
Copyright 2021 Los autores de TF-Agents.
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Introducción
Este ejemplo muestra cómo entrenar a un (Deep Q Redes) DQN agente en el medio ambiente Cartpole usando la biblioteca TF-Agentes.

Lo guiará a través de todos los componentes de un proceso de aprendizaje reforzado (RL) para la capacitación, la evaluación y la recopilación de datos.
Para ejecutar este código en vivo, haga clic en el enlace 'Ejecutar en Google Colab' arriba.
Configuración
Si no ha instalado las siguientes dependencias, ejecute:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet
from __future__ import absolute_import, division, print_function
import base64
import imageio
import IPython
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.dqn import dqn_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.eval import metric_utils
from tf_agents.metrics import tf_metrics
from tf_agents.networks import sequential
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_tf_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.trajectories import trajectory
from tf_agents.specs import tensor_spec
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
tf.version.VERSION
'2.6.0'
Hiperparámetros
num_iterations = 20000 # @param {type:"integer"}
initial_collect_steps = 100 # @param {type:"integer"}
collect_steps_per_iteration = 1# @param {type:"integer"}
replay_buffer_max_length = 100000 # @param {type:"integer"}
batch_size = 64 # @param {type:"integer"}
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 200 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 1000 # @param {type:"integer"}
Medio ambiente
En el aprendizaje por refuerzo (RL), un entorno representa la tarea o problema a resolver. Entornos estándar se pueden crear en la carretera TF-Agentes utilizando tf_agents.environments suites. TF-Agents tiene suites para cargar entornos de fuentes como OpenAI Gym, Atari y DM Control.
Cargue el entorno CartPole desde la suite OpenAI Gym.
env_name = 'CartPole-v0'
env = suite_gym.load(env_name)
Puede renderizar este entorno para ver cómo se ve. Un poste de oscilación libre está sujeto a un carro. El objetivo es mover el carro hacia la derecha o hacia la izquierda para mantener el poste apuntando hacia arriba.
env.reset()
PIL.Image.fromarray(env.render())
El environment.step método toma una action en el medio ambiente y devuelve un TimeStep tupla que contiene la siguiente observación del entorno y la recompensa de la acción.
El time_step_spec() método devuelve la especificación para el TimeStep tupla. Sus observation de atributos muestra la forma de observaciones, los tipos de datos, y los rangos de valores permitidos. La reward atributo muestra los mismos detalles para la recompensa.
print('Observation Spec:')
print(env.time_step_spec().observation)
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
print('Reward Spec:')
print(env.time_step_spec().reward)
Reward Spec:
ArraySpec(shape=(), dtype=dtype('float32'), name='reward')
El action_spec() método devuelve la forma, tipos de datos y valores permitidos de acciones válidas.
print('Action Spec:')
print(env.action_spec())
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
En el entorno de Cartpole:
-
observationes una matriz de 4 flotadores:- la posición y velocidad del carro
- la posición angular y la velocidad del polo
-
rewardes un valor flotante escalar -
actiones un número entero escalar con sólo dos valores posibles:-
0- "mover hacia la izquierda" -
1- "decisión correcta"
-
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([-0.02109759, -0.00062286, 0.04167245, -0.03825747], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([-0.02111005, 0.1938775 , 0.0409073 , -0.31750655], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
Por lo general, se crean instancias de dos entornos: uno para entrenamiento y otro para evaluación.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
El entorno Cartpole, como la mayoría de los entornos, está escrito en Python puro. Esta se convierte en TensorFlow usando el TFPyEnvironment envoltura.
La API del entorno original utiliza matrices Numpy. Los TFPyEnvironment convertidos a estos Tensors para que sea compatible con los agentes y políticas Tensorflow.
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
Agente
El algoritmo utilizado para resolver un problema de RL está representado por un Agent . TF-Agentes proporciona implementaciones estándar de una variedad de Agents , que incluyen:
El agente DQN se puede utilizar en cualquier entorno que tenga un espacio de acción discreto.
En el corazón de un agente DQN es un QNetwork , un modelo de red neuronal que se puede aprender a predecir QValues (retornos esperados) para todas las acciones, teniendo en cuenta una observación del entorno.
