
Aperçu
Aperçu
Ce didacticiel est conçu pour vous aider à apprendre à créer vos propres pipelines de machine learning en utilisant TensorFlow Extended (TFX) et Apache Airflow comme orchestrateur. Il s'exécute sur Vertex AI Workbench et montre l'intégration avec TFX et TensorBoard ainsi que l'interaction avec TFX dans un environnement Jupyter Lab.
Que vas-tu faire ?
Vous apprendrez à créer un pipeline ML à l'aide de TFX
- Un pipeline TFX est un graphique acyclique dirigé, ou « DAG ». Nous appellerons souvent les pipelines des DAG.
- Les pipelines TFX sont appropriés lorsque vous déployez une application ML de production
- Les pipelines TFX sont appropriés lorsque les ensembles de données sont volumineux ou peuvent devenir volumineux
- Les pipelines TFX sont appropriés lorsque la cohérence de la formation/du service est importante
- Les pipelines TFX sont appropriés lorsque la gestion des versions pour l'inférence est importante
- Google utilise les pipelines TFX pour le ML de production
Veuillez consulter le guide de l'utilisateur TFX pour en savoir plus.
Vous suivrez un processus de développement ML typique :
- Ingestion, compréhension et nettoyage de nos données
- Ingénierie des fonctionnalités
- Entraînement
- Analyse des performances du modèle
- Faire mousser, rincer, répéter
- Prêt pour la production
Apache Airflow pour l'orchestration de pipelines
Les orchestrateurs TFX sont responsables de la planification des composants du pipeline TFX en fonction des dépendances définies par le pipeline. TFX est conçu pour être portable sur plusieurs environnements et frameworks d'orchestration. L'un des orchestrateurs par défaut pris en charge par TFX est Apache Airflow . Cet atelier illustre l'utilisation d'Apache Airflow pour l'orchestration de pipeline TFX. Apache Airflow est une plate-forme permettant de créer, planifier et surveiller des flux de travail par programmation. TFX utilise Airflow pour créer des flux de travail sous forme de graphiques acycliques dirigés (DAG) de tâches. L'interface utilisateur riche facilite la visualisation des pipelines exécutés en production, le suivi de la progression et le dépannage des problèmes en cas de besoin. Les workflows Apache Airflow sont définis sous forme de code. Cela les rend plus maintenables, versionnables, testables et collaboratifs. Apache Airflow est adapté aux pipelines de traitement par lots. Il est léger et facile à apprendre.
Dans cet exemple, nous allons exécuter un pipeline TFX sur une instance en configurant manuellement Airflow.
Les autres orchestrateurs par défaut pris en charge par TFX sont Apache Beam et Kubeflow. Apache Beam peut s'exécuter sur plusieurs backends de traitement de données (Beam Ruunners). Cloud Dataflow est l'un de ces Beam Runner qui peut être utilisé pour exécuter des pipelines TFX. Apache Beam peut être utilisé à la fois pour les pipelines de streaming et de traitement par lots.
Kubeflow est une plateforme ML open source dédiée à rendre les déploiements de workflows d'apprentissage automatique (ML) sur Kubernetes simples, portables et évolutifs. Kubeflow peut être utilisé comme orchestrateur pour les pipelines TFFX lorsqu'ils doivent être déployés sur des clusters Kubernetes. De plus, vous pouvez également utiliser votre propre orchestrateur personnalisé pour exécuter un pipeline TFX.
En savoir plus sur Airflow ici .
Ensemble de données sur les taxis de Chicago


Vous utiliserez l' ensemble de données Taxi Trips publié par la ville de Chicago.
Objectif du modèle - Classification binaire
Le client donnera-t-il un pourboire supérieur ou inférieur à 20 % ?
Configurer le projet Google Cloud
Avant de cliquer sur le bouton Démarrer le laboratoire, lisez ces instructions. Les ateliers sont chronométrés et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier , indique la durée pendant laquelle les ressources Google Cloud seront mises à votre disposition.
