example_target_batch[:5])
break
tf.Tensor( [b'No s\xc3\xa9 lo que quiero.' b'\xc2\xbfDeber\xc3\xada repetirlo?' b'Tard\xc3\xa9 m\xc3\xa1s de 2 horas en traducir unas p\xc3\xa1ginas en ingl\xc3\xa9s.' b'A Tom comenz\xc3\xb3 a temerle a Mary.' b'Mi pasatiempo es la lectura.'], shape=(5,), dtype=string) tf.Tensor( [b"I don't know what I want." b'Should I repeat it?' b'It took me more than two hours to translate a few pages of English.' b'Tom became afraid of Mary.' b'My hobby is reading.'], shape=(5,), dtype=string)
テキストの前処理
このチュートリアルの目標の一つは、としてエクスポートすることができるモデル構築することであるtf.saved_model 。そのエクスポートされたモデルが有用にするためにそれが取るべきtf.string入力を、と戻りtf.string出力を:すべてのテキスト処理は、モデルの内部で起こります。
標準化
モデルは、語彙が限られた多言語テキストを処理しています。したがって、入力テキストを標準化することが重要になります。
最初のステップは、アクセント付き文字を分割し、互換性文字を同等のASCII文字に置き換えるUnicode正規化です。
tensorflow_textパッケージは、Unicode正規化の操作が含まれています。
example_text = tf.constant('¿Todavía está en casa?')
print(example_text.numpy())
print(tf_text.normalize_utf8(example_text, 'NFKD').numpy())
b'\xc2\xbfTodav\xc3\xada est\xc3\xa1 en casa?' b'\xc2\xbfTodavi\xcc\x81a esta\xcc\x81 en casa?'
Unicode正規化は、テキスト標準化機能の最初のステップになります。
def tf_lower_and_split_punct(text):
# Split accecented characters.
text = tf_text.normalize_utf8(text, 'NFKD')
text = tf.strings.lower(text)
# Keep space, a to z, and select punctuation.
text = tf.strings.regex_replace(text, '[^ a-z.?!,¿]', '')
# Add spaces around punctuation.
text = tf.strings.regex_replace(text, '[.?!,¿]', r' \0 ')
# Strip whitespace.
text = tf.strings.strip(text)
text = tf.strings.join(['[START]', text, '[END]'], separator=' ')
return text
print(example_text.numpy().decode())
print(tf_lower_and_split_punct(example_text).numpy().decode())
¿Todavía está en casa? [START] ¿ todavia esta en casa ? [END]
テキストのベクトル化
この標準化関数は、に包まするtf.keras.layers.TextVectorizationトークンのシーケンスに入力テキストの語彙抽出および変換を処理する層です。
max_vocab_size = 5000
input_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
TextVectorization層および他の多くの前処理層が持つadapt方法を。この方法では、トレーニングデータの1つのエポックを読み込み、など多くの作品Model.fix 。これは、 adapt方法をデータに基づいて層を初期化します。ここで語彙を決定します:
input_text_processor.adapt(inp)
# Here are the first 10 words from the vocabulary:
input_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'que', 'de', 'el', 'a', 'no']
それはスペインだTextVectorization構築と、今、層.adapt()英語1:
output_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
output_text_processor.adapt(targ)
output_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'the', 'i', 'to', 'you', 'tom']
これで、これらのレイヤーは文字列のバッチをトークンIDのバッチに変換できます。
example_tokens = input_text_processor(example_input_batch)
example_tokens[:3, :10]
<tf.Tensor: shape=(3, 10), dtype=int64, numpy=
array([[ 2, 9, 17, 22, 5, 48, 4, 3, 0, 0],
[ 2, 13, 177, 1, 12, 3, 0, 0, 0, 0],
[ 2, 120, 35, 6, 290, 14, 2134, 506, 2637, 14]])>
get_vocabulary方法は、テキストに戻ってトークンIDを変換するために使用することができます。
input_vocab = np.array(input_text_processor.get_vocabulary())
tokens = input_vocab[example_tokens[0].numpy()]
' '.join(tokens)
'[START] no se lo que quiero . [END] '
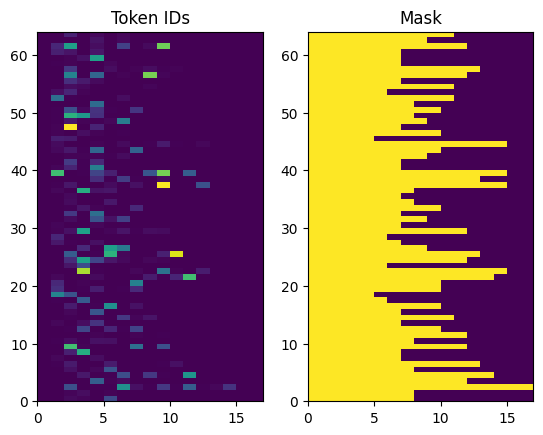
返されたトークンIDはゼロで埋められます。これは簡単にマスクに変えることができます:
plt.subplot(1, 2, 1)
plt.pcolormesh(example_tokens)
plt.title('Token IDs')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')
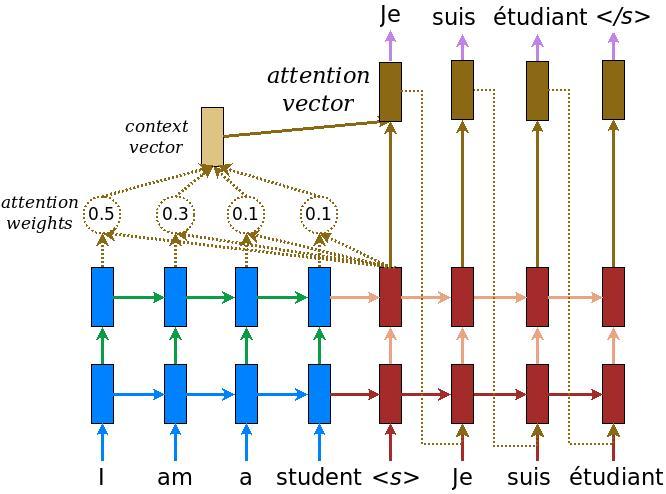
エンコーダー/デコーダーモデル
次の図は、モデルの概要を示しています。各タイムステップで、デコーダーの出力は、エンコードされた入力の加重和と組み合わされて、次の単語を予測します。図や数式があるからルオンの論文。
それに入る前に、モデルのいくつかの定数を定義します。
embedding_dim = 256
units = 1024
エンコーダー
上の図の青い部分であるエンコーダーを構築することから始めます。
エンコーダー:
- (からトークンIDのリストを取り
input_text_processor)。 - (使用して、各トークンの埋め込みベクトルルックアップ
layers.Embedding)。 - (使用して新しい配列への埋め込みを処理
layers.GRU)。 - 戻り値:
- 処理されたシーケンス。これはアテンションヘッドに渡されます。
- 内部状態。これは、デコーダーを初期化するために使用されます
class Encoder(tf.keras.layers.Layer):
def __init__(self, input_vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.enc_units = enc_units
self.input_vocab_size = input_vocab_size
# The embedding layer converts tokens to vectors
self.embedding = tf.keras.layers.Embedding(self.input_vocab_size,
embedding_dim)
