|
|
|
 View source on GitHub View source on GitHub
|
|
This notebook reimplements and extends the Bayesian “Change point analysis” example from the pymc3 documentation.
Prerequisites
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (15,8)
%config InlineBackend.figure_format = 'retina'
import numpy as np
import pandas as pd
Dataset
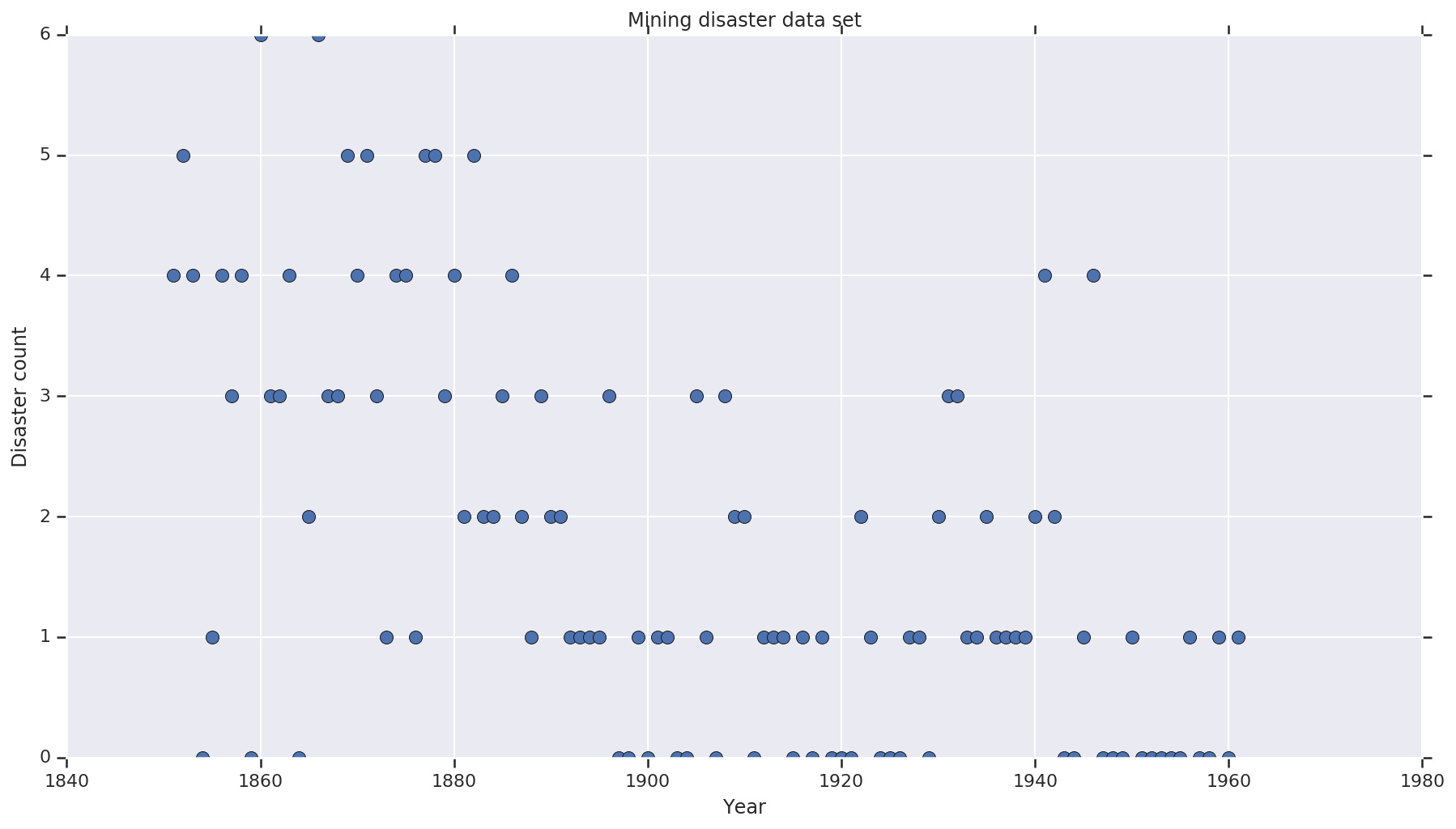
The dataset is from here. Note, there is another version of this example floating around, but it has “missing” data – in which case you’d need to impute missing values. (Otherwise your model will not ever leave its initial parameters because the likelihood function will be undefined.)