Cet atelier pratique vous permet d'effectuer vous-même les activités de laboratoire dans un environnement cloud réel, et non dans un environnement de simulation ou de démonstration. Pour ce faire, il vous fournit de nouveaux identifiants temporaires que vous utilisez pour vous connecter et accéder à Google Cloud pendant toute la durée de l'atelier.
Ce dont vous avez besoin Pour réaliser cet atelier, vous avez besoin :
- Accès à un navigateur Internet standard (navigateur Chrome recommandé).
- Il est temps de terminer le laboratoire.
Comment démarrer votre atelier et vous connecter à Google Cloud Console 1. Cliquez sur le bouton Démarrer l'atelier . Si vous devez payer pour le laboratoire, une fenêtre contextuelle s'ouvre pour vous permettre de sélectionner votre mode de paiement. Sur la gauche se trouve un panneau contenant les informations d'identification temporaires que vous devez utiliser pour cet atelier.
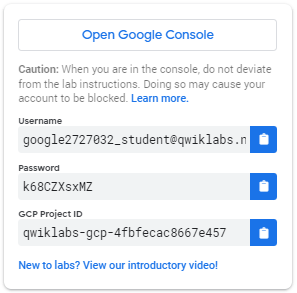
- Copiez le nom d'utilisateur, puis cliquez sur Ouvrir la console Google . Le laboratoire fait tourner les ressources, puis ouvre un autre onglet qui affiche la page de connexion .
Astuce : ouvrez les onglets dans des fenêtres distinctes, côte à côte.
- Sur la page de connexion , collez le nom d'utilisateur que vous avez copié dans le panneau de gauche. Copiez et collez ensuite le mot de passe.
- Cliquez sur les pages suivantes :
- Acceptez les termes et conditions.
N'ajoutez pas d'options de récupération ou d'authentification à deux facteurs (car il s'agit d'un compte temporaire).
Ne vous inscrivez pas pour des essais gratuits.
Après quelques instants, Cloud Console s'ouvre dans cet onglet.
Activer Cloud Shell
Cloud Shell est une machine virtuelle dotée d'outils de développement. Il offre un répertoire personnel persistant de 5 Go et fonctionne sur Google Cloud. Cloud Shell fournit un accès en ligne de commande à vos ressources Google Cloud.
Dans Cloud Console, dans la barre d'outils supérieure droite, cliquez sur le bouton Activer Cloud Shell .
Cliquez sur Continuer .
L'approvisionnement et la connexion à l'environnement prennent quelques instants. Lorsque vous êtes connecté, vous êtes déjà authentifié et le projet est défini sur votre _PROJECT ID . Par exemple:

gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et prend en charge la complétion par tabulation.
Vous pouvez lister le nom du compte actif avec cette commande :
gcloud auth list
(Sortir)
ACTIF : * COMPTE : student-01-xxxxxxxxxxxx@qwiklabs.net Pour définir le compte actif, exécutez : $ gcloud config set account
ACCOUNT
Vous pouvez lister l'ID du projet avec cette commande : gcloud config list project (Output)
projet [de base] =
(Exemple de sortie)
Projet [noyau] = qwiklabs-gcp-44776a13dea667a6
Pour une documentation complète sur gcloud, consultez la présentation de l'outil de ligne de commande gcloud .
Activer les services Google Cloud
- Dans Cloud Shell, utilisez gcloud pour activer les services utilisés dans l'atelier.
gcloud services enable notebooks.googleapis.com
Déployer une instance de Vertex Notebook
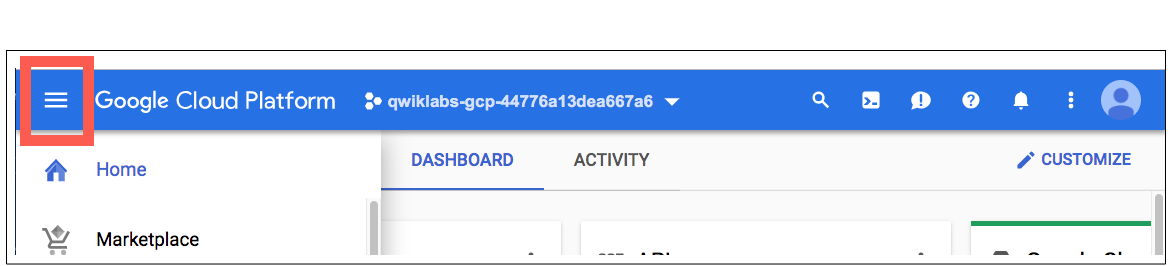
- Cliquez sur le menu de navigation et accédez à Vertex AI , puis à Workbench .
