
Copyright 2021 Los autores de TF-Agents.
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Introducción
Este ejemplo muestra cómo entrenar a un actor crítico suave agente en el Minitaur medio ambiente.
Si usted ha trabajado a través de la DQN Colab este debe sentirse muy familiar. Los cambios notables incluyen:
- Cambio de agente de DQN a SAC.
- Capacitación en Minitaur, que es un entorno mucho más complejo que CartPole. El entorno Minitaur tiene como objetivo entrenar a un robot cuadrúpedo para que avance.
- Uso de la API Actor-Learner de TF-Agents para el aprendizaje por refuerzo distribuido.
La API admite tanto la recopilación de datos distribuidos mediante un búfer de reproducción de experiencias y un contenedor de variables (servidor de parámetros) como el entrenamiento distribuido en varios dispositivos. La API está diseñada para ser muy simple y modular. Utilizamos reverberación tanto para búfer de reproducción y el contenedor variable y TF DistributionStrategy API para la formación distribuidos en las GPU y TPU.
Si no ha instalado las siguientes dependencias, ejecute:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
Configuración
Primero importaremos las diferentes herramientas que necesitemos.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
Hiperparámetros
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
Medio ambiente
Los entornos en RL representan la tarea o problema que estamos tratando de resolver. Entornos estándar se pueden crear fácilmente en la TF-Agentes utilizando suites . Tenemos diferentes suites para la carga de los entornos de fuentes tales como el OpenAI gimnasia, Atari, Control de DM, etc., dado un nombre de entorno cadena.
Ahora carguemos el entorno Minituar desde la suite Pybullet.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

En este entorno, el objetivo es que el agente entrene una política que controlará el robot Minitaur y lo hará avanzar lo más rápido posible. Los episodios duran 1000 pasos y el regreso será la suma de recompensas a lo largo del episodio.
Echemos un vistazo a la información que el entorno ofrece como una observation , que la política va a utilizar para generar actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
La observación es bastante compleja. Recibimos 28 valores que representan los ángulos, velocidades y pares de torsión de todos los motores. A cambio, el entorno de espera 8 valores para las acciones entre [-1, 1] . Estos son los ángulos de motor deseados.
Por lo general, creamos dos entornos: uno para recopilar datos durante la capacitación y otro para la evaluación. Los entornos están escritos en Python puro y usan matrices numpy, que la API Actor Learner consume directamente.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
Estrategia de distribución
Usamos la API DistributionStrategy para permitir la ejecución del cálculo de los pasos del tren en múltiples dispositivos, como múltiples GPU o TPU, utilizando el paralelismo de datos. El paso del tren:
- Recibe un lote de datos de entrenamiento
- Lo divide entre los dispositivos
- Calcula el paso hacia adelante
- Agrega y calcula la MEDIA de la pérdida
- Calcula el paso hacia atrás y realiza una actualización de la variable de gradiente
Con TF-Agents Learner API y DistributionStrategy API, es bastante fácil cambiar entre ejecutar el paso de tren en GPU (usando MirroredStrategy) a TPU (usando TPUStrategy) sin cambiar ninguna de las lógicas de entrenamiento a continuación.
Habilitando la GPU
Si desea intentar ejecutar en una GPU, primero deberá habilitar las GPU para el portátil:
- Vaya a Editar → Configuración del cuaderno
- Seleccione GPU en el menú desplegable Acelerador de hardware
Elegir una estrategia
Utilice strategy_utils para generar una estrategia. Bajo el capó, pasando el parámetro:
-
use_gpu = Falserendimientostf.distribute.get_strategy(), que utiliza la CPU -
use_gpu = Truerendimientostf.distribute.MirroredStrategy(), que utiliza todas las GPU que son visibles para TensorFlow en una máquina
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
Todas las variables y agentes necesitan ser creados bajo strategy.scope() , como se verá a continuación.
Agente
Para crear un Agente SAC, primero necesitamos crear las redes que entrenará. SAC es un agente actor-crítico, por lo que necesitaremos dos redes.
El crítico nos dará las estimaciones del valor de Q(s,a) . Es decir, recibirá como entrada una observación y una acción, y nos dará una estimación de qué tan buena fue esa acción para el estado dado.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
Vamos a utilizar esta crítica a entrenar a un actor red que nos permitirá generar acciones dado una observación.
El ActorNetwork predecirá parámetros para un tanh-aplastado MultivariateNormalDiag distribución. Esta distribución será luego muestreada, condicionada a la observación actual, siempre que necesitemos generar acciones.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
Con estas redes a mano, ahora podemos crear una instancia del agente.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
Búfer de reproducción
Con el fin de realizar un seguimiento de los datos recogidos en el medio ambiente, vamos a utilizar reverberación , un sistema de repetición eficiente, extensible y fácil de usar por Deepmind. Almacena datos de experiencia recopilados por los actores y consumidos por el alumno durante el entrenamiento.