disaster_data = np.array([ 4, 5, 4, 0, 1, 4, 3, 4, 0, 6, 3, 3, 4, 0, 2, 6,
3, 3, 5, 4, 5, 3, 1, 4, 4, 1, 5, 5, 3, 4, 2, 5,
2, 2, 3, 4, 2, 1, 3, 2, 2, 1, 1, 1, 1, 3, 0, 0,
1, 0, 1, 1, 0, 0, 3, 1, 0, 3, 2, 2, 0, 1, 1, 1,
0, 1, 0, 1, 0, 0, 0, 2, 1, 0, 0, 0, 1, 1, 0, 2,
3, 3, 1, 1, 2, 1, 1, 1, 1, 2, 4, 2, 0, 0, 1, 4,
0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1])
years = np.arange(1851, 1962)
plt.plot(years, disaster_data, 'o', markersize=8);
plt.ylabel('Disaster count')
plt.xlabel('Year')
plt.title('Mining disaster data set')
plt.show()
Probabilistic Model
The model assumes a “switch point” (e.g. a year during which safety regulations changed), and Poisson-distributed disaster rate with constant (but potentially different) rates before and after that switch point.
The actual disaster count is fixed (observed); any sample of this model will need to specify both the switchpoint and the “early” and “late” rate of disasters.
Original model from pymc3 documentation example:
\[ \begin{align*} (D_t|s,e,l)&\sim \text{Poisson}(r_t), \\ & \,\quad\text{with}\; r_t = \begin{cases}e & \text{if}\; t < s\\l &\text{if}\; t \ge s\end{cases} \\ s&\sim\text{Discrete Uniform}(t_l,\,t_h) \\ e&\sim\text{Exponential}(r_e)\\ l&\sim\text{Exponential}(r_l) \end{align*} \]
However, the mean disaster rate \(r_t\) has a discontinuity at the switchpoint \(s\), which makes it not differentiable. Thus it provides no gradient signal to the Hamiltonian Monte Carlo (HMC) algorithm – but because the \(s\) prior is continuous, HMC’s fallback to a random walk is good enough to find the areas of high probability mass in this example.
As a second model, we modify the original model using a sigmoid “switch” between e and l to make the transition differentiable, and use a continuous uniform distribution for the switchpoint \(s\). (One could argue this model is more true to reality, as a “switch” in mean rate would likely be stretched out over multiple years.) The new model is thus:
\[ \begin{align*} (D_t|s,e,l)&\sim\text{Poisson}(r_t), \\ & \,\quad \text{with}\; r_t = e + \frac{1}{1+\exp(s-t)}(l-e) \\ s&\sim\text{Uniform}(t_l,\,t_h) \\ e&\sim\text{Exponential}(r_e)\\ l&\sim\text{Exponential}(r_l) \end{align*} \]
In the absence of more information we assume \(r_e = r_l = 1\) as parameters for the priors. We’ll run both models and compare their inference results.
def disaster_count_model(disaster_rate_fn):
disaster_count = tfd.JointDistributionNamed(dict(
e=tfd.Exponential(rate=1.),
l=tfd.Exponential(rate=1.),
s=tfd.Uniform(0., high=len(years)),
d_t=lambda s, l, e: tfd.Independent(
tfd.Poisson(rate=disaster_rate_fn(np.arange(len(years)), s, l, e)),
reinterpreted_batch_ndims=1)
))
return disaster_count
def disaster_rate_switch(ys, s, l, e):
return tf.where(ys < s, e, l)
def disaster_rate_sigmoid(ys, s, l, e):
return e + tf.sigmoid(ys - s) * (l - e)
model_switch = disaster_count_model(disaster_rate_switch)
model_sigmoid = disaster_count_model(disaster_rate_sigmoid)
The above code defines the model via JointDistributionSequential distributions. The disaster_rate functions are called with an array of [0, ..., len(years)-1] to produce a vector of len(years) random variables – the years before the switchpoint are early_disaster_rate, the ones after late_disaster_rate (modulo the sigmoid transition).