Vamos a utilizar tf_agents.networks. para crear un QNetwork . La red consistirá en una secuencia de tf.keras.layers.Dense capas, donde la capa final tendrá 1 de salida para cada acción posible.
fc_layer_params = (100, 50)
action_tensor_spec = tensor_spec.from_spec(env.action_spec())
num_actions = action_tensor_spec.maximum - action_tensor_spec.minimum + 1
# Define a helper function to create Dense layers configured with the right
# activation and kernel initializer.
def dense_layer(num_units):
return tf.keras.layers.Dense(
num_units,
activation=tf.keras.activations.relu,
kernel_initializer=tf.keras.initializers.VarianceScaling(
scale=2.0, mode='fan_in', distribution='truncated_normal'))
# QNetwork consists of a sequence of Dense layers followed by a dense layer
# with `num_actions` units to generate one q_value per available action as
# its output.
dense_layers = [dense_layer(num_units) for num_units in fc_layer_params]
q_values_layer = tf.keras.layers.Dense(
num_actions,
activation=None,
kernel_initializer=tf.keras.initializers.RandomUniform(
minval=-0.03, maxval=0.03),
bias_initializer=tf.keras.initializers.Constant(-0.2))
q_net = sequential.Sequential(dense_layers + [q_values_layer])
Ahora usa tf_agents.agents.dqn.dqn_agent a instancias de un DqnAgent . Además de la time_step_spec , action_spec y la QNetwork, el constructor agente también requiere un optimizador (en este caso, AdamOptimizer ), una función de pérdida, y un contador de paso entero.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
agent = dqn_agent.DqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
q_network=q_net,
optimizer=optimizer,
td_errors_loss_fn=common.element_wise_squared_loss,
train_step_counter=train_step_counter)
agent.initialize()
Políticas
Una política define la forma en que un agente actúa en un entorno. Normalmente, el objetivo del aprendizaje por refuerzo es entrenar el modelo subyacente hasta que la política produzca el resultado deseado.
En este tutorial:
- El resultado deseado es mantener el poste en equilibrio sobre el carro.
- La política devuelve una acción (izquierda o derecha) para cada
time_stepobservación.
Los agentes contienen dos políticas:
-
agent.policy- La principal política que se utiliza para la evaluación y la implementación. -
agent.collect_policy- Una segunda política que se utiliza para la recolección de datos.
eval_policy = agent.policy
collect_policy = agent.collect_policy
Las políticas se pueden crear independientemente de los agentes. Por ejemplo, utilice tf_agents.policies.random_tf_policy para crear una política que seleccionará al azar una acción para cada time_step .
random_policy = random_tf_policy.RandomTFPolicy(train_env.time_step_spec(),
train_env.action_spec())
Para conseguir una acción de una política, llame al policy.action(time_step) método. El time_step contiene la observación del entorno. Este método devuelve un PolicyStep , que es una tupla llamada con tres componentes:
-
action- la acción a tomar (en este caso,0o1) -
state- se utiliza para las políticas de estado (es decir, RNN-based) -
info- datos auxiliares, tales como las probabilidades de registro de acciones
example_environment = tf_py_environment.TFPyEnvironment(
suite_gym.load('CartPole-v0'))
time_step = example_environment.reset()
random_policy.action(time_step)
PolicyStep(action=<tf.Tensor: shape=(1,), dtype=int64, numpy=array([1])>, state=(), info=())
Métricas y evaluación
La métrica más común utilizada para evaluar una póliza es el rendimiento promedio. La devolución es la suma de las recompensas obtenidas al ejecutar una política en un entorno para un episodio. Se ejecutan varios episodios, lo que genera un rendimiento medio.
La siguiente función calcula el rendimiento promedio de una política, dados la política, el entorno y una serie de episodios.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# See also the metrics module for standard implementations of different metrics.
# https://github.com/tensorflow/agents/tree/master/tf_agents/metrics
La ejecución de este cálculo en la random_policy muestra un rendimiento de referencia en el entorno.
compute_avg_return(eval_env, random_policy, num_eval_episodes)
20.7
Búfer de reproducción
Con el fin de realizar un seguimiento de los datos recogidos en el medio ambiente, vamos a utilizar reverberación , un sistema de repetición eficiente, extensible y fácil de usar por Deepmind. Almacena datos de experiencia cuando recopilamos trayectorias y se consume durante el entrenamiento.