En este tutorial, esto es menos importante que max_size - pero en un entorno distribuido con la colección y la formación asincrónica, es probable que desee experimentar con rate_limiters.SampleToInsertRatio , utilizando un samples_per_insert algún lugar entre el 2 y 1000. Por ejemplo:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
El tampón de repetición se construye usando las características que describen los tensores que son para ser almacenados, que se pueden obtener a partir del agente utilizando tf_agent.collect_data_spec .
Puesto que el agente SAC necesita tanto de la actual y la siguiente observación para calcular la pérdida, nos propusimos sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
Ahora generamos un conjunto de datos de TensorFlow a partir del búfer de reproducción de Reverb. Pasaremos esto al alumno para que muestre experiencias para la capacitación.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
Políticas
En la carretera TF-agentes, políticas representan la noción estándar de las políticas en la vida real: dado un time_step producir una acción o una distribución más acciones. El método principal es policy_step = policy.step(time_step) , donde policy_step es una tupla llamado PolicyStep(action, state, info) . El policy_step.action es la action que debe aplicarse a la ambiente, state representa el estado de las políticas con estado (RNN) y info pueden contener información auxiliar tal como probabilidades de registro de las acciones.
Los agentes contienen dos políticas:
-
agent.policy- La principal política que se utiliza para la evaluación y la implementación. -
agent.collect_policy- Una segunda política que se utiliza para la recolección de datos.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
Las políticas se pueden crear independientemente de los agentes. Por ejemplo, utilice tf_agents.policies.random_py_policy para crear una política que seleccionará al azar una acción para cada time_step.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
Actores
El actor gestiona las interacciones entre una política y un entorno.
- Los componentes Actor contienen una instancia del medio ambiente (como
py_environment) y una copia de las variables de política. - Cada trabajador de Actor ejecuta una secuencia de pasos de recopilación de datos dados los valores locales de las variables de política.
- Actualización de las variables se realizan utilizando explícitamente la instancia de cliente contenedor variable en el guión de entrenamiento antes de llamar
actor.run(). - La experiencia observada se escribe en el búfer de reproducción en cada paso de recopilación de datos.
A medida que los actores ejecutan los pasos de recopilación de datos, pasan las trayectorias de (estado, acción, recompensa) al observador, que las almacena en caché y las escribe en el sistema de reproducción Reverb.
Estamos almacenar trayectorias para los marcos [(T0, T1) (t1, t2) (T2, T3), ...] porque stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
Creamos un actor con la política aleatoria y recopilamos experiencias con las que sembrar el búfer de reproducción.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
Cree una instancia de un actor con la política de recopilación para recopilar más experiencias durante el entrenamiento.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
Cree un actor que se utilizará para evaluar la política durante la capacitación. Pasamos por actor.eval_metrics(num_eval_episodes) para registrar las métricas más tarde.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
Aprendices
El componente Learner contiene el agente y realiza actualizaciones escalonadas de gradiente para las variables de política utilizando datos de experiencia del búfer de reproducción. Después de uno o más pasos de entrenamiento, el alumno puede enviar un nuevo conjunto de valores de variable al contenedor de variables.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
Métricas y evaluación
Nos crea una instancia del actor eval con actor.eval_metrics anteriores, lo que crea métricas utilizadas con mayor frecuencia durante la evaluación de políticas:
- Rentabilidad media. El retorno es la suma de las recompensas obtenidas al ejecutar una política en un entorno para un episodio, y generalmente promediamos esto en unos pocos episodios.
- Duración media del episodio.
Ejecutamos el Actor para generar estas métricas.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
Salida del módulo de métricas para otras implementaciones estándar de diferentes métricas.
Entrenando al agente
El ciclo de entrenamiento implica tanto la recopilación de datos del entorno como la optimización de las redes del agente. A lo largo del camino, ocasionalmente evaluaremos la política del agente para ver cómo lo estamos haciendo.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
Visualización
Parcelas
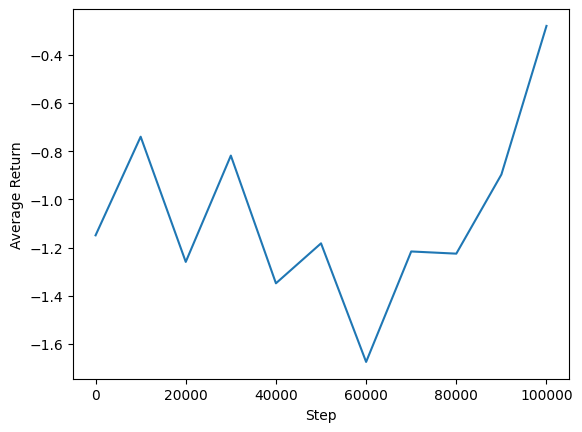
Podemos graficar el rendimiento promedio frente a los pasos globales para ver el desempeño de nuestro agente. En Minitaur , la función de recompensa se basa en qué medida el Minitaur camina en 1000 pasos y penaliza el gasto de energía.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
Videos
Es útil visualizar el desempeño de un agente al representar el entorno en cada paso. Antes de hacer eso, primero creemos una función para incrustar videos en este colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
El siguiente código visualiza la política del agente para algunos episodios:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)