
|
|
|
 View source on GitHub View source on GitHub
|
|
A linear mixed effects model is a simple approach for modeling structured linear relationships (Harville, 1997; Laird and Ware, 1982). Each data point consists of inputs of varying type—categorized into groups—and a real-valued output. A linear mixed effects model is a hierarchical model: it shares statistical strength across groups in order to improve inferences about any individual data point.
In this tutorial, we demonstrate linear mixed effects models with a real-world example in TensorFlow Probability. We'll use the JointDistributionCoroutine and Markov Chain Monte Carlo (tfp.mcmc) modules.
Dependencies & Prerequisites
Import and set ups
import csv
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import requests
import tensorflow as tf
import tf_keras
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
dtype = tf.float64
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
plt.style.use('ggplot')
Make things Fast!
Before we dive in, let's make sure we're using a GPU for this demo.
To do this, select "Runtime" -> "Change runtime type" -> "Hardware accelerator" -> "GPU".
The following snippet will verify that we have access to a GPU.
if tf.test.gpu_device_name() != '/device:GPU:0':
print('WARNING: GPU device not found.')
else:
print('SUCCESS: Found GPU: {}'.format(tf.test.gpu_device_name()))
WARNING: GPU device not found.
Data
We use the InstEval data set from the popular lme4 package in R (Bates et al., 2015). It is a data set of courses and their evaluation ratings. Each course includes metadata such as students, instructors, and departments, and the response variable of interest is the evaluation rating.
def load_insteval():
"""Loads the InstEval data set.
It contains 73,421 university lecture evaluations by students at ETH
Zurich with a total of 2,972 students, 2,160 professors and
lecturers, and several student, lecture, and lecturer attributes.
Implementation is built from the `observations` Python package.
Returns:
Tuple of np.ndarray `x_train` with 73,421 rows and 7 columns and
dictionary `metadata` of column headers (feature names).
"""
url = ('https://raw.github.com/vincentarelbundock/Rdatasets/master/csv/'
'lme4/InstEval.csv')
with requests.Session() as s:
download = s.get(url)
f = download.content.decode().splitlines()
iterator = csv.reader(f)
columns = next(iterator)[1:]
x_train = np.array([row[1:] for row in iterator], dtype=np.int)
metadata = {'columns': columns}
return x_train, metadata
We load and preprocess the data set. We hold out 20% of the data so we can evaluate our fitted model on unseen data points. Below we visualize the first few rows.
data, metadata = load_insteval()
data = pd.DataFrame(data, columns=metadata['columns'])
data = data.rename(columns={'s': 'students',
'd': 'instructors',
'dept': 'departments',
'y': 'ratings'})
data['students'] -= 1 # start index by 0
# Remap categories to start from 0 and end at max(category).
data['instructors'] = data['instructors'].astype('category').cat.codes
data['departments'] = data['departments'].astype('category').cat.codes
train = data.sample(frac=0.8)
test = data.drop(train.index)
train.head()
<ipython-input-4-5d7a9eabeea1>:21: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations x_train = np.array([row[1:] for row in iterator], dtype=np.int)
We set up the data set in terms of a features dictionary of inputs and a labels output corresponding to the ratings. Each feature is encoded as an integer and each label (evaluation rating) is encoded as a floating point number.
get_value = lambda dataframe, key, dtype: dataframe[key].values.astype(dtype)
features_train = {
k: get_value(train, key=k, dtype=np.int32)
for k in ['students', 'instructors', 'departments', 'service']}
labels_train = get_value(train, key='ratings', dtype=np.float32)
features_test = {k: get_value(test, key=k, dtype=np.int32)
for k in ['students', 'instructors', 'departments', 'service']}
labels_test = get_value(test, key='ratings', dtype=np.float32)
num_students = max(features_train['students']) + 1
num_instructors = max(features_train['instructors']) + 1
num_departments = max(features_train['departments']) + 1
num_observations = train.shape[0]
print("Number of students:", num_students)
print("Number of instructors:", num_instructors)
print("Number of departments:", num_departments)
print("Number of observations:", num_observations)
Number of students: 2972 Number of instructors: 1128 Number of departments: 14 Number of observations: 58737
Model
A typical linear model assumes independence, where any pair of data points has a constant linear relationship. In the InstEval data set, observations arise in groups each of which may have varying slopes and intercepts. Linear mixed effects models, also known as hierarchical linear models or multilevel linear models, capture this phenomenon (Gelman & Hill, 2006).
