
Copyright 2020 TF-AgentsAuthors。
はじめに
 GitHubでソースを表示 GitHubでソースを表示 | |
設定
次の依存関係をインストールしていない場合は、次を実行します。
pip install tf-agents
輸入
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
序章
多腕バンディット問題(MAB)は、強化学習の特殊なケースです。エージェントは、環境の状態を観察した後、何らかのアクションを実行することにより、環境内で報酬を収集します。一般的なRLとMABの主な違いは、MABでは、エージェントが実行するアクションが環境の次の状態に影響を与えないと想定していることです。したがって、エージェントは、状態遷移をモデル化したり、過去のアクションに対する報酬をクレジットしたり、報酬が豊富な状態に到達するために「事前に計画」したりしません。
他のRLドメインのように、MABエージェントの目標は、できるだけ多くの報酬として収集することをポリシーを見つけることです。ただし、常に最高の報酬を約束するアクションを利用しようとするのは間違いです。十分に探索しないと、より良いアクションを見逃す可能性があるためです。これは、多くの場合、探査・開発のジレンマと呼ばれる、(MAB)で解決すべき主な問題です。
バンディット環境、ポリシー、およびMABのための薬剤は、サブディレクトリの中に見つけることができますtf_agents /盗賊。
環境
TF-剤中、環境のクラスは、(これは観察またはコンテキストと呼ばれる)は、現在の状態に関する情報を与える入力としての作用を受けて、状態遷移を行い、報酬を出力する役割を果たす。このクラスは、エピソードが終了したときのリセットも処理するため、新しいエピソードを開始できます。これを呼び出すことで実現されてreset状態はエピソードの「最後」と表示されたときに関数を。
詳細については、 TF-エージェント環境のチュートリアルを。
上記のように、MABは、アクションが次の観測に影響を与えないという点で一般的なRLとは異なります。もう1つの違いは、バンディットには「エピソード」がないことです。すべてのタイムステップは、以前のタイムステップとは関係なく、新しい観測から始まります。
観測はRLエピソードのコンセプト独立した抽象離れにあることを確認するために、我々はのサブクラス紹介PyEnvironmentとTFEnvironment : BanditPyEnvironmentとBanditTFEnvironmentを。これらのクラスは、ユーザーがまだ実装していない2つのプライベートメンバー関数を公開します。
@abc.abstractmethod
def _observe(self):
と
@abc.abstractmethod
def _apply_action(self, action):
_observe機能は、観察を返します。次に、ポリシーはこの観察に基づいてアクションを選択します。 _apply_action入力として、そのアクションを受信し、対応する報酬を返します。これらのプライベートメンバ関数は、関数によって呼び出されresetとstepそれぞれ。
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
中間抽象クラスが実装上PyEnvironmentの_resetと_step機能と抽象機能が公開_observeと_apply_actionサブクラスによって実装されます。
簡単なサンプル環境クラス
次のクラスは、観測値が-2から2の間のランダムな整数であり、3つの可能なアクション(0、1、2)があり、報酬はアクションと観測値の積である非常に単純な環境を提供します。
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
これで、この環境を使用して観察を取得し、アクションに対する報酬を受け取ることができます。
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
TF環境
一つは、サブクラス化することで山賊環境を定義することができBanditTFEnvironment 、または、同様にRL環境に、1が定義することができBanditPyEnvironmentとでそれをラップTFPyEnvironment 。簡単にするために、このチュートリアルでは後者のオプションを使用します。
tf_environment = tf_py_environment.TFPyEnvironment(environment)
ポリシー
強盗問題におけるポリシーは、RLの問題と同じように動作します。それは入力として観察与え、アクション(またはアクションの分布)を提供します。
詳細については、 TF-エージェントポリシーのチュートリアルを。
一つは、作成することができます。環境と同じように、ポリシーを作成するには、2つの方法がありますPyPolicyし、それを包むTFPyPolicy 、または直接作成TFPolicy 。ここでは、直接法を選択します。
この例は非常に単純なので、最適なポリシーを手動で定義できます。アクションは、観測の符号にのみ依存します。負の場合は0、正の場合は2です。
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
これで、環境からの監視を要求し、ポリシーを呼び出してアクションを選択できます。そうすると、環境は報酬を出力します。
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
盗賊環境が実装されている方法は、私たちが一歩を踏み出すたびに、私たちが取った行動に対する報酬だけでなく、次の観察も受け取ることを保証します。
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
エージェント
盗賊環境と盗賊ポリシーができたので、トレーニングサンプルに基づいてポリシーの変更を処理する盗賊エージェントも定義します。
山賊エージェントのAPIは、RLエージェントのものと異なっていません:エージェントはちょうど実装する必要があり_initializeと_train方法を、と定義しpolicyとcollect_policy 。
より複雑な環境
