
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В данном руководстве рассматривается частично местное федеративное обучение, где некоторые параметры клиента никогда не агрегируется на сервере. Это полезно для моделей с пользовательскими параметрами (например, модели матричной факторизации) и для обучения в условиях ограниченного обмена данными. Мы строим на понятия , введенные в Федеративные обучения для изображения классификации учебник; так как в этом учебнике, мы вводим API - интерфейсы высокого уровня в tff.learning для федеративнога подготовки и оценки.
Мы начинаем с мотивирующим частично местным федеративным обучением для матричной прогонки . Опишу Федеративную Реконструкцию ( бумага , блог ), практический алгоритм частично местное объединение обучения в масштабе. Мы готовим набор данных MovieLens 1M, строим частично локальную модель, обучаем и оцениваем ее.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
Справочная информация: матричная факторизация
Матрица факторизации была исторически популярный метод для изучения рекомендаций и внедрение представлений для элементов на основе взаимодействия с пользователем. Канонический пример рекомендация фильма, где есть \(n\) пользователи и \(m\) фильмы, и пользователи оценили некоторые фильмы. Учитывая пользователя, мы используем историю его рейтингов и рейтинги похожих пользователей, чтобы прогнозировать рейтинги пользователей для фильмов, которые они не смотрели. Если у нас есть модель, которая может прогнозировать рейтинги, легко рекомендовать пользователям новые фильмы, которые им понравятся.
Для решения этой задачи, полезно представлять рейтинги пользователей как \(n \times m\) матрицы \(R\):

Эта матрица, как правило, разрежена, поскольку пользователи обычно видят только небольшую часть фильмов в наборе данных. Выход матричной прогонки состоит из двух матриц: \(n \times k\) матрицы \(U\) , представляющий \(k\)вложения -мерного пользователя для каждого пользователя, и \(m \times k\) матрица \(I\) , представляющий \(k\)-мерного вложения позиций для каждого элемента. Самая простая задача обучения является обеспечение того , скалярное произведение пользователей и элементов вложений являются предсказанием наблюдаемых оценок \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
Это эквивалентно минимизации среднеквадратичной ошибки между наблюдаемыми оценками и оценками, предсказанными путем скалярного произведения соответствующих вложений пользователя и элемента. Другой способ интерпретировать это в том , что это гарантирует , что \(R \approx UI^T\) для известных оценок, следовательно , «матричной прогонки». Если это сбивает с толку, не беспокойтесь — нам не нужно знать детали матричной факторизации до конца урока.
Изучение данных MovieLens
Давайте начнем с загрузкой MovieLens 1M данных, состоящие из 1,000,209 рейтингов фильмов от 6040 пользователей на 3706 фильмов.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
Давайте загрузим и изучим пару Pandas DataFrames, содержащих данные рейтинга и фильма.
ratings_df, movies_df = load_movielens_data()
Мы видим, что каждый пример рейтинга имеет рейтинг от 1 до 5, соответствующий UserID, соответствующий MovieID и отметку времени.
ratings_df.head()
У каждого фильма есть название и, возможно, несколько жанров.
