
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Questo tutorial esplora apprendimento federata in parte locale, dove alcuni parametri client sono mai aggregate sul server. Ciò è utile per i modelli con parametri specifici dell'utente (ad es. modelli di fattorizzazione a matrice) e per l'addestramento in impostazioni limitate alla comunicazione. Costruiamo su concetti introdotti nella Federati di apprendimento per un'immagine di classificazione esercitazione; come in quel tutorial, vi presentiamo le API di alto livello in tff.learning per la formazione federata e valutazione.
Iniziamo motivare apprendimento federata parzialmente locale matrice fattorizzazione . Descriviamo Federated la ricostruzione ( di carta , post sul blog ), un algoritmo pratico per l'apprendimento federata in parte locale su larga scala. Prepariamo il set di dati MovieLens 1M, costruiamo un modello parzialmente locale, lo addestriamo e lo valutiamo.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
Contesto: fattorizzazione della matrice
Matrix fattorizzazione è stata una tecnica storicamente popolare per l'apprendimento e l'incorporamento raccomandazioni rappresentazioni gli elementi in base alle interazioni dell'utente. L'esempio canonico è raccomandazione di film, dove ci sono \(n\) utenti e \(m\) film, e gli utenti hanno valutato alcuni film. Dato un utente, utilizziamo la cronologia delle valutazioni e le valutazioni di utenti simili per prevedere le valutazioni dell'utente per i film che non ha visto. Se disponiamo di un modello in grado di prevedere le valutazioni, è facile consigliare agli utenti nuovi film che apprezzeranno.
Per questo compito, è utile per rappresentare feedback degli utenti come un \(n \times m\) matrice \(R\):

Questa matrice è generalmente scarsa, poiché gli utenti in genere vedono solo una piccola frazione dei film nel set di dati. L'uscita della matrice di fattorizzazione è due matrici: un \(n \times k\) matrice \(U\) rappresenta \(k\)embeddings utente dimensionale per ogni utente, e un \(m \times k\) matrice \(I\) rappresenta \(k\)embeddings voce -dimensionale per ciascun elemento. L'obiettivo formativo più semplice è quello di garantire che il prodotto scalare di utenti e voce incastri sono predittivi di feedback osservati \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
Ciò equivale a ridurre al minimo l'errore quadratico medio tra le valutazioni osservate e le valutazioni previste prendendo il prodotto scalare dell'utente corrispondente e gli incorporamenti di elementi. Un altro modo di interpretare questo è che questo assicura che \(R \approx UI^T\) per valutazioni conosciuti, perciò "matrice fattorizzazione". Se questo crea confusione, non preoccuparti: non avremo bisogno di conoscere i dettagli della fattorizzazione della matrice per il resto del tutorial.
Esplorazione dei dati di MovieLens
Cominciamo caricando i MovieLens 1M di dati, che consiste di 1,000,209 feedback film dal 6040 utenti su 3706 film.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
Carichiamo ed esploriamo un paio di Panda DataFrame contenenti i dati di valutazione e film.
ratings_df, movies_df = load_movielens_data()
Possiamo vedere che ogni esempio di valutazione ha una valutazione da 1 a 5, un ID utente corrispondente, un ID film corrispondente e un timestamp.
ratings_df.head()
Ogni film ha un titolo e potenzialmente più generi.
