
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini membahas pembelajaran Federasi sebagian lokal, di mana beberapa parameter klien tidak pernah dikumpulkan pada server. Ini berguna untuk model dengan parameter khusus pengguna (misalnya model faktorisasi matriks) dan untuk pelatihan dalam pengaturan terbatas komunikasi. Kami membangun konsep-konsep yang diperkenalkan di Belajar Federated untuk Gambar Klasifikasi tutorial; seperti di tutorial itu, kami memperkenalkan API tingkat tinggi di tff.learning untuk pelatihan federasi dan evaluasi.
Kita mulai dengan memotivasi belajar federasi sebagian lokal untuk matriks faktorisasi . Kami menjelaskan Federasi Rekonstruksi ( kertas , posting blog ), algoritma praktis untuk belajar Federasi sebagian berskala lokal. Kami menyiapkan kumpulan data MovieLens 1M, membangun sebagian model lokal, dan melatih serta mengevaluasinya.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
Latar Belakang: Faktorisasi Matriks
Matrix faktorisasi telah menjadi teknik historis populer untuk belajar rekomendasi, dan embedding representasi untuk item berdasarkan interaksi pengguna. Contoh kanonik adalah rekomendasi film, di mana ada \(n\) pengguna dan \(m\) film, dan pengguna telah dinilai beberapa film. Mengingat seorang pengguna, kami menggunakan riwayat peringkat mereka dan peringkat pengguna serupa untuk memprediksi peringkat pengguna untuk film yang belum mereka lihat. Jika kami memiliki model yang dapat memprediksi peringkat, mudah untuk merekomendasikan pengguna film baru yang akan mereka nikmati.
Untuk tugas ini, ini berguna untuk mewakili peringkat pengguna sebagai \(n \times m\) matriks \(R\):

Matriks ini umumnya jarang, karena pengguna biasanya hanya melihat sebagian kecil film dalam kumpulan data. Output dari matriks Faktorisasi adalah dua matriks: sebuah \(n \times k\) matriks \(U\) mewakili \(k\)embeddings berdimensi pengguna untuk setiap pengguna, dan \(m \times k\) matriks \(I\) mewakili \(k\)embeddings barang berdimensi untuk setiap item. Tujuan pelatihan yang paling sederhana adalah untuk memastikan bahwa produk titik pengguna dan barang embeddings merupakan prediksi peringkat diamati \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
Ini setara dengan meminimalkan kesalahan kuadrat rata-rata antara peringkat yang diamati dan peringkat yang diprediksi dengan mengambil produk titik dari pengguna yang sesuai dan penyematan item. Cara lain untuk menafsirkan ini yang memastikan bahwa \(R \approx UI^T\) untuk peringkat dikenal, maka "matriks faktorisasi". Jika ini membingungkan, jangan khawatir–kita tidak perlu mengetahui detail faktorisasi matriks untuk sisa tutorial.
Menjelajahi Data MovieLens
Mari kita mulai dengan memuat MovieLens 1M data, yang terdiri dari 1.000.209 peringkat film dari pengguna 6040 pada 3706 film.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
Mari muat dan jelajahi beberapa Pandas DataFrames yang berisi data rating dan film.
ratings_df, movies_df = load_movielens_data()
Kita dapat melihat bahwa setiap contoh peringkat memiliki peringkat dari 1-5, UserID yang sesuai, MovieID yang sesuai, dan stempel waktu.
ratings_df.head()
Setiap film memiliki judul dan kemungkinan beberapa genre.
