
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি আংশিকভাবে স্থানীয় ফেডারেট লার্নিং, যেখানে কিছু ক্লায়েন্ট পরামিতি সার্ভারে সমষ্টিগত না হয় প্রতিবেদক। এটি ব্যবহারকারী-নির্দিষ্ট পরামিতি সহ মডেলগুলির জন্য উপযোগী (যেমন ম্যাট্রিক্স ফ্যাক্টরাইজেশন মডেল) এবং যোগাযোগ-সীমিত সেটিংসে প্রশিক্ষণের জন্য। আমরা চালু ধারণা নির্মাণ ভাবমূর্তি শ্রেণীবিভাগ জন্য ফেডারেটেড শিক্ষণ টিউটোরিয়াল; যে টিউটোরিয়ালে হিসাবে, আমরা উচ্চ পর্যায়ের API গুলি পরিচয় করিয়ে tff.learning ফেডারেট প্রশিক্ষণ ও পরীক্ষা নিরীক্ষার জন্য।
আমরা আংশিকভাবে স্থানীয় ফেডারেট লার্নিং প্রেরণার শুরু ম্যাট্রিক্স গুণকনির্ণয় । আমরা ফেডারেটেড রিকনস্ট্রাকশন (বর্ণনা কাগজ , ব্লগ পোস্ট ), মাত্রায় আংশিকভাবে স্থানীয় ফেডারেট শেখার জন্য বাস্তবসম্মত অ্যালগরিদম। আমরা MovieLens 1M ডেটাসেট প্রস্তুত করি, একটি আংশিকভাবে স্থানীয় মডেল তৈরি করি এবং প্রশিক্ষণ ও মূল্যায়ন করি।
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
পটভূমি: ম্যাট্রিক্স ফ্যাক্টরাইজেশন
ম্যাট্রিক্স গুণকনির্ণয় সুপারিশ শেখার এবং ব্যবহারকারী পারস্পরিক ক্রিয়ার উপর ভিত্তি আইটেম জন্য উপস্থাপনা এম্বেড করার জন্য একটি ঐতিহাসিকভাবে জনপ্রিয় কৌশল হয়েছে। ক্যানোনিকাল উদাহরণ সিনেমা সুপারিশ আছে কোথায়, \(n\) ব্যবহারকারী এবং \(m\) চলচ্চিত্র, এবং ব্যবহারকারীদের কিছু চলচ্চিত্র রেট আছে। একজন ব্যবহারকারীকে প্রদত্ত, আমরা তাদের রেটিং ইতিহাস এবং অনুরূপ ব্যবহারকারীদের রেটিং ব্যবহার করে ভবিষ্যদ্বাণী করি যে তারা দেখেননি এমন সিনেমাগুলির জন্য ব্যবহারকারীর রেটিং। যদি আমাদের কাছে এমন একটি মডেল থাকে যা রেটিংগুলি ভবিষ্যদ্বাণী করতে পারে, তাহলে ব্যবহারকারীদের নতুন সিনেমার সুপারিশ করা সহজ যা তারা উপভোগ করবে৷
এই কাজের জন্য, এটি একটি হিসাবে ব্যবহারকারীদের রেটিং প্রতিনিধিত্ব করতে দরকারী \(n \times m\) ম্যাট্রিক্স \(R\):

এই ম্যাট্রিক্সটি সাধারণত বিক্ষিপ্ত হয়, যেহেতু ব্যবহারকারীরা সাধারণত ডেটাসেটে মুভিগুলির একটি ছোট ভগ্নাংশ দেখতে পান। ম্যাট্রিক্স গুণকনির্ণয় আউটপুট দুটি ম্যাট্রিক্সের হল: একটি \(n \times k\) ম্যাট্রিক্স \(U\) প্রতিনিধিত্বমূলক \(k\)প্রত্যেক ব্যবহারকারীর জন্য -dimensional ব্যবহারকারী embeddings, এবং একটি \(m \times k\) ম্যাট্রিক্স \(I\) প্রতিনিধিত্বমূলক \(k\)প্রতিটি আইটেমের জন্য -dimensional আইটেমটি embeddings। সরলতম প্রশিক্ষণ উদ্দেশ্য তা নিশ্চিত করার জন্য ব্যবহারকারী এবং আইটেমের embeddings এর ডট পণ্য পর্যবেক্ষিত রেটিং ভবিষ্যদ্বাণীপূর্ণ হয় \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