movies_df.head()
È sempre una buona idea comprendere le statistiche di base del set di dati:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
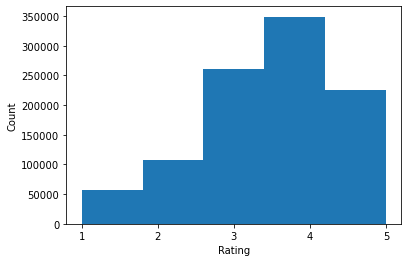
Average rating: 3.581564453029317 Median rating: 4.0
Possiamo anche tracciare i generi di film più popolari.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
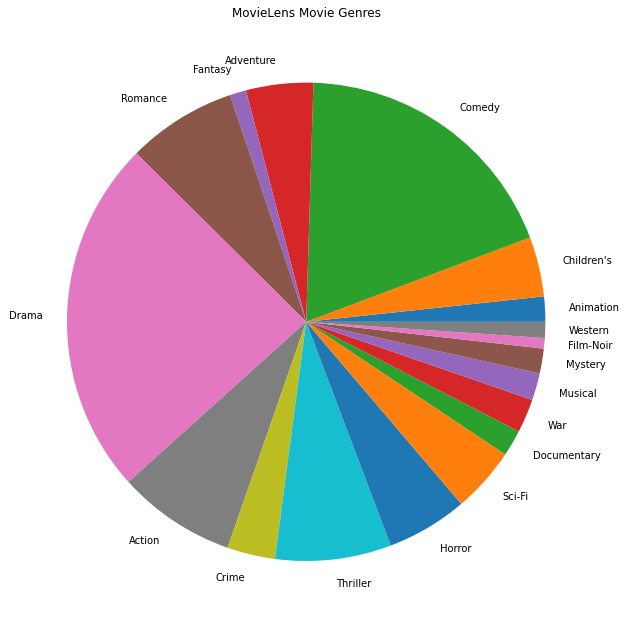
Questi dati sono naturalmente suddivisi in valutazioni di utenti diversi, quindi ci aspetteremmo una certa eterogeneità nei dati tra i clienti. Di seguito mostriamo i generi di film più comunemente valutati per diversi utenti. Possiamo osservare differenze significative tra gli utenti.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
Preelaborazione dei dati di MovieLens
Noi ora prepariamo il set di dati MovieLens come una lista di tf.data.Dataset rappresentare s di dati di ogni utente per l'utilizzo con TFF.
Implementiamo due funzioni:
-
create_tf_datasets: prende le nostre valutazioni dataframe e produce un elenco di utenti-splittf.data.Datasets. -
split_tf_datasets: prende una lista di set di dati e li divide in treno / val / test per utente, in modo che il val / set di test contengono solo feedback degli utenti invisibili durante l'allenamento. In genere nella norma fattorizzazione matrice centralizzato che in realtà diviso in modo che i set val / prova contengono feedback detenuti-out degli utenti visto, dal momento che gli utenti invisibili non hanno incastri degli utenti. Nel nostro caso, vedremo in seguito che l'approccio che utilizziamo per abilitare la fattorizzazione della matrice in FL consente anche di ricostruire rapidamente gli incorporamenti degli utenti per gli utenti non visti.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
Come controllo rapido, possiamo stampare un batch di dati di allenamento. Possiamo vedere che ogni singolo esempio contiene un MovieID sotto il tasto "x" e una valutazione sotto il tasto "y". Tieni presente che non avremo bisogno dell'ID utente poiché ogni utente vede solo i propri dati.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
Possiamo tracciare un istogramma che mostra il numero di valutazioni per utente.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
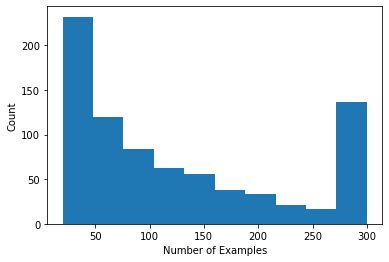
Ora che abbiamo caricato ed esplorato i dati, discuteremo come portare la fattorizzazione a matrice nell'apprendimento federato. Lungo la strada, motiveremo l'apprendimento federato parzialmente locale.
Portare la fattorizzazione della matrice in FL
Sebbene la fattorizzazione a matrice sia stata tradizionalmente utilizzata in ambienti centralizzati, è particolarmente rilevante nell'apprendimento federato: le valutazioni degli utenti possono risiedere su dispositivi client separati e potremmo voler apprendere incorporamenti e raccomandazioni per utenti ed elementi senza centralizzare i dati. Poiché ogni utente ha un'incorporamento utente corrispondente, è naturale che ogni client memorizzi l'incorporamento dell'utente: questo scala molto meglio di un server centrale che memorizza tutti gli incorporamenti dell'utente.