Here is a sanity-check that the target log prob function is sane:
def target_log_prob_fn(model, s, e, l):
return model.log_prob(s=s, e=e, l=l, d_t=disaster_data)
models = [model_switch, model_sigmoid]
print([target_log_prob_fn(m, 40., 3., .9).numpy() for m in models]) # Somewhat likely result
print([target_log_prob_fn(m, 60., 1., 5.).numpy() for m in models]) # Rather unlikely result
print([target_log_prob_fn(m, -10., 1., 1.).numpy() for m in models]) # Impossible result
[-176.94559, -176.28717] [-371.3125, -366.8816] [-inf, -inf]
HMC to do Bayesian inference
We define the number of results and burn-in steps required; the code is mostly modeled after the documentation of tfp.mcmc.HamiltonianMonteCarlo. It uses an adaptive step size (otherwise the outcome is very sensitive to the step size value chosen). We use values of one as the initial state of the chain.
This is not the full story though. If you go back to the model definition above, you’ll note that some of the probability distributions are not well-defined on the whole real number line. Therefore we constrain the space that HMC shall examine by wrapping the HMC kernel with a TransformedTransitionKernel that specifies the forward bijectors to transform the real numbers onto the domain that the probability distribution is defined on (see comments in the code below).
num_results = 10000
num_burnin_steps = 3000
@tf.function(autograph=False, jit_compile=True)
def make_chain(target_log_prob_fn):
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.05,
num_leapfrog_steps=3),
bijector=[
# The switchpoint is constrained between zero and len(years).
# Hence we supply a bijector that maps the real numbers (in a
# differentiable way) to the interval (0;len(yers))
tfb.Sigmoid(low=0., high=tf.cast(len(years), dtype=tf.float32)),
# Early and late disaster rate: The exponential distribution is
# defined on the positive real numbers
tfb.Softplus(),