এটি সংশ্লিষ্ট ব্যবহারকারীর ডট প্রোডাক্ট এবং আইটেম এম্বেডিংয়ের মাধ্যমে অনুমান করা রেটিং এবং রেটিংগুলির মধ্যে গড় বর্গক্ষেত্র ত্রুটি হ্রাস করার সমতুল্য। আরেকটি উপায় ব্যাখ্যা করার যে এটি নিশ্চিত করে যে হয় \(R \approx UI^T\) পরিচিত রেটিংয়ের ক্ষেত্রে, অত "ম্যাট্রিক্স গুণকনির্ণয়"। যদি এটি বিভ্রান্তিকর হয়, চিন্তা করবেন না–আমাদের বাকি টিউটোরিয়ালের জন্য ম্যাট্রিক্স ফ্যাক্টরাইজেশনের বিশদ জানার প্রয়োজন হবে না।
মুভিলেন্স ডেটা অন্বেষণ করা হচ্ছে
এর লোড করে শুরু করা যাক MovieLens 1M ডেটা, 3706 চলচ্চিত্র উপর 6040 ব্যবহারকারীদের কাছ থেকে 1.000.209 সিনেমা রেটিং নিয়ে গঠিত পারে।
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
চলুন রেটিং এবং মুভি ডেটা সহ কয়েকটি পান্ডাস ডেটাফ্রেম লোড এবং অন্বেষণ করি।
ratings_df, movies_df = load_movielens_data()
আমরা দেখতে পাচ্ছি যে প্রতিটি রেটিং উদাহরণের একটি রেটিং 1-5, একটি সংশ্লিষ্ট UserID, একটি সংশ্লিষ্ট MovieID এবং একটি টাইমস্ট্যাম্প রয়েছে৷
ratings_df.head()
প্রতিটি সিনেমার একটি শিরোনাম এবং সম্ভাব্য একাধিক জেনার রয়েছে।
movies_df.head()
ডেটাসেটের প্রাথমিক পরিসংখ্যান বোঝা সর্বদা একটি ভাল ধারণা:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
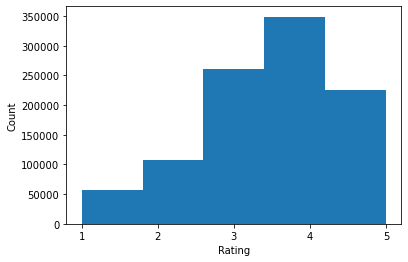
Average rating: 3.581564453029317 Median rating: 4.0
আমরা সবচেয়ে জনপ্রিয় সিনেমার ধরনগুলিও প্লট করতে পারি।
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
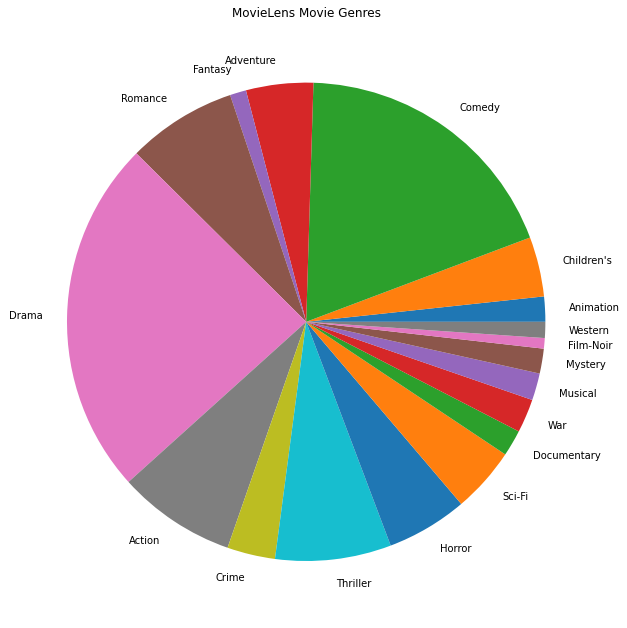
এই ডেটা স্বাভাবিকভাবেই বিভিন্ন ব্যবহারকারীর রেটিংয়ে বিভক্ত করা হয়েছে, তাই আমরা ক্লায়েন্টদের মধ্যে ডেটাতে কিছু ভিন্নতা আশা করব। নীচে আমরা বিভিন্ন ব্যবহারকারীদের জন্য সর্বাধিক রেট করা মুভি জেনারগুলি প্রদর্শন করি৷ আমরা ব্যবহারকারীদের মধ্যে উল্লেখযোগ্য পার্থক্য লক্ষ্য করতে পারি।
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
মুভিলেন্স ডেটা প্রিপ্রসেস করা হচ্ছে
আমরা এখন একটি তালিকা হিসাবে MovieLens ডেটা সেটটি প্রস্তুত করব tf.data.Dataset গুলি TFF সাথে ব্যবহারের জন্য প্রত্যেক ব্যবহারকারীর ডেটা উপস্থাপন করে।
আমরা দুটি ফাংশন বাস্তবায়ন করি:
-
create_tf_datasets: আমাদের রেটিং DataFrame নেয় এবং ব্যবহারকারী-বিভক্ত একটি তালিকা উত্পাদন করেtf.data.Datasetগুলি। -