# The GRU RNN layer processes those vectors sequentially.
self.gru = tf.keras.layers.GRU(self.enc_units,
# Return the sequence and state
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, tokens, state=None):
shape_checker = ShapeChecker()
shape_checker(tokens, ('batch', 's'))
# 2. The embedding layer looks up the embedding for each token.
vectors = self.embedding(tokens)
shape_checker(vectors, ('batch', 's', 'embed_dim'))
# 3. The GRU processes the embedding sequence.
# output shape: (batch, s, enc_units)
# state shape: (batch, enc_units)
output, state = self.gru(vectors, initial_state=state)
shape_checker(output, ('batch', 's', 'enc_units'))
shape_checker(state, ('batch', 'enc_units'))
# 4. Returns the new sequence and its state.
return output, state
これまでのところ、これがどのように組み合わされているかを示します。
# Convert the input text to tokens.
example_tokens = input_text_processor(example_input_batch)
# Encode the input sequence.
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
example_enc_output, example_enc_state = encoder(example_tokens)
print(f'Input batch, shape (batch): {example_input_batch.shape}')
print(f'Input batch tokens, shape (batch, s): {example_tokens.shape}')
print(f'Encoder output, shape (batch, s, units): {example_enc_output.shape}')
print(f'Encoder state, shape (batch, units): {example_enc_state.shape}')
Input batch, shape (batch): (64,) Input batch tokens, shape (batch, s): (64, 14) Encoder output, shape (batch, s, units): (64, 14, 1024) Encoder state, shape (batch, units): (64, 1024)
エンコーダーは内部状態を返すため、その状態を使用してデコーダーを初期化できます。
また、RNNがその状態を返し、複数の呼び出しでシーケンスを処理できるようにすることも一般的です。デコーダーの構築について詳しく説明します。
アテンションヘッド
デコーダーは注意を使用して、入力シーケンスの一部に選択的に焦点を合わせます。アテンションは、各例の入力として一連のベクトルを受け取り、各例の「アテンション」ベクトルを返します。この注意層はに似てlayers.GlobalAveragePoling1Dが、注意層は、加重平均を実行します。
これがどのように機能するかを見てみましょう。


どこ:
- \(s\) エンコーダインデックスです。
- \(t\) デコーダ指標です。
- \(\alpha_{ts}\) 注目の重みです。
- \(h_s\) (注目「キー」とトランス用語の「値」)に出席しているエンコーダ出力のシーケンスです。
- \(h_t\) シーケンス(変圧器の用語で注目「クエリ」)に参加デコーダ状態です。
- \(c_t\) 得られるコンテキストベクトルです。
- \(a_t\) 「コンテキスト」と「クエリ」を組み合わせる最終的な出力です。
方程式:
- 注目の重みを計算し \(\alpha_{ts}\)エンコーダの出力シーケンス全体でソフトマックスとして、。
- エンコーダ出力の加重和としてコンテキストベクトルを計算します。
最後は、 \(score\) 機能。その仕事は、各キーとクエリのペアのスカラーロジットスコアを計算することです。 2つの一般的なアプローチがあります。
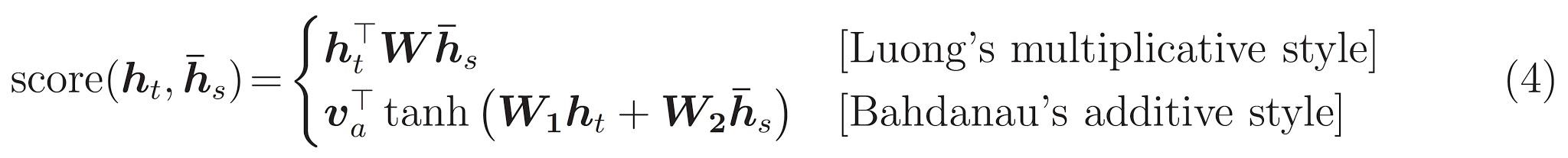
このチュートリアルでは使用していますBahdanauの添加剤の注意を。 TensorFlowでは、どちらの実装を含むlayers.Attentionとlayers.AdditiveAttention 。ハンドル下のクラスのペアの重み行列layers.Dense層、および組み込みの実装を呼び出します。
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
# For Eqn. (4), the Bahdanau attention
self.W1 = tf.keras.layers.Dense(units, use_bias=False)
self.W2 = tf.keras.layers.Dense(units, use_bias=False)
self.attention = tf.keras.layers.AdditiveAttention()
def call(self, query, value, mask):
shape_checker = ShapeChecker()
shape_checker(query, ('batch', 't', 'query_units'))
shape_checker(value, ('batch', 's', 'value_units'))
shape_checker(mask, ('batch', 's'))
# From Eqn. (4), `W1@ht`.
w1_query = self.W1(query)
shape_checker(w1_query, ('batch', 't', 'attn_units'))