Examples of this phenomenon include:
- Students. Observations from a student are not independent: some students may systematically give low (or high) lecture ratings.
- Instructors. Observations from an instructor are not independent: we expect good teachers to generally have good ratings and bad teachers to generally have bad ratings.
- Departments. Observations from a department are not independent: certain departments may generally have dry material or stricter grading and thus be rated lower than others.
To capture this, recall that for a data set of \(N\times D\) features \(\mathbf{X}\) and \(N\) labels \(\mathbf{y}\), linear regression posits the model
\[ \begin{equation*} \mathbf{y} = \mathbf{X}\beta + \alpha + \epsilon, \end{equation*} \]
where there is a slope vector \(\beta\in\mathbb{R}^D\), intercept \(\alpha\in\mathbb{R}\), and random noise \(\epsilon\sim\text{Normal}(\mathbf{0}, \mathbf{I})\). We say that \(\beta\) and \(\alpha\) are "fixed effects": they are effects held constant across the population of data points \((x, y)\). An equivalent formulation of the equation as a likelihood is \(\mathbf{y} \sim \text{Normal}(\mathbf{X}\beta + \alpha, \mathbf{I})\). This likelihood is maximized during inference in order to find point estimates of \(\beta\) and \(\alpha\) that fit the data.
A linear mixed effects model extends linear regression as
\[ \begin{align*} \eta &\sim \text{Normal}(\mathbf{0}, \sigma^2 \mathbf{I}), \\ \mathbf{y} &= \mathbf{X}\beta + \mathbf{Z}\eta + \alpha + \epsilon. \end{align*} \]
where there is still a slope vector \(\beta\in\mathbb{R}^P\), intercept \(\alpha\in\mathbb{R}\), and random noise \(\epsilon\sim\text{Normal}(\mathbf{0}, \mathbf{I})\). In addition, there is a term \(\mathbf{Z}\eta\), where \(\mathbf{Z}\) is a features matrix and \(\eta\in\mathbb{R}^Q\) is a vector of random slopes; \(\eta\) is normally distributed with variance component parameter \(\sigma^2\). \(\mathbf{Z}\) is formed by partitioning the original \(N\times D\) features matrix in terms of a new \(N\times P\) matrix \(\mathbf{X}\) and \(N\times Q\) matrix \(\mathbf{Z}\), where \(P + Q=D\): this partition allows us to model the features separately using the fixed effects \(\beta\) and the latent variable \(\eta\) respectively.
We say the latent variables \(\eta\) are "random effects": they are effects that vary across the population (although they may be constant across subpopulations). In particular, because the random effects \(\eta\) have mean 0, the data label's mean is captured by \(\mathbf{X}\beta + \alpha\). The random effects component \(\mathbf{Z}\eta\) captures variations in the data: for example, "Instructor #54 is rated 1.4 points higher than the mean."
In this tutorial, we posit the following effects:
- Fixed effects:
service.serviceis a binary covariate corresponding to whether the course belongs to the instructor's main department. No matter how much additional data we collect, it can only take on values \(0\) and \(1\). - Random effects:
students,instructors, anddepartments. Given more observations from the population of course evaluation ratings, we may be looking at new students, teachers, or departments.
In the syntax of R's lme4 package (Bates et al., 2015), the model can be summarized as
ratings ~ service + (1|students) + (1|instructors) + (1|departments) + 1
where x denotes a fixed effect,(1|x) denotes a random effect for x, and 1 denotes an intercept term.