Este búfer de reproducción se construye utilizando especificaciones que describen los tensores que se almacenarán, que se pueden obtener del agente mediante agent.collect_data_spec.
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_max_length,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
agent.collect_data_spec,
table_name=table_name,
sequence_length=2,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
replay_buffer.py_client,
table_name,
sequence_length=2)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpcz7e0i7c. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpcz7e0i7c [reverb/cc/platform/default/server.cc:71] Started replay server on port 21909
Para la mayoría de los agentes, collect_data_spec es una tupla con nombre denominada Trajectory , que contiene las especificaciones para las observaciones, acciones, recompensas y otros artículos.
agent.collect_data_spec
Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int64, name='action', minimum=array(0), maximum=array(1)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': BoundedTensorSpec(shape=(4,), dtype=tf.float32, name='observation', minimum=array([-4.8000002e+00, -3.4028235e+38, -4.1887903e-01, -3.4028235e+38],
dtype=float32), maximum=array([4.8000002e+00, 3.4028235e+38, 4.1887903e-01, 3.4028235e+38],
dtype=float32)),
'policy_info': (),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
agent.collect_data_spec._fields
('step_type',
'observation',
'action',
'policy_info',
'next_step_type',
'reward',
'discount')
Recopilación de datos
Ahora ejecute la política aleatoria en el entorno durante algunos pasos, registrando los datos en el búfer de reproducción.
Aquí estamos usando 'PyDriver' para ejecutar el ciclo de recolección de experiencias. Usted puede aprender más acerca controlador Agentes TF en nuestro tutorial de los conductores .
py_driver.PyDriver(
env,
py_tf_eager_policy.PyTFEagerPolicy(
random_policy, use_tf_function=True),
[rb_observer],
max_steps=initial_collect_steps).run(train_py_env.reset())
(TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.04100575, 0.16847703, -0.12718087, -0.6300714 ], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)}),
())
El búfer de reproducción ahora es una colección de trayectorias.
# For the curious:
# Uncomment to peel one of these off and inspect it.
# iter(replay_buffer.as_dataset()).next()
El agente necesita acceso al búfer de reproducción. Esto se proporciona mediante la creación de un iterable tf.data.Dataset tubería que alimentarán datos al agente.
Cada fila del búfer de reproducción solo almacena un único paso de observación. Pero dado que el agente DQN necesita tanto la observación actual y la siguiente para calcular la pérdida, la tubería conjunto de datos se muestra dos filas adyacentes de cada elemento en el lote ( num_steps=2 ).
Este conjunto de datos también se optimiza mediante la ejecución de llamadas paralelas y la obtención previa de datos.
# Dataset generates trajectories with shape [Bx2x...]
dataset = replay_buffer.as_dataset(
num_parallel_calls=3,
sample_batch_size=batch_size,
num_steps=2).prefetch(3)
dataset
<PrefetchDataset shapes: (Trajectory(
{action: (64, 2),
discount: (64, 2),
next_step_type: (64, 2),
observation: (64, 2, 4),
policy_info: (),
reward: (64, 2),
step_type: (64, 2)}), SampleInfo(key=(64, 2), probability=(64, 2), table_size=(64, 2), priority=(64, 2))), types: (Trajectory(
{action: tf.int64,
discount: tf.float32,
next_step_type: tf.int32,
observation: tf.float32,
policy_info: (),
reward: tf.float32,
step_type: tf.int32}), SampleInfo(key=tf.uint64, probability=tf.float64, table_size=tf.int64, priority=tf.float64))>
iterator = iter(dataset)
print(iterator)
<tensorflow.python.data.ops.iterator_ops.OwnedIterator object at 0x7f3cec38cd90>
# For the curious:
# Uncomment to see what the dataset iterator is feeding to the agent.
# Compare this representation of replay data
# to the collection of individual trajectories shown earlier.
# iterator.next()
Entrenando al agente
Deben suceder dos cosas durante el ciclo de entrenamiento:
- recopilar datos del medio ambiente
- usar esos datos para entrenar las redes neuronales del agente
Este ejemplo también evalúa periódicamente la política e imprime la puntuación actual.
