
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini akan menunjukkan praktik terbaik yang direkomendasikan untuk model pelatihan dengan Privasi Diferensial tingkat pengguna menggunakan Tensorflow Federated. Kami akan menggunakan algoritma DP-SGD dari Abadi et al., "Jauh Belajar dengan Differential Privasi" dimodifikasi untuk pengguna tingkat DP dalam konteks federasi di McMahan et al., "Belajar berbeda-beda Swasta berulang Bahasa Model" .
Diferensial Privasi (DP) adalah metode yang banyak digunakan untuk membatasi dan mengukur kebocoran privasi data sensitif saat melakukan tugas pembelajaran. Pelatihan model dengan DP tingkat pengguna menjamin bahwa model tidak mungkin mempelajari sesuatu yang signifikan tentang data individu mana pun, tetapi masih dapat (semoga!) mempelajari pola yang ada dalam data banyak klien.
Kami akan melatih model pada kumpulan data EMNIST federasi. Ada trade-off yang melekat antara utilitas dan privasi, dan mungkin sulit untuk melatih model dengan privasi tinggi yang berkinerja sebaik model non-pribadi yang canggih. Untuk kemanfaatan dalam tutorial ini, kita akan berlatih hanya untuk 100 ronde, mengorbankan beberapa kualitas untuk mendemonstrasikan cara berlatih dengan privasi tinggi. Jika kami menggunakan lebih banyak putaran pelatihan, kami tentu saja dapat memiliki model pribadi dengan akurasi yang lebih tinggi, tetapi tidak setinggi model yang dilatih tanpa DP.
Sebelum kita mulai
Pertama, mari kita pastikan notebook terhubung ke backend yang memiliki komponen yang relevan dikompilasi.
!pip install --quiet --upgrade tensorflow_federated_nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
Beberapa impor yang kita perlukan untuk tutorial. Kami akan menggunakan tensorflow_federated , kerangka open-source untuk pembelajaran mesin dan perhitungan lainnya pada data desentralisasi, serta tensorflow_privacy , perpustakaan open-source untuk menerapkan dan menganalisis algoritma berbeda-beda swasta di tensorflow.
import collections
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
import tensorflow_privacy as tfp
Jalankan contoh "Hello World" berikut untuk memastikan lingkungan TFF telah diatur dengan benar. Jika tidak bekerja, silakan merujuk ke Instalasi panduan untuk petunjuk.
@tff.federated_computation
def hello_world():
return 'Hello, World!'
hello_world()
b'Hello, World!'
Unduh dan praproses kumpulan data EMNIST federasi.
def get_emnist_dataset():
emnist_train, emnist_test = tff.simulation.datasets.emnist.load_data(
only_digits=True)
def element_fn(element):
return collections.OrderedDict(
x=tf.expand_dims(element['pixels'], -1), y=element['label'])
def preprocess_train_dataset(dataset):
# Use buffer_size same as the maximum client dataset size,
# 418 for Federated EMNIST
return (dataset.map(element_fn)
.shuffle(buffer_size=418)
.repeat(1)
.batch(32, drop_remainder=False))
def preprocess_test_dataset(dataset):
return dataset.map(element_fn).batch(128, drop_remainder=False)
emnist_train = emnist_train.preprocess(preprocess_train_dataset)
emnist_test = preprocess_test_dataset(
emnist_test.create_tf_dataset_from_all_clients())
return emnist_train, emnist_test
train_data, test_data = get_emnist_dataset()
Tentukan model kita.
def my_model_fn():
model = tf.keras.models.Sequential([
tf.keras.layers.Reshape(input_shape=(28, 28, 1), target_shape=(28 * 28,)),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(10)])
return tff.learning.from_keras_model(
keras_model=model,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
input_spec=test_data.element_spec,
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
Tentukan sensitivitas kebisingan model.
Untuk mendapatkan jaminan DP tingkat pengguna, kita harus mengubah algoritma dasar Federated Averaging dengan dua cara. Pertama, pembaruan model klien harus dipotong sebelum transmisi ke server, membatasi pengaruh maksimum dari salah satu klien. Kedua, server harus menambahkan noise yang cukup ke jumlah pembaruan pengguna sebelum rata-rata untuk mengaburkan pengaruh klien kasus terburuk.