We implement this model below as a JointDistribution. To have better support for parameter tracking (e.g., we want to track all the tf.Variable in model.trainable_variables), we implement the model template as tf.Module.
class LinearMixedEffectModel(tf.Module):
def __init__(self):
# Set up fixed effects and other parameters.
# These are free parameters to be optimized in E-steps
self._intercept = tf.Variable(0., name="intercept") # alpha in eq
self._effect_service = tf.Variable(0., name="effect_service") # beta in eq
self._stddev_students = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_students") # sigma in eq
self._stddev_instructors = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_instructors") # sigma in eq
self._stddev_departments = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_departments") # sigma in eq
def __call__(self, features):
model = tfd.JointDistributionSequential([
# Set up random effects.
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_students),
scale_diag=self._stddev_students * tf.ones(num_students)),
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_instructors),
scale_diag=self._stddev_instructors * tf.ones(num_instructors)),
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_departments),
scale_diag=self._stddev_departments * tf.ones(num_departments)),
# This is the likelihood for the observed.
lambda effect_departments, effect_instructors, effect_students: tfd.Independent(
tfd.Normal(
loc=(self._effect_service * features["service"] +
tf.gather(effect_students, features["students"], axis=-1) +
tf.gather(effect_instructors, features["instructors"], axis=-1) +
tf.gather(effect_departments, features["departments"], axis=-1) +
self._intercept),
scale=1.),
reinterpreted_batch_ndims=1)
])
# To enable tracking of the trainable variables via the created distribution,
# we attach a reference to `self`. Since all TFP objects sub-class
# `tf.Module`, this means that the following is possible:
# LinearMixedEffectModel()(features_train).trainable_variables
# ==> tuple of all tf.Variables created by LinearMixedEffectModel.
model._to_track = self
return model
lmm_jointdist = LinearMixedEffectModel()
# Conditioned on feature/predictors from the training data
lmm_train = lmm_jointdist(features_train)
lmm_train.trainable_variables
(<tf.Variable 'effect_service:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'intercept:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'stddev_departments:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'stddev_instructors:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'stddev_students:0' shape=() dtype=float32, numpy=0.0>)
As a Probabilistic graphical program, we can also visualize the model's structure in terms of its computational graph. This graph encodes dataflow across the random variables in the program, making explicit their relationships in terms of a graphical model (Jordan, 2003).
As a statistical tool, we might look at the graph in order to better see, for example, that intercept and effect_service are conditionally dependent given ratings; this may be harder to see from the source code if the program is written with classes, cross references across modules, and/or subroutines. As a computational tool, we might also notice latent variables flow into the ratings variable via tf.gather ops. This may be a bottleneck on certain hardware accelerators if indexing Tensors is expensive; visualizing the graph makes this readily apparent.
lmm_train.resolve_graph()
(('effect_students', ()),
('effect_instructors', ()),
('effect_departments', ()),
('x', ('effect_departments', 'effect_instructors', 'effect_students')))
Parameter Estimation
Given data, the goal of inference is to fit the model's fixed effects slope \(\beta\), intercept \(\alpha\), and variance component parameter \(\sigma^2\). The maximum likelihood principle formalizes this task as
\[ \max_{\beta, \alpha, \sigma}~\log p(\mathbf{y}\mid \mathbf{X}, \mathbf{Z}; \beta, \alpha, \sigma) = \max_{\beta, \alpha, \sigma}~\log \int p(\eta; \sigma) ~p(\mathbf{y}\mid \mathbf{X}, \mathbf{Z}, \eta; \beta, \alpha)~d\eta. \]
In this tutorial, we use the Monte Carlo EM algorithm to maximize this marginal density (Dempster et al., 1977; Wei and Tanner, 1990).¹ We perform Markov chain Monte Carlo to compute the expectation of the conditional likelihood with respect to the random effects ("E-step"), and we perform gradient descent to maximize the expectation with respect to the parameters ("M-step"):
For the E-step, we set up Hamiltonian Monte Carlo (HMC). It takes a current state—the student, instructor, and department effects—and returns a new state. We assign the new state to TensorFlow variables, which will denote the state of the HMC chain.