# From Eqn. (4), `W2@hs`.
w2_key = self.W2(value)
shape_checker(w2_key, ('batch', 's', 'attn_units'))
query_mask = tf.ones(tf.shape(query)[:-1], dtype=bool)
value_mask = mask
context_vector, attention_weights = self.attention(
inputs = [w1_query, value, w2_key],
mask=[query_mask, value_mask],
return_attention_scores = True,
)
shape_checker(context_vector, ('batch', 't', 'value_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
return context_vector, attention_weights
アテンションレイヤーをテストする
作成BahdanauAttention層を:
attention_layer = BahdanauAttention(units)
このレイヤーは3つの入力を取ります:
-
query:これは、後に、デコーダによって生成されます。 -
value:これは、エンコーダの出力されます。 -
mask:、パディングを除外するにはexample_tokens != 0
(example_tokens != 0).shape
TensorShape([64, 14])
アテンションレイヤーのベクトル化された実装により、クエリベクトルのシーケンスのバッチと値ベクトルのシーケンスのバッチを渡すことができます。結果は次のとおりです。
- 結果ベクトルのシーケンスのバッチは、クエリのサイズです。
- バッチ注意はサイズで、マップする
(query_length, value_length)
# Later, the decoder will generate this attention query
example_attention_query = tf.random.normal(shape=[len(example_tokens), 2, 10])
# Attend to the encoded tokens
context_vector, attention_weights = attention_layer(
query=example_attention_query,
value=example_enc_output,
mask=(example_tokens != 0))
print(f'Attention result shape: (batch_size, query_seq_length, units): {context_vector.shape}')
print(f'Attention weights shape: (batch_size, query_seq_length, value_seq_length): {attention_weights.shape}')
Attention result shape: (batch_size, query_seq_length, units): (64, 2, 1024) Attention weights shape: (batch_size, query_seq_length, value_seq_length): (64, 2, 14)
注目の重みは合計にすべきである1.0各シーケンスのために。
ここで、シーケンス全体の注意重みであるt=0 :
plt.subplot(1, 2, 1)
plt.pcolormesh(attention_weights[:, 0, :])
plt.title('Attention weights')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')

小さいため、ランダム初期の注目の重みは全てに接近している1/(sequence_length)あなたは、単一のシーケンスに対する重みをズームインする場合は、モデルが展開し、活用するために学ぶことができることをいくつかの小さなばらつきがあることがわかります。
attention_weights.shape
TensorShape([64, 2, 14])
attention_slice = attention_weights[0, 0].numpy()
attention_slice = attention_slice[attention_slice != 0]
plt.suptitle('Attention weights for one sequence')
plt.figure(figsize=(12, 6))
a1 = plt.subplot(1, 2, 1)
plt.bar(range(len(attention_slice)), attention_slice)
# freeze the xlim
plt.xlim(plt.xlim())
plt.xlabel('Attention weights')
a2 = plt.subplot(1, 2, 2)
plt.bar(range(len(attention_slice)), attention_slice)
plt.xlabel('Attention weights, zoomed')
# zoom in
top = max(a1.get_ylim())
zoom = 0.85*top
a2.set_ylim([0.90*top, top])
a1.plot(a1.get_xlim(), [zoom, zoom], color='k')
[<matplotlib.lines.Line2D at 0x7fb42c5b1090>] <Figure size 432x288 with 0 Axes>

デコーダー
デコーダーの仕事は、次の出力トークンの予測を生成することです。
- デコーダーは完全なエンコーダー出力を受け取ります。
- RNNを使用して、これまでに生成されたものを追跡します。
- RNN出力をエンコーダーの出力に対する注意のクエリとして使用し、コンテキストベクトルを生成します。
- これは、式3(下記)を使用してRNN出力とコンテキストベクトルを組み合わせて「注意ベクトル」を生成します。
- 「注意ベクトル」に基づいて、次のトークンのロジット予測を生成します。

ここでDecoderクラスとその初期化子。イニシャライザは、必要なすべてのレイヤーを作成します。
class Decoder(tf.keras.layers.Layer):
def __init__(self, output_vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.dec_units = dec_units
self.output_vocab_size = output_vocab_size
self.embedding_dim = embedding_dim
# For Step 1. The embedding layer convets token IDs to vectors
self.embedding = tf.keras.layers.Embedding(self.output_vocab_size,
embedding_dim)
# For Step 2. The RNN keeps track of what's been generated so far.
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
# For step 3. The RNN output will be the query for the attention layer.
self.attention = BahdanauAttention(self.dec_units)
# For step 4. Eqn. (3): converting `ct` to `at`
self.Wc = tf.keras.layers.Dense(dec_units, activation=tf.math.tanh,
use_bias=False)
# For step 5. This fully connected layer produces the logits for each
# output token.
self.fc = tf.keras.layers.Dense(self.output_vocab_size)
callこの層のための方法をとり、複数のテンソルを返します。それらを単純なコンテナクラスに編成します。
class DecoderInput(typing.NamedTuple):
new_tokens: Any
enc_output: Any
mask: Any
class DecoderOutput(typing.NamedTuple):
logits: Any
attention_weights: Any
ここでの実装であるcall方法は:
def call(self,
inputs: DecoderInput,
state=None) -> Tuple[DecoderOutput, tf.Tensor]:
shape_checker = ShapeChecker()
shape_checker(inputs.new_tokens, ('batch', 't'))
shape_checker(inputs.enc_output, ('batch', 's', 'enc_units'))
shape_checker(inputs.mask, ('batch', 's'))
if state is not None:
shape_checker(state, ('batch', 'dec_units'))
# Step 1. Lookup the embeddings
vectors = self.embedding(inputs.new_tokens)
shape_checker(vectors, ('batch', 't', 'embedding_dim'))
# Step 2. Process one step with the RNN
rnn_output, state = self.gru(vectors, initial_state=state)
shape_checker(rnn_output, ('batch', 't', 'dec_units'))
shape_checker(state, ('batch', 'dec_units'))
