
Używanie jednostek przetwarzania grafiki (GPU) do uruchamiania modeli uczenia maszynowego (ML) może radykalnie poprawić wydajność modelu i komfort korzystania z aplikacji obsługujących technologię ML. Na urządzeniach z systemem iOS możesz włączyć wykonywanie modeli przyspieszane przez procesor graficzny za pomocą delegata . Delegaty działają jako sterowniki sprzętowe dla TensorFlow Lite, umożliwiając uruchomienie kodu Twojego modelu na procesorach GPU.
Na tej stronie opisano, jak włączyć akcelerację GPU dla modeli TensorFlow Lite w aplikacjach na iOS. Aby uzyskać więcej informacji na temat korzystania z delegata procesora GPU dla TensorFlow Lite, w tym najlepszych praktyk i zaawansowanych technik, zobacz stronę delegatów procesora GPU .
Użyj procesora graficznego z interfejsem API interpretera
Interfejs API interpretera TensorFlow Lite zapewnia zestaw interfejsów API ogólnego przeznaczenia do tworzenia aplikacji do uczenia maszynowego. Poniższe instrukcje przeprowadzą Cię przez proces dodawania obsługi procesora graficznego do aplikacji na iOS. W tym przewodniku założono, że masz już aplikację na iOS, która może pomyślnie wykonać model ML za pomocą TensorFlow Lite.
Zmodyfikuj plik Podfile, aby uwzględnić obsługę procesora GPU
Począwszy od wersji TensorFlow Lite 2.3.0 delegat procesora GPU jest wykluczony z zasobnika, aby zmniejszyć rozmiar pliku binarnego. Możesz je uwzględnić, określając podspecyfikację dla modułu TensorFlowLiteSwift :
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
LUB
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Możesz także użyć TensorFlowLiteObjC lub TensorFlowLiteC , jeśli chcesz używać Objective-C, który jest dostępny dla wersji 2.4.0 i nowszych, lub interfejsu API C.
Zainicjuj i użyj delegata GPU
Delegata GPU można używać z interfejsem API interpretera TensorFlow Lite z wieloma językami programowania. Zalecane są Swift i Objective-C, ale można także używać C++ i C. Korzystanie z C jest wymagane, jeśli używasz wersji TensorFlow Lite wcześniejszej niż 2.4. Poniższe przykłady kodu opisują sposób używania delegata w każdym z tych języków.
Szybki
import TensorFlowLite
// Load model ...
// Initialize TensorFlow Lite interpreter with the GPU delegate.
let delegate = MetalDelegate()
if let interpreter = try Interpreter(modelPath: modelPath,
delegates: [delegate]) {
// Run inference ...
}
Cel C
// Import module when using CocoaPods with module support
@import TFLTensorFlowLite;
// Or import following headers manually
#import "tensorflow/lite/objc/apis/TFLMetalDelegate.h"
#import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h"
// Initialize GPU delegate
TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init];
// Initialize interpreter with model path and GPU delegate
TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init];
NSError* error = nil;
TFLInterpreter* interpreter = [[TFLInterpreter alloc]
initWithModelPath:modelPath
options:options
delegates:@[ metalDelegate ]
error:&error];
if (error != nil) { /* Error handling... */ }
if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ }
if (error != nil) { /* Error handling... */ }
// Run inference ...
C++
// Set up interpreter.
auto model = FlatBufferModel::BuildFromFile(model_path);
if (!model) return false;
tflite::ops::builtin::BuiltinOpResolver op_resolver;
std::unique_ptr<Interpreter> interpreter;
InterpreterBuilder(*model, op_resolver)(&interpreter);
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
// Run inference.
WriteToInputTensor(interpreter->typed_input_tensor<float>(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0));
// Clean up.