Una proposta per portare la fattorizzazione a matrice in FL è la seguente:
- Il server e invia le matrici oggetto \(I\) ai clienti campionate ogni round
- Client aggiornare la matrice elemento e il loro uso personale incorporamento \(U_u\) utilizzando SGD sull'obiettivo sopra
- Gli aggiornamenti per \(I\) sono aggregate sul server, aggiornando la copia sul server di \(I\) per il prossimo turno
Questo approccio è parzialmente locali -cioè, alcuni parametri client sono mai aggregate dal server. Sebbene questo approccio sia interessante, richiede ai client di mantenere lo stato durante i round, ovvero gli incorporamenti degli utenti. Gli algoritmi federati con stato sono meno appropriati per le impostazioni FL tra dispositivi: in queste impostazioni la dimensione della popolazione è spesso molto maggiore del numero di client che partecipano a ciascun round e un client di solito partecipa al massimo una volta durante il processo di formazione. Oltre basandosi sullo stato che non può essere inizializzato, algoritmi stateful possono comportare una riduzione delle prestazioni in ambienti cross-device causa dello stato ottenere stantio quando i client rado campionati. È importante sottolineare che nell'impostazione della fattorizzazione della matrice, un algoritmo stateful porta a tutti i client non visti che mancano gli incorporamenti dell'utente addestrato e nella formazione su larga scala la maggior parte degli utenti potrebbe non essere vista. Per maggiori informazioni sulla motivazione per gli algoritmi di apolidi in cross-device FL, vedere Wang et al. 2021 Sez. 3.1.1 e Reddi et al. 2020 Sez. 5.1 .
Federata ricostruzione ( Singhal et al. 2021 ) è uno stateless alternativa all'approccio summenzionato. L'idea chiave è che invece di archiviare gli incorporamenti dell'utente durante i round, i client ricostruiscono gli incorporamenti dell'utente quando necessario. Quando FedRecon viene applicato alla fattorizzazione a matrice, l'addestramento procede come segue:
- Il server e invia le matrici oggetto \(I\) ai clienti campionate ogni round
- Ogni cliente congela \(I\) e treni loro utenti l'incorporamento \(U_u\) utilizzando uno o più passi di SGD (ricostruzione)
- Ogni cliente congela \(U_u\) e treni \(I\) utilizzando uno o più passi di SGD
- Gli aggiornamenti per \(I\) sono aggregate attraverso gli utenti, aggiornando la copia sul server di \(I\) per il prossimo turno
Questo approccio non richiede ai client di mantenere lo stato tra i round. Gli autori mostrano anche nel documento che questo metodo porta a una rapida ricostruzione degli incorporamenti dell'utente per i clienti non visti (Sez. 4.2, Fig. 3 e Tabella 1), consentendo alla maggior parte dei clienti che non partecipano alla formazione di avere un modello addestrato , consentendo consigli per questi client. Vedere la Federated ricostruzione post sul blog di Google AI per i risultati più importanti.
Definizione del modello
Successivamente definiremo il modello di fattorizzazione della matrice locale da addestrare sui dispositivi client. Questo modello include il pieno di matrice oggetto \(I\) e un singolo utente embedding \(U_u\) per il cliente \(u\). Nota che i clienti non avranno bisogno di memorizzare l'intera matrice dell'utente \(U\).
Definiremo quanto segue:
-
UserEmbedding: un semplice strato Keras rappresenta una singolanum_latent_factorsutente -dimensional incorporamento. -
get_matrix_factorization_model: una funzione che restituisce untff.learning.reconstruction.Modelcontenente la logica modello, compreso che gli strati vengono aggregati globalmente sul server e che rimangono strati locale. Abbiamo bisogno di queste informazioni aggiuntive per inizializzare il processo di formazione Ricostruzione federata. Qui si produce iltff.learning.reconstruction.Modelda un modello Keras utilizzandotff.learning.reconstruction.from_keras_model. Simile atff.learning.Model, possiamo anche realizzare un costumetff.learning.reconstruction.Modelimplementando l'interfaccia di classe.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
Analoga all'interfaccia per federati della media, l'interfaccia per la ricostruzione Federati si aspetta un model_fn senza argomenti che restituisce un tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
Ci definiamo prossimo loss_fn e metrics_fn , dove loss_fn è una funzione senza argomenti restituisce un perdita Keras da utilizzare per addestrare il modello, e metrics_fn è una funzione senza argomenti restituisce un elenco di metriche Keras per la valutazione. Questi sono necessari per costruire i calcoli di formazione e valutazione.