# Step 3. Use the RNN output as the query for the attention over the
# encoder output.
context_vector, attention_weights = self.attention(
query=rnn_output, value=inputs.enc_output, mask=inputs.mask)
shape_checker(context_vector, ('batch', 't', 'dec_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
# Step 4. Eqn. (3): Join the context_vector and rnn_output
# [ct; ht] shape: (batch t, value_units + query_units)
context_and_rnn_output = tf.concat([context_vector, rnn_output], axis=-1)
# Step 4. Eqn. (3): `at = tanh(Wc@[ct; ht])`
attention_vector = self.Wc(context_and_rnn_output)
shape_checker(attention_vector, ('batch', 't', 'dec_units'))
# Step 5. Generate logit predictions:
logits = self.fc(attention_vector)
shape_checker(logits, ('batch', 't', 'output_vocab_size'))
return DecoderOutput(logits, attention_weights), state
Decoder.call = call
エンコーダは、そのRNNへの1回の呼び出しでその完全な入力シーケンスを処理します。デコーダのこの実装では、効率的なトレーニングのためにもそれを行うことができます。ただし、このチュートリアルでは、いくつかの理由でデコーダーをループで実行します。
- 柔軟性:ループを作成すると、トレーニング手順を直接制御できます。
- クラリティ:それはマスキングトリックを行うと、使用することが可能です
layers.RNN、またはtfa.seq2seq単一の呼び出しには、このすべてをパックするためのAPIを。しかし、それをループとして書き出す方がより明確かもしれません。- ループのないトレーニングがで実証されたテキスト生成tutiorial。
次に、このデコーダーを使用してみてください。
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
デコーダーは4つの入力を取ります。
-
new_tokens-最後のトークンが生成されます。復号器を初期化する"[START]"トークン。 -
enc_output-によって生成されたEncoder。 -
mask-を示すbooleanテンソルtokens != 0 -
state-前stateデコーダ(デコーダのRNNの内部状態)から出力されます。合格しなかっNoneに、それをゼロに初期化します。元の論文は、エンコーダーの最終的なRNN状態から初期化します。
# Convert the target sequence, and collect the "[START]" tokens
example_output_tokens = output_text_processor(example_target_batch)
start_index = output_text_processor.get_vocabulary().index('[START]')
first_token = tf.constant([[start_index]] * example_output_tokens.shape[0])
# Run the decoder
dec_result, dec_state = decoder(
inputs = DecoderInput(new_tokens=first_token,
enc_output=example_enc_output,
mask=(example_tokens != 0)),
state = example_enc_state
)
print(f'logits shape: (batch_size, t, output_vocab_size) {dec_result.logits.shape}')
print(f'state shape: (batch_size, dec_units) {dec_state.shape}')
logits shape: (batch_size, t, output_vocab_size) (64, 1, 5000) state shape: (batch_size, dec_units) (64, 1024)
ロジットに従ってトークンをサンプリングします。
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
トークンを出力の最初の単語としてデコードします。
vocab = np.array(output_text_processor.get_vocabulary())
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['already'],
['plants'],
['pretended'],
['convince'],
['square']], dtype='<U16')
次に、デコーダーを使用して、ロジットの2番目のセットを生成します。
- 同じパス
enc_outputとmask、これらは変更されていません。 - サンプリングトークンを渡し
new_tokens。 - 通過
decoder_stateデコーダが前回返さので、RNNは、前回中断した場所の記憶を続けます。
dec_result, dec_state = decoder(
DecoderInput(sampled_token,
example_enc_output,
mask=(example_tokens != 0)),
state=dec_state)
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['nap'],
['mean'],
['worker'],
['passage'],
['baked']], dtype='<U16')
トレーニング
すべてのモデルコンポーネントが揃ったので、モデルのトレーニングを開始します。あなたは必要になるでしょう:
- 最適化を実行するための損失関数とオプティマイザー。
- 各入力/ターゲットバッチのモデルを更新する方法を定義するトレーニングステップ関数。
- トレーニングを推進し、チェックポイントを保存するためのトレーニングループ。
損失関数を定義する
class MaskedLoss(tf.keras.losses.Loss):
def __init__(self):
self.name = 'masked_loss'
self.loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def __call__(self, y_true, y_pred):
shape_checker = ShapeChecker()
shape_checker(y_true, ('batch', 't'))
shape_checker(y_pred, ('batch', 't', 'logits'))
# Calculate the loss for each item in the batch.
loss = self.loss(y_true, y_pred)
shape_checker(loss, ('batch', 't'))
# Mask off the losses on padding.
mask = tf.cast(y_true != 0, tf.float32)
shape_checker(mask, ('batch', 't'))
loss *= mask
# Return the total.
return tf.reduce_sum(loss)
トレーニングステップを実装する
モデルクラスから始めて、トレーニングプロセスは、として実装されますtrain_stepこのモデルの方法。参照のカスタマイズは、フィットの詳細については。
ここでtrain_step方法は、ラッパーです_train_step後に来る実装。このラッパーは、オンとオフオンにするスイッチを含むtf.functionデバッグを容易にするために、コンパイル。
class TrainTranslator(tf.keras.Model):
def __init__(self, embedding_dim, units,
input_text_processor,
output_text_processor,
use_tf_function=True):
super().__init__()
# Build the encoder and decoder
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.use_tf_function = use_tf_function
self.shape_checker = ShapeChecker()
def train_step(self, inputs):
self.shape_checker = ShapeChecker()
if self.use_tf_function:
return self._tf_train_step(inputs)
else:
return self._train_step(inputs)
全体としての実装Model.train_step方法は以下の通りです:
- バッチ受信
input_text, target_textからtf.data.Dataset。 - それらの生のテキスト入力をトークン埋め込みとマスクに変換します。
- 上のエンコーダを実行し
input_tokens取得するためにencoder_outputとencoder_state。 - デコーダーの状態と損失を初期化します。
- 以上のループ
target_tokens:- デコーダーを一度に1ステップ実行します。
- 各ステップの損失を計算します。
- 平均損失を累積します。
- 損失の勾配を計算し、モデルのに更新を適用するためにオプティマイザを使用し
trainable_variables。
_preprocess方法は、以下を加え、器具は、#1及び#2ステップ:
def _preprocess(self, input_text, target_text):
self.shape_checker(input_text, ('batch',))
self.shape_checker(target_text, ('batch',))
# Convert the text to token IDs
input_tokens = self.input_text_processor(input_text)
target_tokens = self.output_text_processor(target_text)
self.shape_checker(input_tokens, ('batch', 's'))
self.shape_checker(target_tokens, ('batch', 't'))
# Convert IDs to masks.
input_mask = input_tokens != 0
self.shape_checker(input_mask, ('batch', 's'))
target_mask = target_tokens != 0
self.shape_checker(target_mask, ('batch', 't'))
return input_tokens, input_mask, target_tokens, target_mask
TrainTranslator._preprocess = _preprocess
_train_step下に追加方法は、実際のデコーダの実行を除いた残りのステップを処理します。
def _train_step(self, inputs):
input_text, target_text = inputs
(input_tokens, input_mask,
target_tokens, target_mask) = self._preprocess(input_text, target_text)
max_target_length = tf.shape(target_tokens)[1]
with tf.GradientTape() as tape:
# Encode the input
enc_output, enc_state = self.encoder(input_tokens)
self.shape_checker(enc_output, ('batch', 's', 'enc_units'))
self.shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder's state to the encoder's final state.