TFLGpuDelegateDelete(delegate);
C (przed 2.4.0)
#include "tensorflow/lite/c/c_api.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
// Initialize model
TfLiteModel* model = TfLiteModelCreateFromFile(model_path);
// Initialize interpreter with GPU delegate
TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate();
TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config
TfLiteInterpreterOptionsAddDelegate(options, metal_delegate);
TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options);
TfLiteInterpreterOptionsDelete(options);
TfLiteInterpreterAllocateTensors(interpreter);
NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)];
NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)];
TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0);
const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0);
// Run inference
TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length);
TfLiteInterpreterInvoke(interpreter);
TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length);
// Clean up
TfLiteInterpreterDelete(interpreter);
TFLGpuDelegateDelete(metal_delegate);
TfLiteModelDelete(model);
Uwagi dotyczące używania języka API GPU
- Wersje TensorFlow Lite wcześniejsze niż 2.4.0 mogą używać tylko interfejsu API C dla Objective-C.
- Interfejs API C++ jest dostępny tylko wtedy, gdy używasz bazela lub samodzielnie budujesz TensorFlow Lite. Interfejsu API języka C++ nie można używać z urządzeniami CocoaPods.
- Używając TensorFlow Lite z delegatem GPU w C++, pobierz delegata GPU za pomocą funkcji
TFLGpuDelegateCreate(), a następnie przekaż go doInterpreter::ModifyGraphWithDelegate(), zamiast wywoływaćInterpreter::AllocateTensors().
Kompiluj i testuj w trybie wydania
Zmień wersję na wersję z odpowiednimi ustawieniami akceleratora Metal API, aby uzyskać lepszą wydajność i przeprowadzić końcowe testy. W tej sekcji wyjaśniono, jak włączyć kompilację wydania i skonfigurować ustawienie przyspieszenia Metal.
Aby zmienić wersję na wersję:
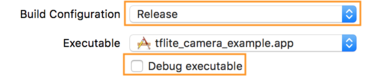
- Edytuj ustawienia kompilacji, wybierając opcję Produkt > Schemat > Edytuj schemat... , a następnie wybierając opcję Uruchom .
- Na karcie Informacje zmień opcję Konfiguracja kompilacji na Wersja i usuń zaznaczenie opcji Debuguj plik wykonywalny .
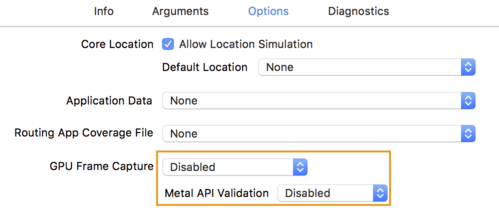
- Kliknij zakładkę Opcje i zmień opcję Przechwytywanie klatek GPU na Wyłączone , a Walidacja API Metal na Wyłączone .
- Pamiętaj, aby wybrać opcję Tylko wersja dla architektury 64-bitowej. W obszarze Nawigator projektu > przykład_kamery_tflite > PROJEKT > nazwa_twojego_projektu > Ustawienia kompilacji ustaw opcję Buduj tylko aktywną architekturę > Zwolnij na Tak .

Zaawansowana obsługa GPU
W tej sekcji omówiono zaawansowane zastosowania delegata procesora GPU dla systemu iOS, w tym opcje delegowania, bufory wejściowe i wyjściowe oraz wykorzystanie modeli skwantowanych.
Opcje delegowania dla systemu iOS
Konstruktor delegata GPU akceptuje struct opcji w interfejsach Swift API , Objective-C API i C API . Przekazanie nullptr (C API) lub nic (Objective-C i Swift API) do inicjatora ustawia opcje domyślne (które są objaśnione w powyższym przykładzie użycia podstawowego).