tfb.Softplus(),
])
kernel = tfp.mcmc.SimpleStepSizeAdaptation(
inner_kernel=kernel,
num_adaptation_steps=int(0.8*num_burnin_steps))
states = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=[
# The three latent variables
tf.ones([], name='init_switchpoint'),
tf.ones([], name='init_early_disaster_rate'),
tf.ones([], name='init_late_disaster_rate'),
],
trace_fn=None,
kernel=kernel)
return states
switch_samples = [s.numpy() for s in make_chain(
lambda *args: target_log_prob_fn(model_switch, *args))]
sigmoid_samples = [s.numpy() for s in make_chain(
lambda *args: target_log_prob_fn(model_sigmoid, *args))]
switchpoint, early_disaster_rate, late_disaster_rate = zip(
switch_samples, sigmoid_samples)
Run both models in parallel:
Visualize the result
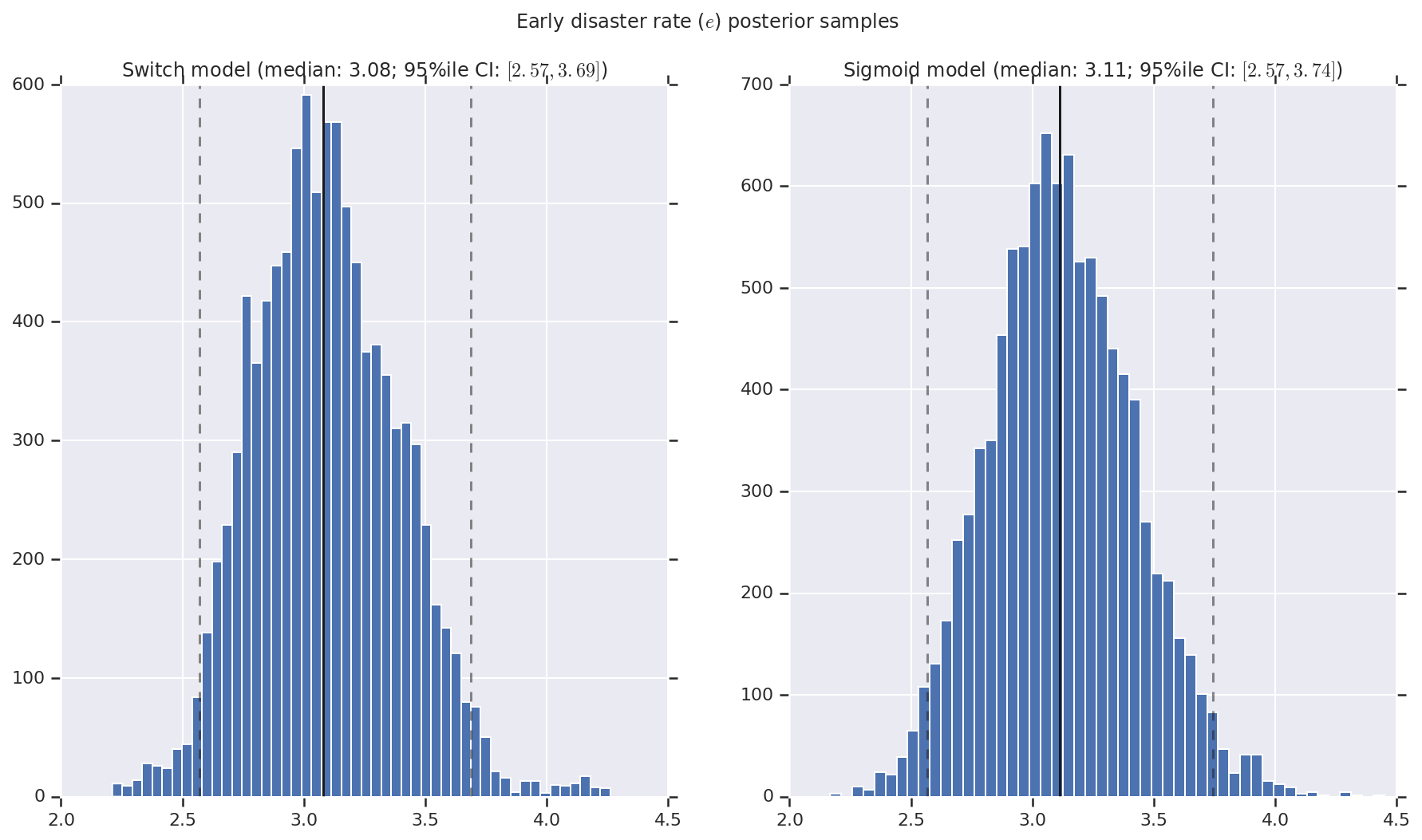
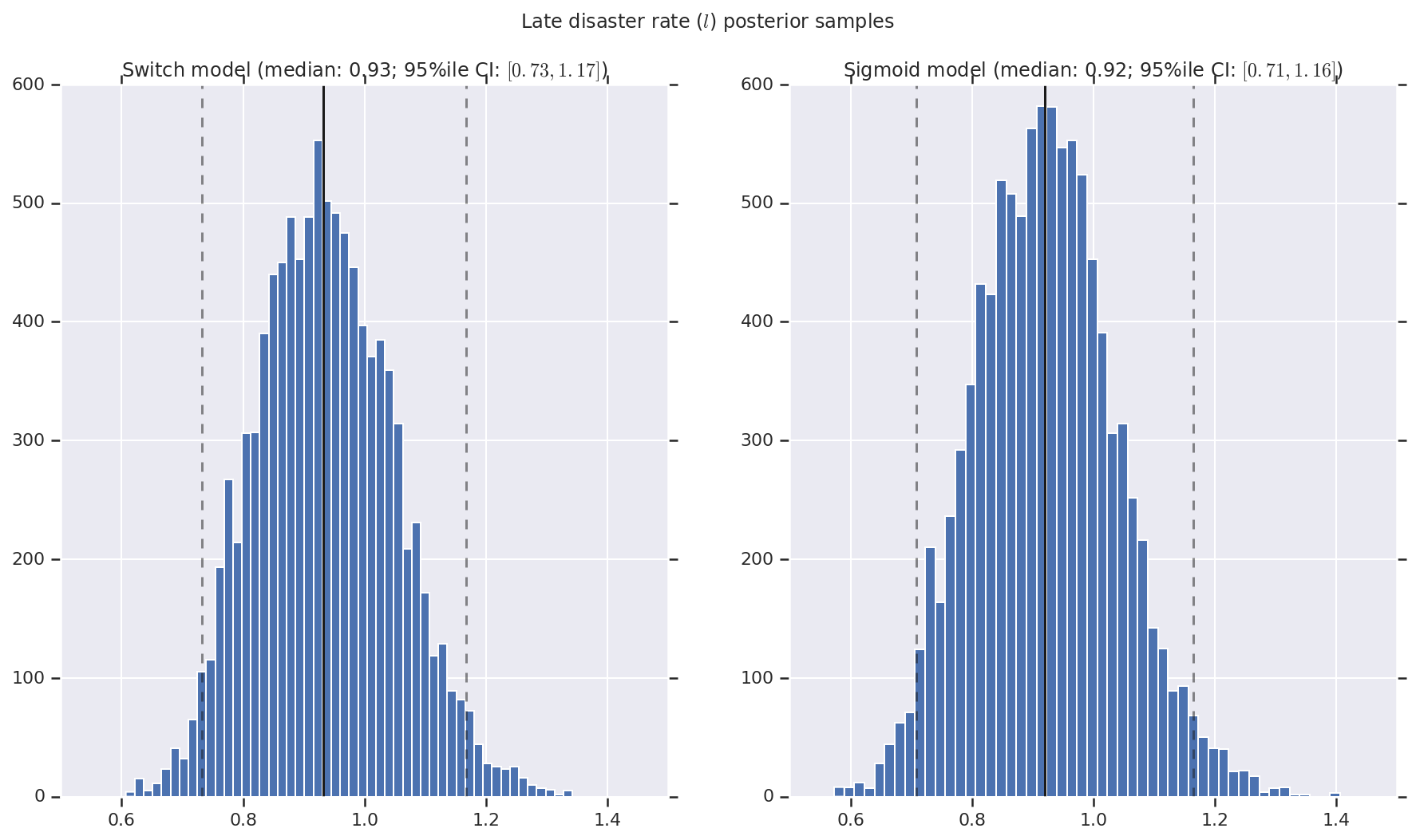
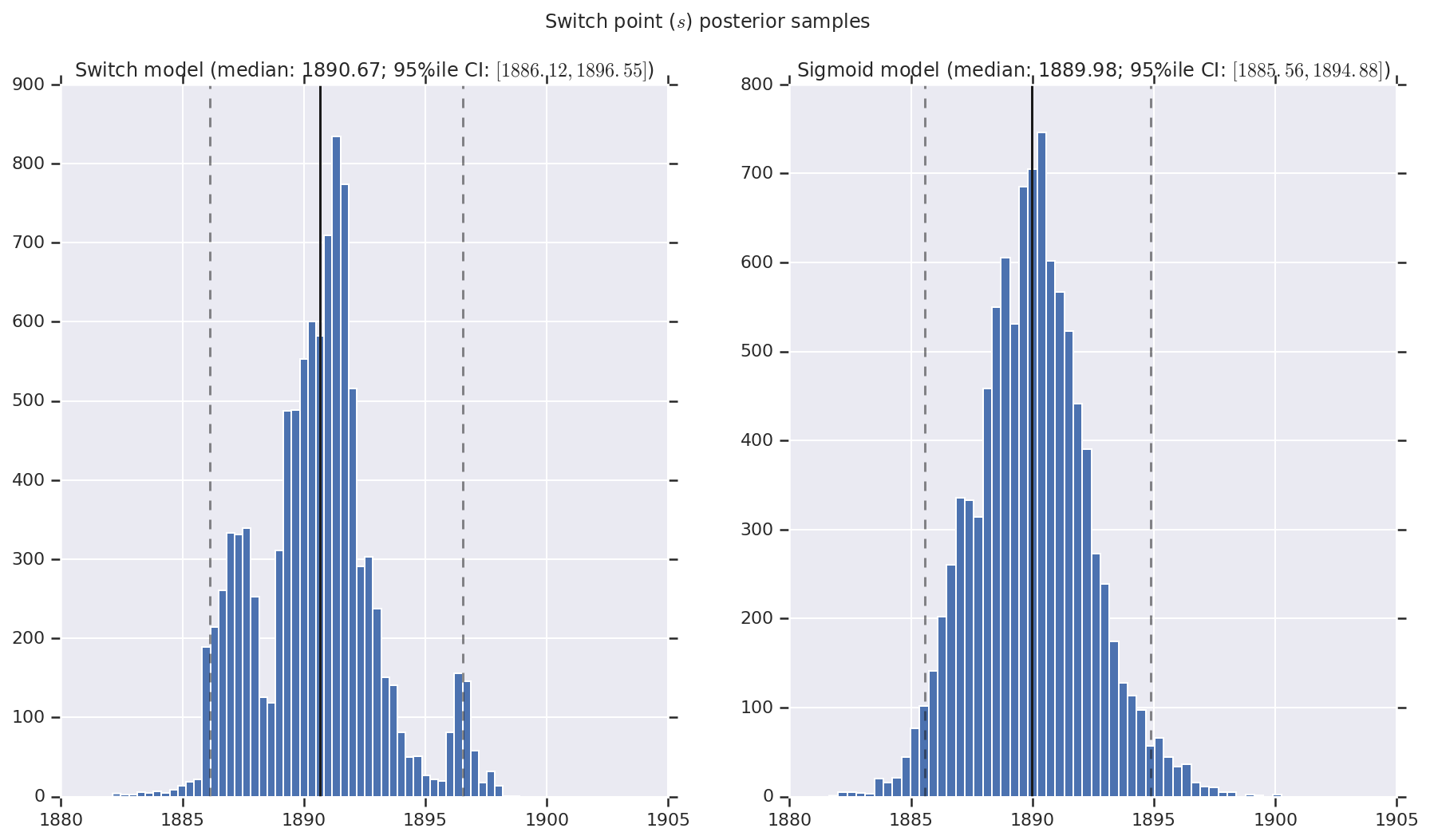
We visualize the result as histograms of samples of the posterior distribution for the early and late disaster rate, as well as the switchpoint. The histograms are overlaid with a solid line representing the sample median, as well as the 95%ile credible interval bounds as dashed lines.
def _desc(v):
return '(median: {}; 95%ile CI: $[{}, {}]$)'.format(
*np.round(np.percentile(v, [50, 2.5, 97.5]), 2))
for t, v in [
('Early disaster rate ($e$) posterior samples', early_disaster_rate),
('Late disaster rate ($l$) posterior samples', late_disaster_rate),
('Switch point ($s$) posterior samples', years[0] + switchpoint),
]:
fig, ax = plt.subplots(nrows=1, ncols=2, sharex=True)
for (m, i) in (('Switch', 0), ('Sigmoid', 1)):
a = ax[i]
a.hist(v[i], bins=50)
a.axvline(x=np.percentile(v[i], 50), color='k')
a.axvline(x=np.percentile(v[i], 2.5), color='k', ls='dashed', alpha=.5)
a.axvline(x=np.percentile(v[i], 97.5), color='k', ls='dashed', alpha=.5)
a.set_title(m + ' model ' + _desc(v[i]))
fig.suptitle(t)
plt.show()