# This only works if the encoder and decoder have the same number of
# units.
dec_state = enc_state
loss = tf.constant(0.0)
for t in tf.range(max_target_length-1):
# Pass in two tokens from the target sequence:
# 1. The current input to the decoder.
# 2. The target for the decoder's next prediction.
new_tokens = target_tokens[:, t:t+2]
step_loss, dec_state = self._loop_step(new_tokens, input_mask,
enc_output, dec_state)
loss = loss + step_loss
# Average the loss over all non padding tokens.
average_loss = loss / tf.reduce_sum(tf.cast(target_mask, tf.float32))
# Apply an optimization step
variables = self.trainable_variables
gradients = tape.gradient(average_loss, variables)
self.optimizer.apply_gradients(zip(gradients, variables))
# Return a dict mapping metric names to current value
return {'batch_loss': average_loss}
TrainTranslator._train_step = _train_step
_loop_step方法は、以下を加え、デコーダを実行し、増分損失と新しいデコーダ状態(算出dec_state )。
def _loop_step(self, new_tokens, input_mask, enc_output, dec_state):
input_token, target_token = new_tokens[:, 0:1], new_tokens[:, 1:2]
# Run the decoder one step.
decoder_input = DecoderInput(new_tokens=input_token,
enc_output=enc_output,
mask=input_mask)
dec_result, dec_state = self.decoder(decoder_input, state=dec_state)
self.shape_checker(dec_result.logits, ('batch', 't1', 'logits'))
self.shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
self.shape_checker(dec_state, ('batch', 'dec_units'))
# `self.loss` returns the total for non-padded tokens
y = target_token
y_pred = dec_result.logits
step_loss = self.loss(y, y_pred)
return step_loss, dec_state
TrainTranslator._loop_step = _loop_step
トレーニングステップをテストする
ビルドしTrainTranslator 、そして使用して訓練するためにそれを構成するModel.compile方法を:
translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
use_tf_function=False)
# Configure the loss and optimizer
translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
試しtrain_step 。このようなテキストモデルの場合、損失は次の近くから始まるはずです。
np.log(output_text_processor.vocabulary_size())
8.517193191416236
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.5849695>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.55271>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.4929113>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.3296022>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=6.80437>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.000246>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.8740363>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.794589>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.3175836>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.108163>}
CPU times: user 5.49 s, sys: 0 ns, total: 5.49 s
Wall time: 5.45 s
それはせずにデバッグが容易ですがtf.functionそれは、パフォーマンスの向上が得られません。だから今という_train_stepメソッドが動作している、してみてくださいtf.function -wrapped _tf_train_stepトレーニングしながら、パフォーマンスを最大化するために、:
@tf.function(input_signature=[[tf.TensorSpec(dtype=tf.string, shape=[None]),
tf.TensorSpec(dtype=tf.string, shape=[None])]])
def _tf_train_step(self, inputs):
return self._train_step(inputs)
TrainTranslator._tf_train_step = _tf_train_step
translator.use_tf_function = True
最初の呼び出しは、関数をトレースするため、遅くなります。
translator.train_step([example_input_batch, example_target_batch])
2021-12-04 12:09:48.074769: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.180156: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:09:48.285846: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:09:48.307794: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.425447: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node while/body/_1/while/TensorListPushBack_56 was passed float from while/body/_1/while/decoder_1/gru_3/PartitionedCall:6 incompatible with expected variant.
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.045638>}
しかし、その後、それは通常より速く熱心に比べ2〜3倍だtrain_step方法:
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.1098256>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.169871>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.139249>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.0410743>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.9664454>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.895707>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.8154407>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.7583396>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.6986444>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.640298>}
CPU times: user 4.4 s, sys: 960 ms, total: 5.36 s
Wall time: 1.67 s
新しいモデルの良いテストは、それが入力の単一のバッチに適合しすぎる可能性があることを確認することです。それを試してみてください、損失はすぐにゼロになるはずです:
losses = []
for n in range(100):
print('.', end='')
logs = translator.train_step([example_input_batch, example_target_batch])
losses.append(logs['batch_loss'].numpy())
print()
plt.plot(losses)
.................................................................................................... [<matplotlib.lines.Line2D at 0x7fb427edf210>]

トレーニングステップが機能していることを確認したので、モデルの新しいコピーを作成して、最初からトレーニングします。
train_translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor)
# Configure the loss and optimizer
train_translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
モデルをトレーニングする
実装する、独自のカスタムトレーニングループを書くとそこですが、何も間違ったModel.train_step方法は、前のセクションのように、あなたは実行することができますModel.fitし、すべてのことボイラープレートコードを書き換えることは避けてください。
このチュートリアルエポックのカップルのための唯一の列車は、その使用callbacks.Callbackプロットするため、バッチ損失の歴史を収集するために:
class BatchLogs(tf.keras.callbacks.Callback):
def __init__(self, key):
self.key = key
self.logs = []
def on_train_batch_end(self, n, logs):
self.logs.append(logs[self.key])
batch_loss = BatchLogs('batch_loss')
train_translator.fit(dataset, epochs=3,
callbacks=[batch_loss])
Epoch 1/3
2021-12-04 12:10:11.617839: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:11.737105: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:10:11.855054: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:10:11.878896: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:12.004755: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node StatefulPartitionedCall/while/body/_59/while/TensorListPushBack_56 was passed float from StatefulPartitionedCall/while/body/_59/while/decoder_2/gru_5/PartitionedCall:6 incompatible with expected variant.