movies_df.head()
Itu selalu merupakan ide yang baik untuk memahami statistik dasar kumpulan data:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
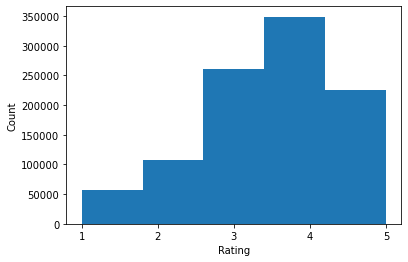
Average rating: 3.581564453029317 Median rating: 4.0
Kami juga dapat memplot genre film paling populer.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
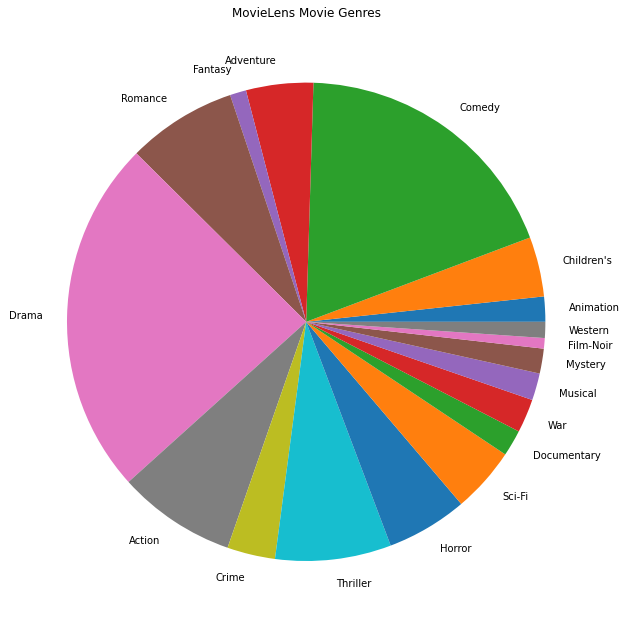
Data ini secara alami dipartisi ke dalam peringkat dari pengguna yang berbeda, jadi kami mengharapkan beberapa heterogenitas dalam data antar klien. Di bawah ini kami menampilkan genre film yang paling sering dinilai untuk pengguna yang berbeda. Kami dapat mengamati perbedaan yang signifikan antara pengguna.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
Memproses Data MovieLens
Kita sekarang akan mempersiapkan dataset MovieLens sebagai daftar tf.data.Dataset s merepresentasikan data setiap pengguna untuk digunakan dengan TFF.
Kami menerapkan dua fungsi:
-
create_tf_datasets: mengambil peringkat kami DataFrame dan menghasilkan daftar pengguna-splittf.data.Datasets. -
split_tf_datasets: mengambil daftar dataset dan perpecahan mereka ke kereta / val / test oleh pengguna, sehingga val / set tes hanya berisi penilaian dari pengguna yang tak terlihat selama pelatihan. Biasanya dalam standar matriks faktorisasi terpusat kita benar-benar berpisah sehingga set val / test mengandung diadakan-out peringkat dari pengguna dilihat, karena pengguna tak terlihat tidak memiliki embeddings pengguna. Dalam kasus kita, kita akan melihat nanti bahwa pendekatan yang kita gunakan untuk mengaktifkan faktorisasi matriks di FL juga memungkinkan dengan cepat merekonstruksi penyematan pengguna untuk pengguna yang tidak terlihat.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
Sebagai pemeriksaan cepat, kami dapat mencetak kumpulan data pelatihan. Kita dapat melihat bahwa setiap contoh individu berisi MovieID di bawah kunci "x" dan peringkat di bawah kunci "y". Perhatikan bahwa kami tidak memerlukan UserID karena setiap pengguna hanya melihat data mereka sendiri.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
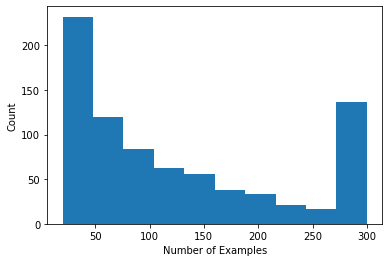
Kami dapat memplot histogram yang menunjukkan jumlah peringkat per pengguna.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
Sekarang setelah kita memuat dan menjelajahi data, kita akan membahas bagaimana membawa faktorisasi matriks ke pembelajaran federasi. Sepanjang jalan, kami akan memotivasi sebagian pembelajaran federasi lokal.