盗賊エージェントを作成する前に、理解するのが少し難しい環境を用意する必要があります。物事を少しだけを盛り上げるために、次の環境はどちらか常に与えるreward = observation * actionやreward = -observation * action 。これは、環境が初期化されるときに決定されます。
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
より複雑なポリシー
より複雑な環境では、より複雑なポリシーが必要になります。基盤となる環境の動作を検出するポリシーが必要です。ポリシーが処理する必要がある3つの状況があります。
- エージェントは、実行中の環境のバージョンをまだ検出していません。
- エージェントは、環境の元のバージョンが実行されていることを検出しました。
- エージェントは、反転したバージョンの環境が実行されていることを検出しました。
我々は定義tf_variable名前_situationの値としてエンコードされ、この情報を格納するために[0, 2]次に、それに応じてポリシー挙動を作ります。
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
エージェント
次に、環境の兆候を検出し、ポリシーを適切に設定するエージェントを定義します。
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
上記のコードでは、エージェントは、ポリシーを定義し、変数situation 、エージェントとポリシーによって共有されています。
また、パラメータのexperienceの_train機能が軌道です。
軌道
TF-エージェントでは、 trajectories取られ、前のステップからのサンプルを含むタプルを命名しています。これらのサンプルは、ポリシーをトレーニングおよび更新するためにエージェントによって使用されます。 RLでは、軌跡には、現在の状態、次の状態、および現在のエピソードが終了したかどうかに関する情報が含まれている必要があります。 Banditの世界ではこれらのものは必要ないため、軌道を作成するためのヘルパー関数を設定します。
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
エージェントのトレーニング
これで、すべてのピースが盗賊エージェントを訓練する準備が整いました。
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
出力から、2番目のステップの後(最初のステップで観測値が0であった場合を除く)、ポリシーが正しい方法でアクションを選択するため、収集される報酬は常に負ではないことがわかります。
実際のコンテキストバンディットの例
このチュートリアルの残りの部分では、我々は、事前に実装され使用環境とエージェントTF-エージェントバンディッツライブラリのを。
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
線形ペイオフ関数を使用した定常確率的環境
この例で使用される環境があるStationaryStochasticPyEnvironment 。この環境は、パラメーターとして観測値(コンテキスト)を与えるための(通常はノイズの多い)関数を取り、すべてのアームに対して、与えられた観測値に基づいて報酬を計算する(ノイズの多い)関数を取ります。この例では、d次元の立方体からコンテキストを均一にサンプリングします。報酬関数は、コンテキストの線形関数にガウスノイズを加えたものです。
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
LinUCBエージェント
実装以下のエージェントLinUCBアルゴリズム。
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
後悔メトリック
バンディッツの最も重要なメトリックは、エージェントによって収集された報酬と環境の報酬機能へのアクセス権を持つOracleポリシーの期待報酬の差として計算し、後悔です。 RegretMetricはこれ観測与えられた最高の達成可能期待される報酬を計算baseline_reward_fn機能を必要とします。この例では、環境に対してすでに定義した報酬関数に相当するノイズのないものを最大にする必要があります。
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
トレーニング
ここで、上記で紹介したすべてのコンポーネント(環境、ポリシー、およびエージェント)をまとめました。我々は、ドライバの助けを借りて、環境に関する政策と出力トレーニングデータを実行し、データにエージェントを訓練します。
実行されるステップ数を一緒に指定する2つのパラメーターがあることに注意してください。 num_iterationsドライバがかかりますしながら、私たちは、トレーナーのループを実行する回数を指定しsteps_per_loop反復ごとの手順を。これらのパラメーターの両方を保持する主な理由は、一部の操作は反復ごとに実行され、一部の操作はすべてのステップでドライバーによって実行されるためです。たとえば、エージェントのtrain機能だけ反復ごとに一度と呼ばれています。ここでのトレードオフは、より頻繁にトレーニングする場合、ポリシーは「より新鮮」であるということです。一方、より大きなバッチでのトレーニングは、より時間効率が良い可能性があります。
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
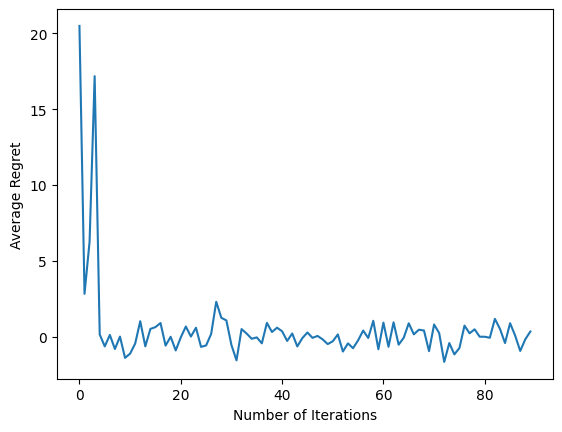
最後のコードスニペットを実行した後、結果のプロットは(うまくいけば)エージェントがトレーニングされるにつれて平均的な後悔が減少していることを示しており、観察結果を踏まえると、ポリシーは正しいアクションが何であるかを理解する上でより良くなります。
次は何ですか?
より多くの作業例を参照するには、以下を参照してください盗賊/エージェント/例の異なる薬剤や環境のためにすぐに実行例を持っているディレクトリを。
TF-Agentsライブラリは、アームごとの機能を備えた多腕バンディットを処理することもできます。そのために、我々は、あたりの腕バンディットに読者を参照してくださいチュートリアル。