split_tf_datasets: ডেটাসেট ও ট্রেন / Val / পরীক্ষা ব্যবহারকারী দ্বারা বিভক্ত তাদের একটি তালিকা লাগে তাই Val / পরীক্ষা সেট শুধুমাত্র প্রশিক্ষণের সময় অদৃশ্য ব্যবহারকারীদের কাছ থেকে রেটিং ধারণ করে। সাধারণত মান কেন্দ্রীভূত ম্যাট্রিক্স গুণকনির্ণয় আমরা আসলে তাই বিভক্ত যে Val / পরীক্ষা সেট দেখা ব্যবহারকারীদের কাছ থেকে অনুষ্ঠিত আউট রেটিং ধারণ, যেহেতু অদৃশ্য ব্যবহারকারী embeddings হবে না। আমাদের ক্ষেত্রে, আমরা পরে দেখব যে FL-এ ম্যাট্রিক্স ফ্যাক্টরাইজেশন সক্ষম করার জন্য আমরা যে পদ্ধতি ব্যবহার করি তা অদেখা ব্যবহারকারীদের জন্য ব্যবহারকারীর এম্বেডিংগুলিকে দ্রুত পুনর্গঠন করতে সক্ষম করে।
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
একটি দ্রুত চেক হিসাবে, আমরা প্রশিক্ষণ ডেটার একটি ব্যাচ মুদ্রণ করতে পারি। আমরা দেখতে পাচ্ছি যে প্রতিটি পৃথক উদাহরণে "x" কী এর অধীনে একটি MovieID এবং "y" কী এর অধীনে একটি রেটিং রয়েছে। মনে রাখবেন যে আমাদের UserID প্রয়োজন হবে না যেহেতু প্রতিটি ব্যবহারকারী শুধুমাত্র তাদের নিজস্ব ডেটা দেখে।
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
আমরা প্রতি ব্যবহারকারীর রেটিং সংখ্যা দেখানো একটি হিস্টোগ্রাম প্লট করতে পারি।
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
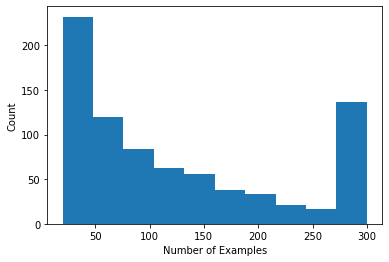
এখন যেহেতু আমরা ডেটা লোড এবং অন্বেষণ করেছি, আমরা আলোচনা করব কিভাবে ফেডারেটেড লার্নিংয়ে ম্যাট্রিক্স ফ্যাক্টরাইজেশন আনতে হয়। পথ ধরে, আমরা আংশিকভাবে স্থানীয় ফেডারেটেড শিক্ষাকে অনুপ্রাণিত করব।
ম্যাট্রিক্স ফ্যাক্টরাইজেশনকে FL এ নিয়ে আসা
যদিও ম্যাট্রিক্স ফ্যাক্টরাইজেশন ঐতিহ্যগতভাবে সেন্ট্রালাইজড সেটিংসে ব্যবহার করা হয়েছে, এটি ফেডারেটেড শেখার ক্ষেত্রে বিশেষভাবে প্রাসঙ্গিক: ব্যবহারকারীর রেটিং পৃথক ক্লায়েন্ট ডিভাইসে থাকতে পারে এবং আমরা ডেটা কেন্দ্রীভূত না করেই ব্যবহারকারী এবং আইটেমগুলির জন্য এমবেডিং এবং সুপারিশ শিখতে চাই। যেহেতু প্রতিটি ব্যবহারকারীর একটি সংশ্লিষ্ট ব্যবহারকারীর এম্বেডিং রয়েছে, তাই প্রতিটি ক্লায়েন্ট তাদের ব্যবহারকারীর এম্বেডিং সংরক্ষণ করে রাখা স্বাভাবিক - এটি সমস্ত ব্যবহারকারীর এম্বেডিং সংরক্ষণ করে এমন একটি কেন্দ্রীয় সার্ভারের চেয়ে অনেক ভালো।
FL-তে ম্যাট্রিক্স ফ্যাক্টরাইজেশন আনার একটি প্রস্তাব নিম্নরূপ:
- সার্ভার দোকানে এবং আইটেমের ম্যাট্রিক্স পাঠায় \(I\) নমুনা গ্রাহকদের প্রতিটি রাউন্ডে
- ক্লায়েন্টদের মধ্যে আইটেমটি ম্যাট্রিক্স আপডেট করুন এবং তাদের ব্যক্তিগত ব্যবহারকারী এম্বেডিং \(U_u\) উপরে উদ্দেশ্য উপর SGD ব্যবহার
- আপডেটগুলি \(I\) সার্ভারে সমষ্টিগত হয়, এর সার্ভার অনুলিপি আপডেট \(I\) পরবর্তী রাউন্ডের জন্য