Untuk kliping, kita menggunakan metode kliping adaptif Andrew et al. 2021, berbeda-beda Swasta Belajar dengan Adaptive Kliping , sehingga tidak ada kliping norma perlu secara eksplisit ditetapkan.
Menambahkan noise pada umumnya akan menurunkan utilitas model, tetapi kita dapat mengontrol jumlah noise dalam pembaruan rata-rata di setiap putaran dengan dua tombol: deviasi standar dari noise Gaussian yang ditambahkan ke penjumlahan, dan jumlah klien di rata-rata. Strategi kami adalah pertama-tama menentukan seberapa banyak kebisingan yang dapat ditoleransi model dengan jumlah klien yang relatif kecil per putaran dengan kerugian yang dapat diterima untuk utilitas model. Kemudian untuk melatih model akhir, kita dapat meningkatkan jumlah kebisingan dalam jumlah, sementara secara proporsional meningkatkan jumlah klien per putaran (dengan asumsi dataset cukup besar untuk mendukung banyak klien per putaran). Ini tidak mungkin secara signifikan mempengaruhi kualitas model, karena satu-satunya efek adalah mengurangi varians karena pengambilan sampel klien (memang kami akan memverifikasi bahwa itu tidak dalam kasus kami).
Untuk itu, pertama-tama kami melatih serangkaian model dengan 50 klien per putaran, dengan jumlah kebisingan yang meningkat. Secara khusus, kami meningkatkan "pengganda_suara" yang merupakan rasio deviasi standar kebisingan dengan norma kliping. Karena kami menggunakan kliping adaptif, ini berarti bahwa besaran sebenarnya dari kebisingan berubah dari putaran ke putaran.
# Run five clients per thread. Increase this if your runtime is running out of
# memory. Decrease it if you have the resources and want to speed up execution.
tff.backends.native.set_local_python_execution_context(clients_per_thread=5)
total_clients = len(train_data.client_ids)
def train(rounds, noise_multiplier, clients_per_round, data_frame):
# Using the `dp_aggregator` here turns on differential privacy with adaptive
# clipping.
aggregation_factory = tff.learning.model_update_aggregator.dp_aggregator(
noise_multiplier, clients_per_round)
# We use Poisson subsampling which gives slightly tighter privacy guarantees
# compared to having a fixed number of clients per round. The actual number of
# clients per round is stochastic with mean clients_per_round.
sampling_prob = clients_per_round / total_clients
# Build a federated averaging process.
# Typically a non-adaptive server optimizer is used because the noise in the
# updates can cause the second moment accumulators to become very large
# prematurely.
learning_process = tff.learning.build_federated_averaging_process(
my_model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.01),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0, momentum=0.9),
model_update_aggregation_factory=aggregation_factory)
eval_process = tff.learning.build_federated_evaluation(my_model_fn)
# Training loop.
state = learning_process.initialize()
for round in range(rounds):
if round % 5 == 0:
metrics = eval_process(state.model, [test_data])['eval']
if round < 25 or round % 25 == 0:
print(f'Round {round:3d}: {metrics}')
data_frame = data_frame.append({'Round': round,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
# Sample clients for a round. Note that if your dataset is large and
# sampling_prob is small, it would be faster to use gap sampling.
x = np.random.uniform(size=total_clients)
sampled_clients = [
train_data.client_ids[i] for i in range(total_clients)
if x[i] < sampling_prob]
sampled_train_data = [
train_data.create_tf_dataset_for_client(client)
for client in sampled_clients]