For the M-step, we use the posterior sample from HMC to calculate an unbiased estimate of the marginal likelihood up to a constant. We then apply its gradient with respect to the parameters of interest. This produces an unbiased stochastic descent step on the marginal likelihood. We implement it with the Adam TensorFlow optimizer and minimize the negative of the marginal.
target_log_prob_fn = lambda *x: lmm_train.log_prob(x + (labels_train,))
trainable_variables = lmm_train.trainable_variables
current_state = lmm_train.sample()[:-1]
# For debugging
target_log_prob_fn(*current_state)
<tf.Tensor: shape=(), dtype=float32, numpy=-485996.53>
# Set up E-step (MCMC).
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.015,
num_leapfrog_steps=3)
kernel_results = hmc.bootstrap_results(current_state)
@tf.function(autograph=False, jit_compile=True)
def one_e_step(current_state, kernel_results):
next_state, next_kernel_results = hmc.one_step(
current_state=current_state,
previous_kernel_results=kernel_results)
return next_state, next_kernel_results
optimizer = tf_keras.optimizers.Adam(learning_rate=.01)
# Set up M-step (gradient descent).
@tf.function(autograph=False, jit_compile=True)
def one_m_step(current_state):
with tf.GradientTape() as tape:
loss = -target_log_prob_fn(*current_state)
grads = tape.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
return loss
We perform a warm-up stage, which runs one MCMC chain for a number of iterations so that training may be initialized within the posterior's probability mass. We then run a training loop. It jointly runs the E and M-steps and records values during training.
num_warmup_iters = 1000
num_iters = 1500
num_accepted = 0
effect_students_samples = np.zeros([num_iters, num_students])
effect_instructors_samples = np.zeros([num_iters, num_instructors])
effect_departments_samples = np.zeros([num_iters, num_departments])
loss_history = np.zeros([num_iters])
# Run warm-up stage.
for t in range(num_warmup_iters):
current_state, kernel_results = one_e_step(current_state, kernel_results)
num_accepted += kernel_results.is_accepted.numpy()
if t % 500 == 0 or t == num_warmup_iters - 1:
print("Warm-Up Iteration: {:>3} Acceptance Rate: {:.3f}".format(
t, num_accepted / (t + 1)))
num_accepted = 0 # reset acceptance rate counter
# Run training.
for t in range(num_iters):
# run 5 MCMC iterations before every joint EM update
for _ in range(5):
current_state, kernel_results = one_e_step(current_state, kernel_results)
loss = one_m_step(current_state)
effect_students_samples[t, :] = current_state[0].numpy()
effect_instructors_samples[t, :] = current_state[1].numpy()
effect_departments_samples[t, :] = current_state[2].numpy()
num_accepted += kernel_results.is_accepted.numpy()
loss_history[t] = loss.numpy()
if t % 500 == 0 or t == num_iters - 1:
print("Iteration: {:>4} Acceptance Rate: {:.3f} Loss: {:.3f}".format(
t, num_accepted / (t + 1), loss_history[t]))
Warm-Up Iteration: 0 Acceptance Rate: 1.000 Warm-Up Iteration: 500 Acceptance Rate: 0.758 Warm-Up Iteration: 999 Acceptance Rate: 0.729 Iteration: 0 Acceptance Rate: 1.000 Loss: 98200.422 Iteration: 500 Acceptance Rate: 0.649 Loss: 98190.469 Iteration: 1000 Acceptance Rate: 0.656 Loss: 98068.664 Iteration: 1499 Acceptance Rate: 0.663 Loss: 98155.070
You can also write the warmup for-loop into a tf.while_loop, and the training step into a tf.scan or tf.while_loop for even faster inference. For example:
@tf.function(autograph=False, jit_compile=True)
def run_k_e_steps(k, current_state, kernel_results):
_, next_state, next_kernel_results = tf.while_loop(
cond=lambda i, state, pkr: i < k,
body=lambda i, state, pkr: (i+1, *one_e_step(state, pkr)),
loop_vars=(tf.constant(0), current_state, kernel_results)
)
return next_state, next_kernel_results
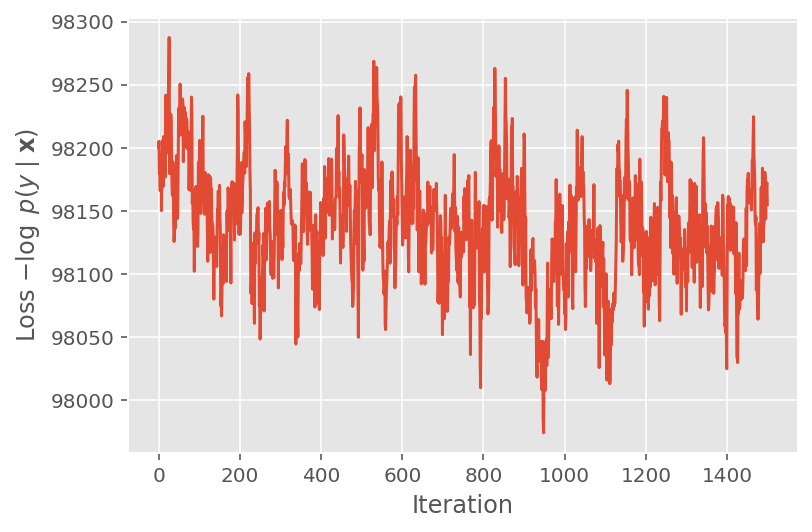
Above, we did not run the algorithm until a convergence threshold was detected. To check whether training was sensible, we verify that the loss function indeed tends to converge over training iterations.
