
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
W featurization poradnik wprowadziliśmy wiele funkcji w naszych modelach, ale modele składają się tylko z warstwy osadzania. Możemy dodać gęstsze warstwy do naszych modeli, aby zwiększyć ich siłę wyrazu.
Ogólnie rzecz biorąc, głębsze modele są w stanie uczyć się bardziej złożonych wzorców niż modele płytsze. Na przykład, nasz model użytkownika zawiera identyfikatory użytkowników i znaczników czasu do modelu preferencji użytkownika w danym momencie. Płytka modelka (powiedzmy, pojedyncza warstwa osadzania) może być w stanie nauczyć się tylko najprostszych relacji między tymi funkcjami a filmami: dany film jest najbardziej popularny w momencie premiery, a dany użytkownik generalnie woli horrory od komedii. Aby uchwycić bardziej złożone relacje, takie jak preferencje użytkownika zmieniające się w czasie, możemy potrzebować głębszego modelu z wieloma ułożonymi warstwami gęstymi.
Oczywiście skomplikowane modele mają też swoje wady. Pierwszym z nich jest koszt obliczeniowy, ponieważ większe modele wymagają zarówno większej ilości pamięci, jak i większej liczby obliczeń, aby dopasować się i obsłużyć. Drugi to wymóg posiadania większej ilości danych: ogólnie rzecz biorąc, potrzeba więcej danych uczących, aby skorzystać z głębszych modeli. Przy większej liczbie parametrów głębokie modele mogą przesadzać lub nawet po prostu zapamiętywać przykłady szkoleniowe zamiast uczyć się funkcji, która może uogólniać. Wreszcie, trenowanie głębszych modeli może być trudniejsze i należy zachować większą ostrożność przy wyborze ustawień, takich jak regularyzacja i tempo uczenia się.
Znalezienie dobrej architektury na system rekomendacyjny w świecie rzeczywistym jest złożonym sztuka, wymagająca dobrej intuicji i starannego hyperparameter strojenie . Na przykład czynniki takie jak głębokość i szerokość modelu, funkcja aktywacji, szybkość uczenia się i optymalizator mogą radykalnie zmienić wydajność modelu. Wybory dotyczące modelowania są dodatkowo komplikowane przez fakt, że dobre metryki oceny offline mogą nie odpowiadać dobrej wydajności online, a wybór tego, co należy zoptymalizować, jest często bardziej krytyczny niż wybór samego modelu.
Niemniej wysiłek włożony w budowanie i dostrajanie większych modeli często się opłaca. W tym samouczku zilustrujemy, jak budować głębokie modele wyszukiwania za pomocą rekomendacji TensorFlow. Zrobimy to, budując coraz bardziej złożone modele, aby zobaczyć, jak wpływa to na wydajność modelu.
Czynności wstępne
Najpierw importujemy niezbędne pakiety.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
W tym tutorialu użyjemy modeli z samouczka featurization wygenerować zanurzeń. Dlatego będziemy używać tylko funkcji identyfikatora użytkownika, sygnatury czasowej i tytułu filmu.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Zajmujemy się również sprzątaniem, aby przygotować słownictwo fabularne.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
Definicja modelu
Model zapytania
Rozpoczynamy od modelu użytkownika określonego w kursie featurization jako pierwszej warstwy naszym modelu zadanie przekształcenie surowych przykłady wejściowe zanurzeń funkcji.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
Definiowanie głębszych modeli będzie wymagało od nas ułożenia warstw trybów na pierwszym wejściu. Coraz węższy stos warstw, oddzielony funkcją aktywacji, to powszechny wzór:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
Ponieważ siła wyrazu głębokich modeli liniowych nie jest większa niż płytkich modeli liniowych, używamy aktywacji ReLU dla wszystkich, z wyjątkiem ostatniej ukrytej warstwy. Ostateczna warstwa ukryta nie korzysta z żadnej funkcji aktywacji: użycie funkcji aktywacji ograniczyłoby przestrzeń wyjściową ostatecznych osadzeń i mogłoby negatywnie wpłynąć na wydajność modelu. Na przykład, jeśli jednostki ReLU są używane w warstwie projekcyjnej, wszystkie komponenty w osadzonym wyjściu będą nieujemne.
