
TL;DR : TensorFlow Sıralama İşlem Hatları ile TensorFlow Sıralama modellerini oluşturmak, eğitmek ve sunmak için standart kodu azaltın; Kullanım durumu ve kaynaklar göz önüne alındığında, büyük ölçekli sıralama uygulamaları için uygun dağıtılmış stratejiler kullanın.
giriiş
TensorFlow Sıralama İşlem Hattı, minimum çabayla veri günlüklerinden ölçeklenebilir sinir ağı tabanlı sıralama modelleri oluşturmanıza, eğitmenize ve hizmet vermenize olanak tanıyan bir dizi veri işleme, model oluşturma, eğitim ve hizmet sürecinden oluşur. Boru hattı, sistemin ölçeği büyüdüğünde en verimli şekilde çalışır. Genel olarak, modelinizin tek bir makinede çalışması 10 dakika veya daha uzun sürüyorsa yükü dağıtmak ve işlemeyi hızlandırmak için bu işlem hattı çerçevesini kullanmayı düşünün.
TensorFlow Sıralama İşlem Hattı, dağıtılmış sistemlerde (1K+ CPU ve 100+ GPU ve TPU) büyük veriler (terabayt+) ve büyük modeller (100M+ FLOP) içeren büyük ölçekli deneylerde ve üretimlerde sürekli ve istikrarlı bir şekilde çalıştırılmıştır. Bir TensorFlow modeli, verilerin küçük bir kısmında model.fit ile kanıtlandıktan sonra hiper parametre taraması, sürekli eğitim ve diğer büyük ölçekli durumlar için ardışık düzen önerilir.
Sıralama Hattı
TensorFlow'da bir sıralama modeli oluşturmak, eğitmek ve sunmak için kullanılan tipik bir işlem hattı aşağıdaki tipik adımları içerir.
- Model yapısını tanımlayın:
- Girişler oluşturun;
- Ön işleme katmanları oluşturun;
- Sinir ağı mimarisi oluşturun;
- Tren modeli:
- Veri günlüklerinden eğitim ve doğrulama veri kümeleri oluşturun;
- Modeli uygun hiper parametrelerle hazırlayın:
- Optimize Edici;
- Sıralama kayıpları;
- Sıralama Metrikleri;
- Birden fazla cihazda eğitim vermek için dağıtılmış stratejileri yapılandırın.
- Çeşitli muhasebe işlemleri için geri aramaları yapılandırın.
- Sunum için ihracat modeli;
- Servis modeli:
- Sunum sırasında veri formatını belirleyin;
- Eğitilmiş modeli seçin ve yükleyin;
- Yüklü modelle işlem yapın.
TensorFlow Sıralaması ardışık düzeninin ana hedeflerinden biri, veri kümesi yükleme ve ön işleme, listesel verilerin ve noktasal puanlama fonksiyonunun uyumluluğu ve model aktarımı gibi adımlarda standart kodu azaltmaktır. Diğer önemli amaç, doğası gereği ilişkili birçok sürecin tutarlı tasarımını sağlamaktır; örneğin, model girdileri, sunum sırasında hem eğitim veri kümeleriyle hem de veri formatıyla uyumlu olmalıdır.
Kılavuzu Kullan
Yukarıdaki tasarımın tümü ile, TF dereceli bir modelin başlatılması, Şekil 1'de gösterildiği gibi aşağıdaki adımlara dayanmaktadır.
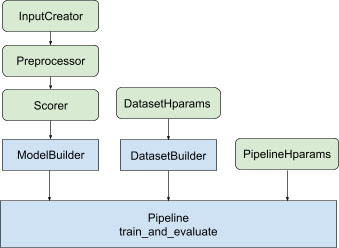
Dağıtılmış bir sinir ağının kullanıldığı örnek
Bu örnekte, model girişlerindeki giriş özelliklerini tutarlı bir şekilde tanımlamak için feature_spec s'yi alan yerleşik tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder ve tfr.keras.pipeline.SimplePipeline yararlanacaksınız. veri kümesi sunucusu. Adım adım açıklamalı not defteri sürümünü dağıtılmış sıralama eğitiminde bulabilirsiniz.
Öncelikle hem bağlam hem de örnek özellikler için feature_spec tanımlayın.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
Şekil 1'de gösterilen adımları izleyin:
input_creator feature_spec s'den tanımlayın.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
Daha sonra aynı giriş özellikleri kümesi için ön işleme özelliği dönüşümlerini tanımlayın.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
Yerleşik ileri beslemeli DNN modeliyle puanlayıcıyı tanımlayın.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
model_builder input_creator , preprocessor ve scorer ile yapın.
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
Şimdi dataset_builder için hiperparametreleri ayarlayın.
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
dataset_builder yapın.