plt.plot(loss_history)
plt.ylabel(r'Loss $-\log$ $p(y\mid\mathbf{x})$')
plt.xlabel('Iteration')
plt.show()
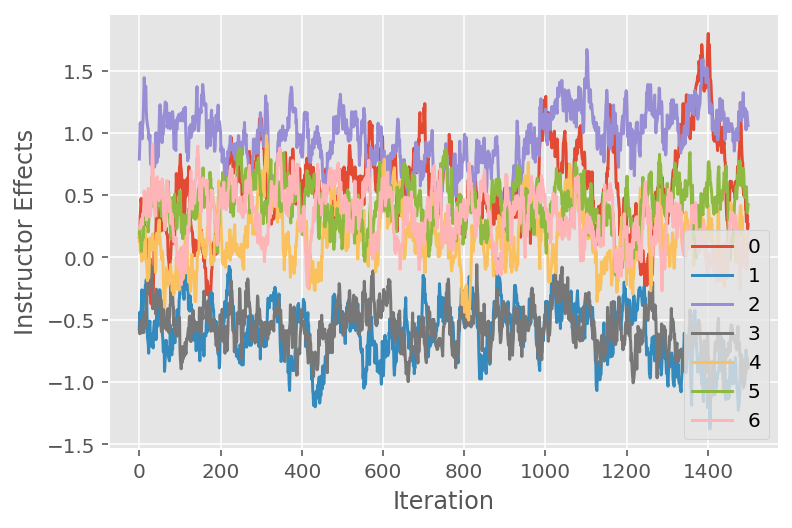
We also use a trace plot, which shows the Markov chain Monte Carlo algorithm's trajectory across specific latent dimensions. Below we see that specific instructor effects indeed meaningfully transition away from their initial state and explore the state space. The trace plot also indicates that the effects differ across instructors but with similar mixing behavior.
for i in range(7):
plt.plot(effect_instructors_samples[:, i])
plt.legend([i for i in range(7)], loc='lower right')
plt.ylabel('Instructor Effects')
plt.xlabel('Iteration')
plt.show()
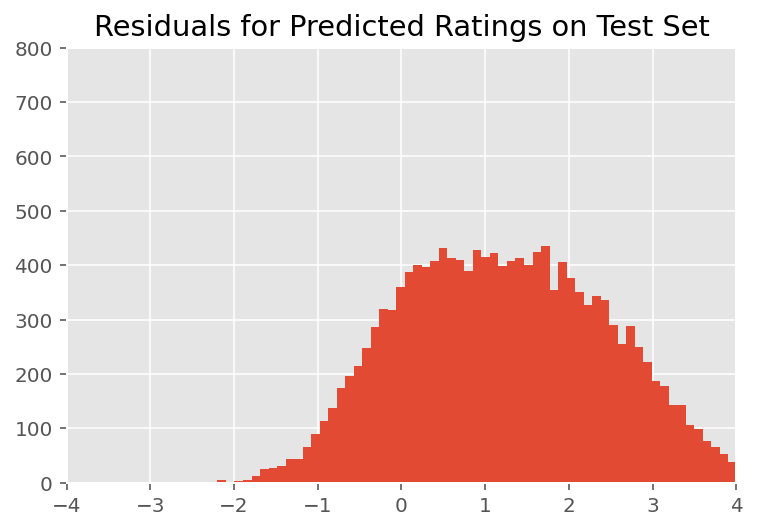
Criticism
Above, we fitted the model. We now look into criticizing its fit using data, which lets us explore and better understand the model. One such technique is a residual plot, which plots the difference between the model's predictions and ground truth for each data point. If the model were correct, then their difference should be standard normally distributed; any deviations from this pattern in the plot indicate model misfit.
