
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
En el tutorial featurization incorporamos características múltiples en nuestros modelos, pero los modelos consisten en sólo una capa de encaje. Podemos agregar capas más densas a nuestros modelos para aumentar su poder expresivo.
En general, los modelos más profundos son capaces de aprender patrones más complejos que los modelos menos profundos. Por ejemplo, nuestro modelo de usuario incorpora identificadores de usuario y las marcas de tiempo a las preferencias del usuario modelo en un punto en el tiempo. Un modelo superficial (digamos, una sola capa de inserción) solo puede aprender las relaciones más simples entre esas características y películas: una película determinada es más popular en el momento de su lanzamiento, y un usuario determinado generalmente prefiere las películas de terror a las comedias. Para capturar relaciones más complejas, como las preferencias del usuario que evolucionan con el tiempo, es posible que necesitemos un modelo más profundo con múltiples capas densas apiladas.
Por supuesto, los modelos complejos también tienen sus desventajas. El primero es el costo computacional, ya que los modelos más grandes requieren más memoria y más computación para adaptarse y servir. El segundo es el requisito de más datos: en general, se necesitan más datos de entrenamiento para aprovechar modelos más profundos. Con más parámetros, los modelos profundos pueden sobreajustarse o incluso simplemente memorizar los ejemplos de entrenamiento en lugar de aprender una función que pueda generalizar. Finalmente, entrenar modelos más profundos puede ser más difícil y se debe tener más cuidado al elegir entornos como la regularización y la tasa de aprendizaje.
Encontrar una buena arquitectura para un sistema de recomendación en el mundo real es un arte complejo, que requiere una buena intuición y una cuidadosa puesta a punto hiperparámetro . Por ejemplo, factores como la profundidad y el ancho del modelo, la función de activación, la tasa de aprendizaje y el optimizador pueden cambiar radicalmente el rendimiento del modelo. Las opciones de modelado se complican aún más por el hecho de que las buenas métricas de evaluación fuera de línea pueden no corresponder a un buen rendimiento en línea, y que la elección de qué optimizar es a menudo más crítica que la elección del modelo en sí.
Sin embargo, el esfuerzo que se pone en construir y ajustar modelos más grandes a menudo vale la pena. En este tutorial, ilustraremos cómo crear modelos de recuperación profunda con los recomendadores de TensorFlow. Haremos esto construyendo modelos progresivamente más complejos para ver cómo esto afecta el rendimiento del modelo.
Preliminares
Primero importamos los paquetes necesarios.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
En este tutorial vamos a utilizar los modelos de la clase particular featurization para generar incrustaciones. Por lo tanto, solo usaremos la identificación de usuario, la marca de tiempo y las características del título de la película.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
También hacemos algunas tareas de limpieza para preparar vocabularios de características.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
Definición de modelo
Modelo de consulta
Empezamos con el modelo definido por el usuario en el tutorial featurization que la primera capa de nuestro modelo, la tarea de conversión de ejemplos de entrada sin procesar en incrustaciones de características.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
Definir modelos más profundos requerirá que apilemos capas de modo sobre esta primera entrada. Una pila de capas cada vez más estrecha, separada por una función de activación, es un patrón común:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
Dado que el poder expresivo de los modelos lineales profundos no es mayor que el de los modelos lineales superficiales, utilizamos las activaciones de ReLU para todos menos la última capa oculta. La capa oculta final no usa ninguna función de activación: el uso de una función de activación limitaría el espacio de salida de las incrustaciones finales y podría afectar negativamente el rendimiento del modelo. Por ejemplo, si se utilizan ReLU en la capa de proyección, todos los componentes de la incrustación de salida serían no negativos.
Intentaremos algo similar aquí. Para facilitar la experimentación con diferentes profundidades, definamos un modelo cuya profundidad (y ancho) está definida por un conjunto de parámetros de constructor.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
El layer_sizes parámetro nos da la profundidad y la anchura del modelo. Podemos variarlo para experimentar con modelos más superficiales o más profundos.