1859/1859 [==============================] - 349s 185ms/step - batch_loss: 2.0443
Epoch 2/3
1859/1859 [==============================] - 350s 188ms/step - batch_loss: 1.0382
Epoch 3/3
1859/1859 [==============================] - 343s 184ms/step - batch_loss: 0.8085
<keras.callbacks.History at 0x7fb42c3eda10>
plt.plot(batch_loss.logs)
plt.ylim([0, 3])
plt.xlabel('Batch #')
plt.ylabel('CE/token')
Text(0, 0.5, 'CE/token')
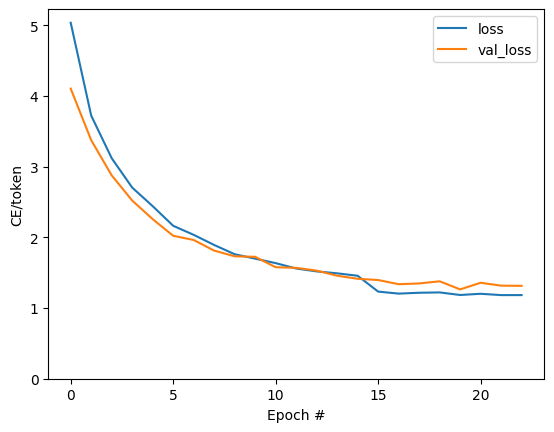
プロットに表示されるジャンプは、エポック境界にあります。
翻訳
今モデルが訓練されていることを、完全な実行するための機能を実装しtext => text翻訳を。
このモデルのニーズを反転させるにはtext => token IDsマッピングによって提供さoutput_text_processor 。また、特別なトークンのIDを知っている必要があります。これはすべて、新しいクラスのコンストラクターに実装されています。実際のtranslateメソッドの実装は次のとおりです。
全体として、これはトレーニングループに似ていますが、各タイムステップでのデコーダーへの入力が、デコーダーの最後の予測からのサンプルである点が異なります。
class Translator(tf.Module):
def __init__(self, encoder, decoder, input_text_processor,
output_text_processor):
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.output_token_string_from_index = (
tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(),
mask_token='',
invert=True))
# The output should never generate padding, unknown, or start.
index_from_string = tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(), mask_token='')
token_mask_ids = index_from_string(['', '[UNK]', '[START]']).numpy()
token_mask = np.zeros([index_from_string.vocabulary_size()], dtype=np.bool)
token_mask[np.array(token_mask_ids)] = True
self.token_mask = token_mask
self.start_token = index_from_string(tf.constant('[START]'))
self.end_token = index_from_string(tf.constant('[END]'))
translator = Translator(
encoder=train_translator.encoder,
decoder=train_translator.decoder,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:21: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
トークンIDをテキストに変換する
実装する最初の方法であるtokens_to_text人間可読テキストにトークンのIDから変換します。
def tokens_to_text(self, result_tokens):
shape_checker = ShapeChecker()
shape_checker(result_tokens, ('batch', 't'))
result_text_tokens = self.output_token_string_from_index(result_tokens)
shape_checker(result_text_tokens, ('batch', 't'))
result_text = tf.strings.reduce_join(result_text_tokens,
axis=1, separator=' ')
shape_checker(result_text, ('batch'))
result_text = tf.strings.strip(result_text)
shape_checker(result_text, ('batch',))
return result_text
Translator.tokens_to_text = tokens_to_text
いくつかのランダムなトークンIDを入力し、それが何を生成するかを確認します。
example_output_tokens = tf.random.uniform(
shape=[5, 2], minval=0, dtype=tf.int64,
maxval=output_text_processor.vocabulary_size())
translator.tokens_to_text(example_output_tokens).numpy()
array([b'vain mysteries', b'funny ham', b'drivers responding',
b'mysterious ignoring', b'fashion votes'], dtype=object)
デコーダーの予測からのサンプル
この関数は、デコーダーのロジット出力を取得し、そのディストリビューションからトークンIDをサンプリングします。
def sample(self, logits, temperature):
shape_checker = ShapeChecker()
# 't' is usually 1 here.
shape_checker(logits, ('batch', 't', 'vocab'))
shape_checker(self.token_mask, ('vocab',))
token_mask = self.token_mask[tf.newaxis, tf.newaxis, :]
shape_checker(token_mask, ('batch', 't', 'vocab'), broadcast=True)
# Set the logits for all masked tokens to -inf, so they are never chosen.
logits = tf.where(self.token_mask, -np.inf, logits)
if temperature == 0.0:
new_tokens = tf.argmax(logits, axis=-1)
else:
logits = tf.squeeze(logits, axis=1)
new_tokens = tf.random.categorical(logits/temperature,
num_samples=1)
shape_checker(new_tokens, ('batch', 't'))
return new_tokens
Translator.sample = sample
いくつかのランダムな入力でこの関数をテスト実行します。
example_logits = tf.random.normal([5, 1, output_text_processor.vocabulary_size()])
example_output_tokens = translator.sample(example_logits, temperature=1.0)
example_output_tokens
<tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[4506],
[3577],
[2961],
[4586],
[ 944]])>
翻訳ループを実装する
これは、テキストからテキストへの翻訳ループの完全な実装です。
この実装は、使用する前に、Pythonのリストに結果を収集tf.concatテンソルにそれらを結合します。
この実装では、静的に出グラフをアンロールmax_lengthの反復。これは、Pythonでの熱心な実行で問題ありません。
def translate_unrolled(self,
input_text, *,
max_length=50,
return_attention=True,
temperature=1.0):
batch_size = tf.shape(input_text)[0]
input_tokens = self.input_text_processor(input_text)
enc_output, enc_state = self.encoder(input_tokens)
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
result_tokens = []
attention = []
done = tf.zeros([batch_size, 1], dtype=tf.bool)
for _ in range(max_length):
dec_input = DecoderInput(new_tokens=new_tokens,
enc_output=enc_output,
mask=(input_tokens!=0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
attention.append(dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens.append(new_tokens)
if tf.executing_eagerly() and tf.reduce_all(done):
break
# Convert the list of generates token ids to a list of strings.
result_tokens = tf.concat(result_tokens, axis=-1)
result_text = self.tokens_to_text(result_tokens)
if return_attention:
attention_stack = tf.concat(attention, axis=1)
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_unrolled
単純な入力で実行します。
%%time
input_text = tf.constant([
'hace mucho frio aqui.', # "It's really cold here."
'Esta es mi vida.', # "This is my life.""