Membawa Faktorisasi Matriks ke FL
Meskipun faktorisasi matriks telah digunakan secara tradisional dalam pengaturan terpusat, ini sangat relevan dalam pembelajaran gabungan: peringkat pengguna dapat hidup di perangkat klien yang terpisah, dan kami mungkin ingin mempelajari penyematan dan rekomendasi untuk pengguna dan item tanpa memusatkan data. Karena setiap pengguna memiliki penyematan pengguna yang sesuai, wajar jika setiap klien menyimpan penyematan pengguna mereka – skala ini jauh lebih baik daripada server pusat yang menyimpan semua penyematan pengguna.
Satu proposal untuk membawa faktorisasi matriks ke FL adalah sebagai berikut:
- Toko server dan mengirimkan item matriks \(I\) kepada klien sampel setiap putaran
- Klien memperbarui matriks barang dan pengguna pribadi mereka embedding \(U_u\) menggunakan SGD pada tujuan di atas
- Update \(I\) dikumpulkan di server, memperbarui salinan server \(I\) untuk putaran berikutnya
Pendekatan ini sebagian lokal -yaitu adalah, beberapa parameter klien tidak pernah dikumpulkan oleh server. Meskipun pendekatan ini menarik, ini mengharuskan klien untuk mempertahankan status di seluruh putaran, yaitu penyematan pengguna mereka. Algoritme federasi stateful kurang sesuai untuk pengaturan FL lintas perangkat: dalam pengaturan ini ukuran populasi seringkali jauh lebih besar daripada jumlah klien yang berpartisipasi dalam setiap putaran, dan klien biasanya berpartisipasi paling banyak satu kali selama proses pelatihan. Selain mengandalkan negara yang mungkin tidak diinisialisasi, algoritma stateful dapat mengakibatkan penurunan kinerja dalam pengaturan lintas-perangkat karena negara mendapatkan basi ketika klien jarang sampel. Yang penting, dalam pengaturan faktorisasi matriks, algoritme stateful menyebabkan semua klien yang tidak terlihat kehilangan penyematan pengguna terlatih, dan dalam pelatihan skala besar sebagian besar pengguna mungkin tidak terlihat. Untuk lebih lanjut tentang motivasi untuk algoritma stateless di lintas-perangkat FL, melihat Wang et al. 2021 Detik. 3.1.1 dan Reddi et al. 2020 Detik. 5.1 .
Federasi Rekonstruksi ( Singhal et al. 2021 ) adalah alternatif stateless dengan pendekatan tersebut. Ide utamanya adalah bahwa alih-alih menyimpan penyematan pengguna di seluruh putaran, klien merekonstruksi penyematan pengguna saat dibutuhkan. Ketika FedRecon diterapkan pada faktorisasi matriks, pelatihan berlangsung sebagai berikut:
- Toko server dan mengirimkan item matriks \(I\) kepada klien sampel setiap putaran
- Setiap klien membeku \(I\) dan melatih pengguna mereka embedding \(U_u\) menggunakan satu atau lebih langkah dari SGD (rekonstruksi)
- Setiap klien membeku \(U_u\) dan kereta \(I\) menggunakan satu atau lebih langkah dari SGD
- Update \(I\) dikumpulkan seluruh pengguna, memperbarui salinan server \(I\) untuk putaran berikutnya
Pendekatan ini tidak mengharuskan klien untuk mempertahankan status di seluruh putaran. Penulis juga menunjukkan dalam makalah bahwa metode ini mengarah pada rekonstruksi cepat dari embeddings pengguna untuk klien yang tidak terlihat (Bag. 4.2, Gambar. 3, dan Tabel 1), memungkinkan sebagian besar klien yang tidak berpartisipasi dalam pelatihan untuk memiliki model yang terlatih , mengaktifkan rekomendasi untuk klien ini. Lihat Federated Rekonstruksi Google AI Blog post untuk hasil yang lebih utama.
