
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
W tym samouczku pokazano, jak używać Deep & Cross Network (DCN) do efektywnego uczenia się krzyżowania funkcji.
Tło
Czym są krzyże cech i dlaczego są ważne? Wyobraź sobie, że budujemy system rekomendacji, aby sprzedawać blender klientom. Następnie, w przeszłości zakupu przez klienta, takich jak purchased_bananas i purchased_cooking_books lub obiektów geograficznych, są pojedyncze cechy. Jeśli ktoś nabył zarówno banany i gotowania książki, to klient będzie bardziej prawdopodobne, kliknij na zalecanym blenderze. Połączenie purchased_bananas i purchased_cooking_books jest określany jako krzyż fabularnego, który zawiera dodatkowe informacje interakcji poza poszczególnymi funkcjami.
Jakie są wyzwania w nauce krzyżyków funkcji? W aplikacjach na skalę internetową dane są w większości kategoryczne, co prowadzi do dużej i rzadkiej przestrzeni dla funkcji. Identyfikowanie efektywnych krzyżyków cech w tym ustawieniu często wymaga ręcznej inżynierii cech lub wyczerpującego wyszukiwania. Tradycyjne modele perceptronu wielowarstwowego ze sprzężeniem do przodu (MLP) są uniwersalnymi aproksymatorami funkcji; Jednakże, nie można skutecznie nawet w przybliżeniu 2 lub 3 rzędu krzyże funkcji [ 1 , 2 ].
Co to jest sieć głęboka i międzysieciowa (DCN)? DCN został zaprojektowany w celu efektywniejszego uczenia się funkcji jawnych i ograniczonych stopni krzyżowych. Zaczyna się od warstwy wejściowej (zazwyczaj osadzanie warstwy), a następnie pole karne sieci zawierającej wiele warstw poprzecznych, że modele wyraźne interakcje fabularne, a następnie łączy się z siecią, która głęboko ukryte modele interakcji funkcję.
- Międzysieciowe. To jest rdzeń DCN. Stosuje on wyraźnie przecinanie elementów w każdej warstwie, a najwyższy stopień wielomianu zwiększa się wraz z głębokością warstwy. Poniżej przedstawiono figurę w \((i+1)\)-ty poprzecznego warstwy.
- Głęboka sieć. Jest to tradycyjny sprzężony wielowarstwowy perceptron (MLP).
Następnie łączy się głęboko sieci i sieci, aby utworzyć przekrój DCN [ 1 ]. Zwykle możemy układać głęboką sieć na górze sieci krzyżowej (struktura piętrowa); moglibyśmy również umieścić je równolegle (struktura równoległa).
Poniżej najpierw pokażemy zalety DCN na przykładzie zabawki, a następnie przedstawimy kilka typowych sposobów wykorzystania DCN przy użyciu zestawu danych MovieLen-1M.
Najpierw zainstalujmy i zaimportujmy niezbędne pakiety dla tej współpracy.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
Przykład zabawki
Aby zilustrować zalety DCN, przeanalizujmy prosty przykład. Załóżmy, że mamy zbiór danych, w którym próbujemy modelować prawdopodobieństwo kliknięcia przez klienta reklamy blendera, z jej funkcjami i etykietą opisanymi poniżej.
| Funkcje / Etykieta | Opis | Typ/zakres wartości |
|---|---|---|
| \(x_1\) = kraj | kraj, w którym mieszka ten klient | Int w [0, 199] |
| \(x_2\) = banany | # banany kupione przez klienta | Int w [0, 23] |
| \(x_3\) = kucharskie | # książek kucharskich kupionych przez klienta | Int w [0, 5] |
| \(y\) | prawdopodobieństwo kliknięcia w blender Ad | -- |
Następnie pozwalamy, aby dane były zgodne z następującym rozkładem:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
gdzie prawdopodobieństwo \(y\) zależy liniowo zarówno od cech \(x_i\)„s, ale także na multyplikatywnych interakcji pomiędzy \(x_i\)” s. W naszym przypadku, chcemy powiedzieć, że prawdopodobieństwo zakupu miksera (\(y\)) zależy nie tylko od kupowania bananów (\(x_2\)) lub książki kucharskie (\(x_3\)), ale także na zakup banany i książki kucharskie razem (\(x_2x_3\)).
Dane do tego możemy wygenerować w następujący sposób:
Generowanie danych syntetycznych
Najpierw określić \(f(x_1, x_2, x_3)\) jak opisano powyżej.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
Wygenerujmy dane zgodne z rozkładem i podzielmy je na 90% do treningu i 10% do testowania.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
Budowa modelu
Wypróbujemy zarówno sieć międzysieciową, jak i głęboką, aby zilustrować korzyści, jakie sieć międzysieciowa może przynieść osobom polecającym. Ponieważ dane, które właśnie utworzyliśmy, zawierają tylko interakcje funkcji drugiego rzędu, wystarczyłoby zilustrować je jednowarstwową siecią krzyżową. Gdybyśmy chcieli modelować interakcje między funkcjami wyższego rzędu, moglibyśmy ułożyć wiele warstw krzyżowych i użyć wielowarstwowej sieci krzyżowej. Dwa modele, które będziemy budować to:
- Cross Network z tylko jedną warstwą krzyżową;
- Deep Network z szerszymi i głębszymi warstwami ReLU.