])
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its a long cold here . this is my life . CPU times: user 165 ms, sys: 4.37 ms, total: 169 ms Wall time: 164 ms
あなたがこのモデルをエクスポートしたい場合は、このメソッドをラップする必要がありますtf.function 。これを行おうとすると、この基本的な実装にはいくつかの問題があります。
- 結果のグラフは非常に大きく、作成、保存、またはロードに数秒かかります。
- それが常に実行されるようにするには、静的に展開されたループから壊すことができない
max_length反復をすべての出力が行われた場合でも、。しかし、それでも、熱心な実行よりもわずかに高速です。
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
実行tf.functionコンパイルした後:
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 18.8 s, sys: 0 ns, total: 18.8 s Wall time: 18.7 s
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 88 ms
[オプション]シンボリックループを使用する
def translate_symbolic(self,
input_text,
*,
max_length=50,
return_attention=True,
temperature=1.0):
shape_checker = ShapeChecker()
shape_checker(input_text, ('batch',))
batch_size = tf.shape(input_text)[0]
# Encode the input
input_tokens = self.input_text_processor(input_text)
shape_checker(input_tokens, ('batch', 's'))
enc_output, enc_state = self.encoder(input_tokens)
shape_checker(enc_output, ('batch', 's', 'enc_units'))
shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
shape_checker(new_tokens, ('batch', 't1'))
# Initialize the accumulators
result_tokens = tf.TensorArray(tf.int64, size=1, dynamic_size=True)
attention = tf.TensorArray(tf.float32, size=1, dynamic_size=True)
done = tf.zeros([batch_size, 1], dtype=tf.bool)
shape_checker(done, ('batch', 't1'))
for t in tf.range(max_length):
dec_input = DecoderInput(
new_tokens=new_tokens, enc_output=enc_output, mask=(input_tokens != 0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
attention = attention.write(t, dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
shape_checker(dec_result.logits, ('batch', 't1', 'vocab'))
shape_checker(new_tokens, ('batch', 't1'))
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens = result_tokens.write(t, new_tokens)
if tf.reduce_all(done):
break
# Convert the list of generated token ids to a list of strings.
result_tokens = result_tokens.stack()
shape_checker(result_tokens, ('t', 'batch', 't0'))
result_tokens = tf.squeeze(result_tokens, -1)
result_tokens = tf.transpose(result_tokens, [1, 0])
shape_checker(result_tokens, ('batch', 't'))
result_text = self.tokens_to_text(result_tokens)
shape_checker(result_text, ('batch',))
if return_attention:
attention_stack = attention.stack()
shape_checker(attention_stack, ('t', 'batch', 't1', 's'))
attention_stack = tf.squeeze(attention_stack, 2)
shape_checker(attention_stack, ('t', 'batch', 's'))
attention_stack = tf.transpose(attention_stack, [1, 0, 2])
shape_checker(attention_stack, ('batch', 't', 's'))
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_symbolic
最初の実装では、Pythonリストを使用して出力を収集しました。これは、使用していますtf.rangeできるように、ループイテレータとしてtf.autographループを変換します。この実装で最大の変化は、の使用であるtf.TensorArrayの代わりに、Pythonのlist蓄積テンソルへ。 tf.TensorArrayグラフモードにおけるテンソルの可変数を収集する必要があります。
熱心に実行すると、この実装は元の実装と同等に実行されます。
%%time
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 170 ms
あなたがそれをラップするときしかしtf.function 、あなたは2つの違いに気付くでしょう。
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
まず:グラフの作成がはるかに高速である(〜10倍)、それは作成されませんので、 max_iterationsモデルのコピーを。
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 1.79 s, sys: 0 ns, total: 1.79 s Wall time: 1.77 s
2番目:コンパイルされた関数は、ループから抜け出す可能性があるため、小さな入力(この例では5倍)ではるかに高速です。
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 40.1 ms, sys: 0 ns, total: 40.1 ms Wall time: 17.1 ms
プロセスを視覚化する
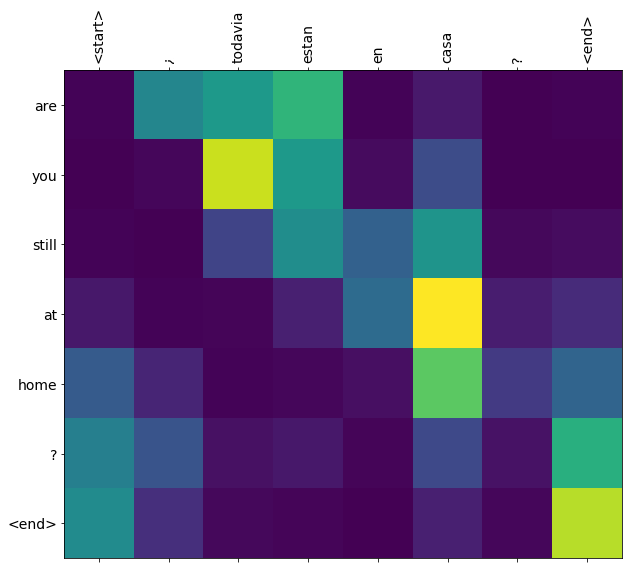
返された注目の重みtranslate 、それは各出力トークンを生成したときにモデルがいた方法ショーは「見ています」。
したがって、入力に対する注意の合計は、すべてのものを返す必要があります。
a = result['attention'][0]
print(np.sum(a, axis=-1))
[1.0000001 0.99999994 1. 0.99999994 1. 0.99999994]
これは、最初の例の最初の出力ステップの注意分布です。トレーニングを受けていないモデルよりも注意が集中していることに注意してください。
_ = plt.bar(range(len(a[0, :])), a[0, :])

入力単語と出力単語の間には大まかな配置があるため、対角線の近くに注意が集中することが期待されます。
plt.imshow(np.array(a), vmin=0.0)
<matplotlib.image.AxesImage at 0x7faf2886ced0>

より良い注意プロットを作成するためのコードを次に示します。
ラベル付き注意プロット
def plot_attention(attention, sentence, predicted_sentence):
sentence = tf_lower_and_split_punct(sentence).numpy().decode().split()
predicted_sentence = predicted_sentence.numpy().decode().split() + ['[END]']
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1)
attention = attention[:len(predicted_sentence), :len(sentence)]
ax.matshow(attention, cmap='viridis', vmin=0.0)
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
ax.set_xlabel('Input text')
ax.set_ylabel('Output text')
plt.suptitle('Attention weights')
i=0
plot_attention(result['attention'][i], input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