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
Ayrıca ardışık düzen için hiperparametreleri de ayarlayın.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
ranking_pipeline yapın ve eğitin.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
TensorFlow Sıralama Boru Hattının Tasarımı
TensorFlow Sıralama İşlem Hattı, ortak kodla mühendislik zamanından tasarruf etmenize yardımcı olur, aynı zamanda geçersiz kılma ve alt sınıflandırma yoluyla özelleştirme esnekliği sağlar. Bunu başarmak için işlem hattı, TensorFlow Sıralaması işlem hattını ayarlamak için tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder ve tfr.keras.pipeline.AbstractPipeline özelleştirilebilir sınıflarını sunar.

Model Oluşturucu
Keras modelinin oluşturulmasıyla ilgili standart kod, AbstractModelBuilder entegre edilir ve bu, AbstractPipeline iletilir ve modeli strateji kapsamı altında oluşturmak için işlem hattının içinde çağrılır. Bu, Şekil 1'de gösterilmektedir. Sınıf yöntemleri soyut temel sınıfta tanımlanır.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
AbstractModelBuilder doğrudan alt sınıflandırabilir ve özelleştirme için somut yöntemlerin üzerine yazabilirsiniz.
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
Aynı zamanda ModelBuilder , alt sınıflama yerine init sınıfında input_creator , preprocessor ve scorer işlev girişleri olarak belirtilen giriş özellikleri, önişlem dönüşümleri ve puanlama işlevleriyle birlikte kullanmalısınız.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
Bu girişleri oluşturmanın standartlarını azaltmak amacıyla, input_creator için tfr.keras.model.InputCreator , preprocessor için tfr.keras.model.Preprocessor ve scorer için tfr.keras.model.Scorer işlev sınıfları, tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer ve tfr.keras.model.GAMScorer . Bunlar yaygın kullanım durumlarının çoğunu kapsamalıdır.
Bu işlev sınıflarının Keras sınıfları olduğunu ve dolayısıyla serileştirmeye gerek olmadığını unutmayın. Alt sınıflandırma, bunları özelleştirmenin önerilen yoludur.
Veri Kümesi Oluşturucu
DatasetBuilder sınıfı, veri kümesiyle ilgili ortak metni toplar. Veriler Pipeline Hattı'na iletilir ve eğitim ve doğrulama veri kümelerine hizmet vermek ve kaydedilen modeller için hizmet imzalarını tanımlamak üzere çağrılır. Şekil 1'de gösterildiği gibi DatasetBuilder yöntemleri tfr.keras.pipeline.AbstractDatasetBuilder temel sınıfında tanımlanmıştır,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
Somut bir DatasetBuilder sınıfında build_train_datasets , build_valid_datasets ve build_signatures öğelerini uygulamanız gerekir.
feature_spec s'den veri kümeleri oluşturan somut bir sınıf da sağlanır:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
DatasetBuilder kullanılan hparams tfr.keras.pipeline.DatasetHparams veri sınıfında belirtilir.
Boru hattı
Sıralama Ardışık Düzeni tfr.keras.pipeline.AbstractPipeline sınıfını temel alır:
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
Modeli, model.fit ile uyumlu farklı tf.distribute.strategy eğiten somut bir işlem hattı sınıfı da sağlanır:
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
tfr.keras.pipeline.ModelFitPipeline kullanılan hparams tfr.keras.pipeline.PipelineHparams veri sınıfında belirtilir. Bu ModelFitPipeline sınıfı çoğu TF Sıralaması kullanım durumu için yeterlidir. Müşteriler bunu belirli amaçlar için kolayca alt sınıflara ayırabilirler.
Dağıtılmış Strateji desteği
TensorFlow destekli dağıtılmış stratejilerin ayrıntılı tanıtımı için lütfen dağıtılmış eğitime bakın. Şu anda TensorFlow Sıralaması ardışık düzeni tf.distribute.MirroredStrategy (varsayılan), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy ve tf.distribute.ParameterServerStrategy desteklemektedir. Aynalanmış strateji, tek makine sistemlerinin çoğuyla uyumludur. Dağıtılmış strateji olmaması durumunda lütfen strategy None olarak ayarlayın.
Genel olarak MirroredStrategy , CPU ve GPU seçeneklerine sahip çoğu cihazda nispeten küçük modeller için çalışır. MultiWorkerMirroredStrategy tek bir çalışana sığmayan büyük modeller için işe yarar. ParameterServerStrategy eşzamansız eğitim yapar ve birden fazla çalışanın mevcut olmasını gerektirir. TPUStrategy TPU'lar mevcut olduğunda büyük modeller ve büyük veriler için idealdir ancak işleyebileceği tensör şekilleri açısından daha az esnektir.
SSS
RankingPipelinekullanmak için minimum bileşen seti
Yukarıdaki örnek koda bakın.Peki ya kendi Keras
modelvarsa
tf.distributestratejileriyle eğitilmek içinmodel, strateji.scope() altında tanımlanan tüm eğitilebilir değişkenlerle oluşturulması gerekir. ModeliniziModelBuilderşu şekilde sarın:
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
Daha sonra daha fazla eğitim için bu model_builder'ı işlem hattına besleyin.