Szybki
// THIS:
var options = MetalDelegate.Options()
options.isPrecisionLossAllowed = false
options.waitType = .passive
options.isQuantizationEnabled = true
let delegate = MetalDelegate(options: options)
// IS THE SAME AS THIS:
let delegate = MetalDelegate()
Cel C
// THIS:
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.precisionLossAllowed = false;
options.waitType = TFLMetalDelegateThreadWaitTypePassive;
options.quantizationEnabled = true;
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options];
// IS THE SAME AS THIS:
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS:
const TFLGpuDelegateOptions options = {
.allow_precision_loss = false,
.wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive,
.enable_quantization = true,
};
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
// IS THE SAME AS THIS:
TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Bufory wejścia/wyjścia przy użyciu API C++
Obliczenia na GPU wymagają, aby dane były dostępne dla GPU. To wymaganie często oznacza konieczność wykonania kopii pamięci. Jeśli to możliwe, należy unikać sytuacji, w których dane przekraczają granicę pamięci procesora/GPU, ponieważ może to zająć znaczną ilość czasu. Zwykle takie przejście jest nieuniknione, ale w niektórych szczególnych przypadkach można pominąć jedno lub drugie.
Jeśli sygnałem wejściowym sieci jest obraz już załadowany do pamięci GPU (na przykład tekstura GPU zawierająca obraz z kamery), może on pozostać w pamięci GPU bez wchodzenia do pamięci procesora. Podobnie, jeśli dane wyjściowe sieci mają postać renderowalnego obrazu, na przykład operacji przesyłania stylu obrazu , wynik można bezpośrednio wyświetlić na ekranie.
Aby osiągnąć najlepszą wydajność, TensorFlow Lite umożliwia użytkownikom bezpośredni odczyt i zapis w buforze sprzętowym TensorFlow oraz ominięcie dających się uniknąć kopii pamięci.
Zakładając, że obraz wejściowy znajduje się w pamięci GPU, musisz najpierw przekonwertować go na obiekt MTLBuffer dla Metalu. Można powiązać TfLiteTensor z przygotowanym przez użytkownika MTLBuffer za pomocą funkcji TFLGpuDelegateBindMetalBufferToTensor() . Należy pamiętać, że tę funkcję należy wywołać po Interpreter::ModifyGraphWithDelegate() . Ponadto dane wyjściowe wnioskowania są domyślnie kopiowane z pamięci procesora graficznego do pamięci procesora. Możesz wyłączyć to zachowanie, wywołując Interpreter::SetAllowBufferHandleOutput(true) podczas inicjalizacji.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h"
// ...
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->inputs()[0], user_provided_input_buffer)) {
return false;
}
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->outputs()[0], user_provided_output_buffer)) {
return false;
}
// Run inference.
if (interpreter->Invoke() != kTfLiteOk) return false;
Po wyłączeniu zachowania domyślnego kopiowanie wyników wnioskowania z pamięci procesora graficznego do pamięci procesora wymaga jawnego wywołania funkcji Interpreter::EnsureTensorDataIsReadable() dla każdego tensora wyjściowego. To podejście działa również w przypadku modeli skwantowanych, ale nadal musisz użyć bufora o rozmiarze float32 z danymi float32 , ponieważ bufor jest powiązany z wewnętrznym buforem dekwantowanym.
Modele kwantowane
Biblioteki delegatów GPU iOS domyślnie obsługują modele kwantyzowane . Aby używać modeli skwantowanych z delegatem procesora GPU, nie trzeba wprowadzać żadnych zmian w kodzie. W poniższej sekcji wyjaśniono, jak wyłączyć obsługę kwantyzacji do celów testowych lub eksperymentalnych.
Wyłącz obsługę modelu skwantowanego
Poniższy kod pokazuje, jak wyłączyć obsługę modeli skwantowanych.
Szybki
var options = MetalDelegate.Options()
options.isQuantizationEnabled = false
let delegate = MetalDelegate(options: options)
Cel C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault();
options.enable_quantization = false;
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Aby uzyskać więcej informacji na temat uruchamiania modeli skwantowanych z akceleracją procesora GPU, zobacz Omówienie delegowania procesora GPU .