Najpierw budujemy zunifikowaną klasę modelu, której stratą jest błąd średniokwadratowy.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
Następnie określamy sieć krzyżową (z 1 warstwą krzyżową o rozmiarze 3) i DNN oparte na ReLU (z rozmiarami warstw [512, 256, 128]):
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
Szkolenie modelowe
Teraz, gdy mamy gotowe dane i modele, będziemy trenować modele. Najpierw tasujemy i grupujemy dane, aby przygotować się do trenowania modelu.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
Następnie określamy liczbę epok oraz tempo uczenia się.
epochs = 100
learning_rate = 0.4
W porządku, wszystko jest już gotowe, skompilujmy i przeszkolmy modele. Można ustawić verbose=True , jeśli chcesz zobaczyć, jak model postępy.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
Ocena modelu
Weryfikujemy wydajność modelu na zestawie danych oceny i zgłaszamy błąd średniokwadratowy (RMSE, im niższy, tym lepiej).
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
Widzimy, że sieć krzyż osiągnięte wielkości niższe niż Relu RMSE opartej DNN a, z wielkości mniejszej liczby parametrów. Sugeruje to skuteczność sieci krzyżowej w uczeniu się funkcji krzyżowych.
Zrozumienie modelu
Wiemy już, jakie krzyże cech są ważne w naszych danych, fajnie byłoby sprawdzić, czy nasz model rzeczywiście nauczył się ważnego krzyża cech. Można to zrobić, wizualizując wyuczoną macierz wag w DCN. Masa \(W_{ij}\) reprezentuje poznaną znaczenie interakcji między funkcji \(x_i\) i \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
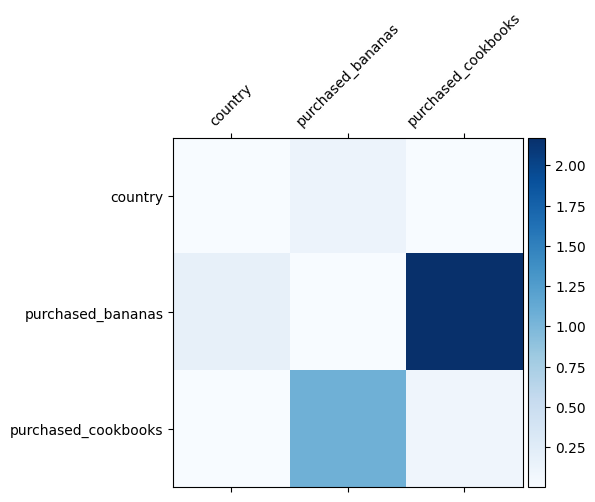
Ciemniejsze kolory reprezentują silniejsze wyuczone interakcje — w tym przypadku wyraźnie widać, że modelka nauczyła się, że ważne jest wspólne kupowanie baban i książek kucharskich.
Jeśli jesteś zainteresowany przetestowaniem bardziej skomplikowanych danych syntetycznych, nie krępuj się, aby sprawdzić ten papier .
Przykład z filmem 1M
Mamy teraz zbadać skuteczność DCN w świecie rzeczywistym zbiorze: Movielens 1M [ 3 ]. Movielens 1M to popularny zbiór danych do badania rekomendacji. Przewiduje oceny filmów użytkowników, biorąc pod uwagę funkcje związane z użytkownikiem i funkcje związane z filmem. Używamy tego zbioru danych, aby zademonstrować kilka typowych sposobów korzystania z DCN.
Przetwarzanie danych
Procedura przetwarzania danych następuje podobną procedurę jako podstawowego tutoriala rankingowej .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
Następnie losowo dzielimy dane na 80% do treningu i 20% do testowania.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
Następnie tworzymy słownictwo dla każdej funkcji.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
Budowa modelu
Architektura modelu, którą będziemy budować, zaczyna się od warstwy osadzania, która jest wprowadzana do sieci krzyżowej, po której następuje sieć głęboka. Wymiar osadzania jest ustawiony na 32 dla wszystkich operacji. Możesz także użyć różnych rozmiarów osadzania dla różnych funkcji.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
Szkolenie modelowe
Tasujemy, grupujemy i buforujemy dane treningowe i testowe.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
Zdefiniujmy funkcję, która uruchamia model wiele razy i zwraca średnią RMSE i odchylenie standardowe modelu z wielu przebiegów.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
Ustawiliśmy kilka hiperparametrów dla modeli. Należy zauważyć, że te hiperparametry są ustawiane globalnie dla wszystkich modeli w celach demonstracyjnych. Jeśli chcesz uzyskać najlepszą wydajność dla każdego modelu lub przeprowadzić rzetelne porównanie między modelami, sugerujemy precyzyjne dostrojenie hiperparametrów. Pamiętaj, że architektura modelu i schematy optymalizacji są ze sobą powiązane.