এই পদ্ধতির আংশিকভাবে স্থানীয় বাসীদের, কিছু ক্লায়েন্ট পরামিতি সার্ভার দ্বারা কখনোই সমষ্টিগত হয়। যদিও এই পদ্ধতিটি আকর্ষণীয়, এটির জন্য ক্লায়েন্টদের রাউন্ড জুড়ে অবস্থা বজায় রাখতে হবে, যথা তাদের ব্যবহারকারী এম্বেডিং। স্টেটফুল ফেডারেটেড অ্যালগরিদমগুলি ক্রস-ডিভাইস এফএল সেটিংসের জন্য কম উপযুক্ত: এই সেটিংসে জনসংখ্যার আকার প্রায়ই প্রতিটি রাউন্ডে অংশগ্রহণকারী ক্লায়েন্টের সংখ্যার চেয়ে অনেক বেশি হয় এবং প্রশিক্ষণ প্রক্রিয়া চলাকালীন একজন ক্লায়েন্ট সাধারণত একবারে অংশগ্রহণ করে। বলে যে সক্রিয়া করা যাবে না জানানোর পাশাপাশি stateful আলগোরিদিম রাষ্ট্র পেয়ে মামুলি কারণে ক্রস ডিভাইস সেটিংস সময় কর্মক্ষমতা হ্রাস হতে পারে আপনি যখন কোনো ক্লায়েন্টকে কখনোসখনো নমুনা করছে। গুরুত্বপূর্ণভাবে, ম্যাট্রিক্স ফ্যাক্টরাইজেশন সেটিংয়ে, একটি স্টেটফুল অ্যালগরিদম সমস্ত অদেখা ক্লায়েন্টদের প্রশিক্ষিত ব্যবহারকারী এম্বেডিং অনুপস্থিত করে, এবং বৃহৎ মাপের প্রশিক্ষণে বেশিরভাগ ব্যবহারকারী অদৃশ্য হতে পারে। ক্রস-ডিভাইস এফএল মধ্যে আড়ম্বরহীন আলগোরিদিম জন্য প্রেরণা আরো জানার জন্য, দেখুন ওয়াং এট অল। 2021 সেকেন্ড 3.1.1 এবং Reddi এট অল। 2020 সেকেন্ড 5.1 ।
ফেডারেটেড রিকনস্ট্রাকশন ( Singhal এট অল। 2021 ) উপরোক্ত পদ্ধতির স্টেট-লেস বিকল্প। মূল ধারণাটি হল যে রাউন্ড জুড়ে ব্যবহারকারীর এম্বেডিংগুলি সংরক্ষণ করার পরিবর্তে, ক্লায়েন্টরা যখন প্রয়োজন তখন ব্যবহারকারীর এম্বেডিংগুলি পুনর্গঠন করে। যখন FedRecon ম্যাট্রিক্স ফ্যাক্টরাইজেশনে প্রয়োগ করা হয়, তখন প্রশিক্ষণ নিম্নলিখিতভাবে এগিয়ে যায়:
- সার্ভার দোকানে এবং আইটেমের ম্যাট্রিক্স পাঠায় \(I\) নমুনা গ্রাহকদের প্রতিটি রাউন্ডে
- প্রতিটি ক্লায়েন্ট স্থির \(I\) এবং তাদের ইউজার এম্বেডিং রেলগাড়ি \(U_u\) SGD এক বা একাধিক পদক্ষেপ ব্যবহার (পুনর্গঠন)
- প্রতিটি ক্লায়েন্ট স্থির \(U_u\) এবং ট্রেন \(I\) SGD এক বা একাধিক পদক্ষেপ ব্যবহার
- আপডেটগুলি \(I\) ব্যবহারকারীদের সাথে সমষ্টিগত হয়, এর সার্ভার অনুলিপি আপডেট \(I\) পরবর্তী রাউন্ডের জন্য
এই পদ্ধতির জন্য ক্লায়েন্টদের রাউন্ড জুড়ে অবস্থা বজায় রাখার প্রয়োজন হয় না। লেখকরা গবেষণাপত্রে আরও দেখান যে এই পদ্ধতিটি অদেখা ক্লায়েন্টদের (বিভাগ 4.2, চিত্র 3, এবং সারণী 1) জন্য ব্যবহারকারীর এম্বেডিংগুলির দ্রুত পুনর্গঠনের দিকে পরিচালিত করে, যার ফলে বেশিরভাগ ক্লায়েন্ট যারা প্রশিক্ষণে অংশগ্রহণ করেন না তাদের একটি প্রশিক্ষিত মডেল থাকতে দেয়। , এই ক্লায়েন্টদের জন্য সুপারিশ সক্রিয় করা. ফেডারেটেড রিকনস্ট্রাকশন দেখুন গুগল এআই ব্লগ পোস্ট আরো কী ফলাফলের জন্য।
মডেল সংজ্ঞায়িত করা
আমরা পরবর্তীতে ক্লায়েন্ট ডিভাইসগুলিতে প্রশিক্ষণের জন্য স্থানীয় ম্যাট্রিক্স ফ্যাক্টরাইজেশন মডেলটিকে সংজ্ঞায়িত করব। এই মডেল পূর্ণ আইটেমটি ম্যাট্রিক্স অন্তর্ভুক্ত করা হবে \(I\) ও একটি একক ব্যবহারকারী এমবেডিং \(U_u\) ক্লায়েন্টের জন্য \(u\)। লক্ষ্য করুন ক্লায়েন্ট পূর্ণ ব্যবহারকারী ম্যাট্রিক্স সংরক্ষণ করার প্রয়োজন হবে না \(U\)।