We build the residual plot by first forming the posterior predictive distribution over ratings, which replaces the prior distribution on the random effects with its posterior given training data. In particular, we run the model forward and intercept its dependence on prior random effects with their inferred posterior means.²
lmm_test = lmm_jointdist(features_test)
[
effect_students_mean,
effect_instructors_mean,
effect_departments_mean,
] = [
np.mean(x, axis=0).astype(np.float32) for x in [
effect_students_samples,
effect_instructors_samples,
effect_departments_samples
]
]
# Get the posterior predictive distribution
(*posterior_conditionals, ratings_posterior), _ = lmm_test.sample_distributions(
value=(
effect_students_mean,
effect_instructors_mean,
effect_departments_mean,
))
ratings_prediction = ratings_posterior.mean()
Upon visual inspection, the residuals look somewhat standard-normally distributed. However, the fit is not perfect: there is larger probability mass in the tails than a normal distribution, which indicates the model might improve its fit by relaxing its normality assumptions.
In particular, although it is most common to use a normal distribution to model ratings in the InstEval data set, a closer look at the data reveals that course evaluation ratings are in fact ordinal values from 1 to 5. This suggests that we should be using an ordinal distribution, or even Categorical if we have enough data to throw away the relative ordering. This is a one-line change to the model above; the same inference code is applicable.
plt.title("Residuals for Predicted Ratings on Test Set")
plt.xlim(-4, 4)
plt.ylim(0, 800)
plt.hist(ratings_prediction - labels_test, 75)
plt.show()
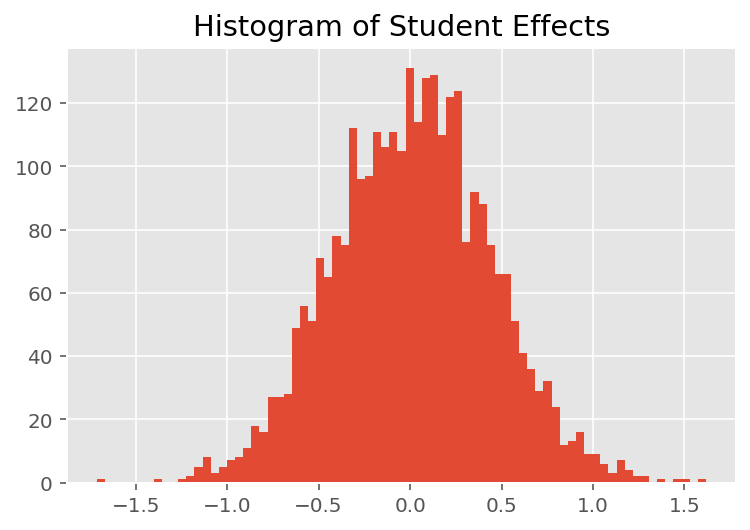
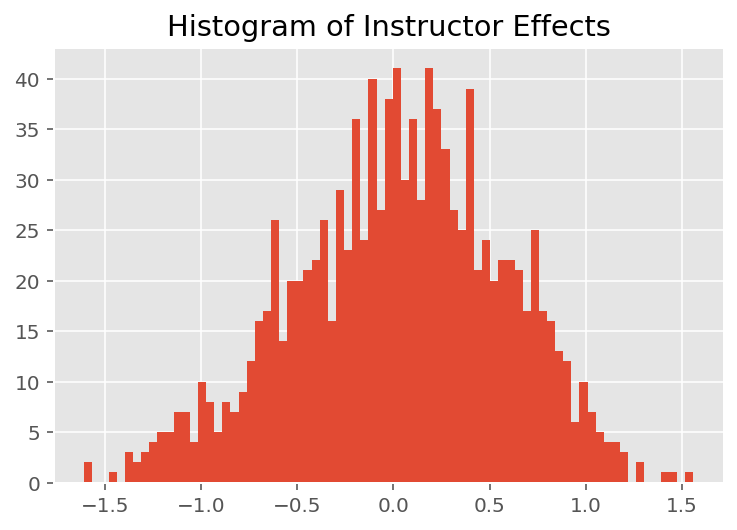
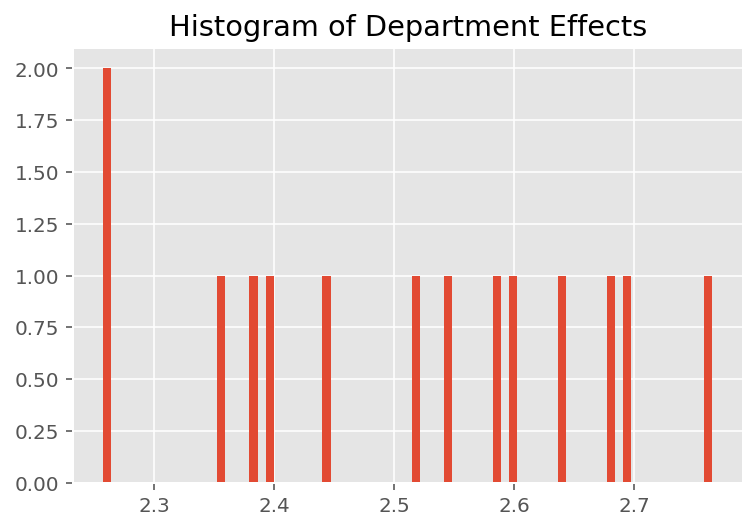
To explore how the model makes individual predictions, we look at the histogram of effects for students, instructors, and departments. This lets us understand how individual elements in a data point's feature vector tends to influence the outcome.
Not surprisingly, we see below that each student typically has little effect on an instructor's evaluation rating. Interestingly, we see that the department an instructor belongs to has a large effect.