Lo siguiente tardará ~ 5 minutos en ejecutarse.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
agent.train = common.function(agent.train)
# Reset the train step.
agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
returns = [avg_return]
# Reset the environment.
time_step = train_py_env.reset()
# Create a driver to collect experience.
collect_driver = py_driver.PyDriver(
env,
py_tf_eager_policy.PyTFEagerPolicy(
agent.collect_policy, use_tf_function=True),
[rb_observer],
max_steps=collect_steps_per_iteration)
for _ in range(num_iterations):
# Collect a few steps and save to the replay buffer.
time_step, _ = collect_driver.run(time_step)
# Sample a batch of data from the buffer and update the agent's network.
experience, unused_info = next(iterator)
train_loss = agent.train(experience).loss
step = agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/util/dispatch.py:206: calling foldr_v2 (from tensorflow.python.ops.functional_ops) with back_prop=False is deprecated and will be removed in a future version. Instructions for updating: back_prop=False is deprecated. Consider using tf.stop_gradient instead. Instead of: results = tf.foldr(fn, elems, back_prop=False) Use: results = tf.nest.map_structure(tf.stop_gradient, tf.foldr(fn, elems)) [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. step = 200: loss = 27.080341339111328 step = 400: loss = 3.0314550399780273 step = 600: loss = 470.9187927246094 step = 800: loss = 548.7870483398438 step = 1000: loss = 4315.17578125 step = 1000: Average Return = 48.400001525878906 step = 1200: loss = 5297.24853515625 step = 1400: loss = 11601.296875 step = 1600: loss = 60482.578125 step = 1800: loss = 802764.8125 step = 2000: loss = 1689283.0 step = 2000: Average Return = 63.400001525878906 step = 2200: loss = 4928921.0 step = 2400: loss = 5508345.0 step = 2600: loss = 17888162.0 step = 2800: loss = 23993148.0 step = 3000: loss = 10192765.0 step = 3000: Average Return = 74.0999984741211 step = 3200: loss = 88318176.0 step = 3400: loss = 77485728.0 step = 3600: loss = 3236693504.0 step = 3800: loss = 102289840.0 step = 4000: loss = 168594496.0 step = 4000: Average Return = 73.5999984741211 step = 4200: loss = 348990528.0 step = 4400: loss = 101819664.0 step = 4600: loss = 136486208.0 step = 4800: loss = 133454864.0 step = 5000: loss = 592934784.0 step = 5000: Average Return = 71.5999984741211 step = 5200: loss = 216909120.0 step = 5400: loss = 181369648.0 step = 5600: loss = 600455680.0 step = 5800: loss = 551183744.0 step = 6000: loss = 368749824.0 step = 6000: Average Return = 83.5 step = 6200: loss = 1010418176.0 step = 6400: loss = 171257856.0 step = 6600: loss = 115424904.0 step = 6800: loss = 144941152.0 step = 7000: loss = 257932752.0 step = 7000: Average Return = 107.0 step = 7200: loss = 854109248.0 step = 7400: loss = 95970128.0 step = 7600: loss = 325583744.0 step = 7800: loss = 858134016.0 step = 8000: loss = 197960128.0 step = 8000: Average Return = 124.19999694824219 step = 8200: loss = 310187552.0 step = 8400: loss = 572293760.0 step = 8600: loss = 2338323456.0 step = 8800: loss = 384659392.0 step = 9000: loss = 676924544.0 step = 9000: Average Return = 200.0 step = 9200: loss = 946199168.0 step = 9400: loss = 605189504.0 step = 9600: loss = 768988928.0 step = 9800: loss = 508231776.0 step = 10000: loss = 526518016.0 step = 10000: Average Return = 200.0 step = 10200: loss = 1461528704.0 step = 10400: loss = 709822016.0 step = 10600: loss = 2770553344.0 step = 10800: loss = 496421504.0 step = 11000: loss = 1822116864.0 step = 11000: Average Return = 200.0 step = 11200: loss = 744854208.0 step = 11400: loss = 778800384.0 step = 11600: loss = 667049216.0 step = 