আমরা নিম্নলিখিত সংজ্ঞায়িত করব:
-
UserEmbedding: একটি সহজ Keras স্তর একটি একক প্রতিনিধিত্বমূলকnum_latent_factors-dimensional ব্যবহারকারী এমবেডিং। -
get_matrix_factorization_model: একটি ফাংশন যা রিটার্ন একটিtff.learning.reconstruction.Modelসহ যা স্তর বিশ্বব্যাপী সার্ভারে সমষ্টিগত হয় এবং যা স্তর স্থানীয় থাকা মডেল যুক্তি, রয়েছে। ফেডারেটেড পুনর্গঠন প্রশিক্ষণ প্রক্রিয়া শুরু করার জন্য আমাদের এই অতিরিক্ত তথ্যের প্রয়োজন। এখানে আমরা উত্পাদনtff.learning.reconstruction.Modelএকটি Keras মডেল ব্যবহার করা থেকেtff.learning.reconstruction.from_keras_model। অনুরূপtff.learning.Model, আমরা একটি কাস্টম বাস্তবায়ন করতে পারেtff.learning.reconstruction.Modelবর্গ ইন্টারফেস প্রয়োগ করে।
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
ফেডারেটেড গড় জন্য ইন্টারফেসে Analagous, সংযুক্ত রিকনস্ট্রাকশন জন্য ইন্টারফেস একটি আশা model_fn কোন যুক্তি হল যে আয় একটি সঙ্গে tff.learning.reconstruction.Model ।
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
আমরা পরের সংজ্ঞায়িত করব loss_fn এবং metrics_fn , যেখানে loss_fn একটি নো যুক্তি Keras ক্ষতি ফিরে মডেল প্রশিক্ষণের ব্যবহার করতে ফাংশন, এবং metrics_fn নিরীক্ষার জন্য Keras মেট্রিক্স একটি তালিকা ফেরার একটি নো যুক্তি ফাংশন। এগুলি প্রশিক্ষণ এবং মূল্যায়ন গণনা তৈরির জন্য প্রয়োজন।
উপরে উল্লিখিত হিসাবে আমরা ক্ষতি হিসাবে গড় স্কোয়ার ত্রুটি ব্যবহার করব। মূল্যায়নের জন্য আমরা রেটিংয়ের নির্ভুলতা ব্যবহার করব (যখন মডেলের পূর্বাভাসিত ডট পণ্যটি নিকটতম পূর্ণ সংখ্যার সাথে বৃত্তাকার করা হয়, তখন এটি কত ঘন ঘন লেবেল রেটিং এর সাথে মেলে?)।
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
প্রশিক্ষণ এবং মূল্যায়ন
এখন আমাদের প্রশিক্ষণ প্রক্রিয়া সংজ্ঞায়িত করার জন্য প্রয়োজনীয় সবকিছু আছে। থেকে এক গুরুত্বপূর্ণ পার্থক্য ফেডারেটেড গড় জন্য ইন্টারফেস যে আমরা এখন একটি মধ্যে পাস হয় reconstruction_optimizer_fn , যা যখন স্থানীয় পরামিতি পুনর্গঠনে (আমাদের ক্ষেত্রে, ব্যবহারকারী embeddings মধ্যে) ব্যবহার করা হবে। এটা ব্যবহার করা সাধারণত যুক্তিসংগত এর SGD একটি অনুরূপ এখানে, অথবা সামান্য হার শেখার অপটিমাইজার ক্লায়েন্ট চেয়ে হার শেখার নত করুন। আমরা নীচে একটি কাজ কনফিগারেশন প্রদান. এটি যত্ন সহকারে টিউন করা হয়নি, তাই বিভিন্ন মান নিয়ে খেলতে নির্দ্বিধায়।
পরীক্ষা করে দেখুন ডকুমেন্টেশন আরো বিস্তারিত জানার এবং বিকল্পের জন্য।
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