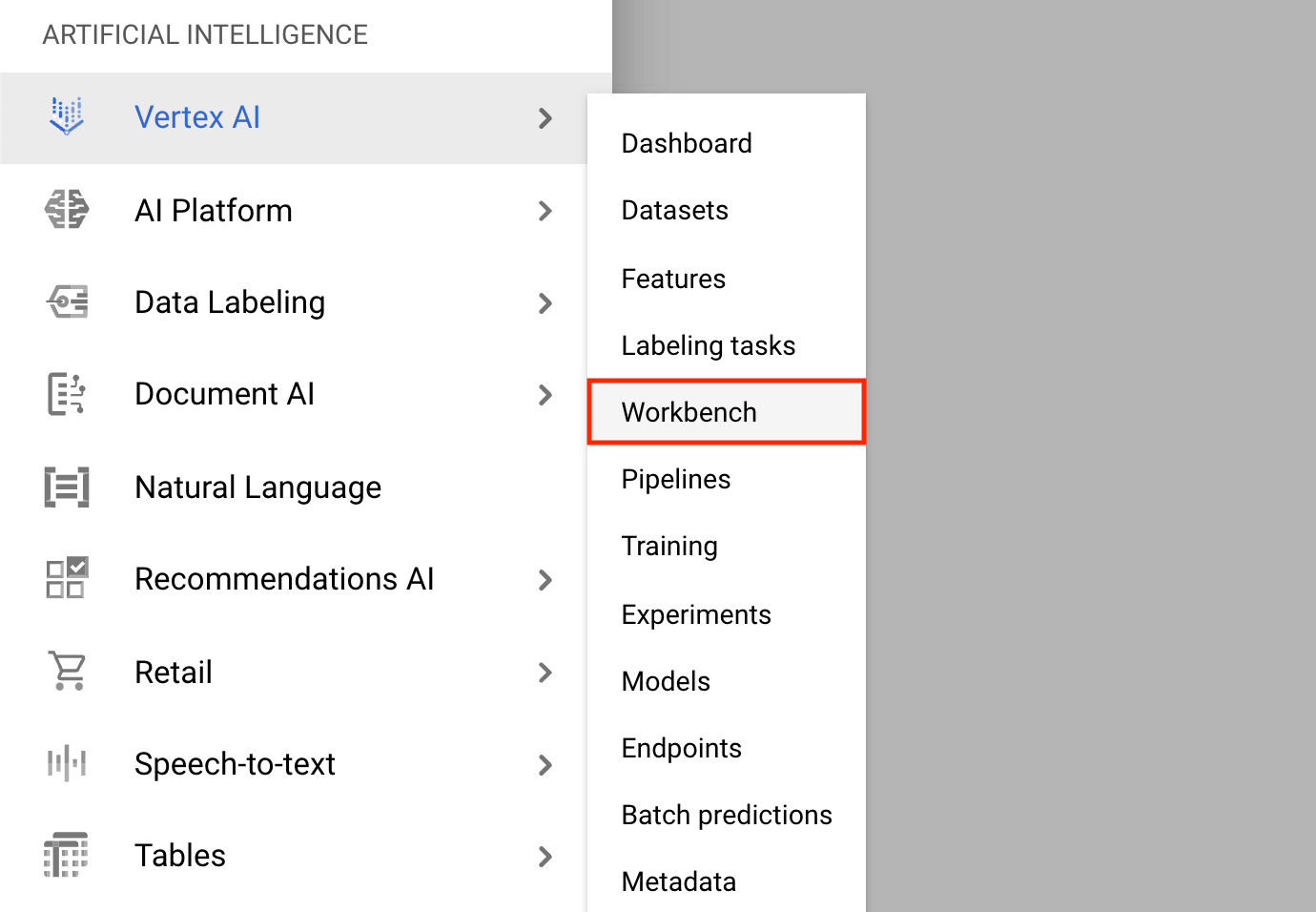
Sur la page Instances de notebook, cliquez sur Nouveau notebook .