11800: loss = 586587648.0 step = 12000: loss = 2586833920.0 step = 12000: Average Return = 200.0 step = 12200: loss = 1002041472.0 step = 12400: loss = 1526919552.0 step = 12600: loss = 1670877056.0 step = 12800: loss = 1857608704.0 step = 13000: loss = 1040727936.0 step = 13000: Average Return = 200.0 step = 13200: loss = 1807798656.0 step = 13400: loss = 1457996544.0 step = 13600: loss = 1322671616.0 step = 13800: loss = 22940983296.0 step = 14000: loss = 1556422912.0 step = 14000: Average Return = 200.0 step = 14200: loss = 2488473600.0 step = 14400: loss = 46558289920.0 step = 14600: loss = 1958968960.0 step = 14800: loss = 4677744640.0 step = 15000: loss = 1648418304.0 step = 15000: Average Return = 200.0 step = 15200: loss = 46132723712.0 step = 15400: loss = 2189093888.0 step = 15600: loss = 1204941056.0 step = 15800: loss = 1578462080.0 step = 16000: loss = 1695949312.0 step = 16000: Average Return = 200.0 step = 16200: loss = 19554553856.0 step = 16400: loss = 2857277184.0 step = 16600: loss = 5782225408.0 step = 16800: loss = 2294467072.0 step = 17000: loss = 2397877248.0 step = 17000: Average Return = 200.0 step = 17200: loss = 2910329088.0 step = 17400: loss = 6317301760.0 step = 17600: loss = 2733602048.0 step = 17800: loss = 32502740992.0 step = 18000: loss = 6295858688.0 step = 18000: Average Return = 200.0 step = 18200: loss = 2564860160.0 step = 18400: loss = 76450430976.0 step = 18600: loss = 6347636736.0 step = 18800: loss = 6258629632.0 step = 19000: loss = 8091572224.0 step = 19000: Average Return = 200.0 step = 19200: loss = 3860335616.0 step = 19400: loss = 3552561152.0 step = 19600: loss = 4175943424.0 step = 19800: loss = 5975838720.0 step = 20000: loss = 4709884928.0 step = 20000: Average Return = 200.0
Visualización
Parcelas
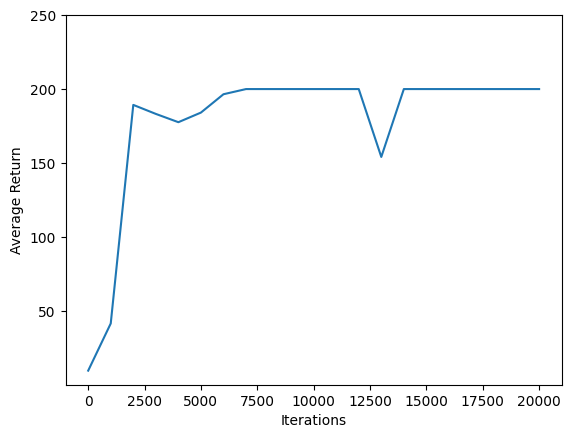
Uso matplotlib.pyplot para trazar cómo mejoró la política durante el entrenamiento.
Una iteración de Cartpole-v0 consiste en 200 pasos de tiempo. El entorno da una recompensa de +1 para cada paso de las estancias de polo hacia arriba, por lo que el rendimiento máximo para un episodio es 200. Los gráficos muestra la rentabilidad creciente hacia ese máximo cada vez que se evalúa durante el entrenamiento. (Puede ser un poco inestable y no aumentar monótonamente cada vez).
iterations = range(0, num_iterations + 1, eval_interval)
plt.plot(iterations, returns)
plt.ylabel('Average Return')
plt.xlabel('Iterations')
plt.ylim(top=250)
(40.82000160217285, 250.0)
Videos
Los gráficos son agradables. Pero lo más emocionante es ver a un agente realizando una tarea en un entorno.
Primero, cree una función para incrustar videos en el cuaderno.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Ahora repite algunos episodios del juego Cartpole con el agente. El entorno Python subyacente (el "dentro" del entorno envoltura TensorFlow) proporciona un render() método, que da salida a una imagen del estado medio ambiente. Estos se pueden recopilar en un video.
def create_policy_eval_video(policy, filename, num_episodes=5, fps=30):
filename = filename + ".mp4"
with imageio.get_writer(filename, fps=fps) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
return embed_mp4(filename)
create_policy_eval_video(agent.policy, "trained-agent")
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x55d99fdf83c0] Warning: data is not aligned! This can lead to a speed loss
Para divertirse, compare al agente capacitado (arriba) con un agente que se mueve al azar. (No funciona tan bien).
create_policy_eval_video(random_policy, "random-agent")
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x55ffa7fe73c0] Warning: data is not aligned! This can lead to a speed loss