epochs = 8
learning_rate = 0.01
DCN (skumulowany). Najpierw trenujemy model DCN ze strukturą stosową, co oznacza, że dane wejściowe są przesyłane do sieci międzysieciowej, a następnie do sieci głębokiej.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
DCN niskiej rangi. Aby obniżyć koszty szkolenia i obsługi, wykorzystujemy techniki niskiego poziomu, aby przybliżyć macierze wag DCN. Ranga jest przekazywana za pośrednictwem argumentu projection_dim ; Mniejsza projection_dim skutkuje niższym koszcie. Zauważ, że projection_dim musi być mniejsza niż (wielkości wejściowych) / 2 w celu zmniejszenia kosztów. W praktyce zaobserwowaliśmy, że użycie DCN o niskiej randze z rangą (rozmiar danych wejściowych)/4 konsekwentnie zachowywało dokładność DCN o pełnej randze.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. Jako odniesienie szkolimy model DNN o tej samej wielkości.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
Oceniamy model na danych testowych i przedstawiamy średnią i odchylenie standardowe z 5 przebiegów.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
Widzimy, że DCN osiągnął lepszą wydajność niż DNN o tej samej wielkości z warstwami ReLU. Co więcej, DCN niskiej rangi był w stanie zredukować parametry przy zachowaniu dokładności.
Więcej o DCN. Poza what've wykazano powyżej, istnieje jeszcze bardziej oszczędny praktycznie użyteczne sposoby wykorzystujące DCN [ 1 ].
DCN z równoległych konstrukcji. Wejścia są podawane równolegle do sieci krzyżowej i sieci głębokiej.
Łączenie warstw krzyżowych. Wejścia są podawane równolegle do wielu warstw krzyżowych, aby uchwycić krzyżyki uzupełniających się cech.
Zrozumienie modelu
Matryca waga \(W\) w DCN ujawnia co cecha przecina model nauczył się być ważne. Przypomnijmy, że w poprzednim przykładzie zabawki znaczenie interakcji między \(i\)-ty oraz \(j\)-tej funkcji jest przechwytywane przez (\(i, j\)) -ty element \(W\).
Co znajduje się w nieco inny tutaj jest to, że zanurzeń fabularne są rozmiaru 32 zamiast wielkości 1. Stąd znaczenie będzie charakteryzował się \((i, j)\)-tego bloku\(W_{i,j}\) co ma wymiar 32 przez 32. W dalszej części, wizualizację normę Frobenius'a [ 4 ] \(||W_{i,j}||_F\) każdego bloku, i większy normę sugerowałyby większe znaczenie (zakładając zanurzeń się funkcje są podobnych skalach).
Oprócz normy blokowej możemy również zwizualizować całą macierz lub średnią/medianę/maksymalną wartość każdego bloku.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
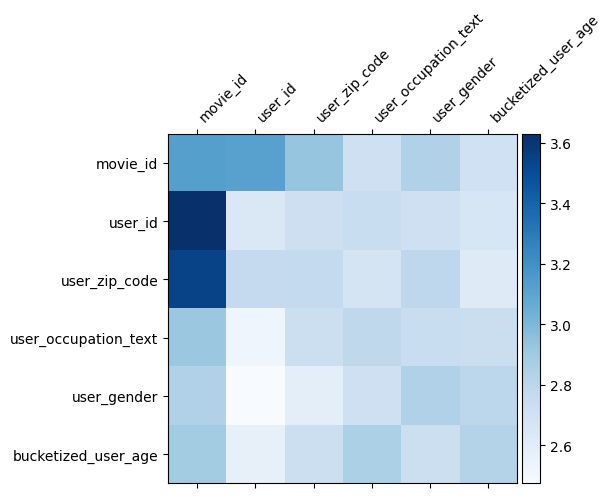
To wszystko dla tej współpracy! Mamy nadzieję, że zapoznanie się z podstawami DCN i powszechnymi sposobami korzystania z niego sprawiło Ci przyjemność. Jeśli jesteś zainteresowany dowiedzieć się więcej, można sprawdzić dwa istotne dokumenty: DCN-v1-papierowych , DCN-v2-papieru .
Bibliografia
DCN V2: Ulepszona Głębokie i Krzyż Sieć i zajęcia praktyczne dla Web skalę Learning oceniającym Systems .
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, Ed Chi. (2020)
Głębokie i Krzyż Sieć Przewidywania kliknięcia reklamy .
Ruoxi Wang, Bin Fu, Gang Fu, Mingliang Wang. (AdKDD 2017)