Dans le menu Personnaliser l'instance, sélectionnez TensorFlow Enterprise et choisissez la version de TensorFlow Enterprise 2.x (avec LTS) > Sans GPU .
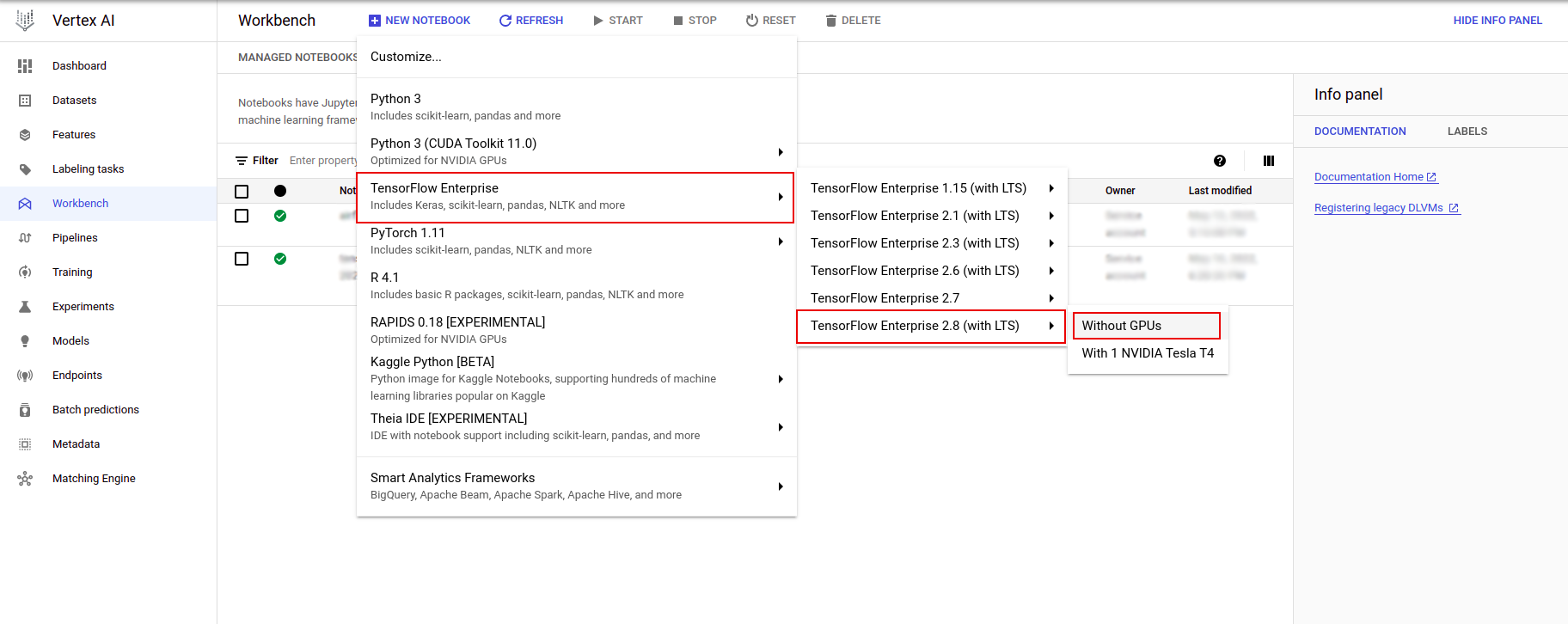
Dans la boîte de dialogue Nouvelle instance de bloc-notes , cliquez sur l'icône en forme de crayon pour modifier les propriétés de l'instance.