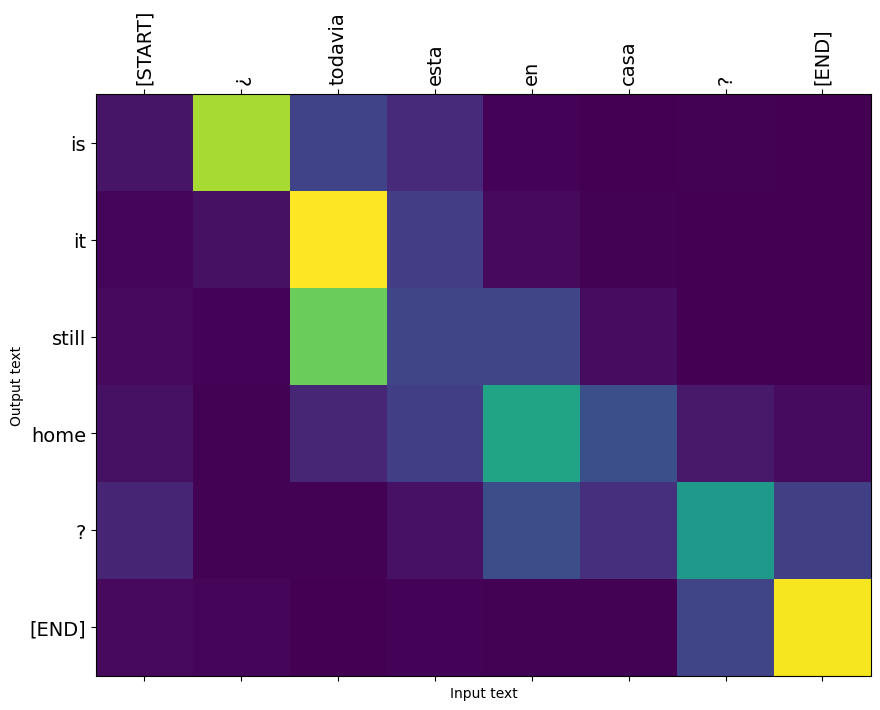
さらにいくつかの文を翻訳してプロットします。
%%time
three_input_text = tf.constant([
# This is my life.
'Esta es mi vida.',
# Are they still home?
'¿Todavía están en casa?',
# Try to find out.'
'Tratar de descubrir.',
])
result = translator.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? all about killed . CPU times: user 78 ms, sys: 23 ms, total: 101 ms Wall time: 23.1 ms
result['text']
<tf.Tensor: shape=(3,), dtype=string, numpy=
array([b'this is my life .', b'are you still at home ?',
b'all about killed .'], dtype=object)>
i = 0
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 1
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 2
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

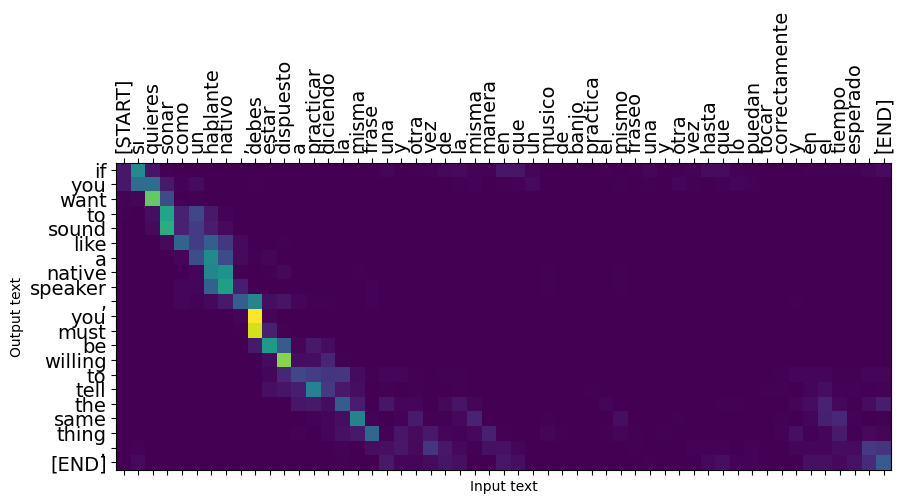
短い文はよく機能しますが、入力が長すぎると、モデルは文字通りフォーカスを失い、合理的な予測の提供を停止します。これには2つの主な理由があります。
- モデルは、モデルの予測に関係なく、各ステップで教師に強制的に正しいトークンを与えることでトレーニングされました。モデルに独自の予測が与えられることがあれば、モデルをより堅牢にすることができます。
- モデルは、RNN状態を介して以前の出力にのみアクセスできます。 RNN状態が破損した場合、モデルを回復する方法はありません。変圧器は、エンコーダとデコーダで自己の注意を使用してこれを解決します。
long_input_text = tf.constant([inp[-1]])
import textwrap
print('Expected output:\n', '\n'.join(textwrap.wrap(targ[-1])))
Expected output: If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
result = translator.tf_translate(long_input_text)
i = 0
plot_attention(result['attention'][i], long_input_text[i], result['text'][i])
_ = plt.suptitle('This never works')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
輸出
あなたはあなたがあなたに満足しているモデルを持っていたらとしてエクスポートすることもできますtf.saved_modelそれを作成し、このPythonプログラムの使用外のため。
モデルはのサブクラスであるので、 tf.Module (スルーkeras.Model )、および輸出のためのすべての機能がでコンパイルされtf.functionモデルができれいにエクスポートする必要がありtf.saved_model.save :
今の機能は、それが使用してエクスポートすることができますトレースされていることをsaved_model.save :
tf.saved_model.save(translator, 'translator',
signatures={'serving_default': translator.tf_translate})
2021-12-04 12:27:54.310890: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as encoder_2_layer_call_fn, encoder_2_layer_call_and_return_conditional_losses, decoder_2_layer_call_fn, decoder_2_layer_call_and_return_conditional_losses, embedding_4_layer_call_fn while saving (showing 5 of 60). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: translator/assets INFO:tensorflow:Assets written to: translator/assets
reloaded = tf.saved_model.load('translator')
result = reloaded.tf_translate(three_input_text)
%%time
result = reloaded.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? find out about to find out . CPU times: user 42.8 ms, sys: 7.69 ms, total: 50.5 ms Wall time: 20 ms
次のステップ
- 異なるデータセットをダウンロードフランス語にドイツ語、または英語に、例えば、翻訳して実験に英語を。
- より大きなデータセットでトレーニングするか、より多くのエポックを使用してみてください。
- 試しトランスチュートリアル類似した翻訳タスクを実装していますが、代わりのRNNのトランスレイヤーを使用しています。このバージョンでは、また、使用しています
text.BertTokenizerwordpieceのトークン化を実装します。 - 見ていtensorflow_addons.seq2seqシーケンスモデルにシーケンスのこの種を実装するために。
tfa.seq2seqパッケージのような高いレベルの機能が含まseq2seq.BeamSearchDecoder。