আমরা আমাদের প্রশিক্ষিত বৈশ্বিক মডেলের মূল্যায়নের জন্য একটি গণনাও সংজ্ঞায়িত করতে পারি।
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
আমরা প্রশিক্ষণ প্রক্রিয়ার অবস্থা শুরু করতে পারি এবং এটি পরীক্ষা করতে পারি। সবচেয়ে গুরুত্বপূর্ণ, আমরা দেখতে পাচ্ছি যে এই সার্ভারের অবস্থা শুধুমাত্র আইটেম ভেরিয়েবল সংরক্ষণ করে (বর্তমানে এলোমেলোভাবে শুরু করা হয়েছে) এবং কোনো ব্যবহারকারীর এম্বেডিং নয়।
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
আমরা বৈধতা ক্লায়েন্টদের উপর আমাদের এলোমেলোভাবে প্রাথমিক মডেল মূল্যায়ন করার চেষ্টা করতে পারি। ফেডারেটেড পুনর্গঠন মূল্যায়ন এখানে নিম্নলিখিতগুলি জড়িত:
- সার্ভার আইটেমটি ম্যাট্রিক্স পাঠায় \(I\) নমুনা মূল্যায়ন গ্রাহকদের
- প্রতিটি ক্লায়েন্ট স্থির \(I\) এবং তাদের ইউজার এম্বেডিং রেলগাড়ি \(U_u\) SGD এক বা একাধিক পদক্ষেপ ব্যবহার (পুনর্গঠন)
- প্রতিটি ক্লায়েন্ট গণনা করে কমে যাওয়া এবং বৈশিষ্ট্যের মান সার্ভার ব্যবহার \(I\) ও পুনঃনির্মাণ \(U_u\) তাদের স্থানীয় ডেটার একটি অদেখা অংশে
- সামগ্রিক ক্ষতি এবং মেট্রিক্স গণনা করতে ব্যবহারকারীদের জুড়ে লোকসান এবং মেট্রিক্স গড় করা হয়
মনে রাখবেন যে ধাপ 1 এবং 2 প্রশিক্ষণের জন্য একই। এই সংযোগ গুরুত্বপূর্ণ, মেটা-শিক্ষা, বা কীভাবে শেখার একটি ফর্ম একই আমরা যেভাবে বিশালাকার মূল্যায়ন প্রশিক্ষণ গেছে। এই ক্ষেত্রে, মডেলটি শিখছে কিভাবে গ্লোবাল ভেরিয়েবল (আইটেম ম্যাট্রিক্স) শিখতে হয় যা স্থানীয় ভেরিয়েবলের (ব্যবহারকারীর এম্বেডিং) কার্যকারিতা পুনর্গঠনের দিকে পরিচালিত করে। এই সম্পর্কে আরো জানার জন্য দেখুন সেকেন্ড। 4.2 কাগজ।
ন্যায্য মূল্যায়ন নিশ্চিত করতে ক্লায়েন্টদের স্থানীয় ডেটার বিচ্ছিন্ন অংশ ব্যবহার করে 2 এবং 3 ধাপগুলি সম্পাদন করাও গুরুত্বপূর্ণ। ডিফল্টরূপে, প্রশিক্ষণ প্রক্রিয়া এবং মূল্যায়ন গণনা উভয়ই পুনর্গঠনের জন্য অন্য প্রতিটি উদাহরণ ব্যবহার করে এবং পুনর্গঠনের পরবর্তী অর্ধেক ব্যবহার করে। এই আচরণ ব্যবহার কাস্টমাইজ করা যায় dataset_split_fn যুক্তি (আমরা এই বিষয়ে আরও পরে অন্বেষণ করব)।
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
আমরা পরবর্তীতে প্রশিক্ষণের একটি রাউন্ড চালানোর চেষ্টা করতে পারি। জিনিসগুলিকে আরও বাস্তবসম্মত করতে, আমরা প্রতিস্থাপন ছাড়াই এলোমেলোভাবে প্রতি রাউন্ডে 50 জন ক্লায়েন্টের নমুনা দেব৷ আমাদের এখনও ট্রেনের মেট্রিক্স খারাপ হওয়ার আশা করা উচিত, যেহেতু আমরা শুধুমাত্র এক রাউন্ড প্রশিক্ষণ করছি।
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
এখন একাধিক রাউন্ডে প্রশিক্ষণের জন্য একটি প্রশিক্ষণ লুপ সেট আপ করা যাক।