Pour Nom de l'instance , entrez un nom pour votre instance.
Pour Region , sélectionnez
us-east1et pour Zone , sélectionnez une zone dans la région sélectionnée.Faites défiler jusqu'à Configuration de la machine et sélectionnez e2-standard-2 pour Type de machine.
Laissez les champs restants avec leur valeur par défaut et cliquez sur Créer .
Après quelques minutes, la console Vertex AI affichera le nom de votre instance, suivi de Open Jupyterlab .
- Cliquez sur Ouvrir JupyterLab . Une fenêtre JupyterLab s'ouvrira dans un nouvel onglet.
Configurer l'environnement
Cloner le référentiel du laboratoire
Vous allez ensuite cloner le référentiel tfx dans votre instance JupyterLab. 1. Dans JupyterLab, cliquez sur l'icône Terminal pour ouvrir un nouveau terminal.
Cancel pour Build Recommandé.
- Pour cloner le référentiel
tfxGithub, tapez la commande suivante et appuyez sur Entrée .
git clone https://github.com/tensorflow/tfx.git
- Pour confirmer que vous avez cloné le référentiel, double-cliquez sur le répertoire
tfxet confirmez que vous pouvez voir son contenu.
Installer les dépendances de laboratoire
- Exécutez ce qui suit pour accéder au dossier
tfx/tfx/examples/airflow_workshop/taxi/setup/, puis exécutez./setup_demo.shpour installer les dépendances de laboratoire :
cd ~/tfx/tfx/examples/airflow_workshop/taxi/setup/
./setup_demo.sh
Le code ci-dessus sera
- Installez les packages requis.
- Créez un dossier
airflowdans le dossier de départ. - Copiez le dossier
dagsdutfx/tfx/examples/airflow_workshop/taxi/setup/vers le dossier~/airflow/. - Copiez le fichier csv de
tfx/tfx/examples/airflow_workshop/taxi/setup/datavers~/airflow/data.
Configuration du serveur Airflow
Créer une règle de pare-feu pour accéder au serveur Airflow dans le navigateur