plt.title("Histogram of Student Effects")
plt.hist(effect_students_mean, 75)
plt.show()
plt.title("Histogram of Instructor Effects")
plt.hist(effect_instructors_mean, 75)
plt.show()
plt.title("Histogram of Department Effects")
plt.hist(effect_departments_mean, 75)
plt.show()
Footnotes
¹ Linear mixed effect models are a special case where we can analytically compute its marginal density. For the purposes of this tutorial, we demonstrate Monte Carlo EM, which more readily applies to non-analytic marginal densities such as if the likelihood were extended to be Categorical instead of Normal.
² For simplicity, we form the predictive distribution's mean using only one forward pass of the model. This is done by conditioning on the posterior mean and is valid for linear mixed effects models. However, this is not valid in general: the posterior predictive distribution's mean is typically intractable and requires taking the empirical mean across multiple forward passes of the model given posterior samples.
Acknowledgments
This tutorial was originally written in Edward 1.0 (source). We thank all contributors to writing and revising that version.
References
Douglas Bates and Martin Machler and Ben Bolker and Steve Walker. Fitting Linear Mixed-Effects Models Using lme4. Journal of Statistical Software, 67(1):1-48, 2015.
Arthur P. Dempster, Nan M. Laird, and Donald B. Rubin. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, Series B (Methodological), 1-38, 1977.
Andrew Gelman and Jennifer Hill. Data analysis using regression and multilevel/hierarchical models. Cambridge University Press, 2006.
David A. Harville. Maximum likelihood approaches to variance component estimation and to related problems. Journal of the American Statistical Association, 72(358):320-338, 1977.
Michael I. Jordan. An Introduction to Graphical Models. Technical Report, 2003.
Nan M. Laird and James Ware. Random-effects models for longitudinal data. Biometrics, 963-974, 1982.
Greg Wei and Martin A. Tanner. A Monte Carlo implementation of the EM algorithm and the poor man's data augmentation algorithms. Journal of the American Statistical Association, 699-704, 1990.