Mendefinisikan Model
Selanjutnya kita akan mendefinisikan model faktorisasi matriks lokal untuk dilatih pada perangkat klien. Model ini akan mencakup penuh barang matriks \(I\) dan pengguna embedding tunggal \(U_u\) untuk klien \(u\). Perhatikan bahwa klien tidak perlu menyimpan penuh matriks pengguna \(U\).
Kami akan mendefinisikan yang berikut:
-
UserEmbedding: a Keras lapisan sederhana mewakili satunum_latent_factorsberdimensi pengguna embedding. -
get_matrix_factorization_model: fungsi yang mengembalikan sebuahtff.learning.reconstruction.Modelmengandung logika Model, termasuk yang lapisan global dikumpulkan pada server dan yang lapisan tetap lokal. Kami membutuhkan informasi tambahan ini untuk menginisialisasi proses pelatihan Rekonstruksi Federasi. Di sini kita menghasilkantff.learning.reconstruction.Modeldari model Keras menggunakantff.learning.reconstruction.from_keras_model. Mirip dengantff.learning.Model, kami juga dapat menerapkan kustomtff.learning.reconstruction.Modeldengan menerapkan antarmuka kelas.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
Analog dengan antarmuka untuk Federasi Averaging, antarmuka untuk Federasi Rekonstruksi mengharapkan model_fn tanpa argumen bahwa return suatu tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
Kami selanjutnya akan menentukan loss_fn dan metrics_fn , di mana loss_fn adalah fungsi tidak-argumen kembali kerugian Keras digunakan untuk melatih model, dan metrics_fn adalah fungsi tidak-argumen kembali daftar metrik Keras untuk evaluasi. Ini diperlukan untuk membangun perhitungan pelatihan dan evaluasi.
Kami akan menggunakan Mean Squared Error sebagai kerugian, seperti yang disebutkan di atas. Untuk evaluasi, kami akan menggunakan akurasi peringkat (ketika produk titik prediksi model dibulatkan ke bilangan bulat terdekat, seberapa sering cocok dengan peringkat label?).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
Pelatihan dan Evaluasi
Sekarang kami memiliki semua yang kami butuhkan untuk menentukan proses pelatihan. Salah satu perbedaan penting dari antarmuka untuk Federated Averaging adalah bahwa kita sekarang lulus dalam reconstruction_optimizer_fn , yang akan digunakan ketika merekonstruksi parameter lokal (dalam kasus kami, embeddings pengguna). Ini umumnya masuk akal untuk menggunakan SGD di sini, dengan sama atau sedikit menurunkan suku belajar dari klien optimizer tingkat belajar. Kami menyediakan konfigurasi kerja di bawah ini. Ini belum disetel dengan hati-hati, jadi jangan ragu untuk bermain-main dengan nilai-nilai yang berbeda.
Check out dokumentasi untuk rincian lebih lanjut dan pilihan.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
Kami juga dapat menentukan perhitungan untuk mengevaluasi model global kami yang terlatih.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
Kita dapat menginisialisasi status proses pelatihan dan memeriksanya. Yang terpenting, kita dapat melihat bahwa status server ini hanya menyimpan variabel item (saat ini diinisialisasi secara acak) dan bukan penyematan pengguna.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
Kami juga dapat mencoba mengevaluasi model kami yang diinisialisasi secara acak pada klien validasi. Evaluasi Rekonstruksi Federasi di sini melibatkan hal-hal berikut:
- Server akan mengirimkan item matriks \(I\) kepada klien evaluasi sampel
- Setiap klien membeku \(I\) dan melatih pengguna mereka embedding \(U_u\) menggunakan satu atau lebih langkah dari SGD (rekonstruksi)
- Setiap klien menghitung kerugian dan metrik menggunakan server \(I\) dan direkonstruksi \(U_u\) pada bagian yang tak terlihat dari data lokal mereka
- Kerugian dan metrik dirata-ratakan di seluruh pengguna untuk menghitung kerugian dan metrik secara keseluruhan
Perhatikan bahwa langkah 1 dan 2 sama seperti untuk pelatihan. Koneksi ini penting, karena melatih dengan cara yang sama kita mengevaluasi mengarah pada bentuk meta-learning, atau belajar bagaimana belajar. Dalam hal ini, model belajar bagaimana mempelajari variabel global (matriks item) yang mengarah pada rekonstruksi kinerja variabel lokal (penyematan pengguna). Untuk lebih lanjut tentang ini, lihat Sec. 4.2 dari kertas.