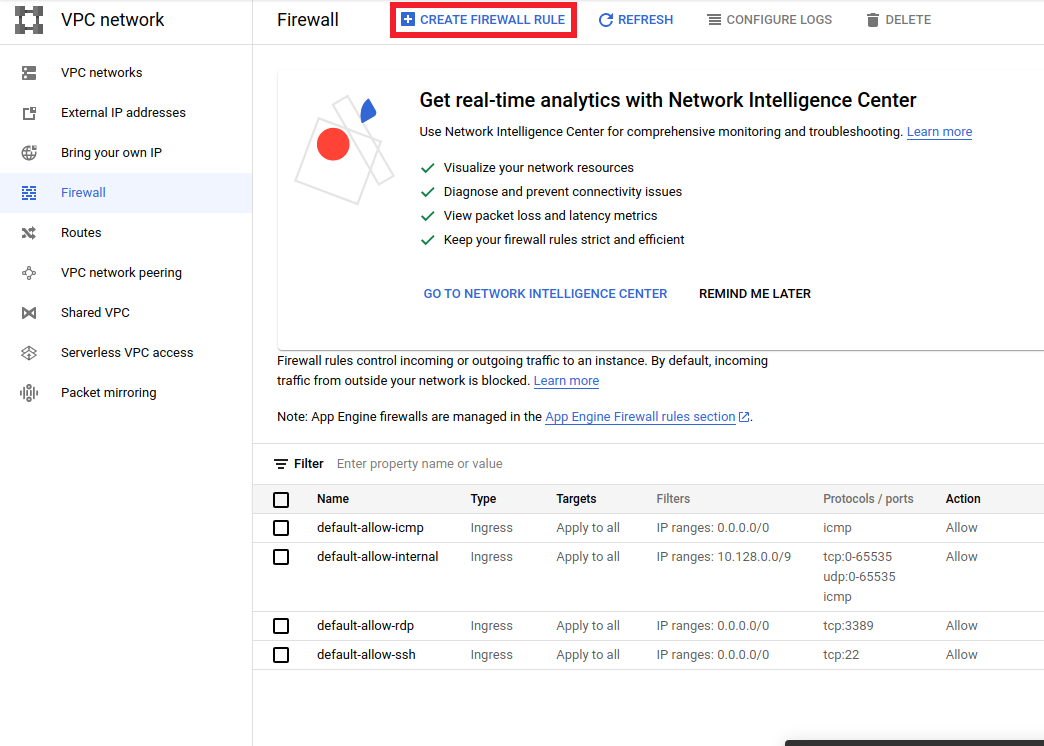
- Accédez à
<a href="https://console.cloud.google.com/networking/firewalls/list">https://console.cloud.google.com/networking/firewalls/list</a>et assurez-vous le nom du projet est sélectionné de manière appropriée - Cliquez sur l'option
CREATE FIREWALL RULEen haut
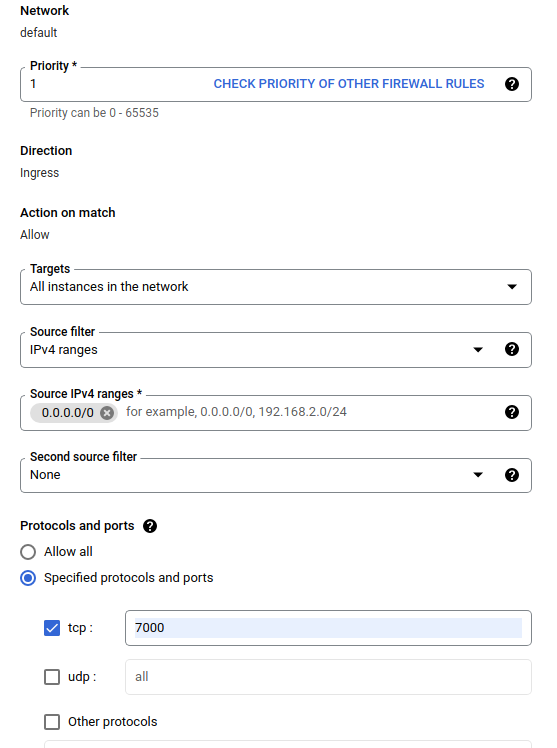
Dans la boîte de dialogue Créer un pare-feu , suivez les étapes répertoriées ci-dessous.
- Pour Name , mettez
airflow-tfx. - Pour Priorité , sélectionnez
1. - Pour Cibles , sélectionnez
All instances in the network. - Pour les plages IPv4 sources , sélectionnez
0.0.0.0/0 - Pour Protocoles et ports , cliquez sur
tcpet entrez7000dans la case à côté detcp - Cliquez sur
Create.
Exécutez le serveur Airflow à partir de votre shell
Dans la fenêtre Jupyter Lab Terminal, accédez au répertoire personnel, exécutez la commande airflow users create pour créer un utilisateur administrateur pour Airflow :
cd
airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin
Exécutez ensuite la commande airflow webserver et airflow scheduler pour exécuter le serveur. Choisissez le port 7000 car il est autorisé via le pare-feu.
nohup airflow webserver -p 7000 &> webserver.out &
nohup airflow scheduler &> scheduler.out &
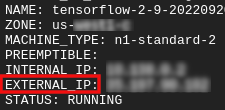
Obtenez votre adresse IP externe
- Dans Cloud Shell, utilisez
gcloudpour obtenir l'adresse IP externe.
gcloud compute instances list
Exécuter un DAG/Pipeline
Dans un navigateur
Ouvrez un navigateur et accédez à http://
- Dans la page de connexion, entrez le nom d'utilisateur (
admin) et le mot de passe (admin) que vous avez choisis lors de l'exécution de la commandeairflow users create.