movies_df.head()
Всегда полезно понимать базовую статистику набора данных:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
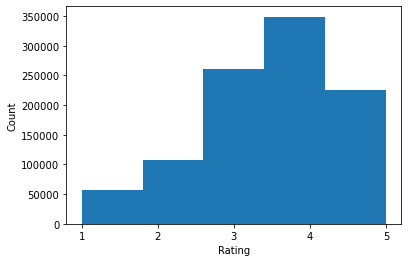
Average rating: 3.581564453029317 Median rating: 4.0
Мы также можем создавать сюжеты самых популярных жанров кино.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
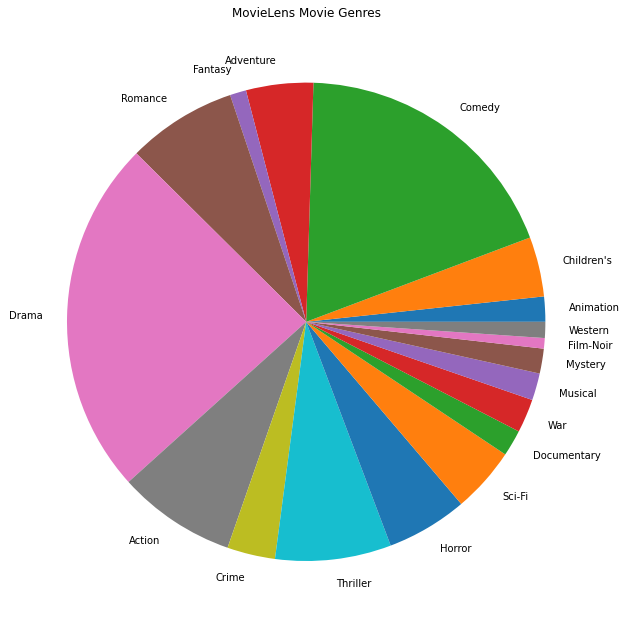
Эти данные естественным образом разделены на рейтинги от разных пользователей, поэтому мы ожидаем некоторой неоднородности данных между клиентами. Ниже мы показываем самые популярные жанры фильмов для разных пользователей. Мы можем наблюдать значительные различия между пользователями.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
Предварительная обработка данных MovieLens
Теперь мы будем готовить набор данных MovieLens как список tf.data.Dataset s представляющих данные каждого пользователя для использования с TFF.
Реализуем две функции:
-
create_tf_datasets: принимает наши рейтинги DataFrame и выдает список пользователей расщепленнойtf.data.Datasets. -
split_tf_datasets: принимает список наборов данных и разбивают их на поезд / вал / тест по пользователю, так знач / тестовые наборы содержат только оценки от пользователей невидимых во время тренировки. Как правило , в стандартной централизованной матричной прогонки мы фактически разделить так , что Вэл / тестовые наборы содержат удерживаемые из рейтингов от увиденного пользователей, так как невидимые пользователи не имеют вложения пользователей. В нашем случае позже мы увидим, что подход, который мы используем для включения матричной факторизации в FL, также позволяет быстро реконструировать пользовательские вложения для невидимых пользователей.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
В качестве быстрой проверки мы можем распечатать пакет обучающих данных. Мы видим, что каждый отдельный пример содержит MovieID под ключом «x» и рейтинг под ключом «y». Обратите внимание, что нам не понадобится UserID, так как каждый пользователь видит только свои данные.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
Мы можем построить гистограмму, показывающую количество оценок на одного пользователя.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
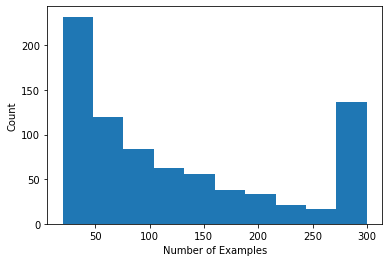
Теперь, когда мы загрузили и изучили данные, мы обсудим, как внедрить матричную факторизацию в федеративное обучение. Попутно мы будем мотивировать частично локальное федеративное обучение.
Внедрение матричной факторизации в FL
Хотя матричная факторизация традиционно использовалась в централизованных настройках, она особенно уместна в федеративном обучении: пользовательские рейтинги могут храниться на отдельных клиентских устройствах, и мы можем захотеть изучить вложения и рекомендации для пользователей и элементов без централизации данных. Поскольку у каждого пользователя есть соответствующее пользовательское внедрение, естественно, что каждый клиент хранит свое пользовательское внедрение — это намного лучше масштабируется, чем центральный сервер, хранящий все пользовательские внедрения.