Modelo candidato
Podemos adoptar el mismo enfoque para el modelo de película. Una vez más, comenzamos con la MovieModel del featurization tutorial:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
Y amplíelo con capas ocultas:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
Modelo combinado
Con tanto QueryModel y CandidateModel definidos, podemos armar un modelo combinado e implementar nuestra lógica pérdida y métricas. Para simplificar las cosas, exigiremos que la estructura del modelo sea la misma en todos los modelos de consulta y candidato.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
Entrenando el modelo
Prepara los datos
Primero dividimos los datos en un conjunto de entrenamiento y un conjunto de prueba.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
Modelo poco profundo
¡Estamos listos para probar nuestro primer modelo superficial!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
Esto nos da una precisión entre los 100 mejores de alrededor de 0,27. Podemos usar esto como un punto de referencia para evaluar modelos más profundos.
Modelo más profundo
¿Qué tal un modelo más profundo con dos capas?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
La precisión aquí es de 0,29, bastante mejor que en el modelo poco profundo.
Podemos trazar las curvas de precisión de validación para ilustrar esto:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
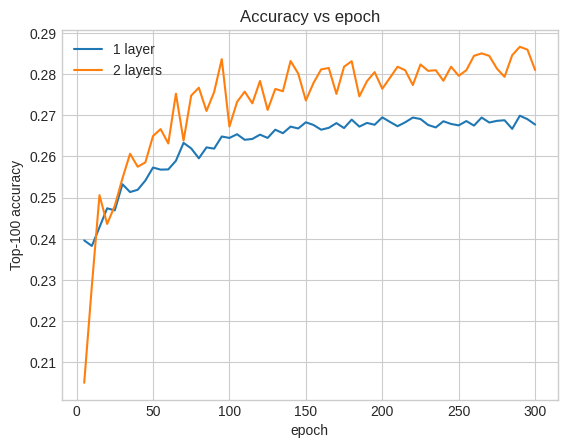
Incluso al principio del entrenamiento, el modelo más grande tiene una ventaja clara y estable sobre el modelo superficial, lo que sugiere que agregar profundidad ayuda al modelo a capturar relaciones más matizadas en los datos.
Sin embargo, los modelos aún más profundos no son necesariamente mejores. El siguiente modelo extiende la profundidad a tres capas:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
De hecho, no vemos mejoras con respecto al modelo superficial:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
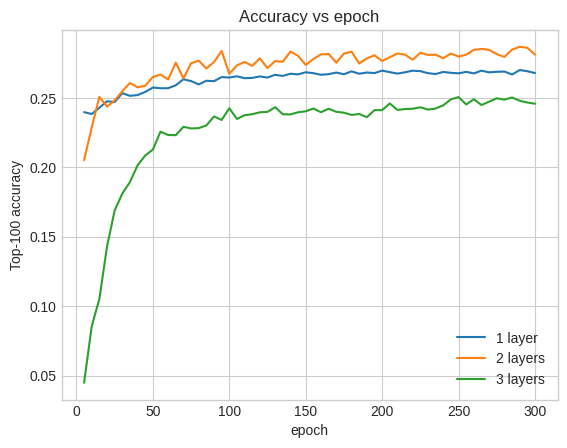
Ésta es una buena ilustración del hecho de que los modelos más grandes y profundos, aunque pueden ofrecer un rendimiento superior, a menudo requieren un ajuste muy cuidadoso. Por ejemplo, a lo largo de este tutorial utilizamos una única tasa de aprendizaje fija. Las opciones alternativas pueden dar resultados muy diferentes y vale la pena explorarlas.
Con el ajuste adecuado y los datos suficientes, el esfuerzo realizado para construir modelos más grandes y más profundos en muchos casos vale la pena: los modelos más grandes pueden conducir a mejoras sustanciales en la precisión de la predicción.
Próximos pasos
En este tutorial ampliamos nuestro modelo de recuperación con capas densas y funciones de activación. Para ver cómo crear un modelo que puede realizar no sólo tareas de recuperación, sino también tareas de calificación, echar un vistazo a la guía de aprendizaje de tareas múltiples .