# Use selected clients for update.
state, metrics = learning_process.next(state, sampled_train_data)
metrics = eval_process(state.model, [test_data])['eval']
print(f'Round {rounds:3d}: {metrics}')
data_frame = data_frame.append({'Round': rounds,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
return data_frame
data_frame = pd.DataFrame()
rounds = 100
clients_per_round = 50
for noise_multiplier in [0.0, 0.5, 0.75, 1.0]:
print(f'Starting training with noise multiplier: {noise_multiplier}')
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
print()
Starting training with noise multiplier: 0.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.112289384), ('loss', 2.5190482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.19075724), ('loss', 2.2449977)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.18115693), ('loss', 2.163907)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49970612), ('loss', 2.01017)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5333317), ('loss', 1.8350543)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.5828517), ('loss', 1.6551636)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7352077), ('loss', 0.8700141)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7769152), ('loss', 0.6992781)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.8049814), ('loss', 0.62453026)])
Starting training with noise multiplier: 0.5
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.09526841), ('loss', 2.4332638)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.20128821), ('loss', 2.2664592)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.35472178), ('loss', 2.130336)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.5480995), ('loss', 1.9713942)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.42246276), ('loss', 1.8045483)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.624902), ('loss', 1.4785467)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7265625), ('loss', 0.85801566)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.77720904), ('loss', 0.70615387)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7702537), ('loss', 0.72331005)])
Starting training with noise multiplier: 0.75
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.098672606), ('loss', 2.422002)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.11794671), ('loss', 2.2227976)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.3208513), ('loss', 2.083766)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49752644), ('loss', 1.8728142)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5816761), ('loss', 1.6084186)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.62896746), ('loss', 1.378527)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.73153406), ('loss', 0.8705139)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7789724), ('loss', 0.7113147)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.70944357), ('loss', 0.89495045)])
Starting training with noise multiplier: 1.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.12002841), ('loss', 2.60482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.104574844), ('loss', 2.3388205)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.29966694), ('loss', 2.089262)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.4067398), ('loss', 1.9109797)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5123677), ('loss', 1.6472703)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.56416535), ('loss', 1.4362282)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.62323666), ('loss', 1.1682972)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.55968356), ('loss', 1.4779186)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.382837), ('loss', 1.9680436)])
Sekarang kita dapat memvisualisasikan akurasi set evaluasi dan kehilangan run tersebut.
import matplotlib.pyplot as plt
import seaborn as sns
def make_plot(data_frame):
plt.figure(figsize=(15, 5))
dff = data_frame.rename(
columns={'sparse_categorical_accuracy': 'Accuracy', 'loss': 'Loss'})
plt.subplot(121)
sns.lineplot(data=dff, x='Round', y='Accuracy', hue='NoiseMultiplier', palette='dark')
plt.subplot(122)
sns.lineplot(data=dff, x='Round', y='Loss', hue='NoiseMultiplier', palette='dark')
make_plot(data_frame)
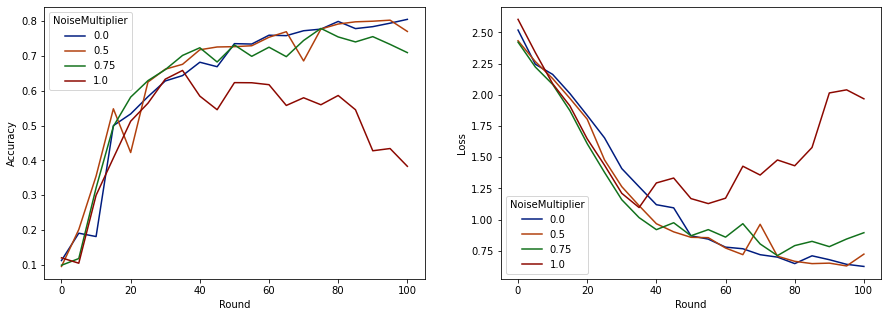
Tampaknya dengan 50 klien yang diharapkan per putaran, model ini dapat mentolerir pengganda kebisingan hingga 0,5 tanpa menurunkan kualitas model. Pengganda kebisingan 0,75 tampaknya menyebabkan sedikit penurunan model, dan 1,0 membuat model menyimpang.
Biasanya ada tradeoff antara kualitas model dan privasi. Semakin tinggi noise yang kami gunakan, semakin banyak privasi yang bisa kami dapatkan untuk jumlah waktu pelatihan dan jumlah klien yang sama. Sebaliknya, dengan lebih sedikit noise, kami mungkin memiliki model yang lebih akurat, tetapi kami harus berlatih dengan lebih banyak klien per putaran untuk mencapai tingkat privasi target kami.
Dengan eksperimen di atas, kita mungkin memutuskan bahwa sejumlah kecil kerusakan model pada 0,75 dapat diterima untuk melatih model akhir lebih cepat, tetapi mari kita asumsikan kita ingin mencocokkan kinerja model pengali noise 0,5.