Useremo l'errore quadratico medio come perdita, come menzionato sopra. Per la valutazione utilizzeremo l'accuratezza della valutazione (quando il prodotto scalare previsto del modello viene arrotondato al numero intero più vicino, con quale frequenza corrisponde alla valutazione dell'etichetta?).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
Formazione e valutazione
Ora abbiamo tutto il necessario per definire il processo di formazione. Una differenza importante dal interfaccia per Federated mediazione è che ora passiamo un reconstruction_optimizer_fn , che verrà utilizzato nella ricostruzione parametri locali (nel nostro caso, immersioni utente). E 'generalmente ragionevole utilizzare SGD qui, con una simile o leggermente inferiore tasso di apprendimento rispetto al client di ottimizzazione tasso di apprendimento. Di seguito forniamo una configurazione funzionante. Questo non è stato messo a punto con attenzione, quindi sentiti libero di giocare con valori diversi.
Controlla la documentazione per maggiori dettagli e opzioni.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
Possiamo anche definire un calcolo per valutare il nostro modello globale addestrato.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
Possiamo inizializzare lo stato del processo di training ed esaminarlo. Ancora più importante, possiamo vedere che questo stato del server memorizza solo le variabili degli elementi (attualmente inizializzate in modo casuale) e non gli incorporamenti dell'utente.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
Possiamo anche provare a valutare il nostro modello inizializzato casualmente sui client di convalida. La valutazione della Ricostruzione federata qui implica quanto segue:
- Il server invia la matrice oggetto \(I\) ai clienti di valutazione campionati
- Ogni cliente congela \(I\) e treni loro utenti l'incorporamento \(U_u\) utilizzando uno o più passi di SGD (ricostruzione)
- Ogni perdita e metriche calcola client tramite il server \(I\) e ricostruito \(U_u\) su una parte invisibile dei propri dati locali
- Le perdite e le metriche vengono mediate tra gli utenti per calcolare la perdita e le metriche complessive
Si noti che i passaggi 1 e 2 sono gli stessi dell'allenamento. Questo collegamento è importante, dal momento che la formazione allo stesso modo valutiamo conduce ad una forma di meta-apprendimento, o imparare come imparare. In questo caso, il modello sta imparando come apprendere variabili globali (matrice di elementi) che portano alla ricostruzione performante di variabili locali (incorporamenti utente). Per ulteriori informazioni su questo, vedi Sez. 4.2 della carta.
È anche importante che i passaggi 2 e 3 vengano eseguiti utilizzando porzioni disgiunte dei dati locali dei clienti, per garantire una valutazione equa. Per impostazione predefinita, sia il processo di addestramento che il calcolo di valutazione utilizzano ogni altro esempio per la ricostruzione e utilizzano l'altra metà dopo la ricostruzione. Questo comportamento può essere personalizzato utilizzando il dataset_split_fn argomento (esploreremo questo ulteriore in seguito).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
Adesso possiamo provare a fare un giro di allenamento. Per rendere le cose più realistiche, campioneremo 50 client per round in modo casuale senza sostituzione. Dovremmo comunque aspettarci che le metriche del treno siano scarse, dal momento che stiamo facendo solo un ciclo di allenamento.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
Ora impostiamo un ciclo di allenamento per allenarti su più round.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
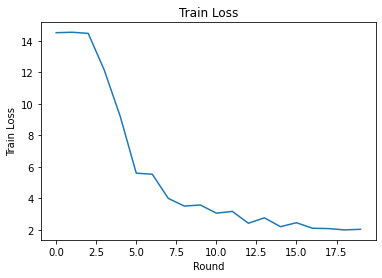
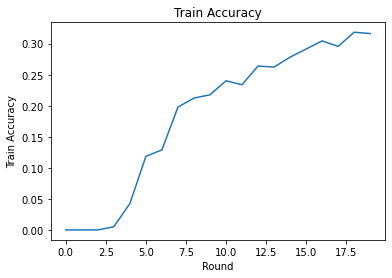
Possiamo tracciare la perdita di allenamento e la precisione su round. Gli iperparametri in questo notebook non sono stati messi a punto con attenzione, quindi sentiti libero di provare diversi client per round, tassi di apprendimento, numero di round e numero totale di client per migliorare questi risultati.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
Infine, possiamo calcolare le metriche su un set di test invisibile quando abbiamo finito di mettere a punto.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
Ulteriori esplorazioni