Одно из предложений по внедрению матричной факторизации в FL звучит следующим образом:
- Сервер хранит и передает элемент матрицы \(I\) для выбранных клиентов каждый раунд
- Клиенты обновить матрицу элемента и их личного пользователя вложения \(U_u\) используя СГД по вышеуказанной цели
- Обновления \(I\) агрегируются на сервере, обновление сервера копии \(I\) для следующего раунда
Такой подход частично местный -Вот не некоторые параметры клиента никогда не объединяется сервер. Хотя этот подход привлекателен, он требует, чтобы клиенты сохраняли состояние на протяжении раундов, а именно свои пользовательские вложения. Федеративные алгоритмы с отслеживанием состояния менее подходят для настроек FL на нескольких устройствах: в этих настройках размер популяции часто намного превышает количество клиентов, участвующих в каждом раунде, и клиент обычно участвует не более одного раза в процессе обучения. Кроме того , опираясь на состояние , которое не может быть инициализирован, сохраняющие состояние алгоритмы могут привести к снижению производительности в настройках кросс-устройств за счет государства получать несвежих , когда клиенты редко пробы. Важно отметить, что в настройке матричной факторизации алгоритм с отслеживанием состояния приводит к тому, что все невидимые клиенты пропускают внедренные обученные пользователи, а при крупномасштабном обучении большинство пользователей могут быть невидимыми. Более подробную информацию о мотивации для алгоритмов лиц без в кросс-устройства FL, см Wang и др. 2021 Сек. 3.1.1 и Редди и др. 2020 Сек. 5.1 .
Федеративная Реконструкция ( Сингал и др. 2021 ) является лицо без альтернативы вышеупомянутого подхода. Ключевая идея заключается в том, что вместо того, чтобы хранить пользовательские вложения по раундам, клиенты реконструируют пользовательские вложения, когда это необходимо. Когда FedRecon применяется к матричной факторизации, обучение происходит следующим образом:
- Сервер хранит и передает элемент матрицы \(I\) для выбранных клиентов каждый раунд
- Каждый клиент замораживает \(I\) и обучает их пользователь вложение \(U_u\) использования одного или несколько шагов SGD (реконструкция)
- Каждый клиент замораживает \(U_u\) и поезд \(I\) использование одного или несколько шагов SGD
- Обновления \(I\) объединяются между пользователями, обновлять серверную копию \(I\) для следующего раунда
Этот подход не требует, чтобы клиенты сохраняли состояние на протяжении раундов. Авторы также показывают в статье, что этот метод приводит к быстрой реконструкции пользовательских вложений для невидимых клиентов (раздел 4.2, рис. 3 и таблица 1), позволяя большинству клиентов, которые не участвуют в обучении, иметь обученную модель. , включив рекомендации для этих клиентов. См Федеративной Реконструкции Google AI Блог пост для более ключевых результатов.
Определение модели
Далее мы определим локальную матричную модель факторизации для обучения на клиентских устройствах. Эта модель будет включать в себя полный элемент матрицы \(I\) и один пользователь вложение \(U_u\) для клиента \(u\). Обратите внимание , что клиенты не должны будут хранить полную матрицу пользователя \(U\).
Мы определим следующее:
-
UserEmbedding: простой слой Keras представляющий собой одиночныеnum_latent_factors- мерный пользователь вложение. -
get_matrix_factorization_model: это функция , которая возвращаетtff.learning.reconstruction.Model, содержащая логику модели, в том числе слоев , которые глобально агрегируются на сервере , и какие слои остаются локальными. Нам нужна эта дополнительная информация для инициализации процесса обучения федеративной реконструкции. Здесь мы производимtff.learning.reconstruction.Modelот модели Keras с использованиемtff.learning.reconstruction.from_keras_model. Подобноtff.learning.Model, мы можем также реализовать собственныйtff.learning.reconstruction.Modelпутем реализации интерфейса класса.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
К , аналогичный интерфейс для федеративного усреднении, интерфейс для федеративной реконструкции ожидает model_fn без аргументов , который возвращает tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
Мы рядом определим loss_fn и metrics_fn , где loss_fn функция без аргументов возвращает потери Keras использовать для обучения модели, и metrics_fn функция без аргументов возвращает список метрик Keras для оценки. Они необходимы для построения обучающих и оценочных вычислений.