Sekarang kita dapat menggunakan fungsi tensorflow_privacy untuk menentukan berapa banyak klien yang diharapkan per putaran yang kita perlukan untuk mendapatkan privasi yang dapat diterima. Praktik standar adalah memilih delta yang agak lebih kecil dari satu daripada jumlah catatan dalam kumpulan data. Dataset ini memiliki total 3383 pengguna pelatihan, jadi mari kita tuju (2, 1e-5)-DP.
Kami menggunakan pencarian biner sederhana atas jumlah klien per putaran. Fungsi tensorflow_privacy kita gunakan untuk memperkirakan epsilon didasarkan pada Wang et al. (2018) dan Mironov et al. (2019) .
rdp_orders = ([1.25, 1.5, 1.75, 2., 2.25, 2.5, 3., 3.5, 4., 4.5] +
list(range(5, 64)) + [128, 256, 512])
total_clients = 3383
base_noise_multiplier = 0.5
base_clients_per_round = 50
target_delta = 1e-5
target_eps = 2
def get_epsilon(clients_per_round):
# If we use this number of clients per round and proportionally
# scale up the noise multiplier, what epsilon do we achieve?
q = clients_per_round / total_clients
noise_multiplier = base_noise_multiplier
noise_multiplier *= clients_per_round / base_clients_per_round
rdp = tfp.compute_rdp(
q, noise_multiplier=noise_multiplier, steps=rounds, orders=rdp_orders)
eps, _, _ = tfp.get_privacy_spent(rdp_orders, rdp, target_delta=target_delta)
return clients_per_round, eps, noise_multiplier
def find_needed_clients_per_round():
hi = get_epsilon(base_clients_per_round)
if hi[1] < target_eps:
return hi
# Grow interval exponentially until target_eps is exceeded.
while True:
lo = hi
hi = get_epsilon(2 * lo[0])
if hi[1] < target_eps:
break
# Binary search.
while hi[0] - lo[0] > 1:
mid = get_epsilon((lo[0] + hi[0]) // 2)
if mid[1] > target_eps:
lo = mid
else:
hi = mid
return hi
clients_per_round, _, noise_multiplier = find_needed_clients_per_round()
print(f'To get ({target_eps}, {target_delta})-DP, use {clients_per_round} '
f'clients with noise multiplier {noise_multiplier}.')
To get (2, 1e-05)-DP, use 120 clients with noise multiplier 1.2.
Sekarang kita bisa melatih model pribadi terakhir kita untuk rilis.
rounds = 100
noise_multiplier = 1.2
clients_per_round = 120
data_frame = pd.DataFrame()
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
make_plot(data_frame)
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.08260678), ('loss', 2.6334999)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.1492212), ('loss', 2.259542)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.28847474), ('loss', 2.155699)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.3989518), ('loss', 2.0156953)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5086697), ('loss', 1.8261365)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.6204692), ('loss', 1.5602393)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.70008814), ('loss', 0.91155165)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.78421336), ('loss', 0.6820159)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7955525), ('loss', 0.6585961)])
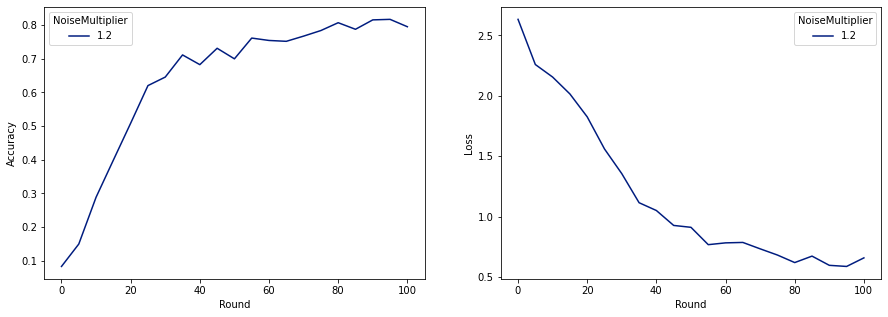
Seperti yang dapat kita lihat, model terakhir memiliki kehilangan dan akurasi yang serupa dengan model yang dilatih tanpa noise, tetapi model ini memenuhi (2, 1e-5)-DP.