Bel lavoro per completare questo quaderno. Suggeriamo i seguenti esercizi per esplorare ulteriormente l'apprendimento federato parzialmente locale, ordinati approssimativamente per difficoltà crescente:
Le implementazioni tipiche della media federata richiedono più passaggi locali (periodi) sui dati (oltre a eseguire un passaggio sui dati su più batch). Per la Ricostruzione federata, potremmo voler controllare separatamente il numero di passaggi per la ricostruzione e l'addestramento post-ricostruzione. Passando il
dataset_split_fntesi alla formazione e valutazione costruttori di calcolo consente il controllo del numero di passi e di epoche più di entrambi i set di dati di ricostruzione post-ricostruzione. Come esercizio, prova a eseguire 3 epoche locali di addestramento alla ricostruzione, con un limite di 50 passi e 1 epoca locale di addestramento post-ricostruzione, con un limite di 50 passi. Suggerimento: troveretetff.learning.reconstruction.build_dataset_split_fnutile. Dopo averlo fatto, prova a mettere a punto questi iperparametri e altri correlati come i tassi di apprendimento e la dimensione del batch per ottenere risultati migliori.Il comportamento predefinito della formazione e della valutazione di Ricostruzione federata consiste nel dividere a metà i dati locali dei clienti per ciascuna ricostruzione e post-ricostruzione. Nei casi in cui i clienti dispongano di pochissimi dati locali, può essere ragionevole riutilizzare i dati per la ricostruzione e la post-ricostruzione solo per il processo di formazione (non per la valutazione, ciò porterà a una valutazione ingiusta). Prova a fare questo cambiamento per il processo di formazione, garantendo la
dataset_split_fnper la valutazione conserva ancora la ricostruzione e post-ricostruzione disgiunti dati. Suggerimento:tff.learning.reconstruction.simple_dataset_split_fnpotrebbe essere utile.Sopra, abbiamo prodotto un
tff.learning.Modelda un modello Keras utilizzandotff.learning.reconstruction.from_keras_model. Possiamo anche realizzare un modello personalizzato utilizzando puro tensorflow 2.0 dal implementando l'interfaccia del modello . Provate a modificareget_matrix_factorization_modelper costruire e restituire una classe che estendetff.learning.reconstruction.Model, implementando i suoi metodi. Accennare: il codice sorgente ditff.learning.reconstruction.from_keras_modelfornisce un esempio di estendere latff.learning.reconstruction.Modelclasse. Consultare anche l' implementazione del modello personalizzato a immagine EMNIST classificazione esercitazione per un esercizio simile in estensione di unatff.learning.Model.In questo tutorial, abbiamo motivato l'apprendimento federato parzialmente locale nel contesto della fattorizzazione della matrice, in cui l'invio di incorporamenti dell'utente al server farebbe passare banalmente le preferenze dell'utente. Possiamo anche applicare la Ricostruzione federata in altre impostazioni come un modo per addestrare modelli più personali (poiché parte del modello è completamente locale per ciascun utente) riducendo la comunicazione (poiché i parametri locali non vengono inviati al server). In generale, utilizzando l'interfaccia presentata qui possiamo prendere qualsiasi modello federato che in genere verrebbe addestrato completamente a livello globale e invece partizionare le sue variabili in variabili globali e variabili locali. L'esempio esplorato nel documento Federati ricostruzione è personale della parola successiva: qui, ogni utente ha il proprio set locale di incastri di parole per out-of-vocabolario parole, consentendo il modello slang degli utenti di cattura e raggiungere la personalizzazione senza comunicazione aggiuntiva. Come esercizio, prova a implementare (come modello Keras o come modello TensorFlow 2.0 personalizzato) un modello diverso da utilizzare con Ricostruzione federata. Un suggerimento: implementare un modello di classificazione EMNIST con un incorporamento utente personale, in cui l'incorporamento utente personale è concatenato alle caratteristiche dell'immagine CNN prima dell'ultimo strato Denso del modello. È possibile riutilizzare gran parte del codice da questo tutorial (ad esempio
UserEmbeddingclasse) e l' immagine di classificazione esercitazione .
Se siete ancora alla ricerca di più sulla formazione federata in parte locali, controlla la carta federati Ricostruzione e open-source il codice dell'esperimento .