Мы будем использовать среднеквадратичную ошибку в качестве потерь, как упоминалось выше. Для оценки мы будем использовать точность рейтинга (когда прогнозируемый скалярный продукт модели округляется до ближайшего целого числа, как часто он соответствует рейтингу метки?).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
Обучение и оценка
Теперь у нас есть все необходимое для определения тренировочного процесса. Одно важное отличие от интерфейса для федеративного усреднении является то , что мы теперь проходим в reconstruction_optimizer_fn , который будет использоваться при реконструкции локальных параметров (в нашем случае, пользователь вложениями). Это вообще разумно использовать SGD здесь, с такой же или немного ниже скорости обучения , чем клиент оптимизатора скорость обучения. Мы предоставляем рабочую конфигурацию ниже. Это не было тщательно настроено, поэтому не стесняйтесь экспериментировать с различными значениями.
Проверьте документацию для получения более подробной информации и опций.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
Мы также можем определить вычисление для оценки нашей обученной глобальной модели.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
Мы можем инициализировать состояние тренировочного процесса и проверить его. Самое главное, мы видим, что это состояние сервера хранит только переменные элементов (в настоящее время инициализированные случайным образом), а не какие-либо пользовательские вложения.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
Мы также можем попытаться оценить нашу случайно инициализированную модель на клиентах проверки. Оценка федеративной реконструкции здесь включает в себя следующее:
- Сервер отправляет элемент матрицы \(I\) для выбранных клиентов оценки
- Каждый клиент замораживает \(I\) и обучает их пользователь вложение \(U_u\) использования одного или несколько шагов SGD (реконструкция)
- Каждый клиент вычисляет потери и метрики с использованием сервера \(I\) и восстановленное \(U_u\) на невидимой части своих локальных данных
- Потери и показатели усредняются по пользователям для расчета общих потерь и показателей.
Обратите внимание, что шаги 1 и 2 такие же, как и для обучения. Это соединение имеет важное значение, так как обучение так же , как мы оцениваем , приводит к форме мета-обучения или обучения , как учиться. В этом случае модель учится изучать глобальные переменные (матрицу элементов), что приводит к эффективной реконструкции локальных переменных (встраивания пользователей). Более подробно об этом см . § 4,2 из бумаги.
Также важно, чтобы шаги 2 и 3 выполнялись с использованием непересекающихся частей локальных данных клиентов, чтобы обеспечить справедливую оценку. По умолчанию как в процессе обучения, так и в оценочных вычислениях для реконструкции используется каждый второй пример, а другая половина — после реконструкции. Такое поведение может быть настроено с помощью dataset_split_fn аргумента (мы рассмотрим это еще позже).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
Теперь мы можем попробовать провести раунд обучения. Чтобы сделать ситуацию более реалистичной, мы будем выбирать 50 клиентов за раунд случайным образом без замены. Мы по-прежнему должны ожидать, что показатели обучения будут плохими, поскольку мы проводим только один раунд обучения.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
Теперь давайте настроим тренировочный цикл, чтобы тренироваться в течение нескольких раундов.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
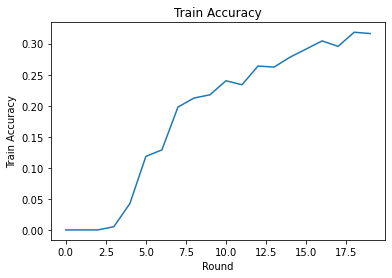
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
Мы можем построить тренировочные потери и точность по раундам. Гиперпараметры в этой записной книжке не были тщательно настроены, поэтому не стесняйтесь пробовать разных клиентов за раунд, скорость обучения, количество раундов и общее количество клиентов, чтобы улучшить эти результаты.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
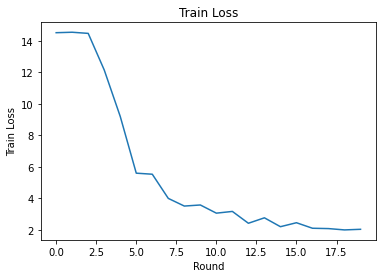
Наконец, мы можем рассчитать метрики для невидимого набора тестов, когда закончим настройку.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
Дальнейшие исследования