Langkah 2 dan 3 juga penting untuk dilakukan dengan menggunakan bagian data lokal klien yang terpisah, untuk memastikan evaluasi yang adil. Secara default, baik proses pelatihan dan perhitungan evaluasi menggunakan setiap contoh lain untuk rekonstruksi dan menggunakan setengah lainnya setelah rekonstruksi. Perilaku ini dapat disesuaikan dengan menggunakan dataset_split_fn argumen (kami akan menjelajahi lebih lanjut kemudian).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
Kami selanjutnya dapat mencoba menjalankan putaran pelatihan. Untuk membuat segalanya lebih realistis, kami akan mengambil sampel 50 klien per putaran secara acak tanpa pengembalian. Kami masih mengharapkan metrik kereta menjadi buruk, karena kami hanya melakukan satu putaran pelatihan.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
Sekarang mari kita siapkan lingkaran pelatihan untuk melatih beberapa putaran.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
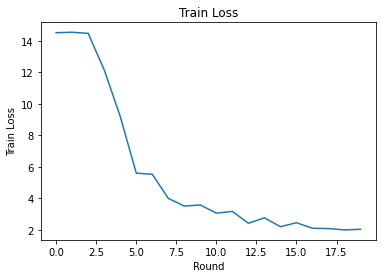
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
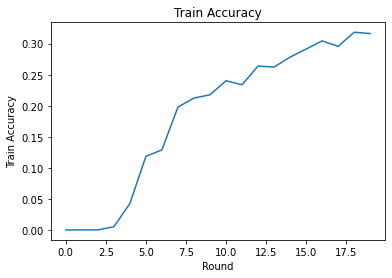
Kami dapat merencanakan kehilangan latihan dan akurasi selama putaran. Hyperparameter di notebook ini belum disetel dengan cermat, jadi jangan ragu untuk mencoba klien yang berbeda per putaran, kecepatan pembelajaran, jumlah putaran, dan jumlah total klien untuk meningkatkan hasil ini.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
Terakhir, kami dapat menghitung metrik pada set pengujian yang tidak terlihat saat kami selesai menyetel.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
Eksplorasi Lebih Lanjut
Selamat menyelesaikan buku catatan ini. Kami menyarankan latihan-latihan berikut untuk mengeksplorasi pembelajaran gabungan lokal sebagian lebih lanjut, yang disusun secara kasar dengan meningkatnya kesulitan:
Implementasi khas dari Federated Averaging mengambil beberapa lintasan lokal (zaman) atas data (selain mengambil satu lintasan data di beberapa kumpulan). Untuk Rekonstruksi Federasi, kami mungkin ingin mengontrol jumlah langkah secara terpisah untuk pelatihan rekonstruksi dan pasca-rekonstruksi. Melewati
dataset_split_fnargumen untuk pembangun perhitungan pelatihan dan evaluasi memungkinkan kontrol dari jumlah langkah dan zaman lebih baik dataset rekonstruksi dan pasca-rekonstruksi. Sebagai latihan, coba lakukan 3 periode lokal pelatihan rekonstruksi, dibatasi pada 50 langkah dan 1 periode lokal pelatihan pasca-rekonstruksi, dibatasi pada 50 langkah. Petunjuk: Anda akan menemukantff.learning.reconstruction.build_dataset_split_fnmembantu. Setelah Anda selesai melakukannya, coba setel hyperparameter ini dan yang terkait lainnya seperti kecepatan pembelajaran dan ukuran batch untuk mendapatkan hasil yang lebih baik.Perilaku default pelatihan dan evaluasi Rekonstruksi Federasi adalah membagi data lokal klien menjadi dua untuk setiap rekonstruksi dan pasca-rekonstruksi. Dalam kasus di mana klien memiliki data lokal yang sangat sedikit, adalah masuk akal untuk menggunakan kembali data untuk rekonstruksi dan pasca-rekonstruksi hanya untuk proses pelatihan (bukan untuk evaluasi, ini akan menyebabkan evaluasi yang tidak adil). Mencoba membuat perubahan ini untuk proses pelatihan, memastikan