Spróbujemy tutaj czegoś podobnego. Aby ułatwić eksperymentowanie z różnymi głębokościami, zdefiniujmy model, którego głębokość (i szerokość) definiuje zestaw parametrów konstruktora.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
layer_sizes parametr daje nam głębię i szerokość modelu. Możemy go zmieniać, aby eksperymentować z płytszymi lub głębszymi modelami.
Model kandydata
Możemy przyjąć to samo podejście do modelu filmowego. Znowu zaczynamy MovieModel od featurization poradnik:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
I rozszerz go o ukryte warstwy:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
Połączony model
Zarówno QueryModel i CandidateModel zdefiniowane, możemy umieścić razem łączny model i realizować nasze straty i metryki logiki. Aby uprościć sprawę, wymusimy, aby struktura modelu była taka sama we wszystkich modelach zapytań i kandydujących.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
Trening modelki
Przygotuj dane
Najpierw podzieliliśmy dane na zestaw uczący i zestaw testowy.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
Płytki model
Jesteśmy gotowi do wypróbowania naszego pierwszego, płytkiego modelu!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
Daje nam to dokładność top-100 około 0,27. Możemy to wykorzystać jako punkt odniesienia do oceny głębszych modeli.
Głębszy model
A co z głębszym modelem z dwiema warstwami?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
Dokładność tutaj wynosi 0,29, trochę lepiej niż w płytkim modelu.
Aby to zilustrować, możemy wykreślić krzywe dokładności walidacji:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
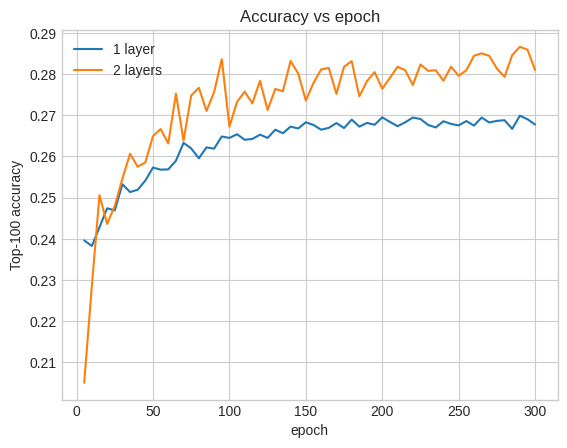
Nawet na początku szkolenia większy model ma wyraźną i stabilną przewagę nad modelem płytkim, co sugeruje, że dodanie głębi pomaga modelowi uchwycić bardziej zróżnicowane relacje w danych.
Jednak nawet głębsze modele niekoniecznie są lepsze. Poniższy model rozszerza głębokość do trzech warstw:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
W rzeczywistości nie widzimy poprawy w stosunku do modelu płytkiego:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
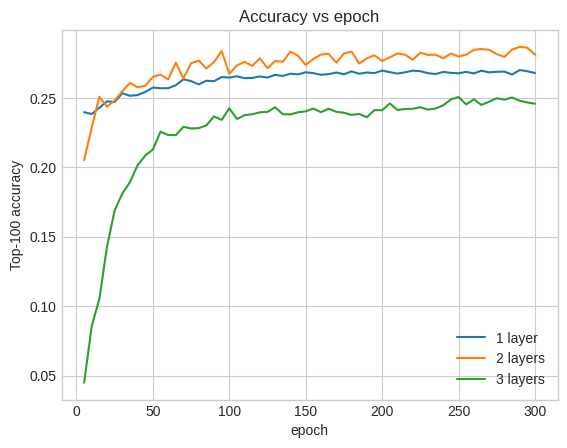
To dobry przykład na to, że głębsze i większe modele, choć zdolne do doskonałych osiągów, często wymagają bardzo starannego dostrojenia. Na przykład w tym samouczku używaliśmy jednej, stałej szybkości uczenia się. Alternatywne wybory mogą dać bardzo różne wyniki i warto je zbadać.
Przy odpowiednim dostrojeniu i wystarczającej ilości danych wysiłek włożony w tworzenie większych i głębszych modeli w wielu przypadkach jest tego warty: większe modele mogą prowadzić do znacznej poprawy dokładności predykcji.
Następne kroki
W tym samouczku rozszerzyliśmy nasz model pobierania o gęste warstwy i funkcje aktywacji. Aby zobaczyć, jak stworzyć model, który można wykonać nie tylko pobierania zadań, ale również ocenił zadania, spojrzeć na tutorialu wielozadaniowej .