Хорошая работа по заполнению этой тетради. Мы предлагаем следующие упражнения для дальнейшего изучения частично локального федеративного обучения, примерно упорядоченные по возрастанию сложности:
Типичные реализации федеративного усреднения используют несколько локальных проходов (эпох) по данным (в дополнение к одному проходу по данным в нескольких пакетах). Для объединенной реконструкции мы можем захотеть контролировать количество шагов отдельно для реконструкции и обучения после реконструкции. Переходя
dataset_split_fnаргумента к обучению и оценки вычислительных строителям позволяет контролировать количество шагов и эпохи как по отношению к восстановлению и после реконструкции данных. В качестве упражнения попробуйте выполнить 3 локальные эпохи тренировки реконструкции, ограниченные 50 шагами, и 1 локальную эпоху тренировки после реконструкции, ограниченную 50 шагами. Подсказка: вы найдетеtff.learning.reconstruction.build_dataset_split_fnполезным. После того, как вы это сделаете, попробуйте настроить эти гиперпараметры и другие связанные параметры, такие как скорость обучения и размер пакета, чтобы получить лучшие результаты.Поведение по умолчанию при обучении и оценке федеративной реконструкции заключается в разделении локальных данных клиентов пополам для каждой реконструкции и пост-реконструкции. В тех случаях, когда у клиентов очень мало локальных данных, может быть разумно повторно использовать данные для реконструкции и пост-реконструкции только для учебного процесса (не для оценки, это приведет к несправедливой оценке). Попробуйте сделать это изменение учебного процесса, обеспечение
dataset_split_fnдля оценки до сих пор продолжает реконструкцию и после реконструкции непересекающихся данных. Подсказка:tff.learning.reconstruction.simple_dataset_split_fnможет быть полезным.Выше мы подготовили
tff.learning.Modelиз модели Keras с помощьюtff.learning.reconstruction.from_keras_model. Мы также можем реализовать пользовательскую модель с использованием чистого TensorFlow 2.0, реализующий интерфейс модели . Попробуйте изменитьget_matrix_factorization_modelпостроить и возвращает класс , который расширяетtff.learning.reconstruction.Model, реализуя свои методы. Подсказка: исходный кодtff.learning.reconstruction.from_keras_modelприведен пример расширенияtff.learning.reconstruction.Modelкласса. Обратитесь также к пользовательской реализации модели в классификации обучающей EMNIST изображения для подобного упражнения в расширяяtff.learning.Model.В этом руководстве мы мотивировали частично локальное федеративное обучение в контексте матричной факторизации, когда отправка пользовательских внедрений на сервер тривиально приведет к утечке пользовательских настроек. Мы также можем применить федеративную реконструкцию в других настройках как способ обучения более личных моделей (поскольку часть модели полностью локальна для каждого пользователя) при одновременном сокращении связи (поскольку локальные параметры не отправляются на сервер). В общем, используя представленный здесь интерфейс, мы можем взять любую федеративную модель, которая обычно обучается полностью глобально, и вместо этого разделить ее переменные на глобальные переменные и локальные переменные. В примере исследуется в статье Федеративной Реконструкции личностно предсказание следующего слова: здесь, каждый пользователь имеет свой собственный локальный набор слова вложения для вне-лексикона слов, что позволяет модели на жаргон пользователей захватывать и добиться персонализаций без дополнительной коммуникации. В качестве упражнения попробуйте реализовать (как модель Keras или пользовательскую модель TensorFlow 2.0) другую модель для использования с федеративной реконструкцией. Предложение: внедрить модель классификации EMNIST с личным внедрением пользователя, где личное внедрение пользователя объединяется с функциями изображения CNN перед последним плотным слоем модели. Вы можете повторно использовать большую часть кода из этого урока (например,
UserEmbeddingкласса) и изображения классификации учебника .
Если вы все еще ищете больше на частично местное федеративном обучении, проверить Федеративную Реконструкцию бумага и открытой исходный код эксперимента .