TensorFlow 用のテキスト処理ツール
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
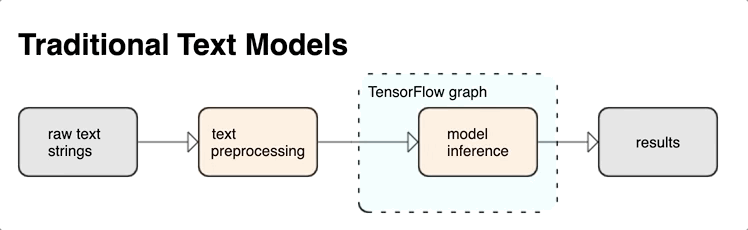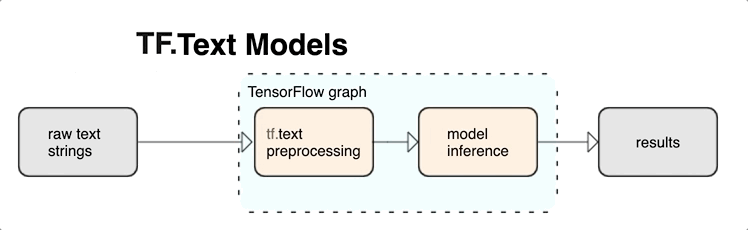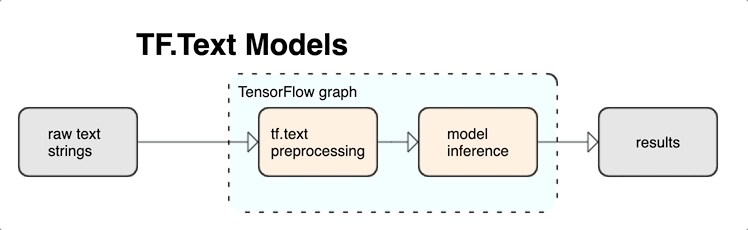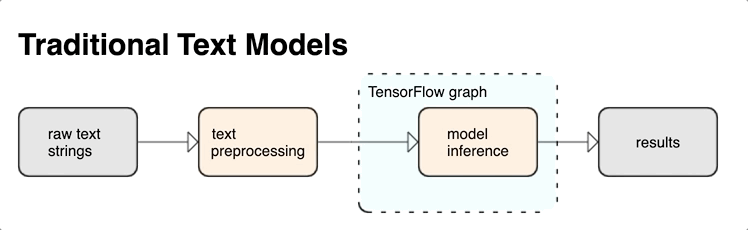
TensorFlow には、未加工のテキスト文字列や文書など、テキスト形式の入力を処理するための豊富なオペレーションやライブラリが用意されています。これらのライブラリでは、テキストベースのモデルで定期的に必要とされる前処理を行うことができ、シーケンス モデリングに有用なその他の機能も含まれています。
TensorFlow グラフの内部から強力な構文的および意味的テキスト特徴を抽出し、これらの特徴をニューラル ネットワークへの入力として使用することができます。
前処理を TensorFlow のグラフと統合することで、次のようなメリットがあります。
- 大規模なツールキットを使ったテキストの処理が容易になる
- 豊富な TensorFlow ツールとの統合を可能にして、問題定義、トレーニング、評価、リリースなどのプロジェクトをサポートする
- サービス提供時の複雑さを軽減し、トレーニング/サービング スキューを防ぐ
上記以外でも、トレーニング時のトークン化と推論時のトークン化を分けることや、前処理スクリプトを管理することなどについて心配する必要はありません。