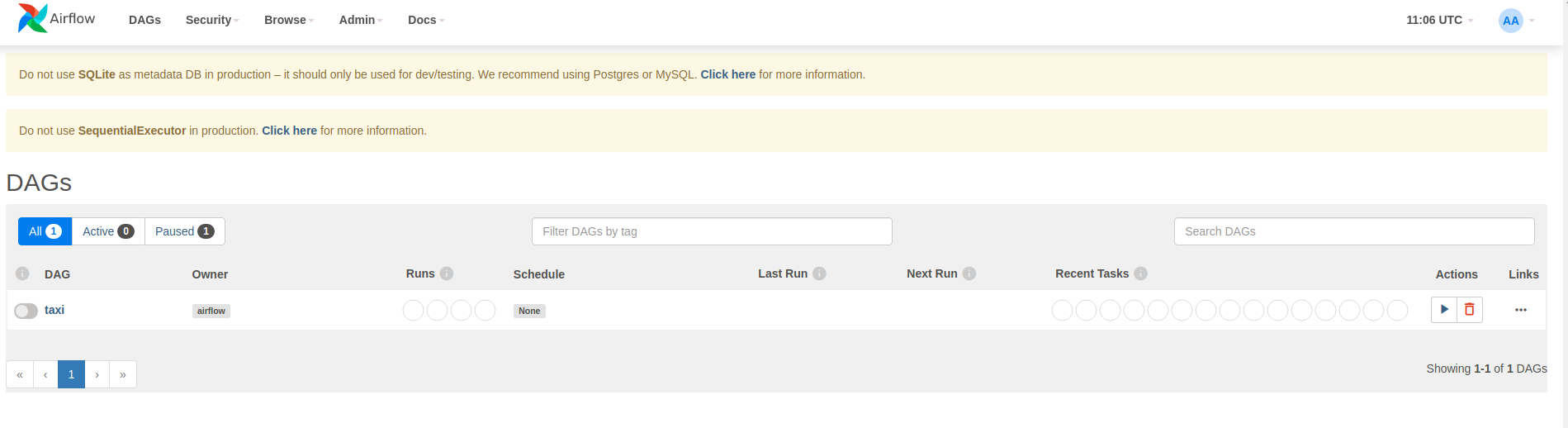
Airflow charge les DAG à partir des fichiers sources Python. Il prend chaque fichier et l'exécute. Ensuite, il charge tous les objets DAG de ce fichier. Tous les fichiers .py qui définissent les objets DAG seront répertoriés en tant que pipelines sur la page d'accueil d'Airflow.
Dans ce didacticiel, Airflow analyse le dossier ~/airflow/dags/ à la recherche d'objets DAG.
Si vous ouvrez ~/airflow/dags/taxi_pipeline.py et faites défiler vers le bas, vous pouvez voir qu'il crée et stocke un objet DAG dans une variable nommée DAG . Par conséquent, il sera répertorié en tant que pipeline sur la page d’accueil du flux d’air, comme indiqué ci-dessous :
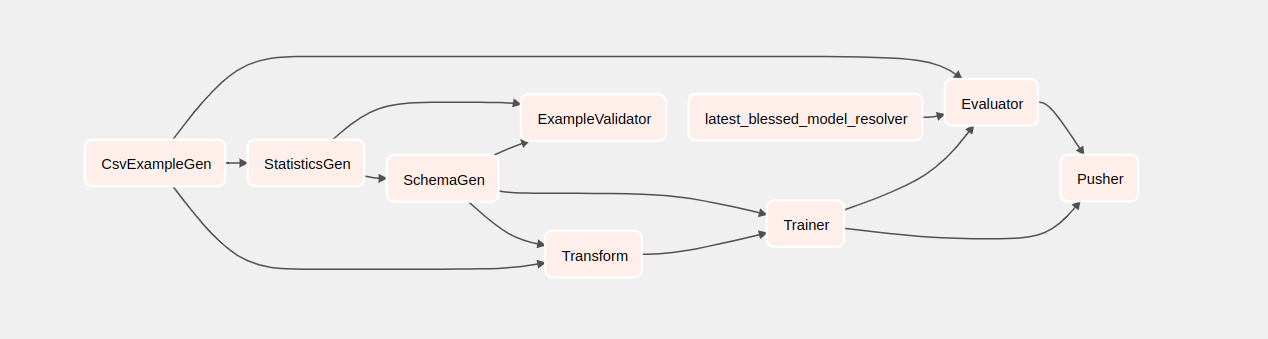
Si vous cliquez sur taxi, vous serez redirigé vers la vue grille du DAG. Vous pouvez cliquer sur l'option Graph en haut pour obtenir la vue graphique du DAG.