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
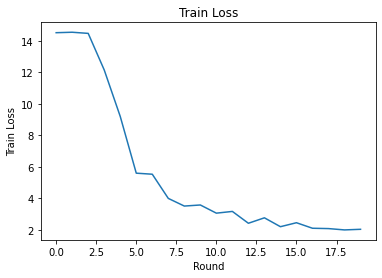
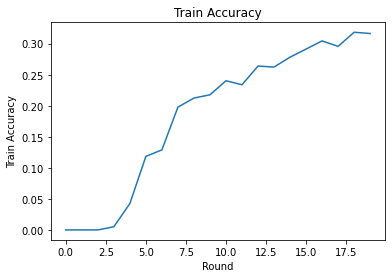
আমরা রাউন্ডে প্রশিক্ষণের ক্ষতি এবং নির্ভুলতা প্লট করতে পারি। এই নোটবুকের হাইপারপ্যারামিটারগুলি যত্ন সহকারে টিউন করা হয়নি, তাই এই ফলাফলগুলি উন্নত করতে প্রতি রাউন্ডে বিভিন্ন ক্লায়েন্ট, শেখার হার, রাউন্ডের সংখ্যা এবং মোট ক্লায়েন্টের সংখ্যা নির্দ্বিধায় চেষ্টা করুন।
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
অবশেষে, আমরা যখন টিউনিং শেষ করি তখন আমরা একটি অদেখা পরীক্ষার সেটে মেট্রিক্স গণনা করতে পারি।
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
আরও অনুসন্ধান
এই নোটবুক সম্পূর্ণ করার উপর চমৎকার কাজ. আমরা আংশিকভাবে স্থানীয় ফেডারেটেড লার্নিংকে আরও অন্বেষণ করার জন্য নিম্নলিখিত অনুশীলনের পরামর্শ দিই, মোটামুটিভাবে ক্রমবর্ধমান অসুবিধার মাধ্যমে:
ফেডারেটেড এভারেজিংয়ের সাধারণ প্রয়োগগুলি ডেটার উপর একাধিক স্থানীয় পাস (যুগ) নেয় (একাধিক ব্যাচ জুড়ে ডেটার উপর একটি পাস নেওয়া ছাড়াও)। ফেডারেটেড পুনর্গঠনের জন্য আমরা পুনর্গঠন এবং পুনর্গঠন পরবর্তী প্রশিক্ষণের জন্য আলাদাভাবে পদক্ষেপের সংখ্যা নিয়ন্ত্রণ করতে চাই। পাসিং
dataset_split_fnপ্রশিক্ষণ ও মূল্যায়ন গণনার বিল্ডার আর্গুমেন্ট প্রাপ্ত করতে পদক্ষেপ এবং উভয় পুনর্গঠন ও পোস্ট পুনর্গঠন ডেটাসেট উপর সময়কাল সংখ্যা নিয়ন্ত্রণ দেয়। একটি অনুশীলন হিসাবে, 50টি ধাপে সীমাবদ্ধ পুনর্গঠন প্রশিক্ষণের 3টি স্থানীয় যুগ এবং 50টি ধাপে সীমাবদ্ধ পুনর্গঠন পরবর্তী প্রশিক্ষণের 1টি স্থানীয় যুগ সম্পাদন করার চেষ্টা করুন৷ ইঙ্গিত: আপনি পাবেনtff.learning.reconstruction.build_dataset_split_fnসহায়ক। একবার আপনি এটি সম্পন্ন করার পরে, আরও ভাল ফলাফল পেতে এই হাইপারপ্যারামিটার এবং অন্যান্য সম্পর্কিত বিষয়গুলি যেমন শেখার হার এবং ব্যাচের আকার টিউন করার চেষ্টা করুন।ফেডারেটেড পুনর্গঠন প্রশিক্ষণ এবং মূল্যায়নের ডিফল্ট আচরণ হল ক্লায়েন্টদের স্থানীয় ডেটা প্রতিটি পুনর্গঠন এবং পরবর্তী পুনর্গঠনের জন্য অর্ধেক ভাগ করা। যে ক্ষেত্রে ক্লায়েন্টদের খুব কম স্থানীয় ডেটা থাকে, শুধুমাত্র প্রশিক্ষণ প্রক্রিয়ার জন্য পুনর্গঠন এবং পুনর্গঠনের জন্য ডেটা পুনরায় ব্যবহার করা যুক্তিসঙ্গত হতে পারে (মূল্যায়নের জন্য নয়, এটি অন্যায্য মূল্যায়নের দিকে পরিচালিত করবে)। , প্রশিক্ষণ প্রক্রিয়ার জন্য এই পরিবর্তন করার নিশ্চিত করার চেষ্টা করুন
dataset_split_fnনিরীক্ষার জন্য এখনো পুনর্গঠন ও পোস্ট পুনর্গঠন তথ্য গ্রন্থিচ্যুত রাখে। ইঙ্গিত:tff.learning.reconstruction.simple_dataset_split_fnসহায়ক হতে পারে।সর্বোপরি, আমরা একটি উত্পাদিত