dataset_split_fnuntuk evaluasi masih terus rekonstruksi dan pasca-rekonstruksi data yang menguraikan. Petunjuk:tff.learning.reconstruction.simple_dataset_split_fnmungkin berguna.Di atas, kita menghasilkan
tff.learning.Modeldari model Keras menggunakantff.learning.reconstruction.from_keras_model. Kami juga dapat menerapkan model kustom menggunakan murni TensorFlow 2.0 dengan mengimplementasikan interface model yang . Cobalah memodifikasiget_matrix_factorization_modeluntuk membangun dan mengembalikan kelas yang memanjangtff.learning.reconstruction.Model, menerapkan metode-metode. Petunjuk: kode sumbertff.learning.reconstruction.from_keras_modelmemberikan contoh memperluastff.learning.reconstruction.Modelkelas. Merujuk juga untuk penerapan model kustom di EMNIST gambar klasifikasi tutorial untuk latihan yang sama dalam memperluastff.learning.Model.Dalam tutorial ini, kami telah memotivasi pembelajaran gabungan lokal sebagian dalam konteks faktorisasi matriks, di mana pengiriman embeddings pengguna ke server akan secara sepele membocorkan preferensi pengguna. Kami juga dapat menerapkan Rekonstruksi Federasi di pengaturan lain sebagai cara untuk melatih lebih banyak model pribadi (karena sebagian model sepenuhnya bersifat lokal untuk setiap pengguna) sambil mengurangi komunikasi (karena parameter lokal tidak dikirim ke server). Secara umum, menggunakan antarmuka yang disajikan di sini kita dapat mengambil model federasi apa pun yang biasanya akan dilatih sepenuhnya secara global dan sebagai gantinya mempartisi variabelnya menjadi variabel global dan variabel lokal. Contoh dieksplorasi di kertas Federasi Rekonstruksi adalah pribadi berikutnya prediksi kata: di sini, setiap pengguna memiliki set lokal mereka sendiri embeddings kata untuk out-of-kosakata kata-kata, yang memungkinkan model untuk gaul menangkap pengguna dan mencapai personalisasi tanpa komunikasi tambahan. Sebagai latihan, coba terapkan (baik sebagai model Keras atau model TensorFlow 2.0 khusus) model yang berbeda untuk digunakan dengan Rekonstruksi Federasi. Saran: terapkan model klasifikasi EMNIST dengan penyematan pengguna pribadi, di mana penyematan pengguna pribadi digabungkan ke fitur gambar CNN sebelum lapisan Padat terakhir model. Anda dapat menggunakan kembali banyak kode dari tutorial ini (misalnya
UserEmbeddingkelas) dan gambar klasifikasi tutorial .
Jika Anda masih mencari lebih pada pembelajaran Federasi sebagian lokal, memeriksa Federated Rekonstruksi kertas dan open-source code eksperimen .