Déclenchez le pipeline de taxis
Sur la page d'accueil, vous pouvez voir les boutons qui peuvent être utilisés pour interagir avec le DAG.
Sous l'en-tête des actions , cliquez sur le bouton de déclenchement pour déclencher le pipeline.
Dans la page Taxi DAG , utilisez le bouton de droite pour actualiser l’état de la vue graphique du DAG pendant l’exécution du pipeline. De plus, vous pouvez activer l'actualisation automatique pour demander à Airflow d'actualiser automatiquement la vue graphique au fur et à mesure que l'état change.
Vous pouvez également utiliser l' Airflow CLI dans le terminal pour activer et déclencher vos DAG :
# enable/disable
airflow pause <your DAG name>
airflow unpause <your DAG name>
# trigger
airflow trigger_dag <your DAG name>
En attente de la fin du pipeline
Après avoir déclenché votre pipeline, dans la vue DAG, vous pouvez suivre la progression de votre pipeline pendant son exécution. Au fur et à mesure de l'exécution de chaque composant, la couleur du contour du composant dans le graphique DAG change pour afficher son état. Lorsqu'un composant a terminé le traitement, le contour devient vert foncé pour indiquer que c'est terminé.
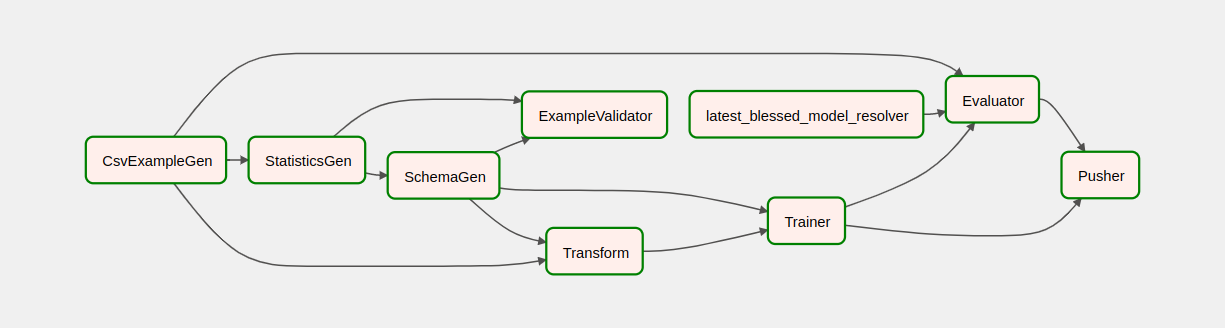
Comprendre les composants
Nous allons maintenant examiner les composants de ce pipeline en détail et examiner individuellement les résultats produits par chaque étape du pipeline.
Dans JupyterLab, accédez à
~/tfx/tfx/examples/airflow_workshop/taxi/notebooks/Ouvrez notebook.ipynb.

Poursuivez l'atelier dans le bloc-notes et exécutez chaque cellule en cliquant sur le bouton Exécuter (
 ) en haut de l'écran. Alternativement, vous pouvez exécuter le code dans une cellule avec SHIFT + ENTER .
) en haut de l'écran. Alternativement, vous pouvez exécuter le code dans une cellule avec SHIFT + ENTER .
Lisez le récit et assurez-vous de comprendre ce qui se passe dans chaque cellule.