tff.learning.Modelব্যবহার করে একটি Keras মডেল থেকেtff.learning.reconstruction.from_keras_model। আমরা দ্বারা বিশুদ্ধ TensorFlow 2.0 ব্যবহার করে একটি কাস্টম মডেল বাস্তবায়ন করতে পারে মডেল ইন্টারফেস বাস্তবায়ন । সংশোধন করার চেষ্টা করুনget_matrix_factorization_modelনির্মাণ ও একটি বর্গ যে প্রসারিত করে ফিরে যাওয়ারtff.learning.reconstruction.Model, তার পদ্ধতি বাস্তবায়ন। ইঙ্গিত: সোর্স কোডtff.learning.reconstruction.from_keras_modelব্যাপ্ত একটি উদাহরণ প্রদান করেtff.learning.reconstruction.Modelবর্গ। এছাড়াও পড়ুন EMNIST ইমেজ শ্রেণীবিন্যাস টিউটোরিয়ালে কাস্টম মডেল বাস্তবায়ন একটি ব্যাপ্ত মধ্যে একটি অনুরূপ ব্যায়াম জন্যtff.learning.Model।এই টিউটোরিয়ালে, আমরা ম্যাট্রিক্স ফ্যাক্টরাইজেশনের প্রেক্ষাপটে আংশিকভাবে স্থানীয় ফেডারেটেড লার্নিংকে অনুপ্রাণিত করেছি, যেখানে সার্ভারে ব্যবহারকারীর এম্বেডিং পাঠানোর ফলে ব্যবহারকারীর পছন্দগুলি তুচ্ছভাবে ফাঁস হবে। যোগাযোগ হ্রাস করার সময় (যেহেতু স্থানীয় পরামিতিগুলি সার্ভারে পাঠানো হয় না) আরও ব্যক্তিগত মডেলকে প্রশিক্ষণ দেওয়ার উপায় হিসাবে আমরা অন্যান্য সেটিংসে ফেডারেটেড পুনর্গঠন প্রয়োগ করতে পারি (যেহেতু মডেলের অংশটি প্রতিটি ব্যবহারকারীর জন্য সম্পূর্ণ স্থানীয়)। সাধারণভাবে, এখানে উপস্থাপিত ইন্টারফেস ব্যবহার করে আমরা যে কোনো ফেডারেটেড মডেল নিতে পারি যা সাধারণত বিশ্বব্যাপী সম্পূর্ণভাবে প্রশিক্ষিত হবে এবং পরিবর্তে এর ভেরিয়েবলগুলিকে গ্লোবাল ভেরিয়েবল এবং স্থানীয় ভেরিয়েবলে বিভক্ত করে। উদাহরণে অন্বেষণ ফেডারেটেড রিকনস্ট্রাকশন কাগজ ব্যক্তিগত পরবর্তী শব্দের পূর্বানুমান হল: এখানে প্রত্যেক ব্যবহারকারীর আউট-অফ-শব্দভান্ডার শব্দের জন্য শব্দ embeddings তাদের নিজস্ব স্থানীয় সেট আছে, ক্যাপচার ব্যবহারকারীদের অপভাষা করার মডেল সক্রিয় এবং অতিরিক্ত যোগাযোগ ছাড়া ব্যক্তিগতকরণ অর্জন করে। একটি অনুশীলন হিসাবে, ফেডারেটেড পুনর্গঠনের সাথে ব্যবহারের জন্য একটি ভিন্ন মডেল (কেরাস মডেল বা একটি কাস্টম টেনসরফ্লো 2.0 মডেল হিসাবে) প্রয়োগ করার চেষ্টা করুন। একটি পরামর্শ: একটি ব্যক্তিগত ব্যবহারকারী এম্বেডিং সহ একটি EMNIST শ্রেণীবিভাগ মডেল বাস্তবায়ন করুন, যেখানে ব্যক্তিগত ব্যবহারকারী এমবেডিং মডেলের শেষ ঘন স্তরের আগে CNN চিত্র বৈশিষ্ট্যের সাথে সংযুক্ত থাকে। আপনি এই টিউটোরিয়াল থেকে কোড (যেমন অনেক পুনরায় ব্যবহার করতে পারেন
UserEmbeddingবর্গ) এবং ইমেজ শ্রেণীবিন্যাস টিউটোরিয়াল ।
আপনি যদি এখনও আংশিকভাবে স্থানীয় ফেডারেট শেখার উপর খুঁজছেন আরো থাকেন, তবে খুঁজে বার করো ফেডারেটেড রিকনস্ট্রাকশন কাগজ এবং ওপেন সোর্স পরীক্ষা কোড ।